Regexの概要
Regex、またはregexp(regular expressions)は、テキスト内のパターン照合に使用される強力なツールです。 Regexは、文字列またはパターンを表す記号と文字のシーケンスです。 Regexは、特定のパターンに従うテキスト文字列を識別するための簡潔で柔軟な方法を提供します。 Workatoでは、regexを使用してテキスト本文から特定の情報を抽出したり、ユーザー入力を検証したりできます。
このドキュメントでは、regexとWorkatoでの利用状況の基本を紹介します。 Regexとその利用状況に関する包括的なガイドについては、Ruby docを参照してください。
Workatoでregexを使用する
Regexは、次のようなさまざまなWorkato製品および機能で使用できます。
Formula: 複雑なテキスト操作を実行するために、文字列Formula内でregexを使用できます。 たとえば、regexを使用して文字列の特定の部分を抽出したり、入力形式を検証したり、テキストパターンを置換したりできます。
ユーティリティ: Workatoは、JSONまたはXMLドキュメントの解析などのタスクでregexをサポートするユーティリティコネクターを提供します。 これにより、より正確なデータ抽出と変換が可能になります。
レシピ: レシピを構築するときに、条件やアクションでregexを使用して、特定のパターンに基づいてデータをフィルタリングおよび操作できます。
Workbot: ユーザー入力が想定した形式に一致することを検証します。 たとえば、regexを使用してメールアドレス、URLなどを検証できます。
Workflow apps: ユーザー入力が想定する形式と一致することを検証します。 たとえば、regexを使用してSSN(Social Security Numbers)、IBAN(International Bank Account Numbers)などを検証できます。
制限事項
WorkbotおよびWorkflow appsでは、補間(正規表現パターン内で変数コンテンツを挿入または含めること)はサポートされていません。
基本構文
Regexは、リテラル文字(その文字自体に一致)とメタ文字(特別な意味を持つ)で構成されます。 基本的な要素を次に示します。
リテラル文字
リテラル文字は、次のようにその文字自体に一致します。
a1!
その他の例については、リテラル文字のリファレンステーブルを参照してください。
メタ文字
メタ文字は、事前定義された意味を持つ特殊文字です。 例:
.: 任意の1文字に一致します。*: 文字または文字範囲の0回以上の出現を許可します。+: 文字または文字範囲の1回以上の出現を許可します。
その他の例については、メタ文字のリファレンステーブルを参照してください。
利用状況の例
特定のパターンに一致させる
次の例は、regexを使用して特定のパターンに一致させる方法を示しています。
/hello/は、文字列内のシーケンスhelloに一致します。
文字クラス
文字クラスは、一致させる予定の文字セットを指定する方法です。 文字クラスを使用すると、複数の文字または文字範囲のいずれか1つに一致するようregexエンジンに指示できます。
/[a-z]/は、任意の小文字に一致します。/[0-9]/は、任意の数字に一致します。
量指定子
Regexの量指定子は、パターン内の要素を何回一致させるかを指定します。 これらは、regexパターン内の文字、グループ、または文字クラスの繰り返しを制御するうえで重要です。
/a*/は、aの0回以上の出現に一致します。/b+/は、bの1回以上の出現に一致します。/c?/は、cの0回または1回の出現に一致します。
アンカー
アンカーは、文字に一致するのではなく、文字列内の位置を指定する特殊文字です。 文字列または行の先頭や末尾を示したり、他の文字を基準にした位置を定義したりするために使用されます。
^は、行の先頭に一致します。$は、行の末尾に一致します。
エスケープシーケンス
\dは、任意の数字に一致します。\wは、英数字と_(アンダースコア)を含む任意の単語文字に一致します。
グループ化とキャプチャ
/(abc)+/は、abc、abcabc、および定義したパターンの同様の繰り返しに一致します。
実践例
次の例は、regexを使用して、メールアドレス、SSN、URLなどの特定のテキスト文字列に一致させる方法を示しています。
IBAN(International Banking Account Number)
IBAN(International Banking Account Number)の形式は国によって異なります。 次のregexパターンは、多くの標準IBAN形式をカバーします。
^[A-Z]{2}[0-9]{2}[A-Z0-9]{1,30}$詳細な説明を表示
^[A-Z]{2}: 2つの大文字(国コード)[0-9]{2}: 2桁の数字(チェックディジット)[A-Z0-9]{1,30}: 1~30文字の英数字
Social Security Number(SSN)
次のパターンは、米国のSSN(Social Security Number)に一致します。
^\d{3}-\d{2}-\d{4}$詳細な説明を表示
^\d{3}: 先頭の3桁の数字\d{2}: ハイフンに続く2桁の数字\d{4}: ハイフンに続く4桁の数字
ZIP Code/郵便番号
ZIP Codes(US)
米国のZIP Codeは、5桁または9桁(ZIP+4形式)のいずれかです。 次のregexはその両方に対応しています。
^\d{5}(-\d{4})?$EUの郵便番号
^\d{4,5}([-\s]?\d{3})?$詳細な説明を表示
^\d{4,5}: 先頭の4桁または5桁の数字に一致します。これは多くのEU郵便番号で一般的です。([-\s]?\d{3})?: オプションで、スペースまたはハイフンに続く3桁の数字に一致し、オランダやポルトガルのような形式に対応します。$: 文字列の末尾をアサートします。
日本の郵便番号
日本の郵便番号は、3桁、ハイフン、4桁の形式です。
^\d{3}-\d{4}$詳細な説明を表示
^\d{3}: 先頭の3桁の数字\d{4}: ハイフンに続く4桁の数字
シンガポールの郵便番号
シンガポールの郵便番号は6桁です。
^\d{6}$詳細な説明を表示
^\d{6}: ちょうど6桁の数字に一致します。
オーストラリアの郵便番号
オーストラリアの郵便番号は4桁です。
^\d{4}$詳細な説明を表示
^\d{4}: ちょうど4桁の数字に一致します。
メールアドレス
メールアドレスに一致させるには、次のregexを使用します。
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$詳細な説明を表示
^: Regexを文字列の先頭に固定し、文字列全体が次に定義されたパターンで始まるようにします。[a-zA-Z0-9._%+-]+: これは、@記号の前にあるメールアドレスのローカル部分を表します。 任意の英数字(a-z、A-Z、0-9)および文字._%+-の1回以上の出現(+量指定子)に一致します。 これは、@記号の前にあるメールアドレスのローカル部分を表します。@: メールアドレスのローカル部分とドメイン部分を区切るリテラル@文字に一致します。[a-zA-Z0-9.-]+: これは、メールアドレスのドメイン名部分を表します。 任意の英数字(a-z、A-Z、0-9)および文字.と-の1回以上の出現(+量指定子)に一致します。\.:.文字をエスケープして、リテラル.に一致するようにします。 Regexでは、.は任意の1文字に一致するメタ文字であるため、リテラル.に一致させるには\でエスケープする必要があります。[a-zA-Z]{2,}: これは、メールアドレスのトップレベルドメイン(TLD)部分を表し、少なくとも2文字の英字(.com、.net、.orgなど)で構成されるようにします。 少なくとも2回出現する({2,})任意の大文字または小文字(a-z、A-Z)に一致します。$: Regexを文字列の末尾に固定します。 これにより、文字列全体が先頭(^)から末尾($)まで定義されたパターンに一致するようになります。
URL
/^(https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w .-]*)*\/?$/詳細説明を表示
^: 文字列の先頭で一致を固定します。(https?:\/\/)?:https?はhttpまたはhttpsに一致します。s?によって"s"がオプションになるため、httpとhttpsの両方に一致します。:\/\/はリテラル://に一致します。- 末尾の
?により、この部分全体がオプションになります。 これにより、プロトコルなしのURL(www.example.com)にも一致できます。
([a-zA-Z0-9-]+(\.[a-zA-Z0-9-]+)+):[a-zA-Z0-9-]+は、ドメイン名の部分(exampleまたはsub-domain)に一致します。(\.[a-zA-Z0-9-]+)+は、.に続く別のドメイン部分(.com、.co.uk)に一致します。+により、このようなセクションを複数指定できます(サブドメイン、TLDなど)。
(:[0-9]{1,5})?:(:[0-9]{1,5})は、オプションのポート番号に一致します。 コロン:で始まり、その後に1~5桁の数字(:8080)が続きます。?により、ポートセクションがオプションになります。
(\/[^\s]*)?:\/は、通常パスの開始を示すスラッシュ/に一致します。[^\s]*は、空白ではない任意の文字([^\s])に0回以上(*)一致し、URLパス、クエリパラメーター、フラグメントの残りの部分をカバーします。?により、この部分がオプションになるため、パスのないURLにも一致します。
$: 文字列の末尾で一致を固定します。
複数のregex一致を処理する
複数のレコードを含む非構造化テキストを解析する場合は、.scan()をRepeat whileループとともに使用して、データを抽出して構造化します。
このパターンが必要な理由
多くのシステムは、JSONではなく非構造化テキストを出力します。
- 監視システムからのメールアラート
- アプリケーションからのログファイル
- レガシーシステムからエクスポートされたレポート
このテキストに複数のレコードが含まれる場合、各フィールドを抽出し、構造化データに再結合する必要があります。
例: テキストから構造化データを抽出する
次のような複数のレコードを含むテキストがあるとします。
Order: #1001, Customer: Alice, Status: Shipped
Order: #1002, Customer: Bob, Status: Pending
Order: #1003, Customer: Carol, Status: Deliveredこのデータをオブジェクトのリストに抽出して構造化するには、次の手順に従います。
テキストデータを保存する変数を作成します。 Create variableアクションを使用し、名前をemail_contentにします。
スクリーンショットを表示
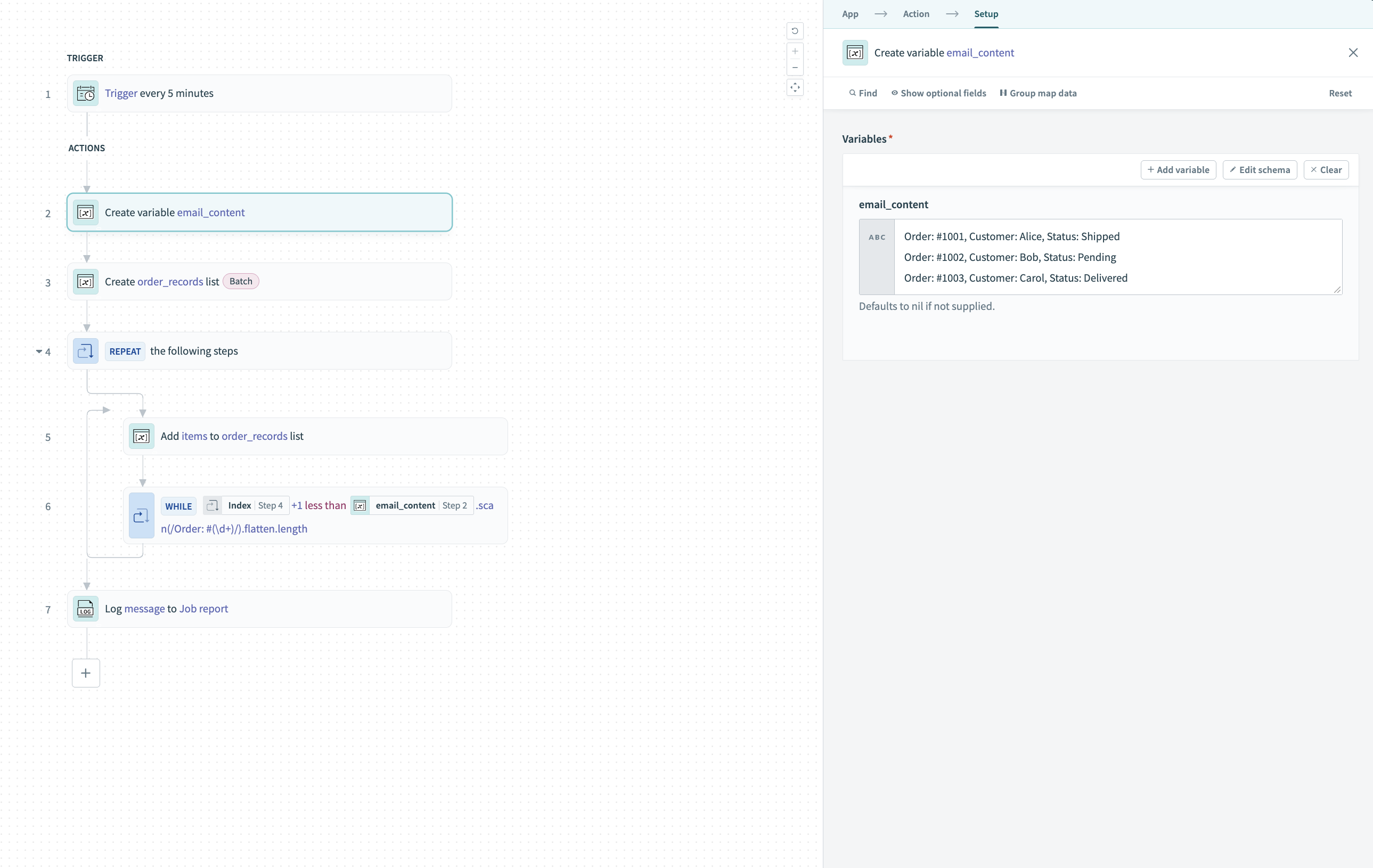 email_content変数を設定する
email_content変数を設定する
目的のスキーマで空のリストを作成します。 次の設定でCreate listアクションを使用します。
- List name:
order_records - 3つのフィールドを持つList item schema:
order_numbercustomer_nameorder_status
スクリーンショットを表示
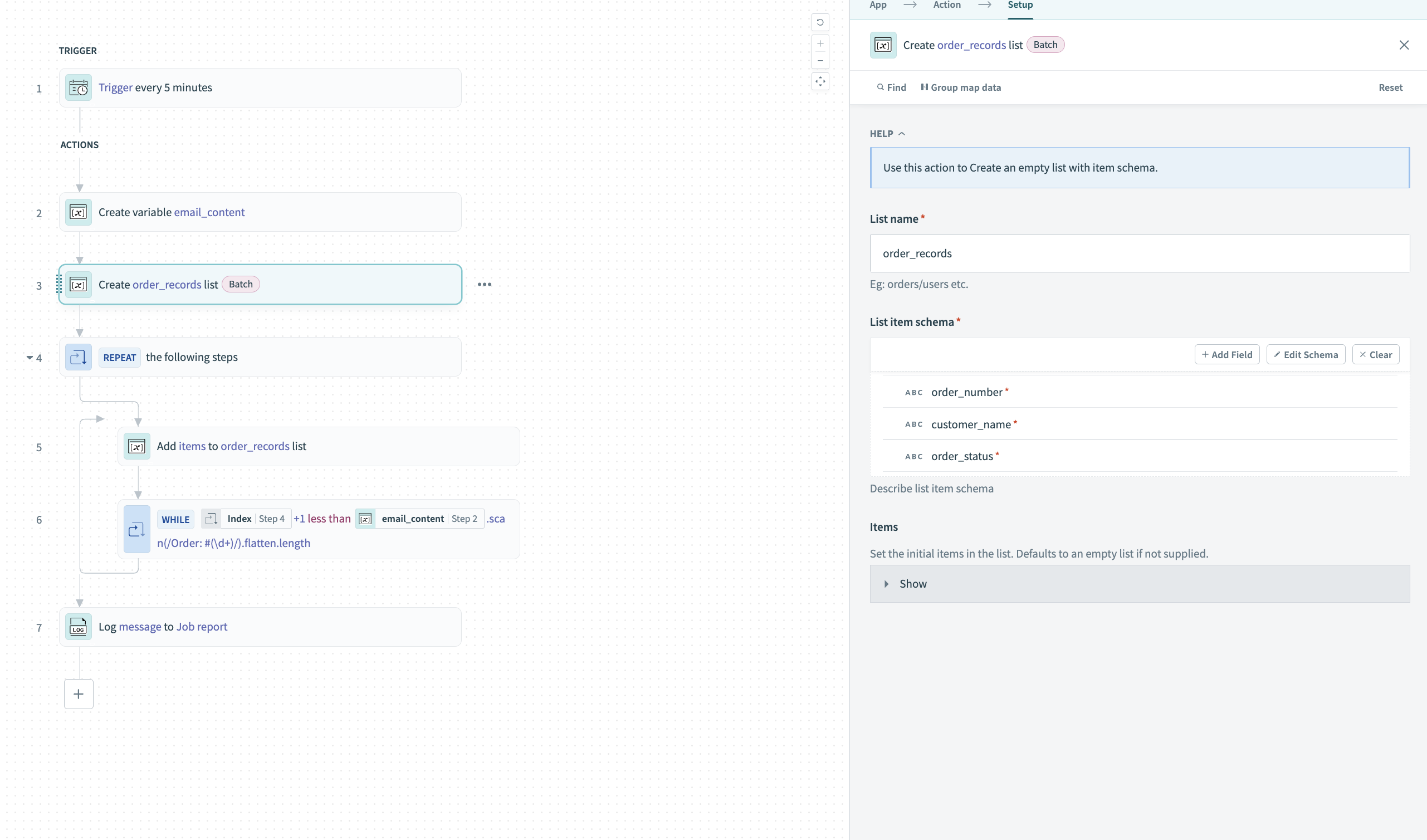 リストスキーマを定義する
リストスキーマを定義する
レシピにRepeat whileアクションを追加します。 これにより、テキスト内の各レコードを反復処理するループが作成されます。
スクリーンショットを表示
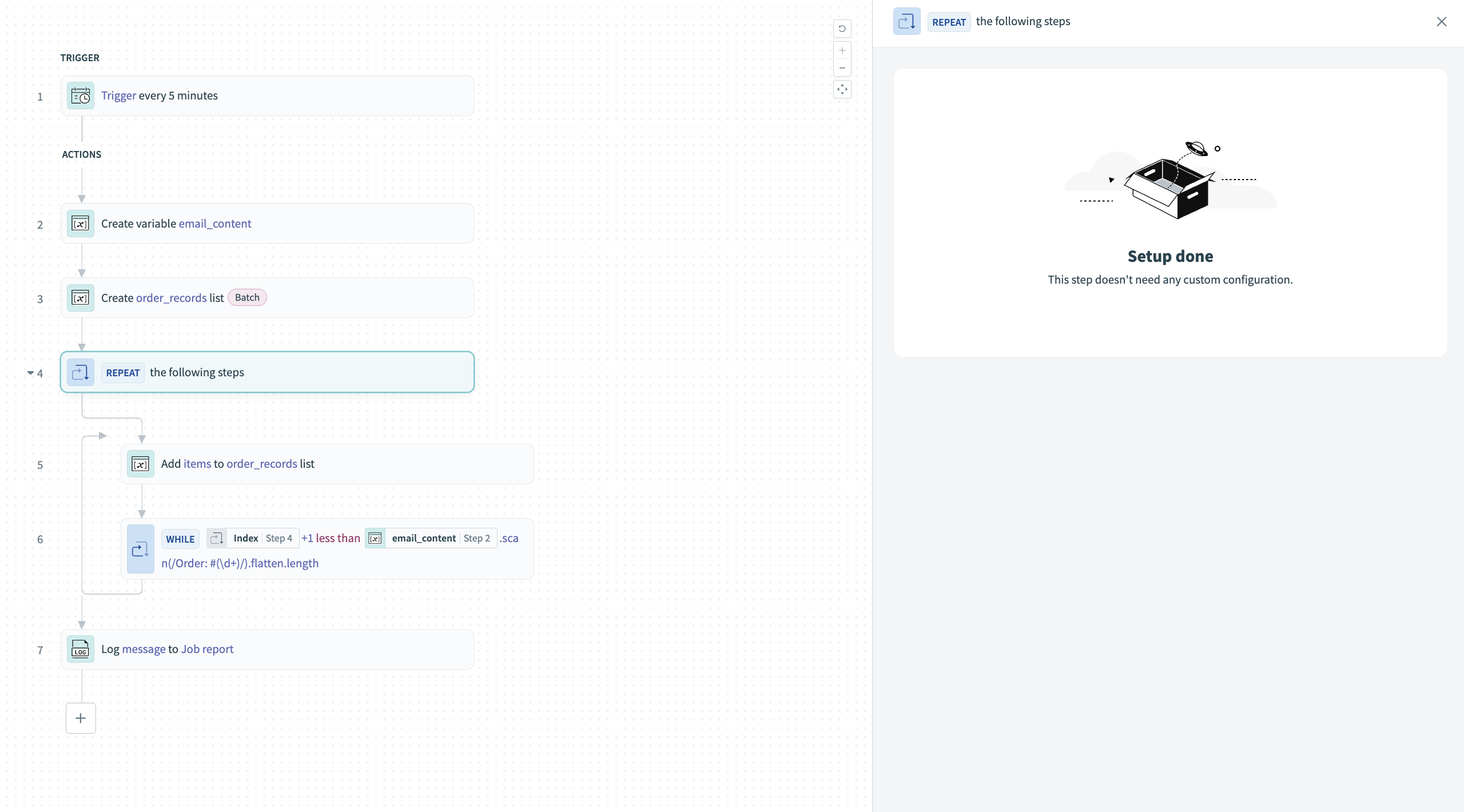 Repeat whileループを追加する
Repeat whileループを追加する
Repeat whileループ内で、Add items to listアクションを追加し、order_records (step 3)リストを選択します。
ループのIndexステップ 4を使用してデータを抽出するインライン.scan() Formulaで各フィールドを設定します。
各Formulaはテキストに対して.scan()を実行し、すべての一致を抽出し、結果をフラット化してから、Indexステップ 4を使用して現在の位置にアクセスします。
スクリーンショットを表示
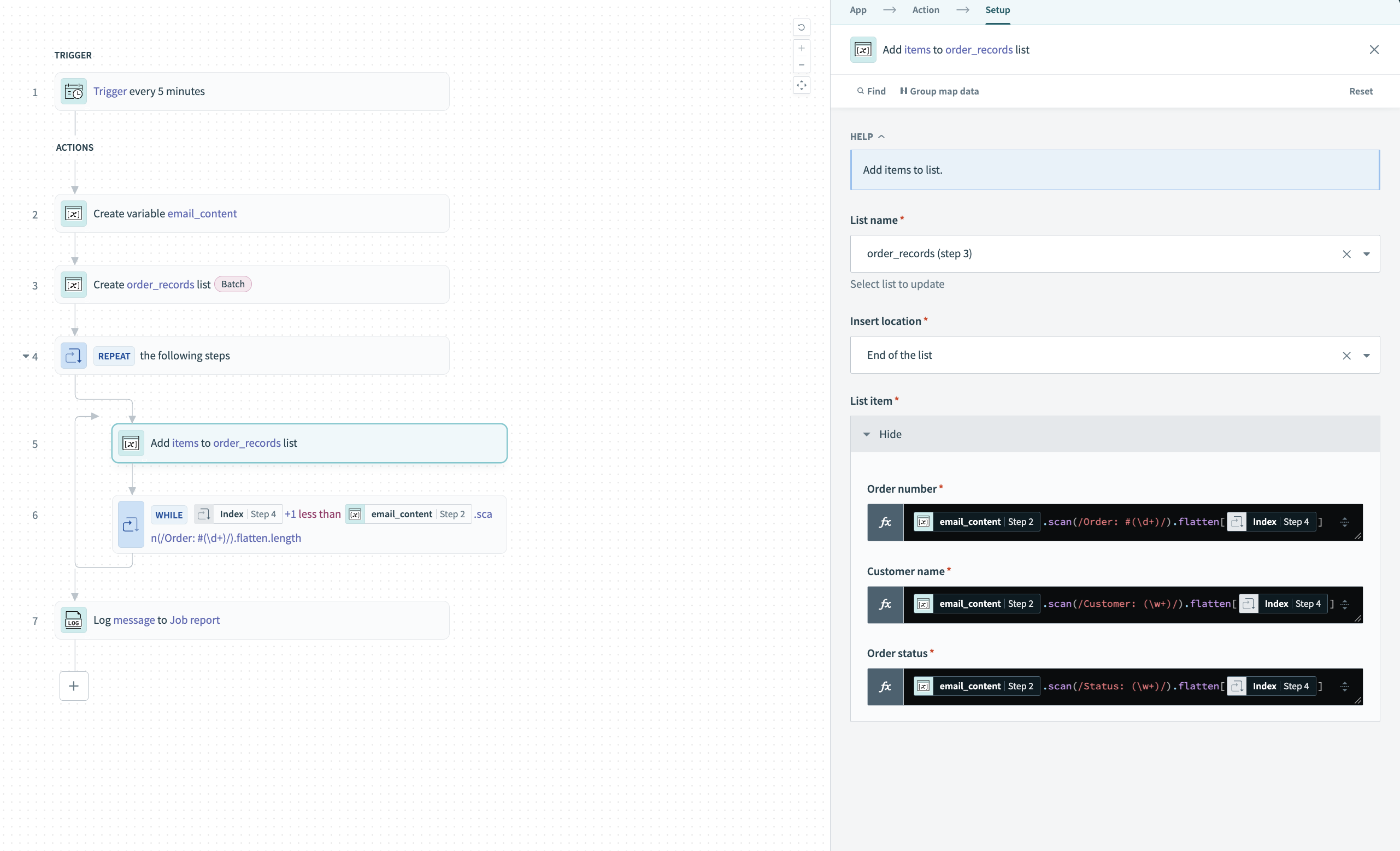 インラインFormulaでフィールドを設定する
インラインFormulaでフィールドを設定する
処理するレコードがさらにある間ループを続行するように、Repeat whileループのWHILE conditionを設定します。
Condition: less than
これにより、現在のIndexステップ 4を、.scan()を実行して配列の長さをカウントすることで見つかったレコードの総数と比較します。
スクリーンショットを表示
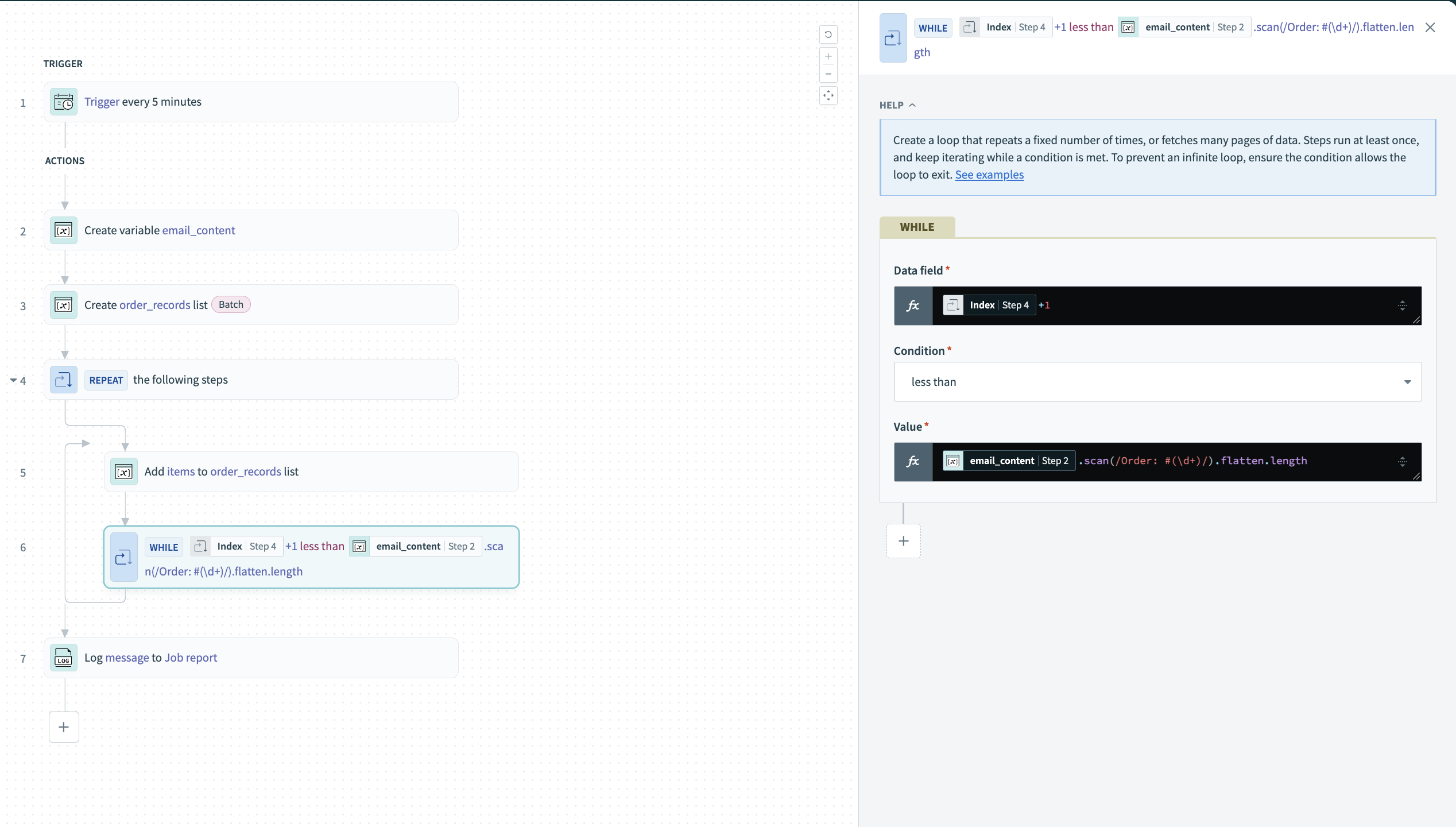 ループ条件を設定する
ループ条件を設定する
構造化リストを出力するために、Log message to Job reportアクションを追加します。 これにより、結果を検証し、後続のレシピステップでデータを使用できるようになります。
完全な構造化データをログに記録するには、order_recordsステップ 3リストデータピルを使用します。
スクリーンショットを表示
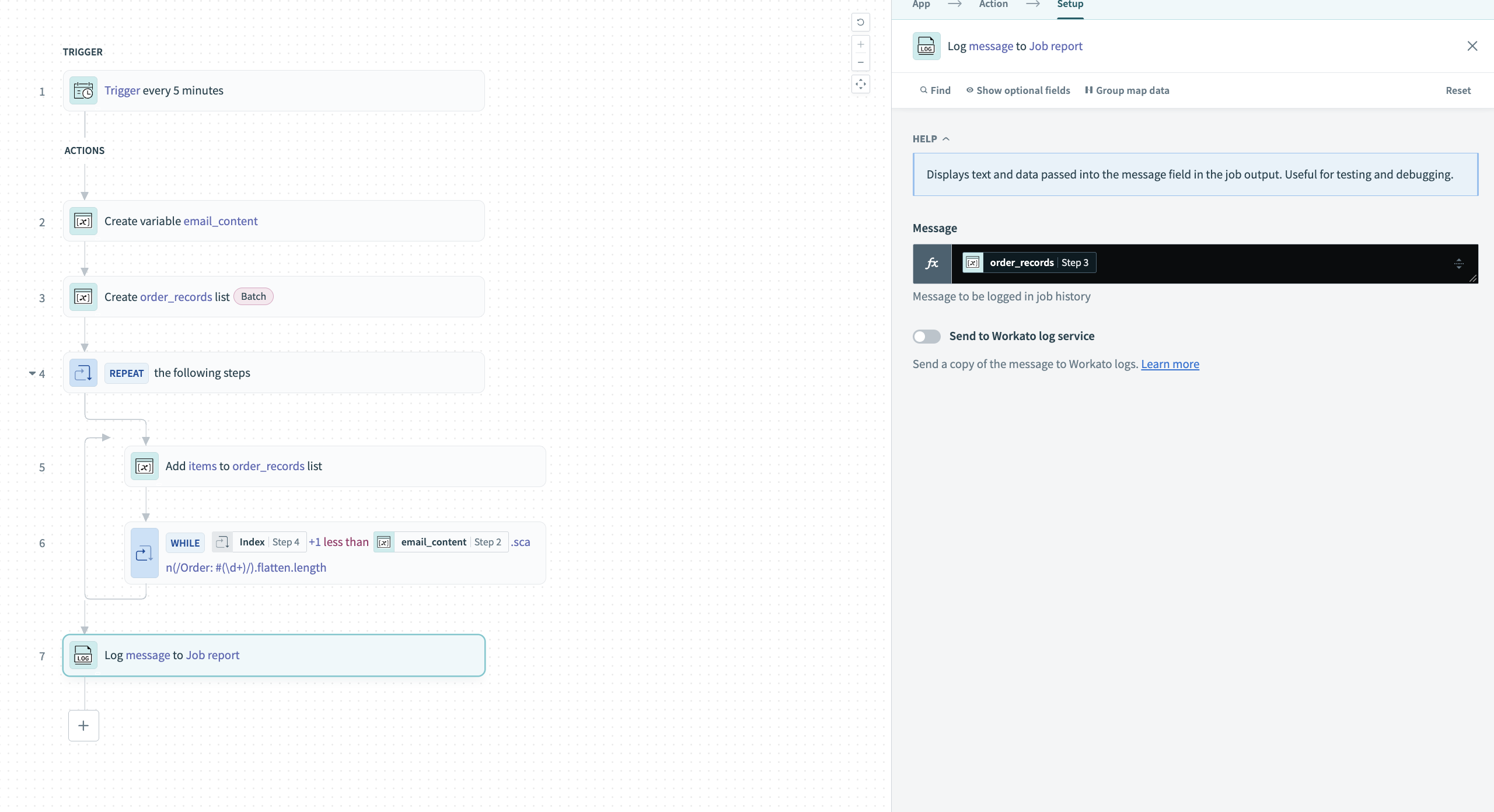 構造化されたorder_recordsリストをログに記録する
構造化されたorder_recordsリストをログに記録する
Result: レシピの実行後、order_recordsリストには3つの構造化レコードが含まれます。
- Order #1001, Alice, Shipped
- Order #1002, Bob, Pending
- Order #1003, Carol, Delivered
出力スクリーンショットを表示
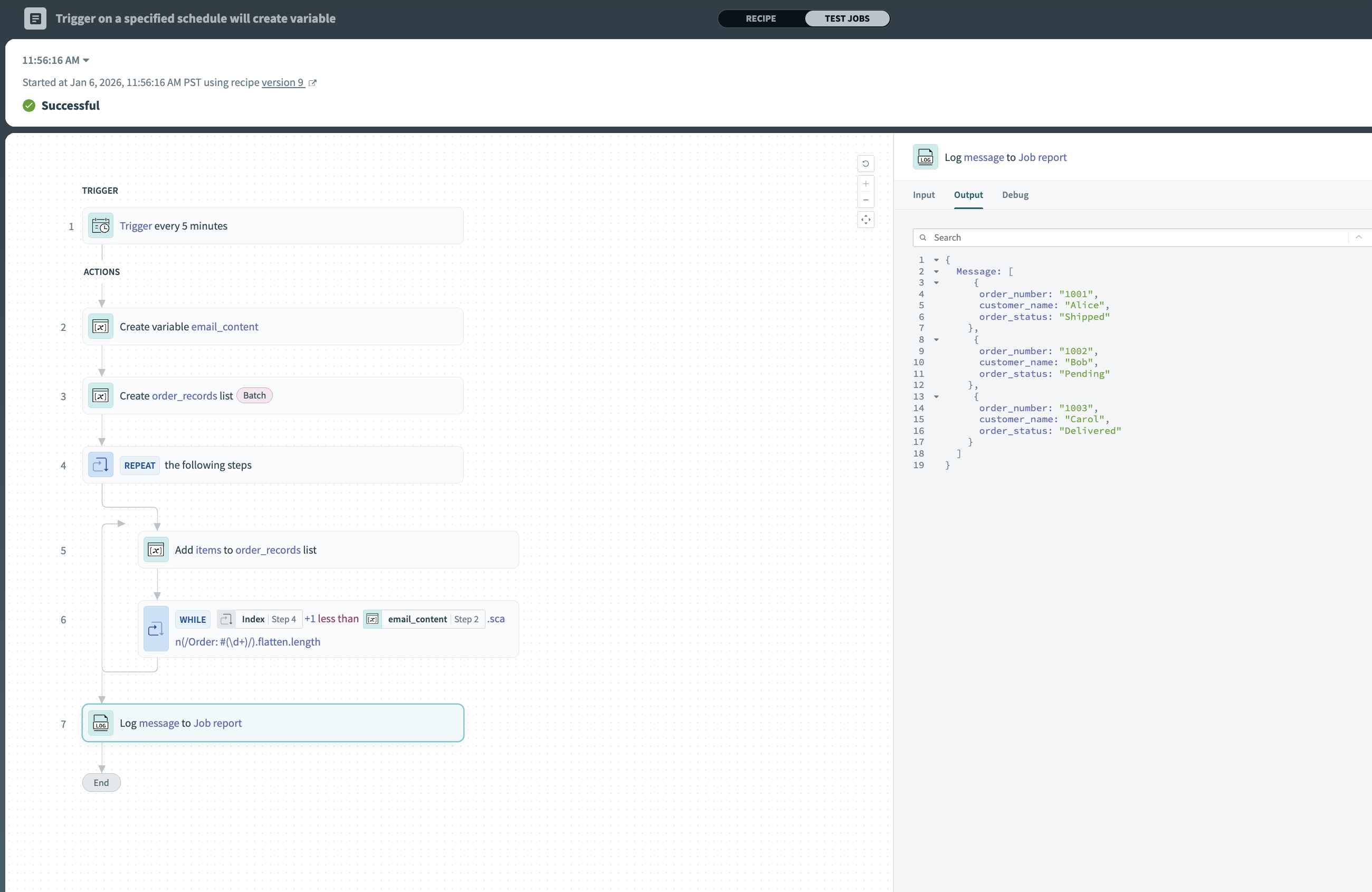 ジョブレポート内の構造化リスト出力
ジョブレポート内の構造化リスト出力
リファレンス
リテラル文字
| リテラル文字 | 説明 |
|---|---|
すべての英字、a~z | 小文字(a-z)に一致します。 |
すべての英字、A~Z | 大文字(A-Z)に一致します。 |
すべての数字、0~9 | 数字(0-9)に一致します。 |
! | 感嘆符に一致します。 |
" | 二重引用符に一致します。 |
# | ハッシュ記号に一致します。 |
% | パーセント記号に一致します。 |
& | アンパサンドに一致します。 |
' | 一重引用符に一致します。 |
, | カンマに一致します。 |
- | ハイフンに一致します(文字クラス内で使用される場合を除く)。 |
: | コロンに一致します。 |
; | セミコロンに一致します。 |
< | 小なり記号に一致します。 |
= | 等号に一致します。 |
> | 大なり記号に一致します。 |
@ | アット記号に一致します。 |
_ | アンダースコアに一致します。 |
` | バッククォートに一致します。 |
~ | チルダに一致します。 |
メタ文字
| メタ文字 | 説明 |
|---|---|
. | 改行(\n)を除く任意の1文字に一致します。 |
^ | Regexを文字列の先頭に固定します。 |
$ | Regexを文字列の末尾に固定します。 |
\ | メタ文字をエスケープし、リテラル文字として使用できるようにします。 |
[] | 文字クラスを定義し、角かっこ内の任意の文字に一致できるようにします。 |
[^] | 否定文字クラスを定義し、角かっこ内にない任意の文字に一致します。 |
- | 文字クラス内の範囲を示します。 |
| | OR演算子として機能し、選択肢を指定できます。 |
() | 式をまとめてグループ化し、量指定子(*、+、?、{})をグループ全体に適用できるようにします。 |
* | 直前の要素の0回以上の出現に一致します。 |
+ | 直前の要素の1回以上の出現に一致します。 |
? | 直前の要素の0回または1回の出現に一致します(オプション)。 |
{} | 直前の要素の正確な出現回数または出現回数の範囲を指定します。 |
\b | 単語境界に一致します。 |
\B | 非単語境界に一致します。 |
\d | 任意の数字文字に一致します([0-9]と同等)。 |
\D | 任意の数字以外の文字に一致します([^0-9]と同等)。 |
\w | 任意の単語文字に一致します(英数字にアンダースコアを加えたもの、[a-zA-Z0-9_]と同等)。 |
\W | 任意の非単語文字に一致します([^a-zA-Z0-9_]と同等)。 |
\s | 任意の空白文字に一致します。 |
\S | 任意の非空白文字に一致します。 |
(?...) | ?の後に続く内容に応じて、非キャプチャグループ、先読み、後読みなどを指定します。 |
最終更新日: