基本情報
要求の実行
カスタムアダプターフレームワークでは、アプリケーションに HTTP/HTTPS によって API アクセス可能なアダプターを作成できます。一般的な要求/応答形式が、JSON (デフォルト)、XML、および www-form-urlencoded でサポートされます。
アダプターの要求を実行する部分では、HTTP 動詞 (GET、POST など) が Ruby メソッドとしてサポートされています。ここで、ある API の例について考えます。その API では、トークンを URL パラメータとして渡す単純な認証を使用し、冗長な customer JSON オブジェクトでラップされた顧客レコードを返します。このラップは、アダプターを使用するレシピ作者にとって使いにくいので、アダプターで削除したいと考えています。
GET https://api.my-app.com/v1/customers.json?id=1234&api_token=xyz
{
"customer": {
"id": 1234,
"name": "John Smith",
"email": "[email protected]",
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA",
"zip": "94321",
"country": "USA"
}
}
}上のコードを実行する要求は、カスタムアダプターでは、次のように記述できます。
get('https://api.my-app.com/v1/customers.json?id=1234&api_token=xyz')['customer']または次のように記述できます。
get('https://api.my-app.com/v1/customers.json').params(id: 1234, api_token: 'xyz')['customer']要求の実行
では、上の要求の2番目の形式を部分ごとに分けて見てみましょう。
get('https://api.my-app.com/v1/customers.json').params(id: 1234, api_token: 'xyz')['customer']これは、次の3つのメソッド呼び出しを連結しています。
ベース要求を作成する。
要求のオプションを追加する。
応答にアクセスし、その時点で要求が遅延実行される。
ベース要求
GET https://api.my-app.com/v1/customers.json
get('https://api.my-app.com/v1/customers.json')要求はまだ実行されていません。ここまでの結果は、ベース URL へきっかけとなる指示を出す要求です。要求および予期される応答の形式はデフォルトの JSON に設定されています。
要求のオプションを追加する
id=1234&api_token=xyz
params(id: 1234, api_token: 'xyz')params は要求オブジェクトで利用できるメソッドの1つで、URL パラメータを追加します。これはハッシュオブジェクトとして渡されます。次のようなメソッドを同じように連結することで、要求の他の項目と組み合わせて実行することもできます。
payloadペイロードフィールド (PATCH、POST、PUT のみ)。同様にハッシュとして渡されます。
headers要求ヘッダー。ハッシュとして渡されます。
要求、応答、またはその両方の形式をデフォルトの JSON から変更するメソッド:
request_format_json、response_format_json、format_json、request_format_xml、response_format_xml、format_xml、request_format_www_form_urlencodedHTTP 認証
user、password
要求の実行と応答の処理
['customer']要求オプションではなくメソッド (この場合は []) を呼び出すと、アダプターが、要求を実行するタイミングがきたことを通知します。これにより API 応答を処理できます。このデフォルトの JSON の場合、応答は Ruby ハッシュとして解析されます。
{
"customer" => {
"id" => 1234,
"name" => "John Smith",
"email" => "[email protected]",
"address" => {
"street" => "123 Main St",
"city" => "Anytown",
"state" => "CA",
"zip" => "94321",
"country" => "USA"
}
}
}次に、['customer'] メソッドが評価され、customer エンベロープが削除されて、このアクションの出力となります。
{
"id" => 1234,
"name" => "John Smith",
"email" => "[email protected]",
"address" => {
"street" => "123 Main St",
"city" => "Anytown",
"state" => "CA",
"zip" => "94321",
"country" => "USA"
}
}スキーマ - 入力/出力の記述
アダプターを使用する場合、いくつかのコンポーネントで、入力、出力、または設定として期待されるフィールドを記述する必要があります。これは、次のようにスキーマ表記で記述します。
[
{ name: "id", type: :integer },
{ name: "name" },
{ name: "email" },
{
name: "address",
type: :object,
properties: [
{ name: "street" },
{ name: "city" },
{ name: "zip" },
{ name: "country" }
]
}
]アダプターコンポーネント
基本的な項目を理解したので、次にアダプターの例で確認し、それぞれの部分が、レシピの編集や実行とどのように関係しているかを示します。
{
title: 'My sample adapter',
connection: {connection フィールド
必要に応じてオプションの connection fields で、スキーマ表記を用いて接続設定のフィールドを記述します。api_token URL パラメータを必要とする上記のサンプル API の場合は、次のようになります。
fields: [
{
name: 'api_token',
label: 'API token',
optional: false,
hint: 'You can find your MyApp API token under "Account Settings"'
}
],スキーマ表記を使用して、接続のプロパティを記述します。これは、レシピの接続タブなど、接続設定が表示されるすべての場所で表示されます。

認証
任意に connection へ authorization コンポーネントを追加することができ、API の認証ロジックを統合できます。authorization にはいくつかの要素を含めることができますが、最も重要な要素は apply です。これにより、アダプターが実行するすべての API 要求に追加する要求オプションを定義できます。
authorization: {
apply: lambda do |connection|
params(api_token: connection['api_token'])
end
},こうすることで、サンプルの要求で、認証オプションを繰り返す必要がなくなります。
get('https://api.my-app.com/v1/customers.json').params(id: 1234)['customer']接続テスト
connection の外側に戻って、test コンポーネントで接続をテストします。たとえば、この例の api_token などの証明書が依然として有効であることを確認します。
},
test: lambda do |connection|
get('https://api.my-app.com/v1/customers.json').params(limit: 1)
end,lambda が例外を発生しなければ、接続が現在も維持されていると考えることができます。lambda は次の場合に呼び出されます。
OAuth 以外のアダプターのみを使用している場合 :
Connectボタンがクリックされたとき。すべての場合 : レシピを開始すると、レシピ内で使用されているそれぞれの接続で対応する
testが呼び出されます。いずれかのtestでエラーが発生した場合、レシピの開始に失敗します。
アクション
actions: {
get_customer_by_id: {入力フォーム
アダプターのアクションの1つがレシピで使用されているとき、その入力形式は input_fields lambda に従います。そこでもスキーマ表記を使用します。
「get customer by ID」アクションの例の場合は、次のようになります。
input_fields: lambda do
[
{ name: 'id', type: :integer, optional: false }
]
end,
出力ツリー
output_fields では、同じスキーマ表記を使用して、アクションの出力を記述します。これは、レシピジョブデータの下流に表示されます。
output_fields: lambda do
[
{ name: "id", type: :integer },
{ name: "name" },
{ name: "email" },
{
name: "address",
type: :object,
properties: [
{ name: "street" },
{ name: "city" },
{ name: "zip" },
{ name: "country" }
]
}
]
end,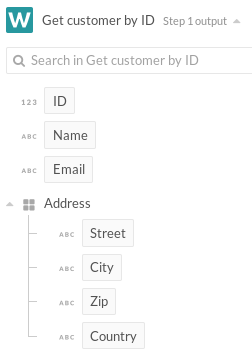
execute
実行時に、ジョブがこのアクションを使用するレシピ行に到達すると、その execute lambda が呼び出されます。
最初の引数は
connectionフィールドです。ハッシュオブジェクトでパッケージ化されています。2番目の引数はアクションの入力です。レシピで設定された入力形式に基づいて評価されます。同様にハッシュオブジェクトとしてパッケージ化されています。
前述のとおり、execute lambda が要求を実行します。結果は、lambda 内で遅延評価されるか、lambda が返された直後に遅延評価されます。結果には指定された出力フィールドが含まれることが期待されます。
execute: lambda do |connection, input|
get('https://api.my-app.com/v1/customers.json').params(id: input['id'])['customer']
end
} # get_customer_by_id
}, # actions:トリガー
triggers: {
new_customer: {
入力フォーム
アクションの場合と同じです。
出力ツリー
アクションの場合とほぼ同じですが、トリガーの poll (次を参照) に含まれるレコードのコレクションの それぞれ について何を含んでいるかを記述します。
トリガーイベントのポーリング
トリガーには、2つの種類があります。これは API エンドポイントで2つの一般的なパターンに対応するためで、"ascending" (昇順、デフォルト) と "paging" (降順) があります。
エンドポイントの昇順の並べ替え
次に、消費する順番と同じ順番でレコードを表示する API エンドポイントを示します。これは、通常、作成または変更時刻の昇順で表示されます。
GET /v1/customers.json?created_since=2017-01-01T12:00:00Z&order=asc&limit=100
{
"customers": [
{
id: 1234,
created_at: "2017-01-02T12:34:56Z",
...
},
... (up to 100 total customer records)
{
id: 2345,
created_at: "2017-01-03T12:34:56Z",
...
}
]
}
poll
new_customer_ascending: {
poll: lambda do |connection, input, last_created_since|
created_since = last_created_since || input['created_since']
customers = get('https://api.my-app.com/v1/customers.json').
params(created_since: created_since.iso8601,
order: 'asc',
limit: 100)['customers'] || []
{
events: customers,
next_poll: (customers.length > 0 && customers.last['created_at'] ||
created_since),
can_poll_more: (customers.length >= 100)
}
end,
poll の応答には、次の3つの部分があります。
events
これはポーリングされたイベント (この場合は顧客オブジェクト) の配列です。その配列内のジョブをレシピによって開始できます。
next_poll
次のポーリングサイクルの最後の引数として渡されるオブジェクト (この例では last_created_since)。これは、次の要求の「カーソル」を維持するために使用します。
can_poll_more
ランタイムが、より多くの結果をすぐにポーリングできるかどうかを通知するフラグ。true の場合、さらなるポーリングが (ほぼ) 即座に実行されます。
dedup
dedup: lambda do |customer|
customer['id']
end,
}, # closing out the trigger
1つのレコードが別々の poll 呼び出しに表示されるのを防ぐことは、常に可能とは限りません。レシピジョブの重複を避けるために、ランタイムで dedup が使用されます。これは events で返されたアイテムごとに渡されます。出力は、そのアイテムの結果であるレシピジョブに関連付けられた一意の識別子です。
新規オブジェクトの作成を追跡するトリガーの場合、一意の識別子は、通常そのオブジェクトのアプリケーション固有の一意 ID です。
他にも、よくあるトリガーパターンとして、オブジェクトの修正を追跡する場合があります。このトリガーを反映するために、通常アダプターでは、オブジェクトの修正のタイムスタンプをイベントの一意な ID と組み合わせます。
"#{customer['id']}@#{customer['modified_at']}"
エンドポイントの降順の並べ替え
次に、消費する順番と逆の順番でレコードを表示するエンドポイントを示します。
GET /v1/customers.json?created_since=2017-01-01T12:00:00Z&created_before=2017-01-21T00:00:00Z&order=desc&limit=100
{
"customers": [
{
id: 9876,
created_at: "2017-01-20T12:34:56Z",
...
}
... (up to 100 total customer records)
{
id: 8765,
created_at: "2017-01-19T12:34:56Z",
...
}
]
}
poll
次のエンドポイントのポーリング方法は、結果セット (または以前に処理した結果) の先頭に到達するまで、逆に「ページ送り」することです。その時点で、ランタイムはレシピジョブを「正しい」順番で作成するように処理します。
new_customer_descending: {
type: :paging_desc, # marks this as a "descending" trigger
poll: lambda do |connection, input, last_created_before|
created_before = last_created_before || Time.now
customers = get('https://api.my-app.com/v1/customers.json').
params(created_since: input['created_since'].iso8601,
created_before: created_before.iso8601,
order: 'desc',
limit: 100)['customers'] || []
{
events: customers,
next_page: (customers.length >= 100 && customers.last['created_at']).presence
}
end,
このトリガーバリアントの poll 応答には、次の2つの部分があります。
events
ascending バリアントの events と似ていますが、降順になることが期待されます。
next_page
これが存在する場合 (nil ではない場合)、エンドポイントに、もっと「前の」イベントが存在する可能性があることをランタイムに通知します。
この値は、次の poll に3番目の引数として渡されます (この例では last_created_before)。
昇順トリガーバリアントと比較した場合、この値は「カーソル」 (next_poll) とポーリングタイミングのヒント (can_poll_more) の両方の役割を担っています。
アダプターでは、すでに発生したイベントに到達するまでの距離を記録しておく必要はありません。ランタイムはその状態を、残りの下降トリガーコンポーネントとの組み合わせによって処理します。
document_id
document_id: lambda do |customer|
customer['id']
end,
基になるオブジェクトの一意の ID を抽出します。これは省略可能です。これがない場合、デフォルトでは、オブジェクトの id (大文字小文字は区別されません) というフィールドが使用されます (上の例は、デフォルトを示しているだけです)。
注 : これは、以下の dedup とは異なります。
sort_by
sort_by: lambda do |customer|
customer['created_at']
end,
基になるオブジェクトのソート/ランク付けの値を抽出し、「十分な距離」だけ後からポーリングしたかどうかをランタイムが判断できるようにします。
dedup
dedup: lambda do |customer|
"#{customer['id']}@#{customer['created_at']}"
end
}, # closing out the trigger
昇順トリガーの場合と同じ重複除去ロジックを実行します。ただし、降順トリガーの場合は省略可能です。上の例はデフォルトで document_id と sort_by の結果を結合したもので、@ 記号が区切り文字として使用されています。
アダプターの終了
これは、アダプターの記述で残された「開いたまま」の中括弧を閉じたところです。
} # triggers
} # top-level adapter hash
アダプターが、使用待ちの状態になります。
Last updated: