S3 Data Lake - データのインポートアクション
データのインポートアクションは、AWS Glueジョブを使用してS3ファイルからIcebergテーブルにデータをロードします。 このアクションを使用して、Icebergベースのデータレイクへのバッチインポートを実行できます。
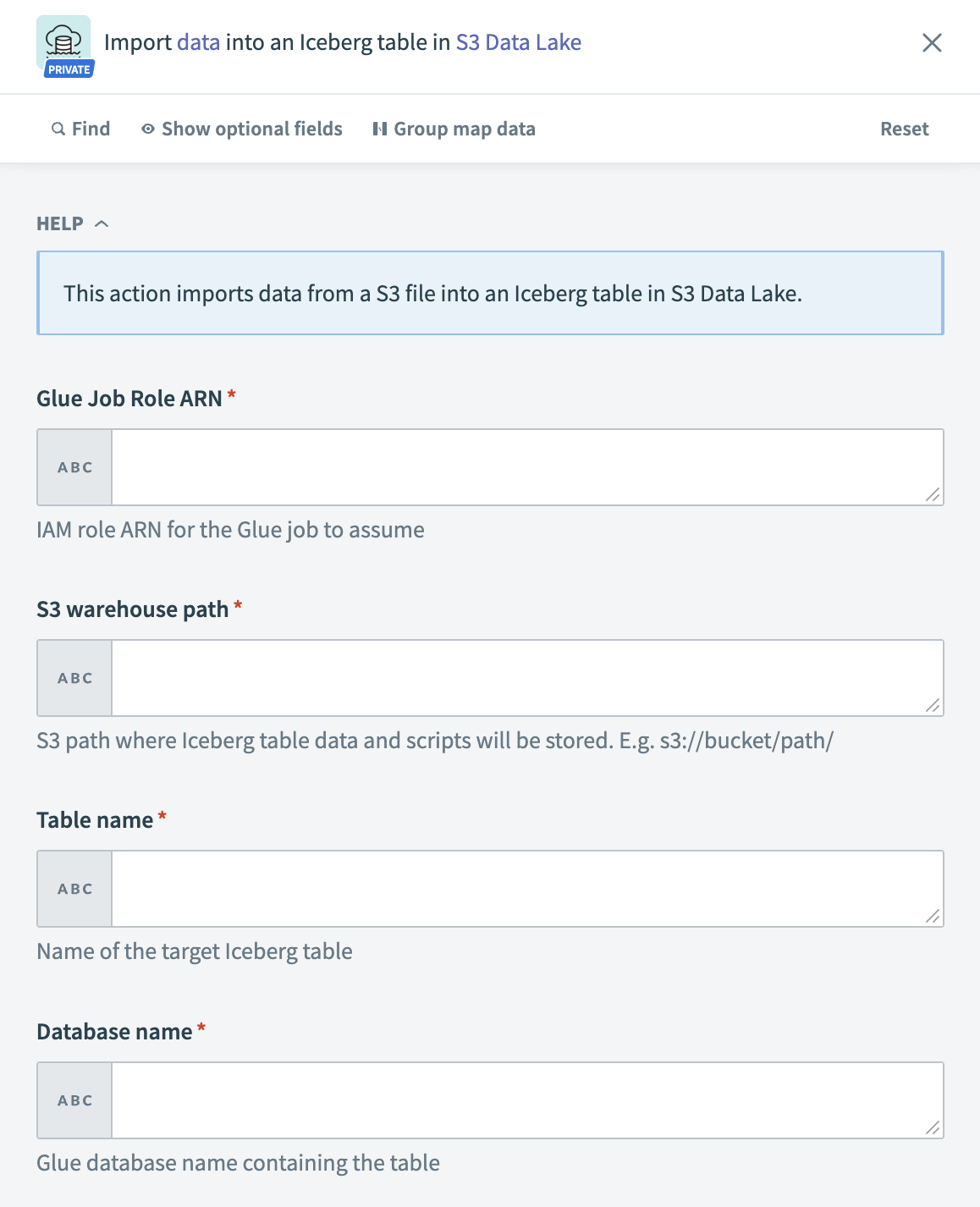 S3 Data Lake - データのインポートアクション
S3 Data Lake - データのインポートアクション
入力
| 入力フィールド | 説明 |
|---|---|
| GlueジョブロールARN | Glueジョブが引き受けるIAMロールARNを入力します。 |
| S3ウェアハウスパス | Icebergテーブルデータおよびスクリプトが保存されているS3パスを入力します。 例:s3://bucket/path/。 |
| テーブル名 | ターゲットIcebergテーブルの名前を入力します。 |
| データベース名 | テーブルを含むGlueデータベースを入力します。 |
| S3ファイルパス | インポートするファイルへの完全なS3パスを入力します。 例:s3://bucket/path/file.csv。 |
| ファイル形式 | ソースファイルの形式を選択します。 |
| CSV区切り文字 | CSVファイルで使用される区切り文字を指定します。 ファイル形式がCSVの場合にのみ適用されます。 空白の場合、デフォルトはカンマ(,)です。 |
| ヘッダーあり | CSVファイルに列名を含むヘッダー行が含まれるかどうかを指定します。 ファイル形式がCSVの場合にのみ適用されます。 |
| Glueバージョン | 使用するAWS Glueバージョンを選択します。 空白の場合、デフォルトは4.0です。 |
| ワーカータイプ | ジョブのAWS Glueワーカータイプを選択します。 |
| ワーカー数 | 使用するワーカー数を入力します。 空白の場合、デフォルトは2です。 |
出力
| 出力フィールド | 説明 |
|---|---|
| ジョブ実行ID | Glueジョブ実行の一意のID。 |
| ジョブ名 | トリガーされたGlueジョブの名前。 |
| Status | Glueジョブのステータス(SUCCEEDEDやFAILEDなど)。 |
| ソースファイルパス | インポートされたファイルのS3パス。 |
| エラーメッセージ | ジョブ実行中に返されたエラーメッセージ(ある場合)。 |
| 開始日時 | Glueジョブが開始された日時のタイムスタンプ。 |
| 完了日時 | Glueジョブが完了した日時のタイムスタンプ。 |
最終更新日: