PostgreSQL - 新規行トリガー
新規行
このトリガーは、選択したテーブルまたはビューに挿入された行を取得します。 各行は個別のジョブとして処理されます。 各ポーリング間隔で新しい行をチェックします。
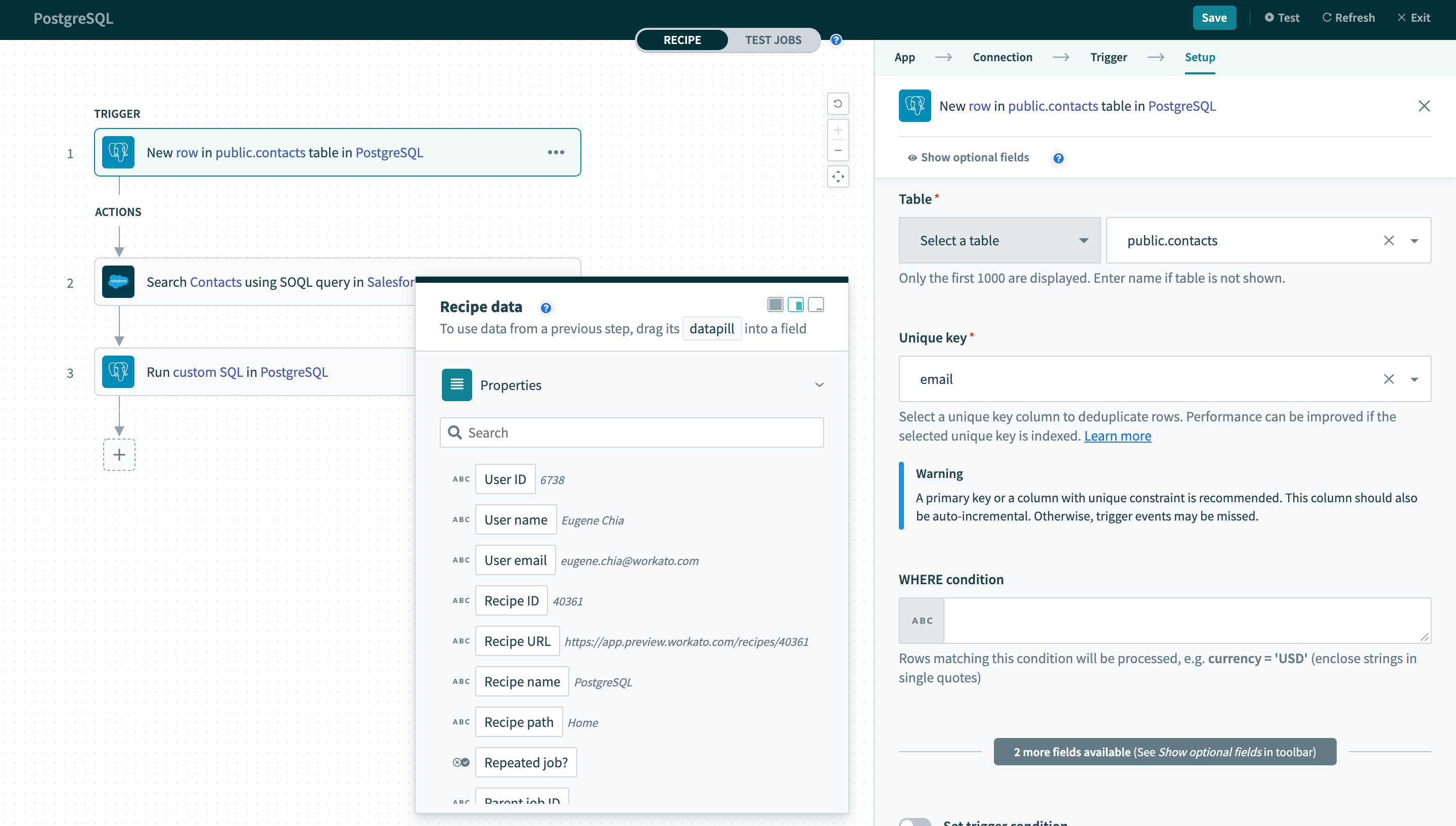 新規行トリガー
新規行トリガー
| 入力フィールド | 説明 |
|---|---|
| テーブル | まず、行の処理元となるテーブル/ビューを選択します。 |
| 一意キー | 次に、行を一意に識別するための一意キー列を選択します。 この列のリストは、選択したテーブル/ビューから生成されます。 |
| WHERE条件 | 最後に、行をフィルタリングするための任意のWHERE条件を指定します。 |
行の新規バッチ
このトリガーは、選択したテーブルまたはビューに挿入された行を取得します。 これらの行は、各ジョブで行のバッチとして処理されます。 このバッチサイズは、トリガー入力で設定できます。 各ポーリング間隔で新しい行をチェックします。
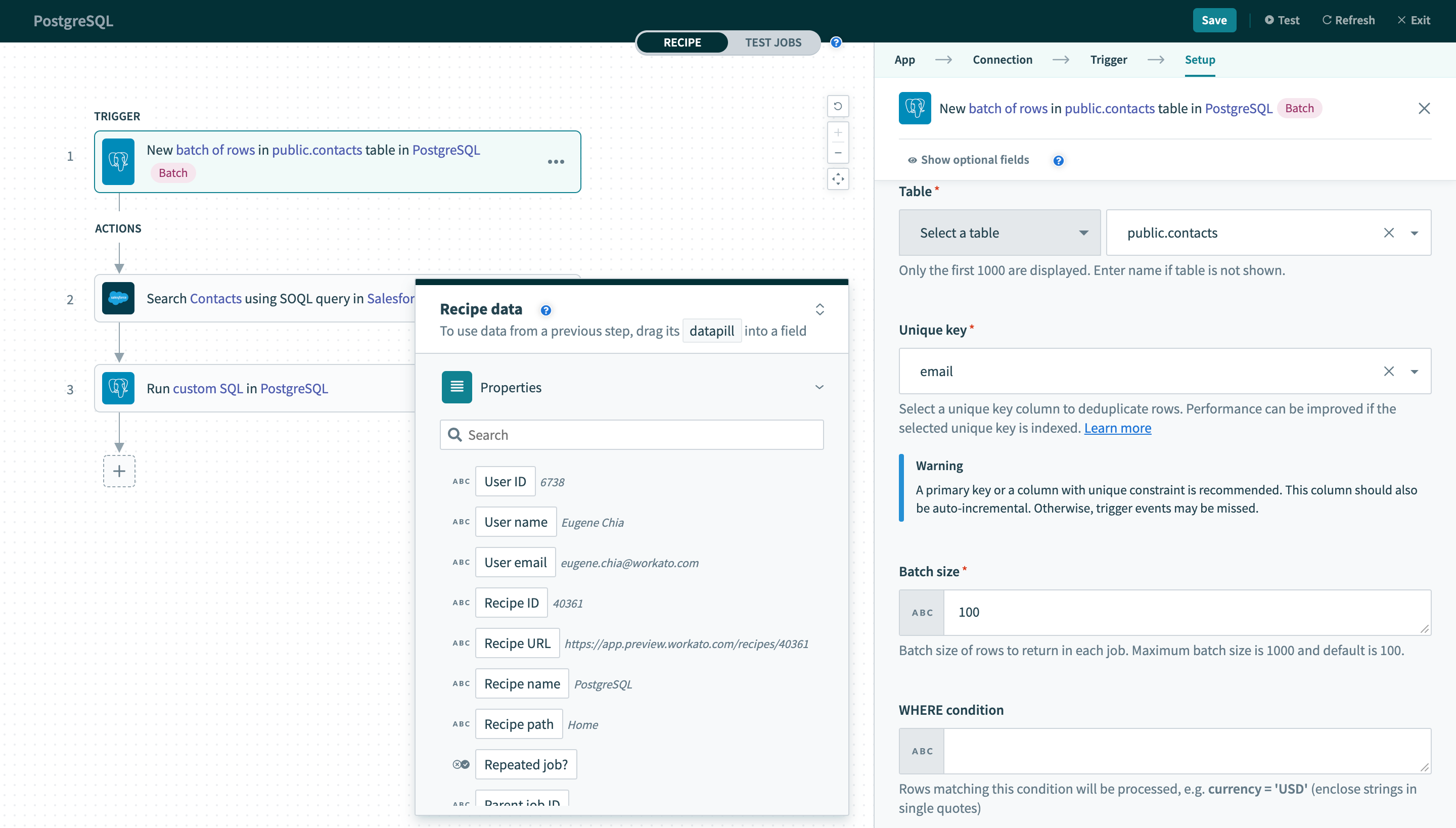 行の新規バッチトリガー
行の新規バッチトリガー
| 入力フィールド | 説明 |
|---|---|
| テーブル | まず、行の処理元となるテーブル/ビューを選択します。 |
| 一意キー | 次に、行を一意に識別するための一意キー列を選択します。 この列のリストは、選択したテーブル/ビューから生成されます。 |
| バッチサイズ | 次に、このレシピの各個別ジョブで処理するバッチサイズを設定します。 |
| WHERE条件 | 最後に、行をフィルタリングするための任意のWHERE条件を指定します。 |
入力
テーブル
行の処理元となるテーブル/ビューを選択します。 これは、選択リストからテーブルを選択するか、入力フィールドをテキストモードに切り替えて完全なテーブル名を入力することで実行できます。
一意キー
この選択した列の値は、選択したテーブル内の行の重複を排除し、同じレシピで同じ行が2回処理されないようにするために使用されます。
そのため、選択した列の値がテーブル内で重複しないようにしてください。 通常、この列はテーブルの主キーです(例:ID)。 増分可能で、ソート可能である必要があります。 パフォーマンスを向上させるために、この列にインデックスを付けることもできます。
PRIMARY KEYまたはUNIQUE制約を持つ列のみ使用できます。 この要件を満たす列を確認するには、このSQLクエリを実行します。
SELECT c.column_name
FROM information_schema.key_column_usage AS c
LEFT JOIN information_schema.table_constraints AS t
ON t.constraint_name = c.constraint_name
WHERE
t.table_schema = 'schema_name' AND
t.table_name = 'table_name' AND
t.constraint_type in ('PRIMARY KEY', 'UNIQUE')
ORDER BY c.ordinal_position;バッチサイズ
各ジョブで返す行のバッチサイズ。 これは1から最大バッチサイズまでの任意の数値にできます。 最大バッチサイズは100で、デフォルトは100です。
任意のポーリングで、行数が設定されたバッチサイズより少ない場合、このトリガーはすべての行をより小さいバッチとして配信します。
WHERE条件
この条件は、1つ以上の列の値に基づいて行をフィルタリングするために使用されます。
status = 'closed' and priority > 3選択したテーブルのすべての行を処理するには、空白のままにします。
サブクエリを含む複雑なWHERE条件も使用できます。 詳細については、WHERE条件ガイドを参照してください。
最終更新日: