# Apache Kafka - New message trigger
# New message in Kafka topic
This trigger picks up new Kafka messages for a selected Kafka topic. You can select Kafka message and key schemas in AVRO format. Additionally, the initial offset can be configured to define from where you want to start picking Kafka messages. This trigger exists in two options: single, where processing every message will result in creating a single job, and batch, where multiple messages will be processed in a single job.
New version of the trigger
With on-prem agent 2.20.0 version we have released an updated Apache Kafka new message trigger. If you are using a previous version of the trigger, we recommend upgrading your agent and switching to a new trigger. Previous triggers are now marked as deprecated.
Changes resulted in better reliability, especially in cases when your recipe has been stopped and there were Kafka messages in the queue awaiting processing.
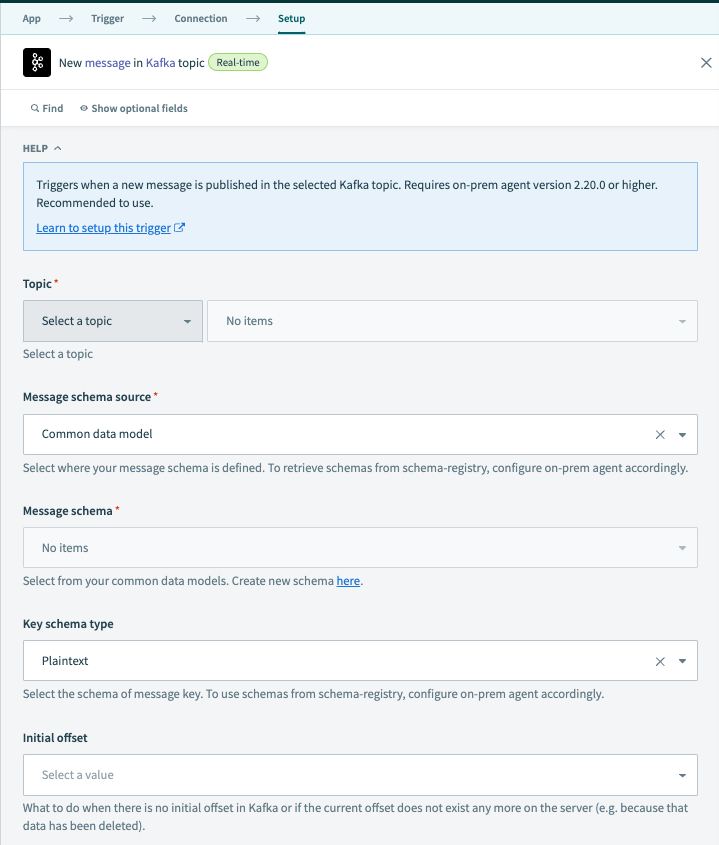 New Kafka message trigger
New Kafka message trigger
# Input fields
| Input field | Description |
|---|---|
| Topic | Select a Kafka topic to which you want to subscribe. The trigger consumes all messages from the selected topic and all its partitions. You can filter the messages by partition later on in the recipe. |
| Message schema source |
Define your message schema source. When Common data model is selected you will use the schema defined in Workato. By selecting the Schema registry (on-prem) option, you can use the schema that is defined in your Kafka cluster. This option requires schema.registry.url property to be configured. Workato supports schemas in AVRO format.
|
| Message schema | Select the message schema format based on the Message schema source input. |
| Key schema type |
Similarly to the Message schema source, you can configure the schema type for your message Keys. Defined in schema registry (on-prem) option also requires the schema.registry.url property to be configured. Workato supports schemas in AVRO format.
|
| Initial offset |
You can choose from which point you want to consume Kafka messages from the selected topic. Earliest means that we will try to retrieve all messages that are available in the Kafka cluster. Latest means that all historical messages will be ignored and only new ones will be consumed from the selected Kafka topic.Note: this option only works when you are running a recipe for the first time for a selected topic. In case you stop the recipe and want to ignore all messages that were produced in the meantime you have to change the topic or clone this recipe and select the Latest option before starting it.
|
# Output fields
The output of this trigger is a single Kafka message or a batch of Kafka messages, depending on the selected trigger option. To use the output in downstream steps, map in the relevant datapill.
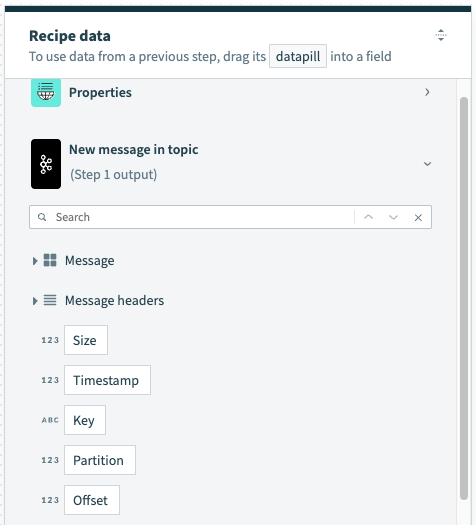 New message trigger output fields
New message trigger output fields
| Field name | Description |
|---|---|
| Message | Message fields with data consumed from the selected Kafka topic. |
| Message headers | Kafka message headers. |
| Size | Size of the consumed Kafka message. |
| Timestamp | Timestamp of the Kafka message. |
| Key | Kafka message key fields with data. |
| Partition | ID of the partition topic from which the Kafka message was consumed. |
| Offset | Message offset which is a unique message identifier in Kafka. |
Last updated: 6/16/2023, 7:21:57 AM