OpenAI - 録音翻訳アクション
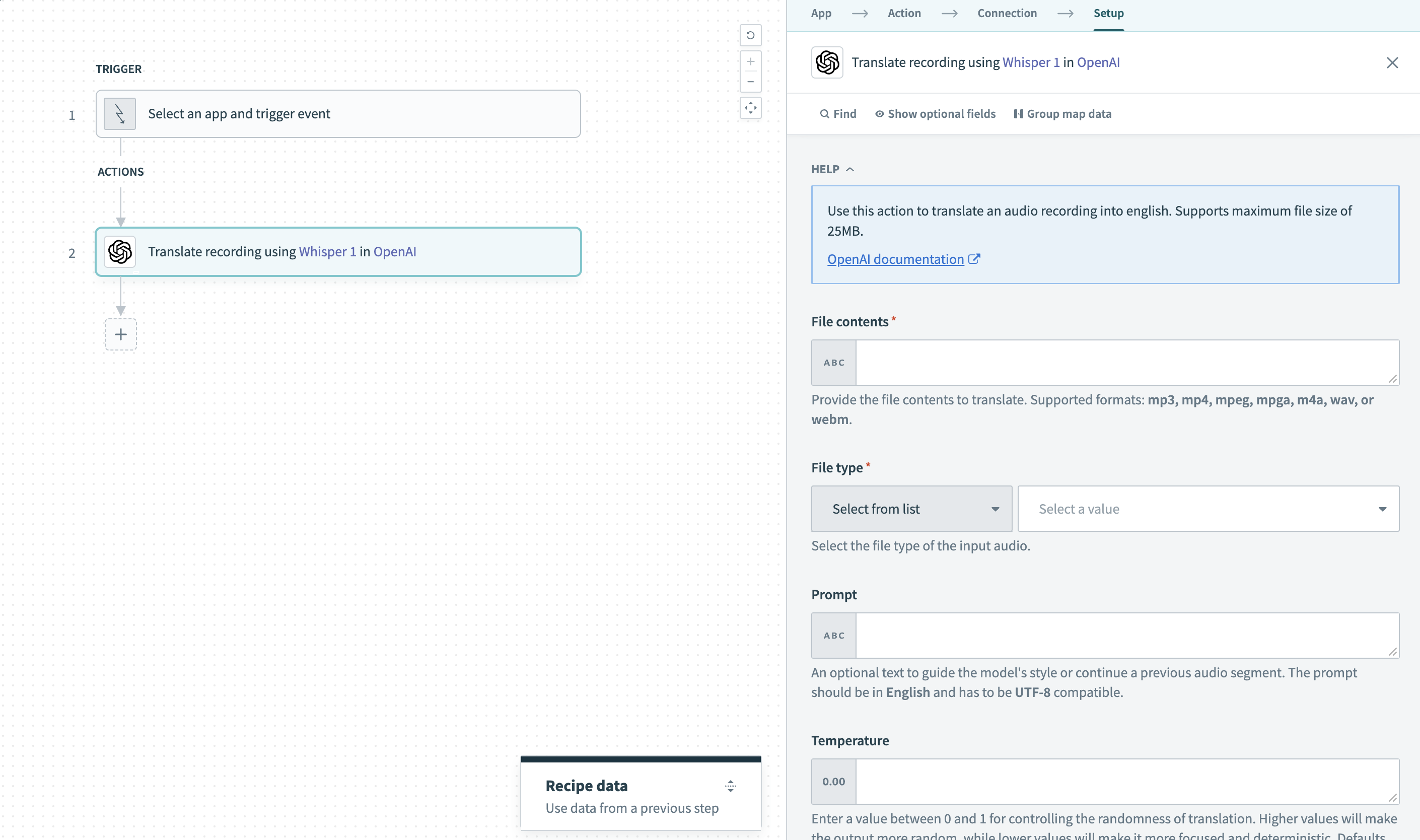 録音翻訳アクション
録音翻訳アクション
入力
| フィールド | 説明 |
|---|---|
| ファイルの内容 | 翻訳するファイルの内容を指定します。 サポートされている形式は、mp3、mp4、mpeg、mpga、m4a、wav、またはwebmです。 |
| ファイルタイプ | 翻訳する入力のファイルタイプを選択します。 |
| プロンプト | モデルのスタイルを導く、または前の音声セグメントを続行するための任意のテキストです。 文字起こし時にモデルへ追加のコンテキストを提供し、特定の単語やフレーズを省略、含める、または特定の方法で記述するよう指定するのに役立ちます。 詳細については、OpenAIのspeech-to-text prompting guideを参照してください。 プロンプトは英語で、UTF-8互換である必要があります。 |
| Temperature | 通常は値を0に設定することをお勧めします。 0~2の値を設定して、補完のランダム性を制御できます。 値を高くすると出力のランダム性が高まり、値を低くするとより焦点が絞られ、決定的になります。 これまたはtop pのどちらかを使用し、両方は使用しないことをお勧めします。 |
出力
出力は、翻訳されたテキストを含むデータピルです。 これは後続のアクションで直接使用することも、追加処理のためにテキストベースのOpenAIモデルに送信することもできます。
最終更新日: