OpenAI - 録音の文字起こしアクション
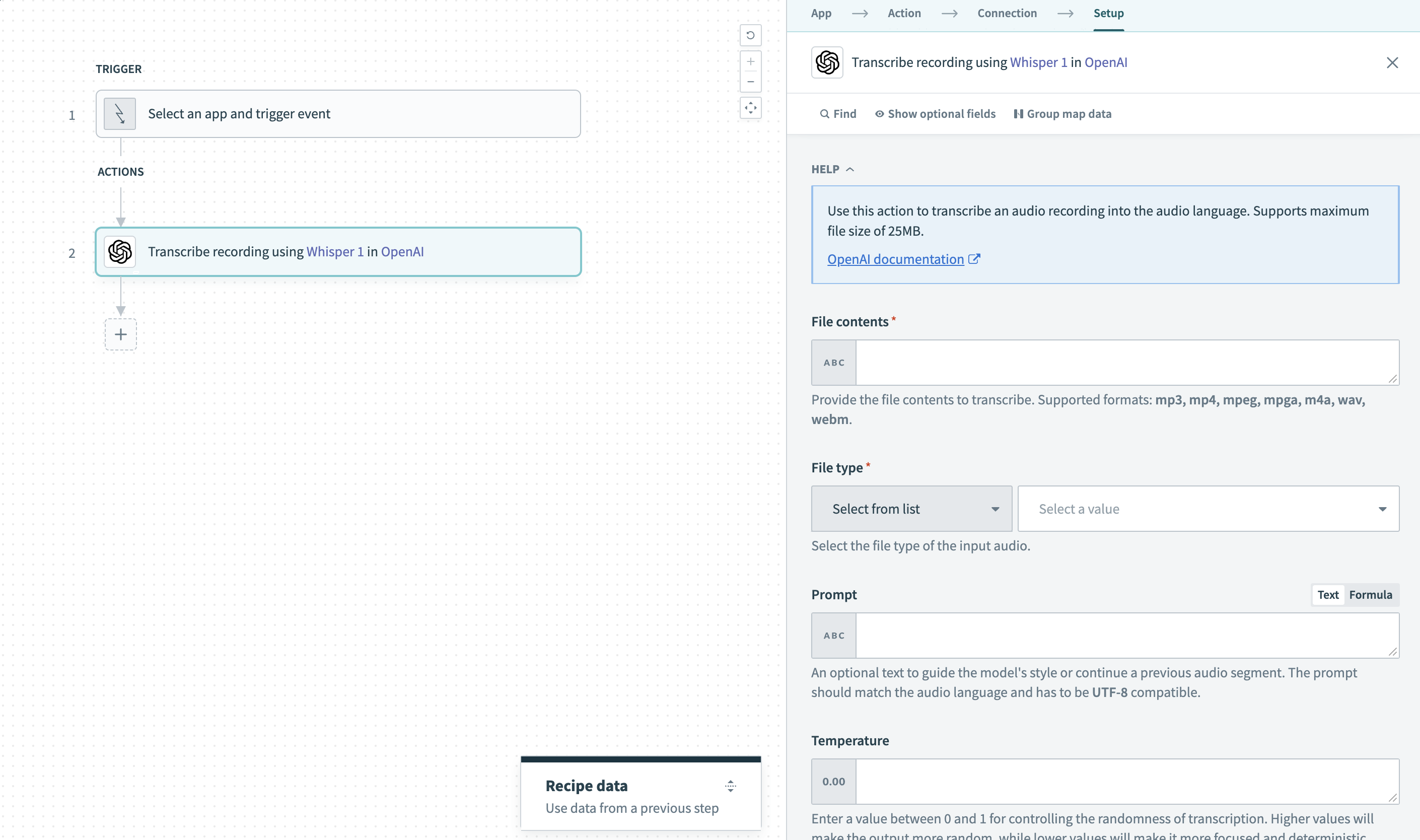 録音の文字起こしアクション
録音の文字起こしアクション
入力
| フィールド | 説明 |
|---|---|
| ファイルの内容 | 文字起こしするファイルの内容を指定します。 サポートされている形式:mp3、mp4、mpeg、mpga、m4a、wav、webm。 |
| ファイルタイプ | 文字起こしする入力のファイルタイプを選択します。 |
| プロンプト | モデルのスタイルを導く、または前の音声セグメントを続行するための任意のテキストです。 文字起こし時にモデルに追加のコンテキストを提供し、特定の単語やフレーズを省略、含める、または表記する方法を指定するのに役立ちます。 詳細については、OpenAIのspeech-to-text prompting guideを参照してください。 プロンプトは英語で、UTF-8と互換性がある必要があります。 |
| Temperature | 通常は値を0に設定することをお勧めします。 0~2の値を設定して、補完のランダム性を制御できます。 値を高くすると出力のランダム性が高まり、値を低くするとより焦点が絞られ、決定的になります。 これまたはtop pのどちらかを使用し、両方は使用しないことをお勧めします。 |
出力
出力は、文字起こしされたテキストを含むデータピルです。 これは後続のアクションで直接使用することも、追加処理のためにテキストベースのOpenAIモデルに送信することもできます。
エンドポイントの機能
このエンドポイントは、他の言語のテキストの文字起こしにも役立つことが確認されています。 たとえば、入力言語が日本語の場合、文字起こしされたテキストも日本語になります。 これは、エンドポイントの文書化されていない機能のようです。 エンドポイントはベータ版であるため、動作が変更される可能性があるため、これを重要なワークフローの一部として利用することはお勧めしません。
最終更新日: