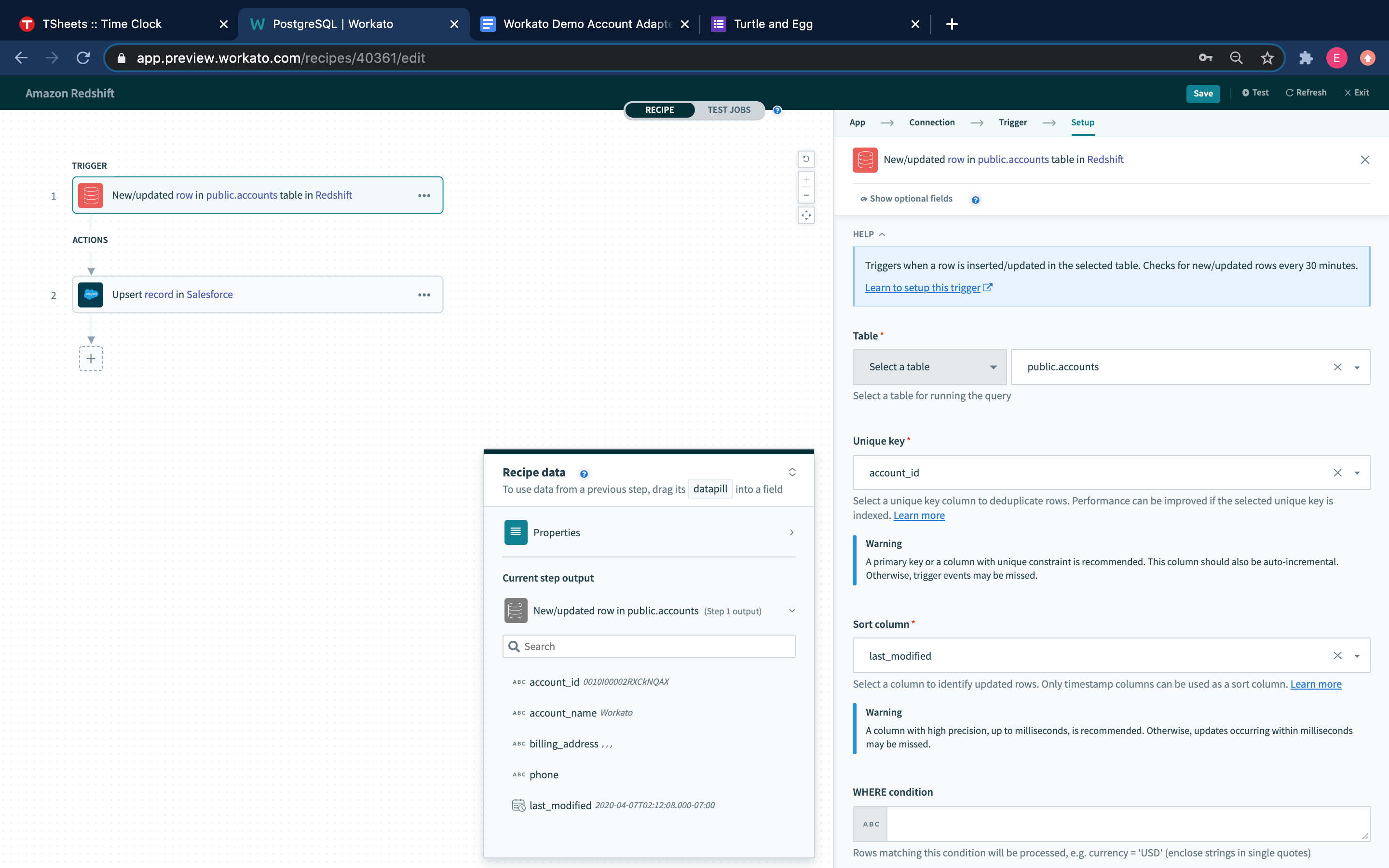
Redshift - New/updated row triggers
New/updated row
This trigger picks up rows that are inserted/updated in the selected table or view. Each row is processed as a separate job. It checks for new/updated rows once every poll interval.
 New/updated row trigger
New/updated row trigger
| Input field | Description |
|---|---|
| Table | Select a table/view to process rows from. |
| Unique key | Select a unique key column to uniquely identify rows. This list of columns is generated from the selected table/view. |
| Sort column | Select a column to identify updated rows. This list of columns is generated from custom SQL provided. |
| WHERE condition | Provide an optional WHERE condition to filter rows. |
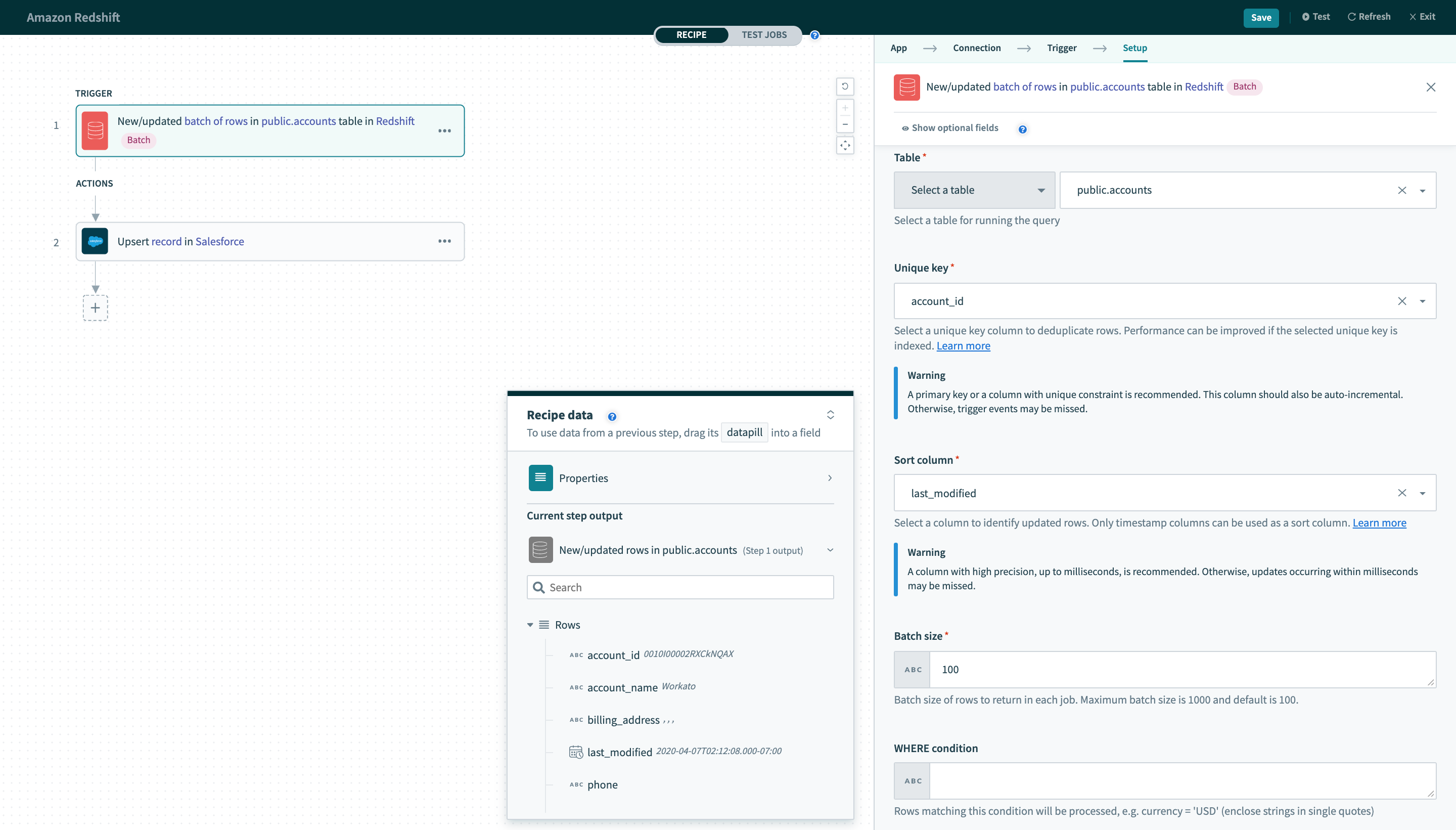
New/updated batch of rows
This trigger picks up rows that are inserted/updated in the selected table or view. These rows are processed as a batch of rows for each job. This batch size can be configured in the trigger input. It checks for new/updated rows once every poll interval.
 New/updated batch of rows trigger
New/updated batch of rows trigger
| Input field | Description |
|---|---|
| Table | First, select a table/view to process rows from. |
| Unique key | Select a unique key column to uniquely identify rows. This list of columns is generated from the selected table/view. |
| Sort column | Select a column to identify updated rows. This list of columns is generated from custom SQL provided. |
| Batch size | Configure the batch size to process in each individual job for this recipe. |
| WHERE condition | Provide an optional WHERE condition to filter rows. |
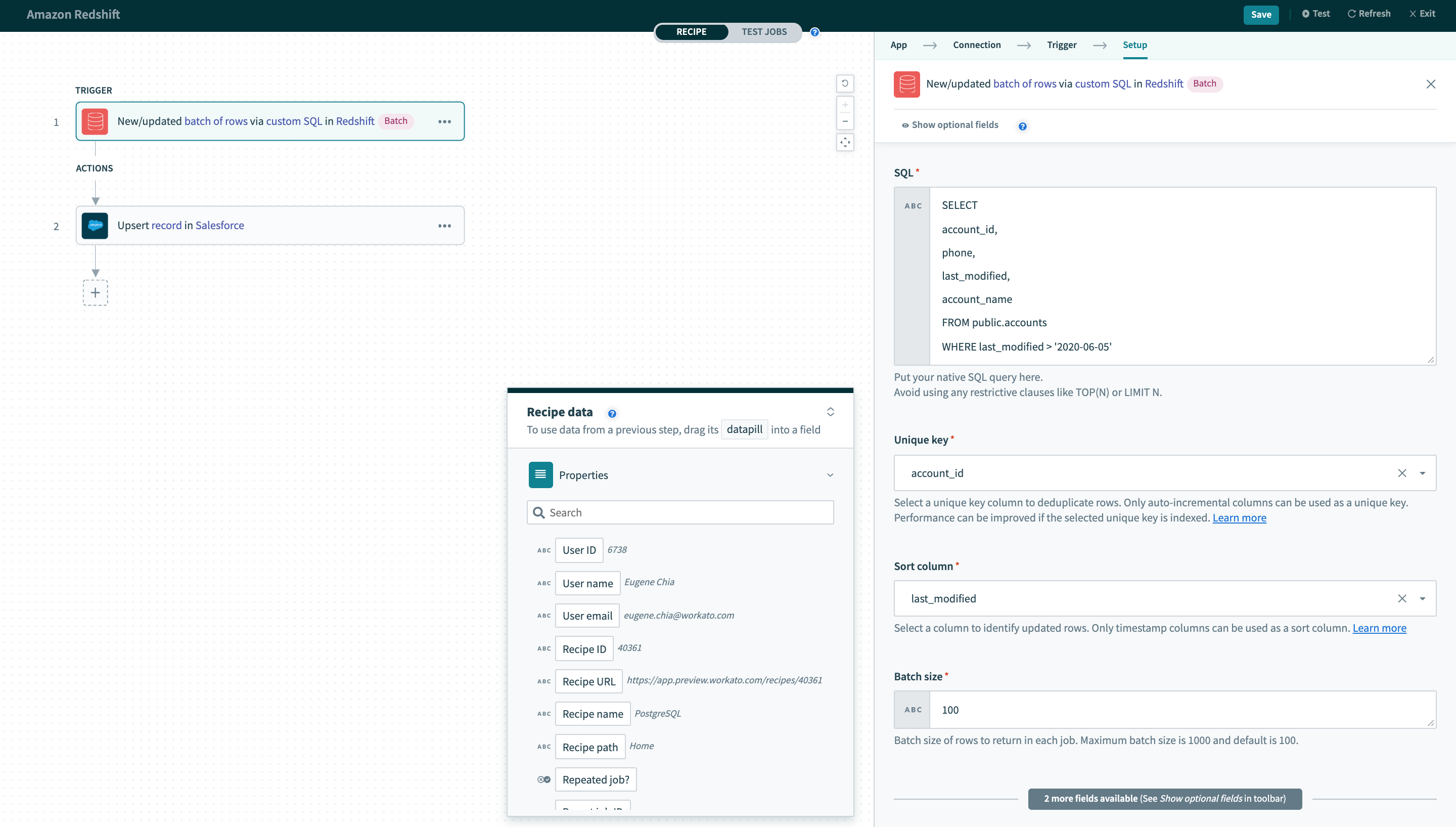
New/updated batch of rows via custom SQL
This trigger picks up rows when any rows matching the custom SQL are inserted/updated. These rows are processed as a batch of rows for each job. This batch size can be configured in the trigger input. It checks for new rows once every poll interval.
 New/updated batch of rows trigger via custom SQL
New/updated batch of rows trigger via custom SQL
| Input field | Description |
|---|---|
| SQL | Custom SQL query to be executed at each poll interval to pick up new rows. |
| Unique key | Select a unique key column to uniquely identify rows. This list of columns is generated from custom SQL provided. |
| Sort column | Select a column to identify updated rows. This list of columns is generated from custom SQL provided. |
| Batch size | Configure the batch size to process in each individual job for this recipe. This defaults to 100. |
Input
Table
Select the table/view to process rows from. This can be done either by selecting a table from the pick list, or toggling the input field to text mode and typing the full table name.
Unique key
Values from this selected column are used to deduplicate rows in the selected table.
As such, the values in the selected column should not be repeated in your table. Typically, this column is the primary key of the table (for example, ID). It should be incremental and sortable. This column can also be indexed for better performance.
Only columns that has key column usage defined can be used. Run this SQL query to find out which columns fulfill this requirement.
SELECT kc.column_name
FROM information_schema.table_constraints tc
JOIN information_schema.key_column_usage kc
ON kc.table_name = tc.table_name AND
kc.table_schema = tc.table_schema AND
kc.constraint_name = tc.constraint_name
WHERE tc.table_schema = 'schema_name' AND tc.table_name = 'table_name'Sort column
Sort column is a column that is updated whenever a row in the table is updated. Typically, this is a timestamp column.
When a row is updated, the Unique key value remains the same. However, it should have it's timestamp updated to reflect the last updated time. Following this logic, Workato keeps track of values in this column together with values in the selected Unique key column. When a change in the Sort column value is observed, an updated row event will be recorded and processed by the trigger.
Only timestamp and timestamptz column types can be used. Run this SQL query to find out which columns fulfill this requirement.
SELECT column_name
FROM svv_columns
WHERE
table_schema = 'schema_name' AND
table_name = 'table_name' AND
date_type like 'timestamp%'Batch size
Batch size of rows to return in each job. This can be any number between 1 and the maximum batch size. Maximum batch size is 100 and default is 100.
In any given poll, if there are less rows than the configured batch size, this trigger will deliver all rows as a smaller batch.
WHERE condition
This condition is used to filter rows based on one or more column values.
status = 'closed' and priority > 3Leave blank to process all rows from the selected table.
Complex WHERE conditions with subqueries can also be used. Refer to the WHERE condition guide for more information.
SQL
Provide the SQL to be executed to select rows. The SQL here will be used to generate the output datatree. To do this, the SQL will be executed once when you provide it. You can map datapills here to execute dynamically changing SQL statements. Remember to wrap datapills in quotes ('').
Avoid using limit clauses like TOP in your SQL. This is because the limit to the number of rows returned in the query is based on the value defined in the Batch size input field. Adding your own limit clause will cause the action to fail.
Last updated: