OpenAI - Transcribe recording action
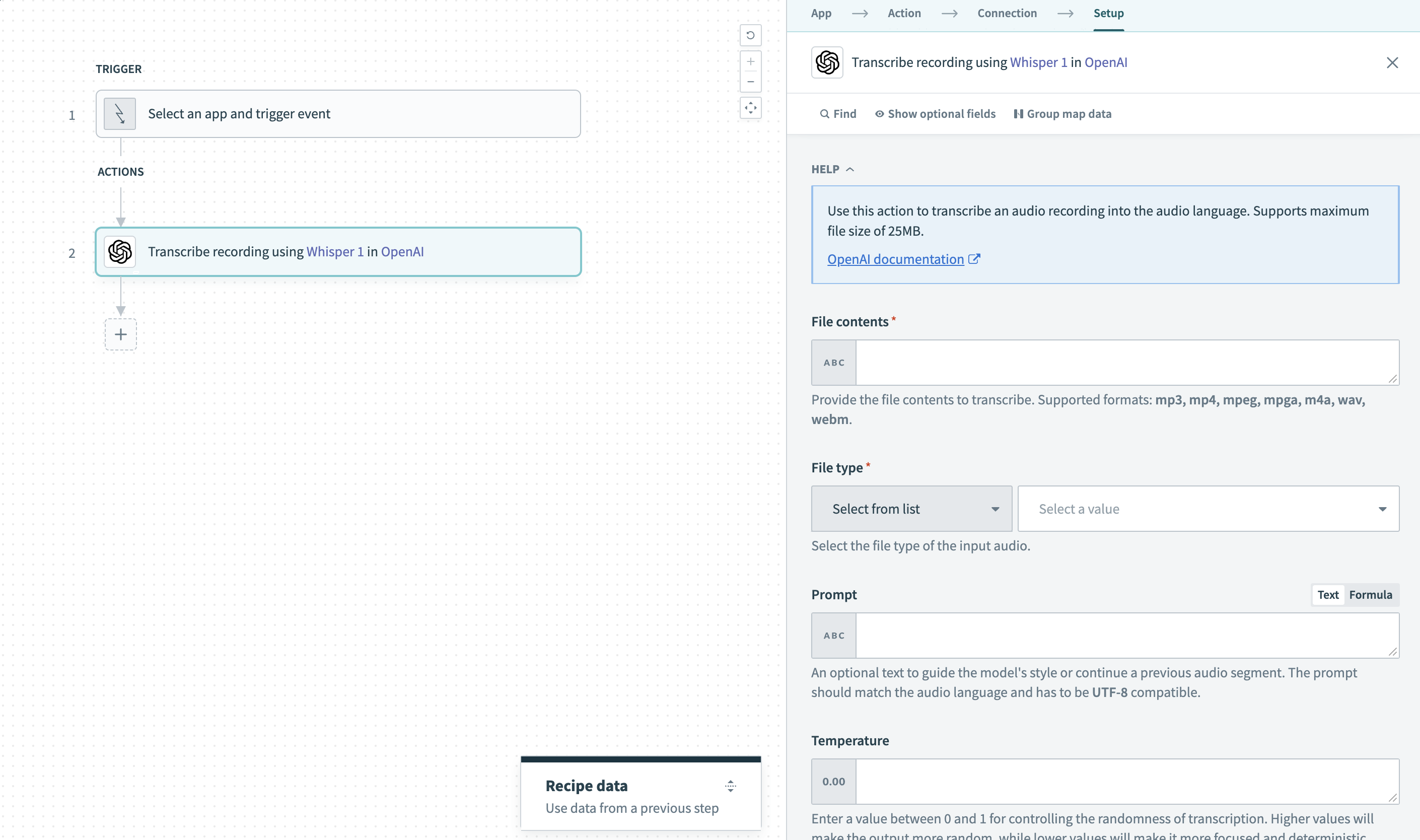 Transcribe Recording Action
Transcribe Recording Action
Input
| Field | Description |
|---|---|
| File contents | Provide the file contents to transcribe. Supported formats are: mp3, mp4, mpeg, mpga, m4a, wav, or webm. |
| File type | Select the file type of the input to transcribe. |
| Prompt | An optional text to guide the model's style or continue a previous audio segment. You can use it to provide additional context to the model when transcribing and help specify the way certain words and phrases should be either omitted, included or written. Refer to the OpenAI speech-to-text prompting guide for more information. The prompt should be in English and must be UTF-8 compatible. |
| Temperature | We generally recommend setting a value of 0. You can set a value between 0 and 2 to control the randomness of completions. Higher values will make the output more random, while lower values will make it more focused and deterministic. We recommend using this or top p but not both. |
Output
The output is a datapill containing the transcribed text. You can use this directly in further actions or send it to text-based OpenAI models for further processing.
ENDPOINT CAPABILITIES
We have observed that this endpoint can help transcribe text from other languages as well. For example, if the input language is in Japanese, the transcribed text is in Japanese as well. This seems to be an undocumented functionality of the endpoint. As the endpoint is in beta, we do not recommend leveraging this as a part of critical workflows because its behavior might change.
Last updated: