Google BigQuery
Google BigQueryは、インメモリBI Engineと機械学習を組み込んだ、サーバーレスでスケーラビリティが高く、費用対効果に優れたクラウドデータウェアハウスです。
Google BigQueryコネクターを使用すると、行の挿入や既存のデータセットに対するクエリの実行など、Google BigQueryインスタンス内のデータセットに対するアクションを自動化できます。 データセットイベントの新しい行からレシピをトリガーすることもできます。
機能の提供状況
CNデータセンターのワークスペースでは、Google BigQueryコネクターを利用できません。 これは現地の規制要件を反映したものであり、当社のマルチテナントおよびVirtual Private Workato(VPW)サービスに適用されます。
APIバージョン
Google BigQueryコネクターはGoogle BigQuery API v2を使用します。
Google BigQueryへの接続方法
Google BigQueryコネクターは、次の認証方法をサポートしています。
- OAuth 2.0
- サービスアカウント
サービスアカウント認証
サービスアカウントを使用すると、個人ユーザーアカウントなしで認証できます。 一貫した使用のため、Workatoではサービスアカウント認証をお勧めします。
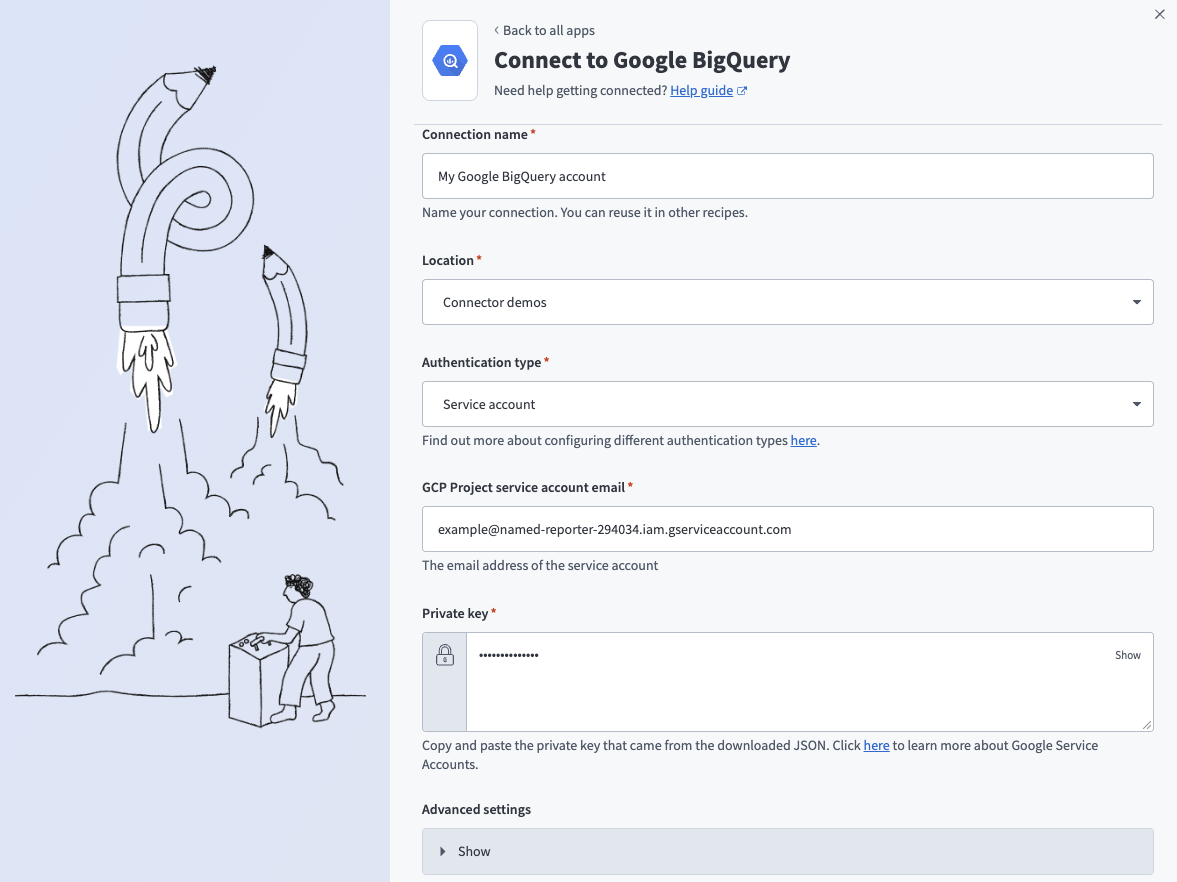
WorkatoでGoogle BigQueryへのコネクションを確立するには、次の手順を実行します。
Google BigQueryコネクターを検索して選択します。
接続先のGoogle BigQueryインスタンスを識別する、コネクションの一意の名前をコネクション名フィールドに入力します。
コネクションを保存する予定のプロジェクトまたはフォルダをロケーションドロップダウンメニューから選択します。
認証タイプドロップダウンメニューからOAuth 2.0またはService accountを選択します。 ユーザーアカウントを使用してGoogle BigQueryに接続する場合は、OAuth 2.0を選択します。 サービスアカウントを使用してGoogle BigQueryに接続する場合は、Service accountを選択します。
サービスアカウント認証に適用されます。 サービスアカウントのメールアドレスをGCPプロジェクトサービスアカウントメールフィールドに入力します。
サービスアカウント認証に適用されます。 サービスアカウントの秘密鍵を秘密鍵フィールドに入力します。
サービスアカウント認証に適用されます。 詳細設定セクションを展開し、コネクションでリクエストするスコープを選択します。
Googleでサインインをクリックします。
WorkatoによるGoogleアカウントへのアクセスを承認するよう求められたら、許可をクリックします。
サービスアカウント認証
Googleサービスアカウントは、Google Cloudプロジェクト(GCP)に関連付けられた専用のGoogleアカウントであり、ユーザーに代わってAPIリクエストを実行できます。
サービスアカウントには次の利点があります:
- 継続的な運用: サービスアカウントにより、個々のユーザー権限が変更された場合でも運用を継続できます。
- 専用の権限: サービスアカウントは、共有先として指定したプロジェクトにのみアクセスできます。
- 専用のAPIクォータ: GCPを通じてサービスアカウントのAPIクォータを管理し、Googleに直接クォータの引き上げをリクエストできます。
サービスアカウントの詳細については、Googleサービスアカウントのドキュメントを参照してください。
Googleサービスアカウントの設定
Googleサービスアカウントを設定するには、次の手順を実行します:
GCPプロジェクトでサービスアカウントを作成します。
IAMと管理>サービスアカウントに移動します。 ダッシュボードのスコープが、サービスアカウントを含むプロジェクトに設定されていることを確認します。 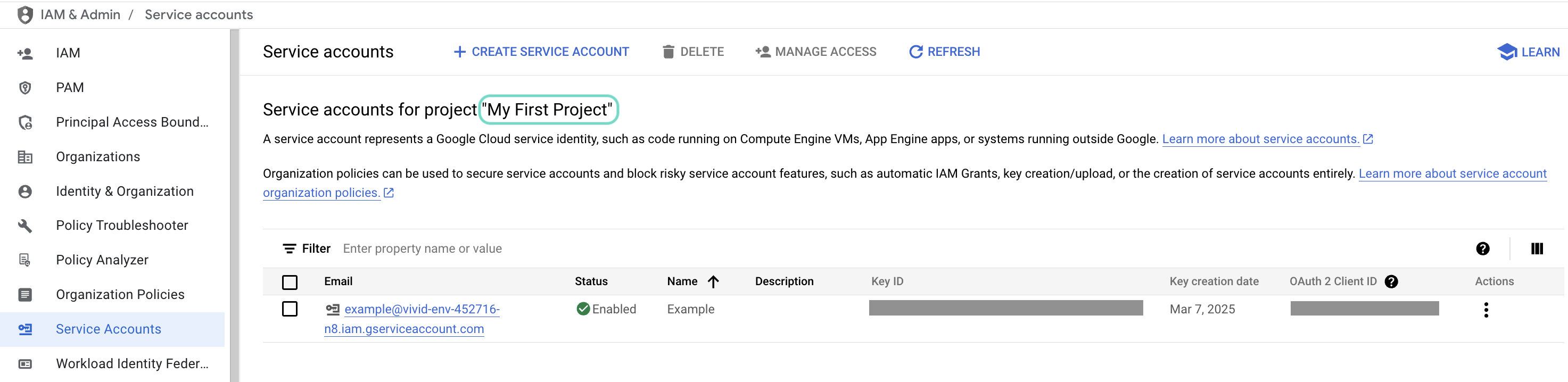 ダッシュボードのスコープを確認します。
ダッシュボードのスコープを確認します。
使用するサービスアカウントのメールをクリックします。 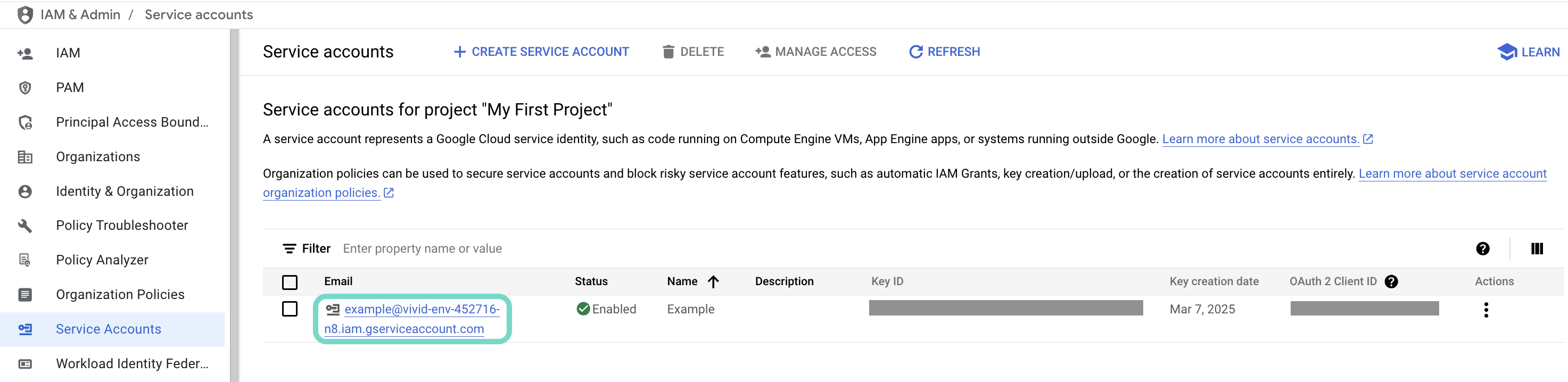 使用するサービスアカウントのメールをクリックします。
使用するサービスアカウントのメールをクリックします。
サービスアカウントのメールをコピーし、後でコネクションを設定するために保存します。 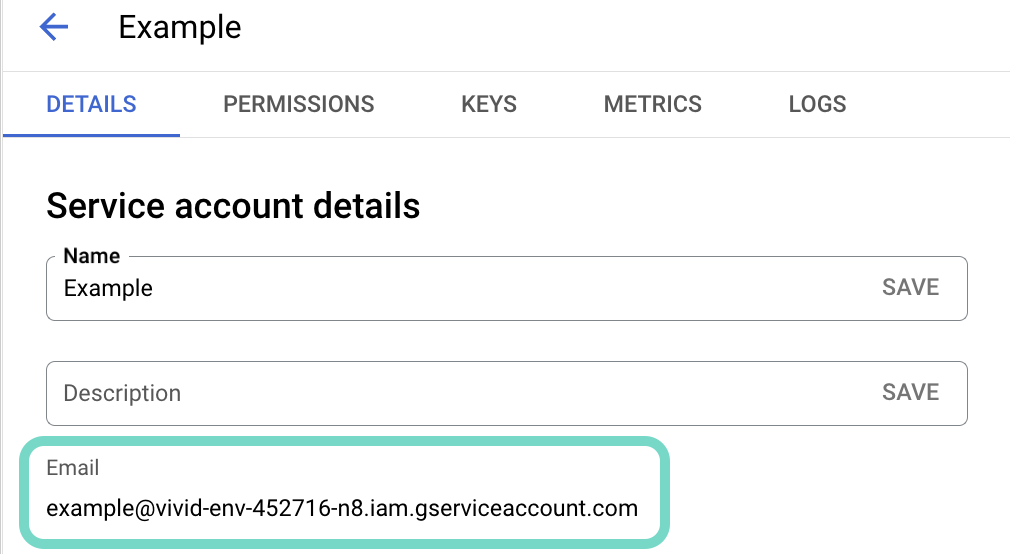 アカウントのメールをコピーします。
アカウントのメールをコピーします。
キータブに移動します。
秘密鍵を生成し、JSON形式でダウンロードします。 キーは1回しかダウンロードできません。
JSONファイルを開き、秘密鍵全体を-----BEGIN PRIVATE KEY-----から-----END PRIVATE KEY-----\nまで(両端を含む)コピーして、後でコネクションを設定するために保存します。
Google BigQuery APIを有効にしてからWorkatoに戻り、コネクションの設定を完了します。
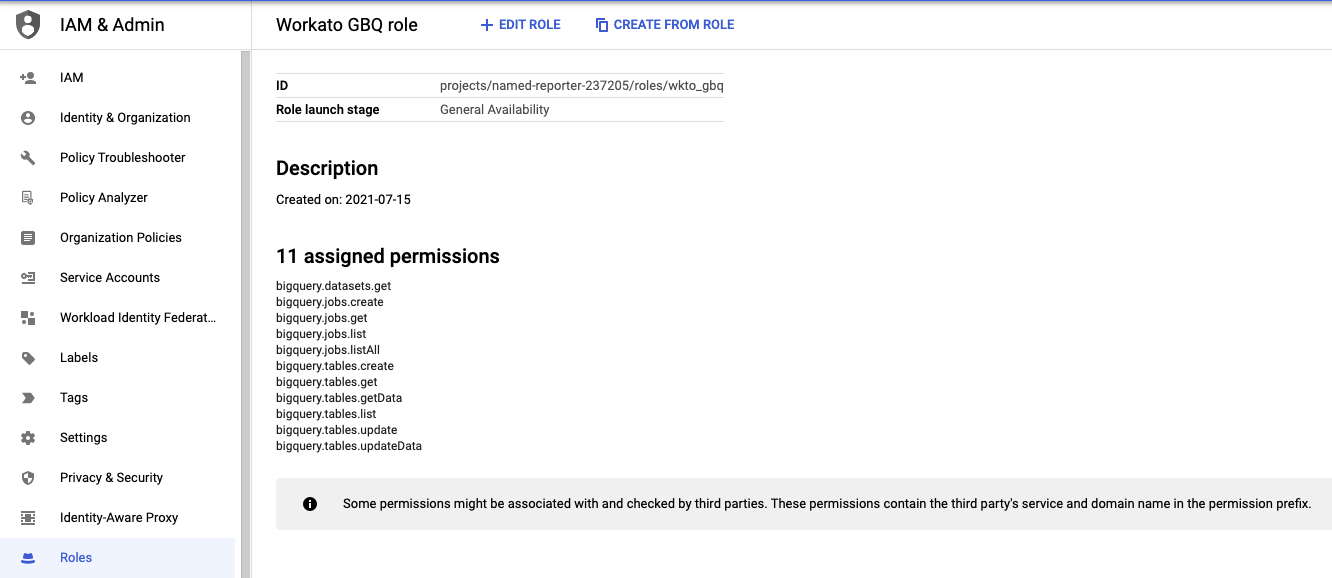
サービスアカウントの権限
Google BigQueryコネクターですべてのトリガーとアクションを使用するには、サービスアカウントにBigQuery Admin IAMロール、または次の権限を持つカスタムロールを付与する必要があります。
- bigquery.datasets.get
- bigquery.jobs.create
- bigquery.jobs.get
- bigquery.jobs.list
- bigquery.jobs.listAll
- bigquery.tables.create
- bigquery.tables.get
- bigquery.tables.getData
- bigquery.tables.list
- bigquery.tables.update
- bigquery.tables.updateData
TIP
Workatoでこのコネクションを使用してデータの挿入のみを行う場合は、次のようにします。
BigQuery Data Editorロールを使用します。- bigquery.jobs.create権限を追加します。
Workatoでこのコネクションを使用してデータの選択のみを行う場合は、次のようにします。
BigQuery Data Viewerロールを使用します。- bigquery.jobs.create権限を追加します。
詳細については、カスタムロールの作成およびGoogle BigQueryの権限に関するGoogleのドキュメントを参照してください。
サービスアカウントとカスタムロール
サービスアカウントにカスタムロールを使用している場合は、プロジェクトIDをWorkatoで直接指定する必要があります。 指定しない場合、プロジェクトを選択ドロップダウンメニューが設定で読み込まれないため、プロジェクトIDを手動で指定する必要があります。
Google BigQueryのレート制限
テーブルに関するGoogle BigQueryのレート制限では、テーブルに対するbulk挿入操作は1日に1000回までしか実行できないことが示されています。 これらの制限を回避するには、Insert rowおよびInsert rowsアクションを使用します。
Google BigQueryコネクターの使用
Google BigQueryコネクターでコネクションを確立した後、ほとんどのアクションでは追加のパラメーター入力が必要です。
| フィールド | 説明 |
|---|---|
| プロジェクト | クエリの課金対象となるプロジェクト。 |
| データセット | アクションまたはトリガーが使用可能なテーブルを取得するデータセット。 |
| テーブル | データセット内のテーブル。 |
| 場所 | ジョブを実行する地理的ロケーション。 |
単一行と行のバッチの比較
Google BigQueryコネクターは、単一行またはバッチのいずれかでデータベースの読み取りまたは書き込みを行うことができます。 バッチ読み取りアクションまたはトリガーを使用する場合は、バッチサイズを指定する必要があります。 バッチサイズは1~50000の任意の数値にでき、最大バッチサイズは50000です。
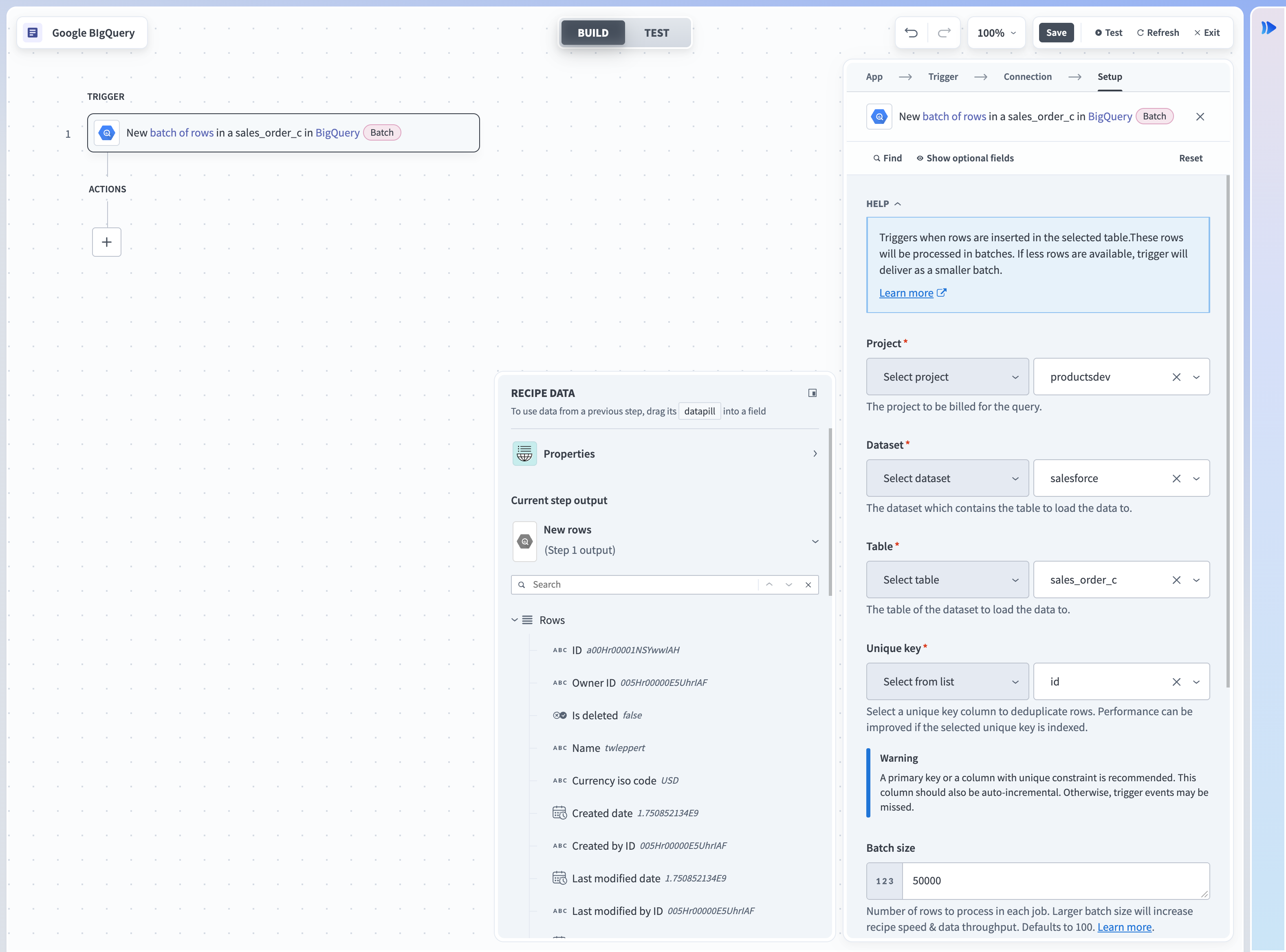 バッチトリガー入力
バッチトリガー入力
単一トリガーおよびバッチトリガー、単一アクションおよびバッチアクションの出力も異なります。 たとえば、行を1つずつ処理する単一トリガーは、その単一行からデータをマッピングできる出力データツリーを返します。
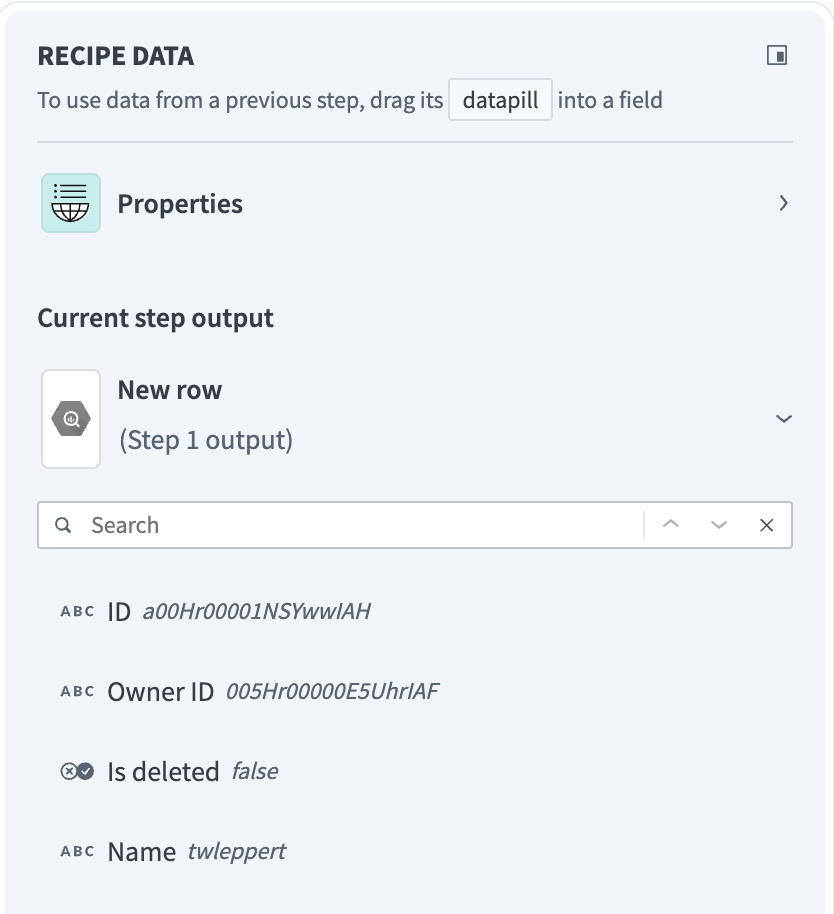 単一行出力
単一行出力
行をバッチで処理するバッチトリガーは、このデータを行の配列として返します。 行データピルは、出力がそのバッチ内の各行のデータを含むリストであることを示します。
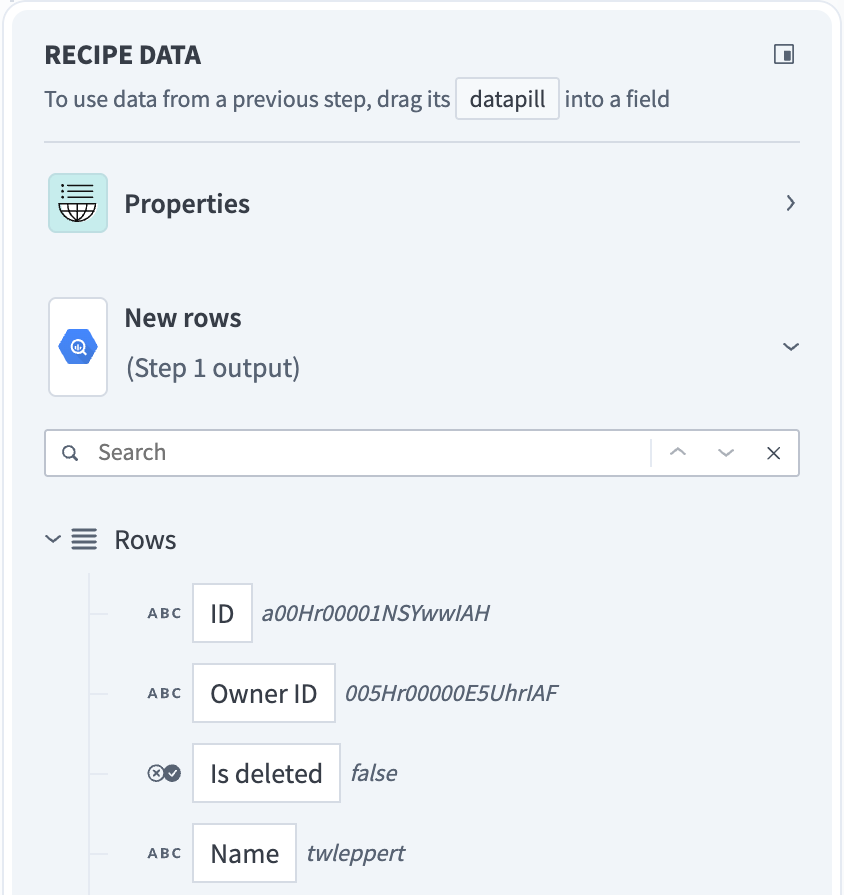 バッチトリガー出力
バッチトリガー出力
バッチトリガーまたはアクションの出力は、異なる方法で処理する必要があります。 下流のバッチアクションが行のソースリスト入力フィールドを受け入れる場合、行データピルをマッピングして配列全体を処理できます。
WHERE条件
WHERE条件入力フィールドを使用すると、操作対象の行をフィルタリングして特定できます。 このフィールドは、次のように設定できます。
- トリガーで取得する行をフィルタリング
- 行を選択アクションで行をフィルタリングする
- 行を削除アクションで削除する行をフィルタリングする
各リクエストでは、この句がWHEREステートメントとして使用されます。 これは基本的なSQL構文に従う必要があります。 Google BigQueryと互換性のあるSQLステートメントを記述するためのルールの完全なリストについては、Google BigQueryドキュメントを参照してください。
単純なステートメント
動作するクエリを作成するには、Google BigQueryの列のデータ型を把握しておくことが重要です。 文字列値を比較する場合は、値を一重引用符('')で囲む必要があり、使用する列はテーブル内に存在している必要があります。 整数値を比較する場合、指定する値を一重引用符で囲まないでください。
単一列の値に基づいて行をフィルタリングする単純なWHERE条件は、次のようになります。
string_column = 'USD' and integer_column = 1111行を選択アクションで使用した場合、このWHERE条件は、currency列に値'USD'を持つすべての行を返します。 入力では、データピルを一重引用符で囲むことを忘れないでください。
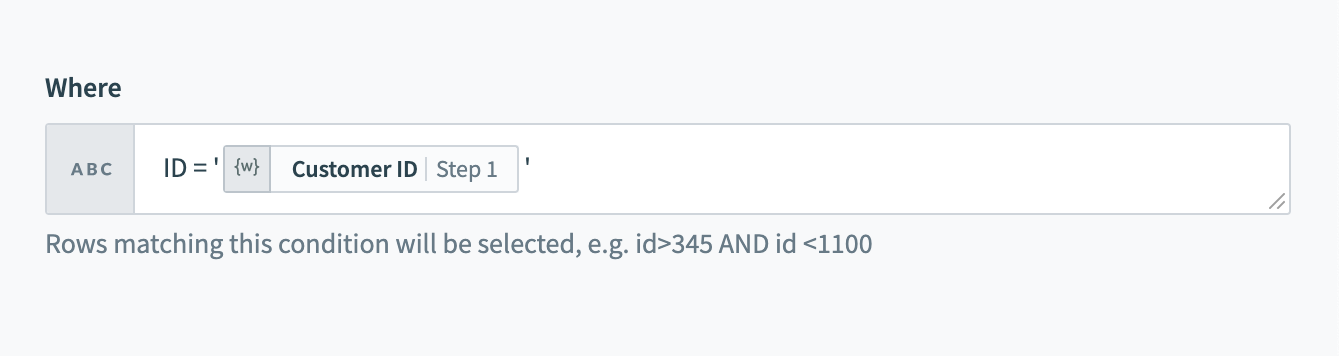
WHERE条件でのデータピルの使用
複雑なステートメント
WHERE条件にはサブクエリを含めることもできます。 次のクエリはusersテーブルで使用できます。
id in (select distinct(user_id) from zendesk.tickets where priority = 2)行を削除アクションで使用した場合、このクエリは、関連付けられたticketsテーブル内の少なくとも1つの行のpriority列に値2があるusersテーブル内のすべての行を削除します。
出力フィールドの定義
一部のGoogle BigQueryアクションとトリガーでは、クエリの想定される出力列を定義できます。 この入力フィールドは、次のトリガーとアクションで使用できます。
- スケジュール済みクエリトリガー
- クエリジョブ出力の取得
- カスタムSQLを使用した行の選択
CSVアップローダーを使用して、出力スキーマデザイナーで出力フィールドを定義します。 このような場合は、Google BigQueryコンソールでサンプルクエリを実行し、CSVをエクスポートします。
このCSVをスキーマウィザードにアップロードすると、Workatoがすべてのフィールドを自動的に生成します。
最終更新日: