Google BigQuery - 新規行トリガー
新規行トリガー
新規行トリガーは、選択したテーブルに挿入された行を取得します。 各行は個別のジョブとして処理されます。 各ポーリング間隔で新しい行をチェックします。
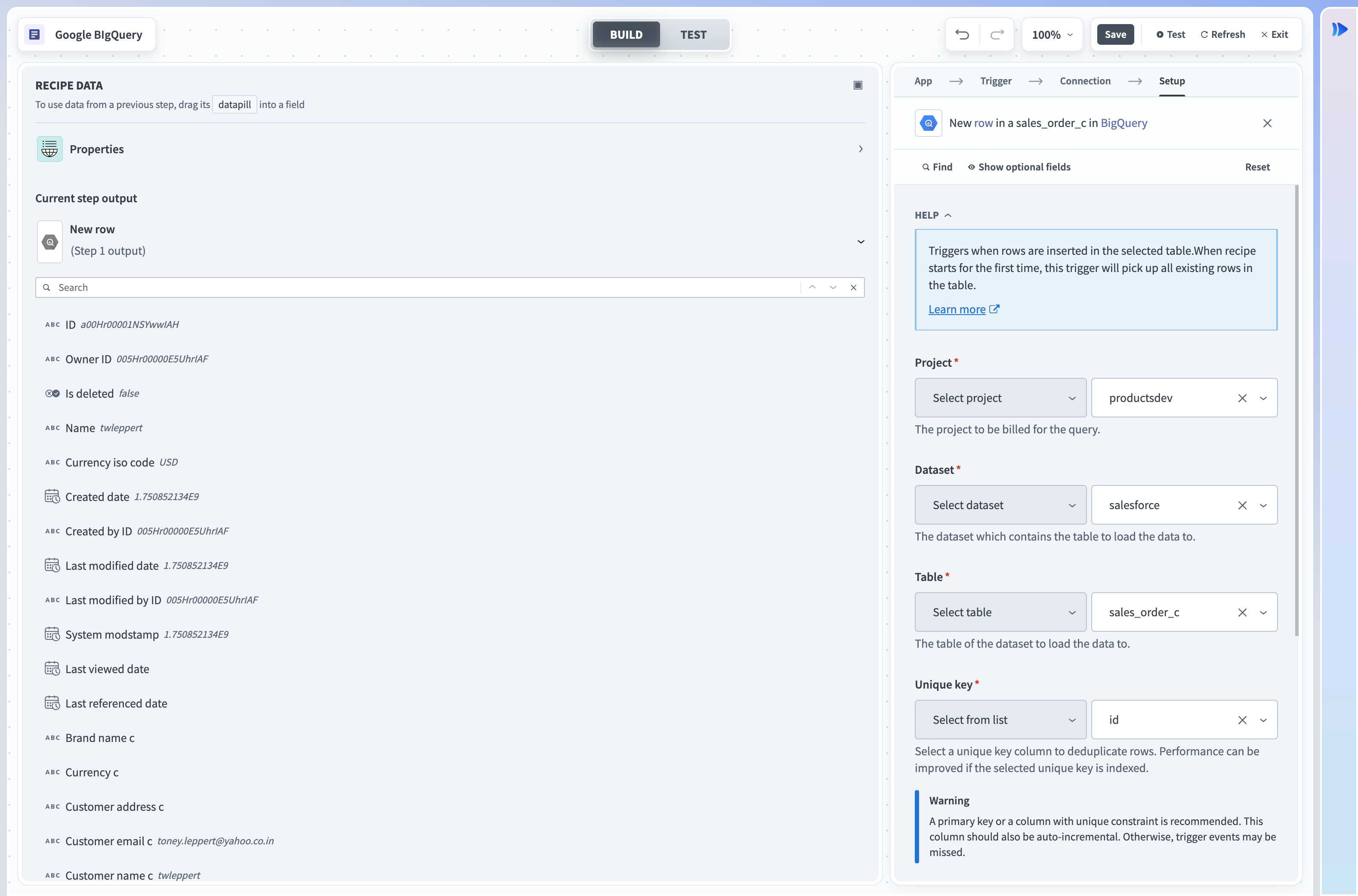 新規行トリガー
新規行トリガー
入力
| 入力フィールド | 説明 |
|---|---|
| プロジェクト | クエリに課金するプロジェクトを選択します。 |
| データセット | テーブルの取得元となるデータセットを選択します。 |
| テーブル | データセット内のテーブルを選択します。 |
| テーブルフィールド | テーブルIDがデータピルの場合にのみ必要です。 テーブルの列を宣言するテーブルフィールドを選択します。 これはデータピルのすべての可能な値で同じである必要があります。 |
| 一意キー | 選択したテーブル内の行を重複除外するには、この列から値を選択し、同じレシピ内で同じ行が2回処理されないようにします。 テーブル内の選択した列で値を繰り返さないでください。 この列はinteger型である必要があります。 |
| 出力列 | テーブルを選択した後、返される列を選択することもできます。 レシピに必要なものだけを選択すると、ジョブのスループットとレシピ全体の効率が向上します。 |
| WHERE条件 | 詳細については、WHERE条件ガイドを参照してください。 |
| 場所 | ジョブを実行する地理的ロケーションを選択します。 ほとんどの場合、このフィールドは必須ではありません。 |
| Standard SQLを使用 | Standard SQLまたはlegacy SQLのどちらを使用するかを指定します。 |
出力
| 出力フィールド | 説明 |
|---|---|
| 列 | Workatoはテーブルのスキーマをイントロスペクトし、各列の値をデータピルとして返します。 |
新規行バッチトリガー
このトリガーは、選択したテーブルまたはビューに挿入された行を取得します。 これらの行は、各ジョブで行のバッチとして処理されます。 このバッチサイズは、トリガー入力で設定できます。 各ポーリング間隔で新しい行をチェックします。
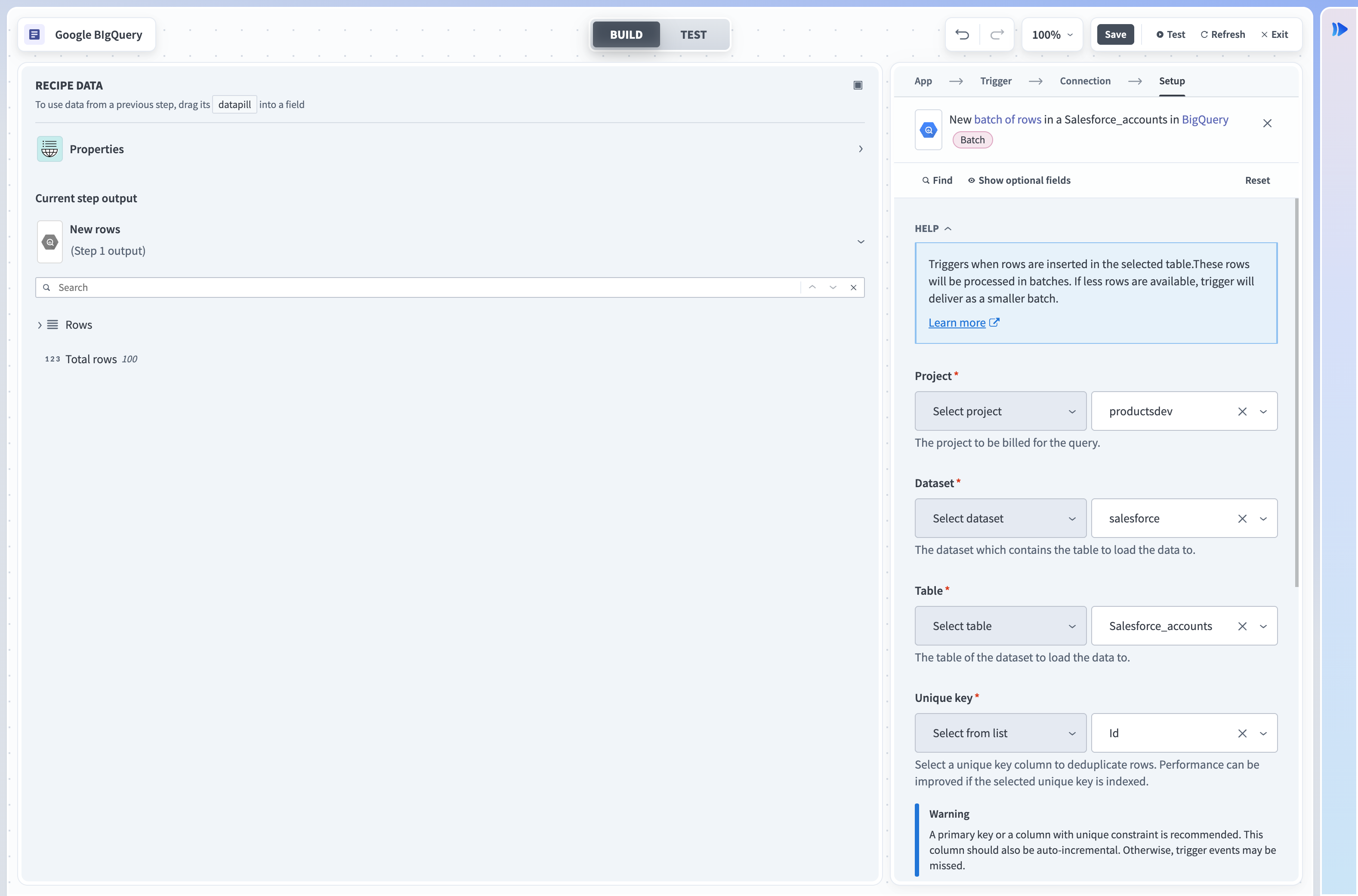 新規行バッチトリガー
新規行バッチトリガー
入力
| 入力フィールド | 説明 |
|---|---|
| プロジェクト | クエリに課金するプロジェクトを選択します。 |
| データセット | 使用可能なテーブルを取得するデータセットを選択します。 |
| テーブル | データセット内のテーブル。 |
| テーブルフィールド | テーブルIDがデータピルの場合にのみ必要です。 テーブルの列を宣言するテーブルフィールドを選択します。 これはデータピルのすべての可能な値で同じである必要があります。 |
| 一意キー | 選択したテーブル内の行を重複除外するには、この列から値を選択し、同じレシピ内で同じ行が2回処理されないようにします。 テーブル内の選択した列で値を繰り返さないでください。 この列はinteger型である必要があります。 |
| 出力列 | 返される列を選択します。 レシピに必要なものだけを選択すると、ジョブのスループットとレシピ全体の効率が向上します。 |
| バッチサイズ | 各ジョブで返される行のバッチサイズを選択します。 これは1~50,000の範囲で設定でき、デフォルトは50,000です。 バッチサイズを大きくすると、データスループットが向上します。 バッチサイズを超える新規行が見つかった場合、すべての新規行が処理されるまで複数のジョブが作成されます。 |
| WHERE条件 | 詳細については、WHERE条件ガイドを参照してください。 |
| 場所 | ジョブを実行する地理的ロケーションを選択します。 ほとんどの場合、このフィールドは必須ではありません。 |
| Standard SQLを使用 | Standard SQLまたはlegacy SQLのどちらを使用するかを指定します。 |
出力
| 出力フィールド | 説明 |
|---|---|
| 行 | 行の配列。 行内の各データピルは1つの列に対応します。 |
| 合計行数 | このポーリングで返された行の合計数。 |
最終更新日: