Google BigQuery: Google BigQueryへの行の挿入
データソースで大量のデータが生成され、そのデータを頻繁にBigQueryへストリーミングする必要がある場合、Google BigQueryへの行の挿入が役立ちます。 Workatoでは、そのために2つのアクションを提供しています:
データの一括エクスポートが可能なデータソースで、より長い間隔(数時間から数日)でのみデータが必要な場合は、行単位でより高速な取り込みと少ないタスク数を保証するload fileアクションの使用を検討してください。
行の挿入
Insert rowアクションは、ストリーミングを使用してGoogle BigQueryのテーブルに単一行を挿入します。 1日にストリーミングできる行数に制限はありません。 行がストリーミングされると、このデータがコピーおよびエクスポート操作で利用可能になるまでに最大90分かかることがあります。
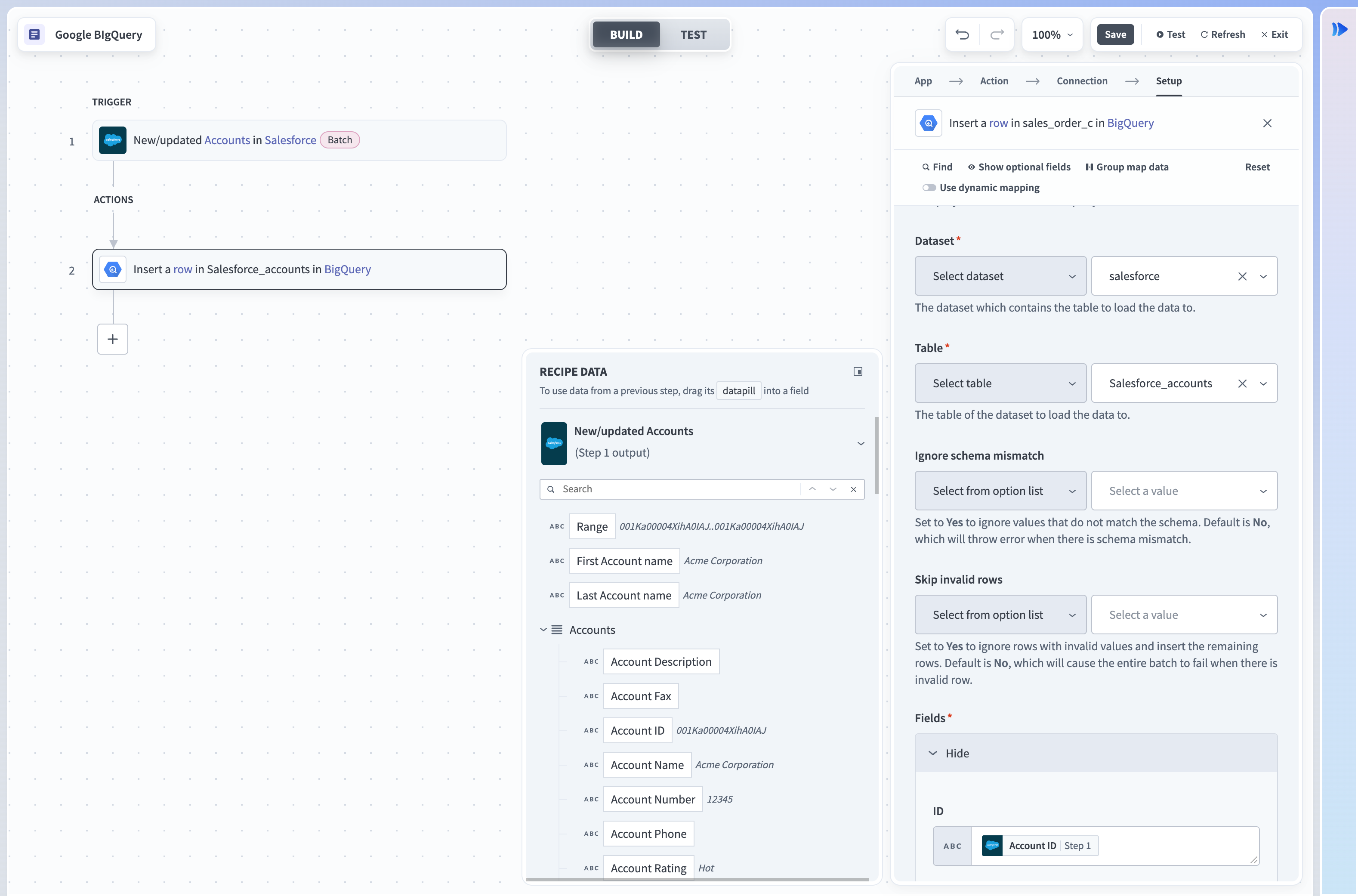 Insert rowアクション
Insert rowアクション
入力
| 入力フィールド | 説明 |
|---|---|
| プロジェクト | クエリに課金するプロジェクトを選択します。 |
| データセット | 使用可能なテーブルを取得するデータセットを選択します。 |
| テーブル | データセット内のテーブルを選択します。 |
| テーブルフィールド | テーブルIDがデータピルの場合にのみ必要です。 テーブルの列を宣言します。 これはデータピルのすべての可能な値で同じである必要があります。 |
| スキーマ不一致を無視 | このフィールドにはYesまたはNoのいずれかを選択します。 Noに設定し、ストリーミングされた値が想定されるデータ型と一致しない場合、Workatoはエラーを返します。 これらの行を無視するには、Yesに設定します。 |
| フィールド | 選択したテーブルの列を選択します。 |
| Insert ID | Insert IDを指定します。 これは、ストリーミング時に行を重複除外するために使用されます。 Insert IDが同一の場合、Google BigQueryは行を再度ストリーミングしません。 |
出力
| 出力フィールド | 説明 |
|---|---|
| エラー | insert row操作中に発生したすべてのエラーが含まれます。 |
行をバッチで挿入
Insert rows in batchesアクションは、ストリーミングを使用してGoogle BigQueryのテーブルに行のバッチを挿入します。 1日にストリーミングできる行数に制限はありません。 行がストリーミングされると、このデータがコピーおよびエクスポート操作で利用可能になるまでに最大90分かかることがあります。 行の挿入に関する詳細については、このサンプルレシピを参照してください。
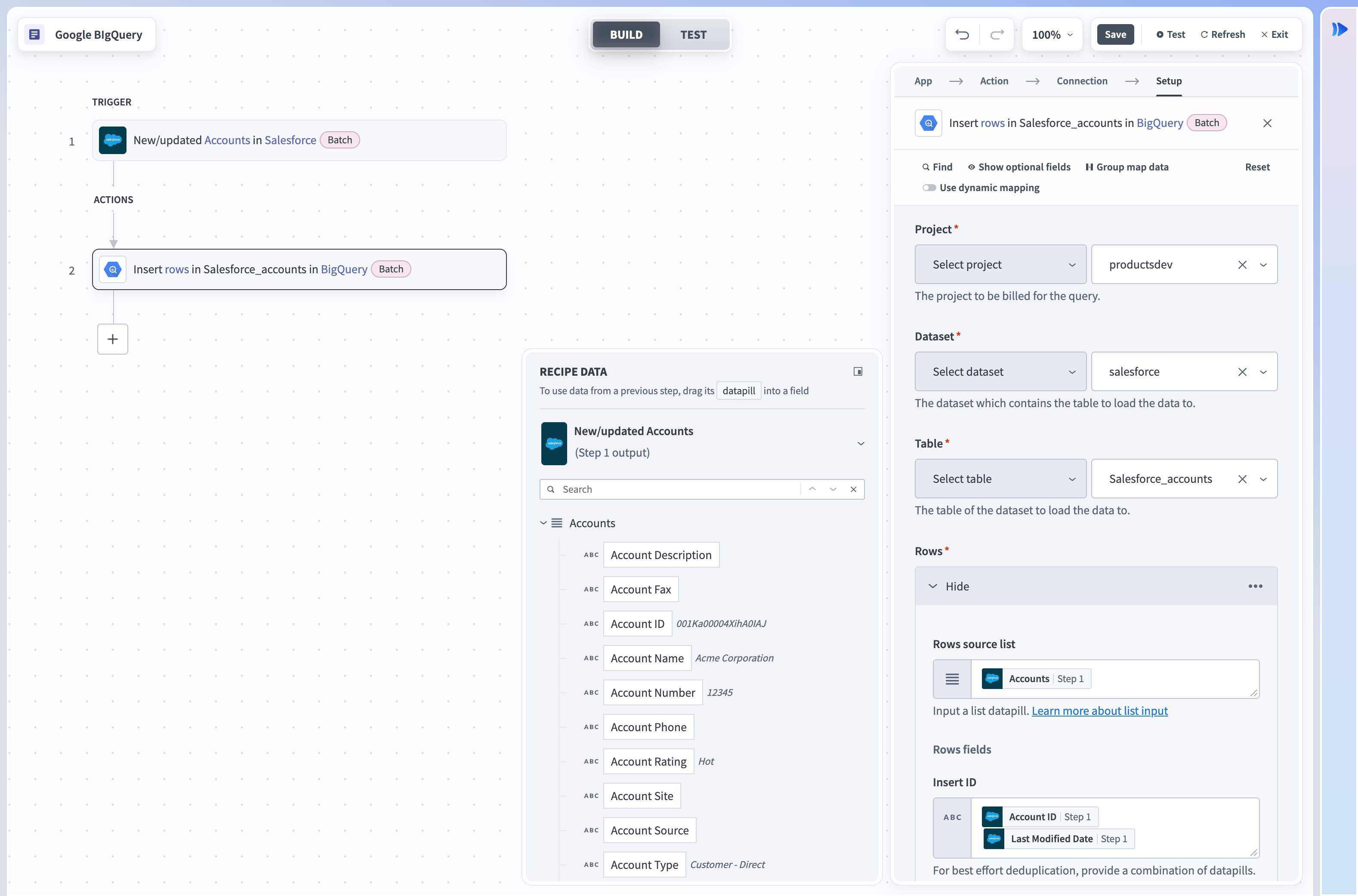 Insert rowsアクション
Insert rowsアクション
入力
| 入力フィールド | 説明 |
|---|---|
| プロジェクト | クエリに課金するプロジェクトを選択します。 |
| データセット | 使用可能なテーブルを取得するデータセットを選択します。 |
| テーブル | データセット内のテーブルを選択します。 |
| テーブルフィールド | テーブルIDがデータピルの場合にのみ必要です。 テーブルの列を宣言するテーブルフィールドを選択します。 これはデータピルのすべての可能な値で同じである必要があります。 |
| スキーマ不一致を無視 | このフィールドにはYesまたはNoを選択します。 Noに設定し、想定されるデータ型と一致しない値がストリーミングされた場合、Workatoはエラーを返します。 これらの行を無視するには、Yesに設定します。 |
| フィールド | 選択したテーブルの列を選択します。 |
| Insert ID | Insert IDを指定します。 これは、ストリーミング時に行を重複除外するために使用されます。 Insert IDが同一の場合、Google BigQueryは行を再度ストリーミングしません。 |
出力
| 出力フィールド | 説明 |
|---|---|
| 挿入エラー | batch insert row操作のエラーが含まれます。 |
| 失敗した行 | 失敗した各行に関するデータが含まれます。 行のストリーミングを再試行するには、これを使用します。 |
最終更新日: