MCP serverツール設計
MCPサーバーは、大規模言語モデル(LLM)がシステム内のデータにアクセスし、アクションを実行できるようにするツールの集合です。 MCP serverツール設計とは、AIエージェントがアプリケーションとやり取りするためのツールを計画し、構造化するプロセスです。
Workatoでは、MCP serverツール設計について次のベストプラクティスを推奨しています:
- 複雑なワークフローに対応するため、互いに補完し合うツールを構築します。
- 大規模なデータセットを要約する前処理ステップを作成します。
- ユースケースの発展に合わせて、新しいツールを段階的に追加します。
- すべてのツールで一貫したエラーコードを使用します。
- 実際のAIエージェントワークフローでツールをテストします。
- 最も頻繁に使用されているツールを監視します。
- 利用状況パターンに基づいてツールの説明を改善します。
- 追加のユースケースをサポートするために新しいツールを追加します。
効果的なMCP serverを設計するための包括的なベストプラクティス(MCPスコープの特定、MCP serverの説明ガイドライン、エラー処理、入出力構造の定義など)については、MCP server設計を参照してください。
MCP serverツール設計の考慮事項
特定のツールユースケースを中心にMCPサーバーを設計します。 有効にする予定のワークフローから開始し、必要なツール、各ツールが返すデータ、ツール間のやり取りを決定します。 各コンポーネントは相互に関連しており、これらの関係を理解することで、効率的で信頼性が高く、構成可能なMCPサーバーを設計できます。
これらの考慮事項は、時間の経過に伴う調整を最小限に抑えながら、成功するMCP serverを設計するのに役立つ次のポイントに分類できます:
- ユースケース: ツールで解決する具体的なシナリオを定義します。 MCP serverはどのワークフローを実現しますか。
- ツールの分解: ワークフローを構成する個別の操作を特定します。 どのようなアクションが必要ですか。
- データ最適化: ツールの応答に含めるデータフィールドを決定します。 どの情報が不可欠ですか。
- 開発者エクスペリエンス: 明確な説明と例を計画します。 LLMがツールを効果的に解釈して適用できるようにします。
MCPサーバーには通常、次のコンポーネントが含まれます。
- ツール:AIエージェントが実行できるアクション(スキル)を定義します。
- ツールアーキテクチャ:ツールの構造と、他のツールおよびアプリとの連携方法を指定します。
- データ戦略:AIエージェントに返される情報を制御します。
- ツールの説明:AIエージェントが各ツールを理解し、使用する方法を決定します。
最初のMCP serverワークフローユースケースを設計する
すべてのMCP serverは、特定のワークフローから始まります。 ワークフローのユースケースは、ツールがサポートするタスクと必要な操作の順序を定義します。 ワークフローのユースケースは、広範で抽象的なものではなく、具体的で測定可能である必要があります。 次の原則に沿ってツールを設計します:
- シナリオから始める: 実現する予定の、具体的で価値の高いワークフローを特定します。
- ツールに分解する: ワークフローを、AIエージェントがOrchestrateできる個別の操作に分解します。
- モノリシックなツールを避ける: ワークフロー全体を処理しようとする単一のツールを作成しないでください。 たとえば、
process_zoom_to_jiraという1つのツールを作成するのではなく、連携して動作するget_zoom_meetings、get_zoom_transcript、create_jira_issueのような個別のツールを作成します。
| ❌非推奨 | ✅推奨 |
|---|---|
過負荷のツールmanage_item(action, type, id, data)- アクション: create, read, update, delete - タイプ: customer, order, product | 単一目的のツールcreate_customer(data)get_customer(id)update_customer(id, fields)search_customers(query) |
隠れた副作用update_order(id, status)// 次の処理も実行: メール送信、在庫更新 | 明示的なツールupdate_order_status(id, status)send_order_email(id)update_inventory(id) |
隠れた制限search(query)// queryが100文字を超えると失敗 // 最大10件を返し、通知なし | 明示的な制限search(query, limit=20)// query: 最大100文字、超過時はエラーを返す // has_moreフラグを返す |
ツール設計の原則
ツールは、具体的で予測可能な方法でアプリケーションとやり取りする必要があります。 MCP serverは、ユースケースの複雑さに応じて、1つまたは複数のツールを持つことができます。 ツールを設計する際は、次の原則を考慮します:
シンプルなツール
シンプルなツールは曖昧さを減らします。 各ツールには、単一で明確な目的が必要です。 入力に基づいて出力を変更する複雑な分岐ロジックは避けてください。 たとえば、get_customer_by_idというツールは明確ですが、get_customer_or_create_newというツールは、どのアクションが発生するのかについて混乱を招きます。
シンプルなツールを設計すると、次のメリットがあります:
- AIエージェントは、各ツールの動作を正確に把握できます。
- ハルシネーションや予期しない動作を減らします。
- ツールの動作を理解しやすく、テストしやすくします。
コンポーザブルなツール
コンポーザブルなツールはワークフローを実現します。 ツールは構成要素として連携する必要があります。 あるツールの出力は、別のツールの入力として簡単に利用できる必要があります。 すべてのツールで、一貫した標準の命名規則を使用します。 たとえば、emailとuser_emailを切り替えるのではなく、常にemail_addressを使用します。
コンポーザブルなツールを設計すると、次のメリットがあります:
- AIエージェントが操作を自然につなげられるようにします。
- シンプルなツールから複雑なワークフローを実現します。
- エージェントに新しいパターンを教える必要性を減らします。
予測可能なツール
予測可能なツールはエラーを適切に処理します。 ツールは、すべてのシナリオで一貫して動作する必要があります。 IDが欠落している場合、ツールはランダムなバリエーションではなく標準エラーを返す必要があります。 AIエージェントが何が問題だったのかを理解できるように、詳細なエラーメッセージを含むHTTPステータスコードを定義します。 Workatoでは、次の標準ステータスコードを使用することを推奨しています:
- 成功には
200 - 不正な入力には
400 - リソースが見つからない場合は
404 - サーバーエラーには
500
予測可能なツールを設計すると、次のメリットがあります:
- AIエージェントがエラー状態の処理方法を学習します。
- ワークフローを終了する代わりに、適切な復旧を可能にします。
- エージェントが確認を求めたり、代替手段を試したりできるようにします。
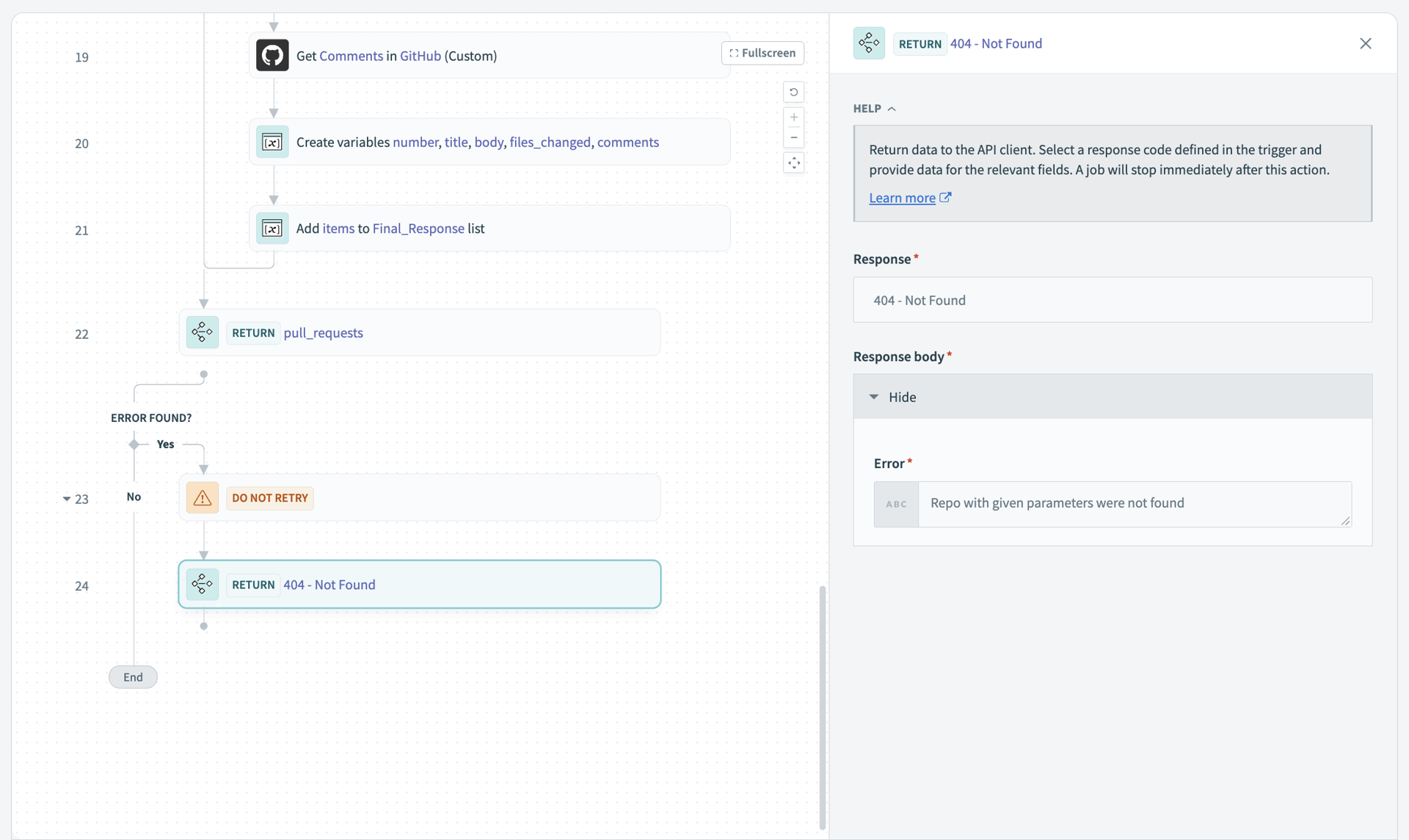 標準HTTPエラーコードを使用するMCPツール
標準HTTPエラーコードを使用するMCPツール
データ戦略
このセクションでは、ツールが返すデータを最適化するための戦略について説明します。 過剰なデータや無関係なデータを返すと、AIエージェントに負荷がかかり、パフォーマンスが低下する可能性があります。 ワークフローに必要な情報のみを含めることに重点を置きます。
コンテキストウィンドウ向けにデータを最適化する
AIエージェントは、一度に限られた量の情報しか処理できません。 返される情報が多すぎると、以前のツール呼び出しからのコンテキストが失われる可能性があります。 データ応答は、効率的で焦点を絞ったものになるように設計します。
必要なフィールドのみを返す
APIは、ワークフローに関係のない大量のデータを返すことがよくあります。 Jira課題を取得する呼び出しでは、メタデータ、アイコン、リンク、履歴ログを含む200個のフィールドが返される場合があります。 この未加工データはトークンを無駄にし、混乱を生じさせます。
ベストプラクティス: 必須フィールドのみを含めるように応答スキーマを定義します。 たとえば、ページの完全な内容ではなく、タイトル、URL、簡単な概要のみを返す検索ツールを作成します。
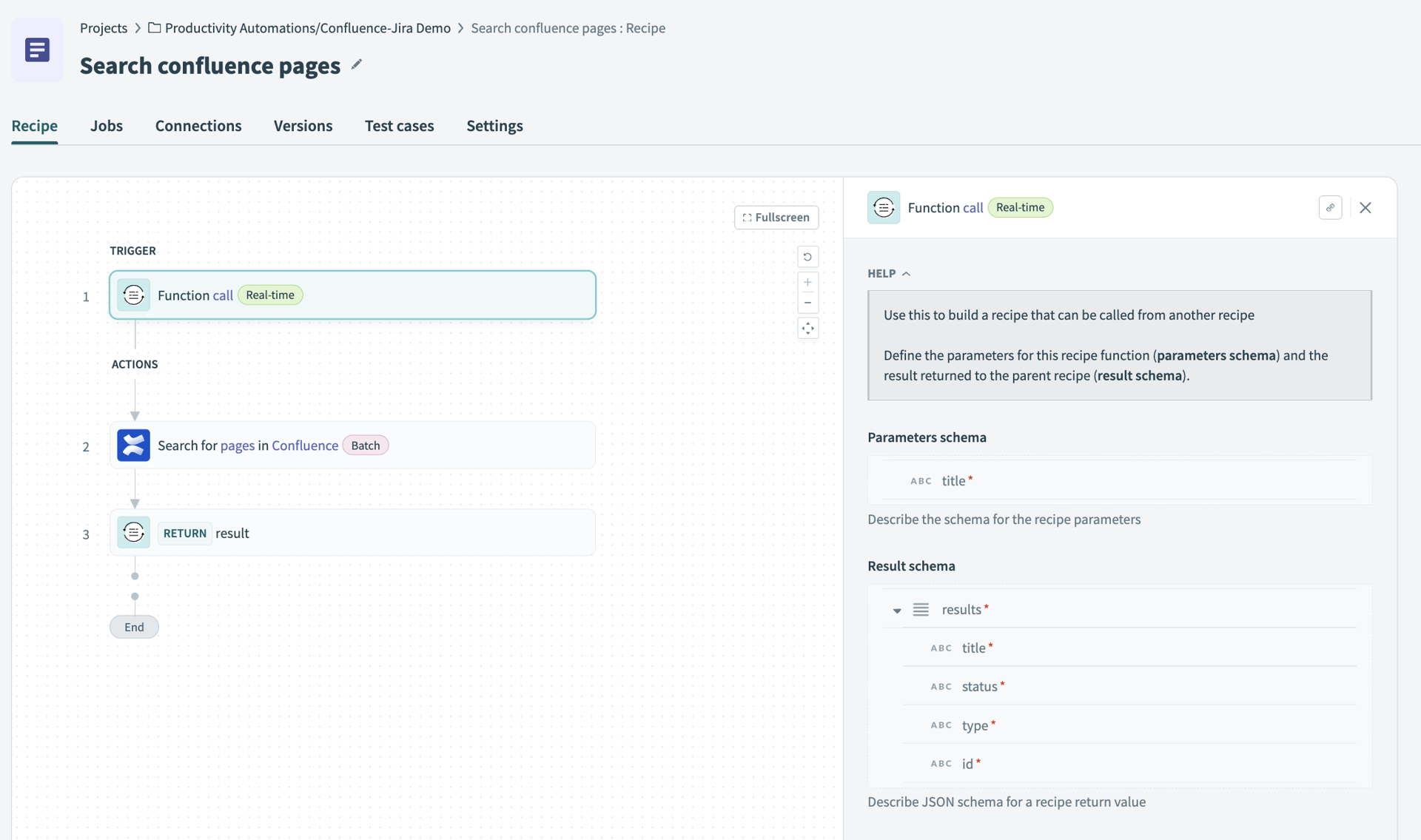 スキーマには必須フィールドのみを含める
スキーマには必須フィールドのみを含める
必要なフィールドのみを返すと、次のメリットがあります:
- 他の操作のためにコンテキストウィンドウを保持します。
- トークンコストを削減します。
- AIエージェントが関連情報に集中できるようにします。
大規模なデータにAI前処理を使用する
トランスクリプトやログなどの大規模なテキストソースからの未加工データを、AIエージェントに直接送信しないでください。 結果を返す前に、中間のAI処理ステップを使用してコンテンツを要約します。 たとえば、次のようなワークフローを設計できます:
- APIから完全なトランスクリプトを取得します。
- AIモデルを使用してトランスクリプトを要約します。
- 概要のみをAIエージェントに返します。
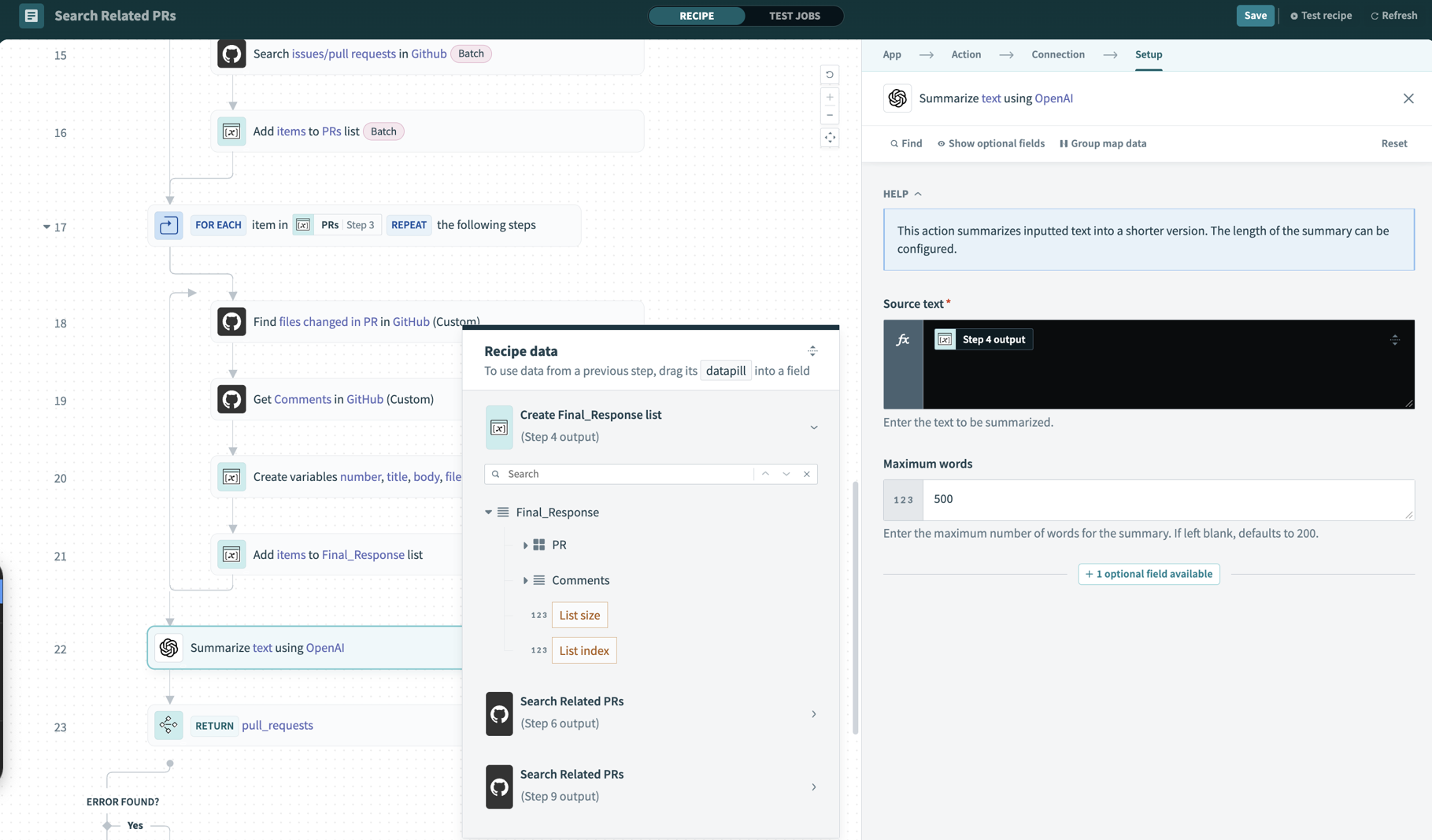 AIモデルを使用してトランスクリプトを要約する
AIモデルを使用してトランスクリプトを要約する
大規模なデータにAI前処理を使用すると、次のメリットがあります:
- コンテキストウィンドウを管理可能な状態に保ちます。
- AIエージェントに実用的な情報を提供します。
- メインワークフローの処理オーバーヘッドを削減します。
開発者エクスペリエンス
AIエージェントは、ツールドキュメントを使用してツールを効果的に理解し、使用します。 AIエージェントは、ツール名、説明、スキーマを使用して各ツールの動作を理解します。 明確なドキュメントにより、エラーが減少し、ツールの採用が向上し、エージェントが複雑なワークフローを正常にOrchestrateできるようになります。 効果的なツールドキュメントを設計するには、次のセクションを参照してください:
詳細なツールの説明を書く
ツールの説明方法によって、AIエージェントがそのツールをどれだけ適切に使用できるかが決まります。 AIエージェントはコード実装を認識しません。 エージェントが認識するのは、ツール名、説明、スキーマのみです。 ツール名は、そのツールの動作を明確に示す必要があります。 意味を分かりにくくする専門用語、バージョン番号、略語は避けてください。 例:
| 推奨 | 非推奨 |
|---|---|
✅ search_products | ❌ prod_lookup_v2 |
✅ create_jira_issue | ❌ jira_create |
✅ get_zoom_transcript | ❌ fetch_zm_txt |
説明には、ツールの目的、返される内容、使用するタイミングを記載する必要があります。 データ構造とユースケースに関する具体的な詳細を含めます。 例:
Searches the product catalog by keyword. Returns a list of matching items including SKU, price, and stock level. Use this tool when checking product availability or looking up pricing information.| ❌非推奨 | ✅推奨 |
|---|---|
Use for searches | Use when user asks to find customers by name, email, or company |
Standard limits apply | Max 100 results per call, returns cursor if more available |
Ensure data is valid | account_id must come from search_accounts or create_account |
このツールを使用するタイミング - 具体的に記載する
✅ 推奨 - 具体的なトリガー 次の場合にこのツールを使用します:
- ユーザーが名前、アカウント、所有者、またはステージで商談を検索するよう依頼する場合
- ユーザーが特定の条件に一致する取引を求めている場合
- ユーザーが担当者またはチームに割り当てられた商談を要求する場合 検索条件が指定されていない場合は、検索条件を尋ねます。
❌ 非推奨 - 曖昧すぎる
- 商談関連の検索にこのツールを使用します。
このツールを使用しないタイミング - 混乱を防ぐ
✅ このツールを次の目的で使用しないようLLMに伝える否定的なガイダンスを含めます:
- 新しい商談を作成する(create_opportunityを使用)
- 集計分析を実行する(opportunity_analyticsを使用)
- 日付範囲のみでフィルタリングする(list_opportunities_by_dateを使用)
制限を明示的に定義する
✅ 明確な制限
- 1回の呼び出しあたり最大100件の結果
- クエリ文字列: 最大200文字
- 日付範囲: 最大90日
- レート制限: 1分あたり10回の呼び出し
❌ 曖昧な制限
- 標準の制限が適用されます。 大規模なリクエストには注意してください。
前提条件を明確に記載する
明示的な前提条件と依存関係により、MCP serverのパフォーマンスが向上します。 例:
1. Call validate_account before creating opportunities
2. Use get_opportunity before update_opportunity to confirm current state
Dependencies:
- account_id must come from search_accounts or create_account
- stage values must be selected from list_opportunity_stagesサンプルリクエストと応答を含める
ツールの説明にJSONリクエストと応答の例を追加します。 これにより、AIエージェントが想定されるデータ形式を理解するのに役立つ例が提供されます。
リクエスト例
{
"keyword": "laptop",
"limit": 5
}応答例
{
"products": [
{
"sku": "LAP-001",
"name": "Business Laptop Pro",
"price": 899.99,
"in_stock": true
}
]
}リクエストと応答のサンプルを含めると、次のメリットがあります:
- エージェントがツールを呼び出す前に入力を検証するのに役立ちます。
- 応答で想定されるデータ構造をエージェントに示します。
- 不適切なツールの利用状況によるエラーを減らします。
最終更新日: