Design of the ELT Pipeline for Snowflake accelerator
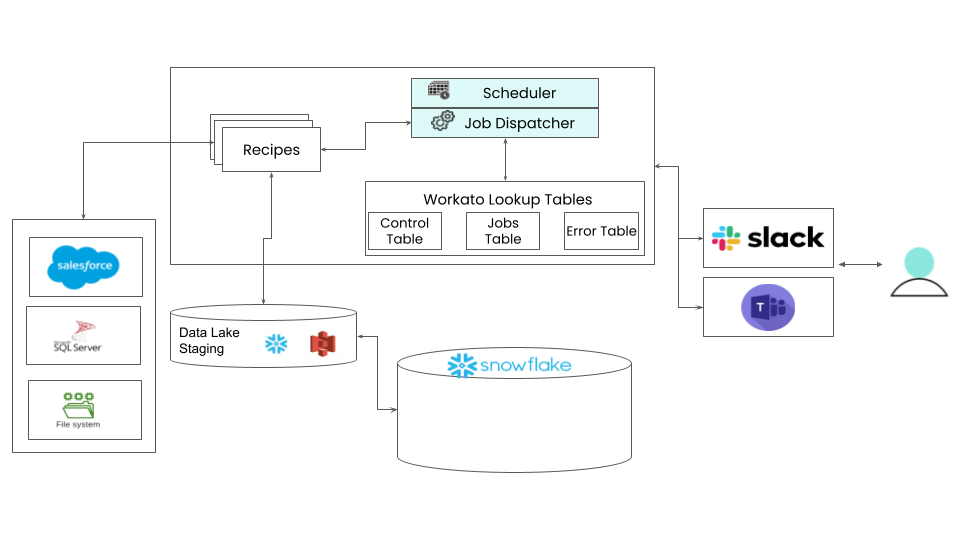
The ELT Pipeline for Snowflake accelerator consists of multiple recipes and lookup tables that work together to create a robust framework for extracting, loading, and transforming data. This framework consists of the following components:
- Change data capture (CDC)
- Real-time streaming to S3
- Pipeline orchestration
- Jobs
- Scheduler
- Dispatcher
- Errors and notifications
Change data capture (CDC)
Change data capture is the ability to detect the changed data in source systems and capture these changes. The Workato ELT accelerator uses timestamp-based change data capture. This accelerator can run incremental jobs to populate data based on the last load date-time using a control and jobs table.
Real time streaming to S3
This accelerator leverages Workato’s existing S3 Streaming upload action connector to move source files to staging. This type of real-time streaming in micro batches accommodates moving large volumes of files to the data lake efficiently through Workato’s S3 Connector.
Pipeline orchestration
The control and jobs tables maintain an audit to schedule and keep dependencies on various jobs in the pipeline. This helps with CDC, as it controls pipeline jobs execution, rerunning jobs, troubleshooting, and backfilling data. The ELT accelerator scheduler and dispatcher recipes are instrumental in coordinating pipeline orchestration.
Job types
Users can perform three different job types:
- Full load (FULL)
- Full refers to a full extract of the source table every time a job runs. These types of jobs usually do not have a start date. You can determine their frequency when you create the pipeline. For example, you can assign small to medium-sized lookup tables, including currency, or codes, to full load.
- Incremental Load(INCR)
- All incremental jobs begin with a full refresh. The refresh syncs the source to the target, and then the pipeline switches to incremental using the timedate-based CDC approach. You can determine INCR frequency when you create the pipeline. Rather than refresh the entire extract every time a job runs, the accelerator picks up the data that has changed after the last time the pipeline ran. For example, consider a scenario where you migrate an opportunities table from Salesforce completely and set the load frequency to daily. In this situation, only daily data changes are extracted and merged.
- Extract Load (EXTR)
- Extract loads pull data from within a given time frame, usually between two timestamps. You can use this load type to build custom reports, including audits.
Status
Jobs may have one of the following statuses:
- Pending
- After you create a pipeline, the accelerator dispatches the job. Then the current status is updated in the control table to pending. Another situation in which the pipeline's status is pending is between successive jobs.
- Active
- Active is when the pipeline is scheduled to run successive jobs.
- Inactive
- InActive is when the pipeline is suspended after it has finished processing. InActive pipelines do not run again.
- Error
- Error is when the job has erred out.
- Processing
- Processing is when the pipeline is currently running the job.
- Extract
- Extract is the status when a new extract-type pipeline is created.
Scheduler
The scheduler is a 5 minute poller that queries the Control table to retrieve the details of jobs in a pipeline based on the current time of the scheduler. If the next_time from the control table matches, the scheduler picks up the job. If the desired conditions are met, the scheduler makes an asynchronous call to the job dispatcher. The accelerator also sends a notification to the Slack/Microsoft Teams channel. Simultaneously, the accelerator updates the job status to Processing. If the job type is extract, then there could be any start and end time. Extract job types process in the next run of the scheduler. Incremental and Full job types follow the next_time logic described previously.
Dispatcher
The job dispatcher can handle multiple jobs running simultaneously, and its concurrency limit is 5. The dispatcher evaluates inputs from the scheduler and dispatches jobs to respective recipes to run workloads. As soon as the dispatcher starts, it records the batch start date time which is the pipeline next_time it received from the scheduler. Workato records the dispatcher job and recipe ID in unison with the control ID of the received pipeline in the ELT Job Table.
The accelerator calls different respective workload recipes depending on the job load type and source system. After the job completes successfully, the accelerator updates the Job table using the respective control ID with the dispatcher job ID and batch end date-time. Simultaneously, using the same control ID, the accelerator updates the control table with the last_successful_job_dt, last_successful_job_id, status, and next_time.
The accelerator calculates the next_time value according to the job type and scheduler frequency (hourly, weekly, or monthly) configured by the user while setting up the pipeline.
Extract job types are unique because they do not run on a set schedule and are one-time jobs. In this scenario, the accelerator skips the next_time calculation and updates the control table status to Inactiveimmediately.
If a job executed by the dispatcher errors out, the accelerator updates the is_success field in the jobs table to False. It also updates the Status field in the control table to Error. Then, the accelerator sends both Successful and Unsuccessful job notifications to the communication channels in Microsoft Teams or Slack.
Errors and notifications
The ELT Pipeline bot sends the following error messages and notifications to the notifications channel in Slack or Microsoft Teams.
- Pipeline created
- Pipeline started
- Pipeline completed
- Pipeline error
See our tips and troubleshooting article for information on how to customize notifications.
Last updated: