# Concepts
This guide provides an overview of Data integration concepts in Workato.
# Bulk and batch operations
Understanding the distinction between bulk and batch operations is crucial for optimizing data movement and synchronization across diverse systems. This section explains bulk and batch operations and the scenarios in which they are most effective.
# Bulk operations
Bulk operations involve the processing of large volumes of data in a single, collective transaction. Instead of manipulating individual records, bulk operations handle data in bulk, often transferring or modifying thousands or millions of records in a single operation.
Bulk actions are typically asynchronous actions.
Bulk operations provide the following benefits:
Efficiency: Bulk operations are highly efficient when dealing with large datasets. Bulk operations minimize the overhead associated with processing individual records, resulting in faster execution times.
Atomicity: Bulk operations are typically atomic, meaning they are treated as a single, indivisible unit. This ensures that either all the changes are applied, or none at all, maintaining data integrity.
Optimized for large datasets: Bulk operations optimize performance when dealing with a significant volume of data, making them suitable for scenarios involving mass data migration, synchronization, or transformation.
Reduced network overhead: Bulk operations transmit data in large chunks, which reduces the overall network overhead compared to handling individual records separately.
# Use cases
- Data pipelines: Move aggregated datasets from source applications to data warehouses daily.
- Data migration: Move large datasets from one system to another.
- Historical data load: Load complete historical data into a system on a weekly basis.
# Batch operations
Batch operations involve the processing of data in smaller, discrete sets or batches. Instead of handling all records at once, data is processed incrementally in manageable chunks.
Batch actions are typically synchronous actions that process a limited number of records at a time.
Batch operations provide the following benefits:
Incremental processing: Batch operations process data in smaller increments, allowing for more manageable and controlled data manipulation.
Error handling: Batch operations provide opportunities for better error handling and recovery. If an error occurs in a specific batch, it can be addressed without affecting the entire dataset.
Frequent data retrieval: Batch operations excel at retrieving records frequently and in small volumes, ideally for shorter intervals or higher frequencies. Batch operations collect limited sets of records within each period to optimize record volumes.
# Use cases
Regular data updates: Update low volume records in a system at frequent intervals to ensure data accuracy and relevance.
Data synchronization: Maintain data consistency between systems by synchronizing data at regular intervals throughout the day, ensuring harmonized information across platforms.
Routine data processing: Consistently perform targeted operations on predefined sets of records, ensuring smooth and efficient data management processes.
# Choose between bulk and batch operations
The choice between bulk and batch operations depends on your specific requirements. Understanding the strengths and applications of each approach can help you design efficient and scalable data integration processes tailored to your organization's specific requirements.
Data volume: Consider the volume of data you are working with. Bulk operations are more suitable for large datasets, while batch operations may be preferable for smaller, incremental updates.
Performance requirements: Evaluate the performance implications of each operation. Bulk operations are generally faster and scalable for large-scale data movements, while batch operations offer more control and granularity for incremental updates.
Frequency of execution: Determine whether your data integration tasks are better suited for periodic, frequent updates (batch), or scheduled, high-volume transactions (bulk).
Error handling: If granular error handling and recovery are essential to your use case, batch operations may provide more flexibility.
# Transfer, buffer, and store
Transferring, buffering, and storing data are crucial processes that enable the management and optimization of data flow between various stages in a system. Workato FileStorage enables data transferring, buffering, and storing in your data integration workflows.
# Data transfers
Data transferring is the process of moving data from one location to another, such as between file systems, applications, databases, or data warehouses. Workato enables you to build data integration recipes that are scalable and high performing when working with high volume transfers. Workato uses a streaming mechanism to transfer data at high speeds.
All bulk actions or triggers in applications, database, and data warehouse connectors, and all file upload/download actions in filesystem connectors (Including the FileStorage system) support streaming. Learn more about streaming.
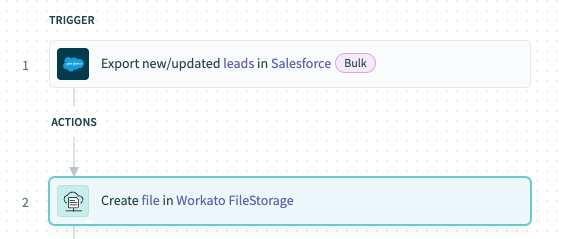
# Example recipe: Export leads from Salesforce in bulk and transfer them to FileStorage
The following recipe exports records from Salesforce in bulk and transfers them to FileStorage using streaming.
 Export records from Salesforce and transfer them to FileStorage
Export records from Salesforce and transfer them to FileStorage
# Recipe walkthrough
Export new/updated leads from Salesforce using the Export new/updated leads in Salesforce trigger.
Transfer data obtained from Salesforce using the Create file in Workato FileStorage action.
# Data buffering
FileStorage enables you to store large volume data as a file temporarily. You can store data as files and share them across jobs or across recipes.
You can use buffering in data integration to manage the flow of data between two processes or systems that operate at different frequencies or different volumes.
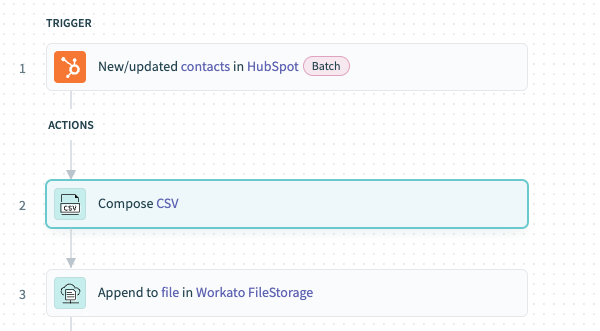
# Example recipe: Move data from Hubspot to Snowflake
The following recipe demonstrates how to move data from HubSpot, which provides data in batches at a polled frequency, to Snowflake which loads the data in bulk to data tables.
 Export data from HubSpot in batch and load into Snowflake
Export data from HubSpot in batch and load into Snowflake
# Recipe walkthrough
Fetch new/updated records from HubSpot using the New/updated contacts in HubSpot trigger.
Aggregate and buffer the records obtained from Salesforce as CSV rows in FileStorage using the Compose CSV and Append to file actions.
The recipe streams the bulk data from the file into designated data tables in Snowflake at a specified time each day. This process reduces complexity by consolidating all aggregated data loading into a single job to load into Snowflake.
# Data storage
Data storage is the persistent retention of data in a structured manner for future use. This includes storing data in databases, data warehouses, file systems, on-prem systems, or cloud storage solutions. Workato enables connection to various data storage systems using our platform connectors. You can also store frequently fetched data, such as lookup information, as a file within Workato FileStorage. Files stored in FileStorage are encrypted by default and retained permanently. This enables you to fetch and reuse the files across multiple jobs or recipes.
Last updated: 4/23/2024, 3:50:22 PM