Google BigQuery - スケジュール設定されたクエリトリガー
スケジュール設定されたクエリトリガー
Scheduled queryトリガーは、クエリを定期的に実行します。 クエリの結果は、ユーザー定義のバッチサイズに基づいてジョブにバッチ処理されます。 デフォルトでは、発生する可能性のある関連コストのため、Workatoはクエリから返される列を自動的に推定しません。 代わりに、想定される出力列を手動で定義する必要があります。 これは、スキーマウィザードを使用して簡単に実行できます。 詳細については、BigQueryコネクション設定を参照してください。
Workatoで出力列を自動生成する場合は、入力フィールドAutomatic schema introspectionをYesに変更します。 入力SQLステートメントが変更されるたびに、出力列の導出を試みるため、Google BigQueryインスタンスでクエリが実行されることに注意してください。 クエリの返却に時間がかかりすぎる場合、処理されるバイト数が多すぎる場合、または構文が正しくない場合は、出力フィールドを手動で定義する必要があります。
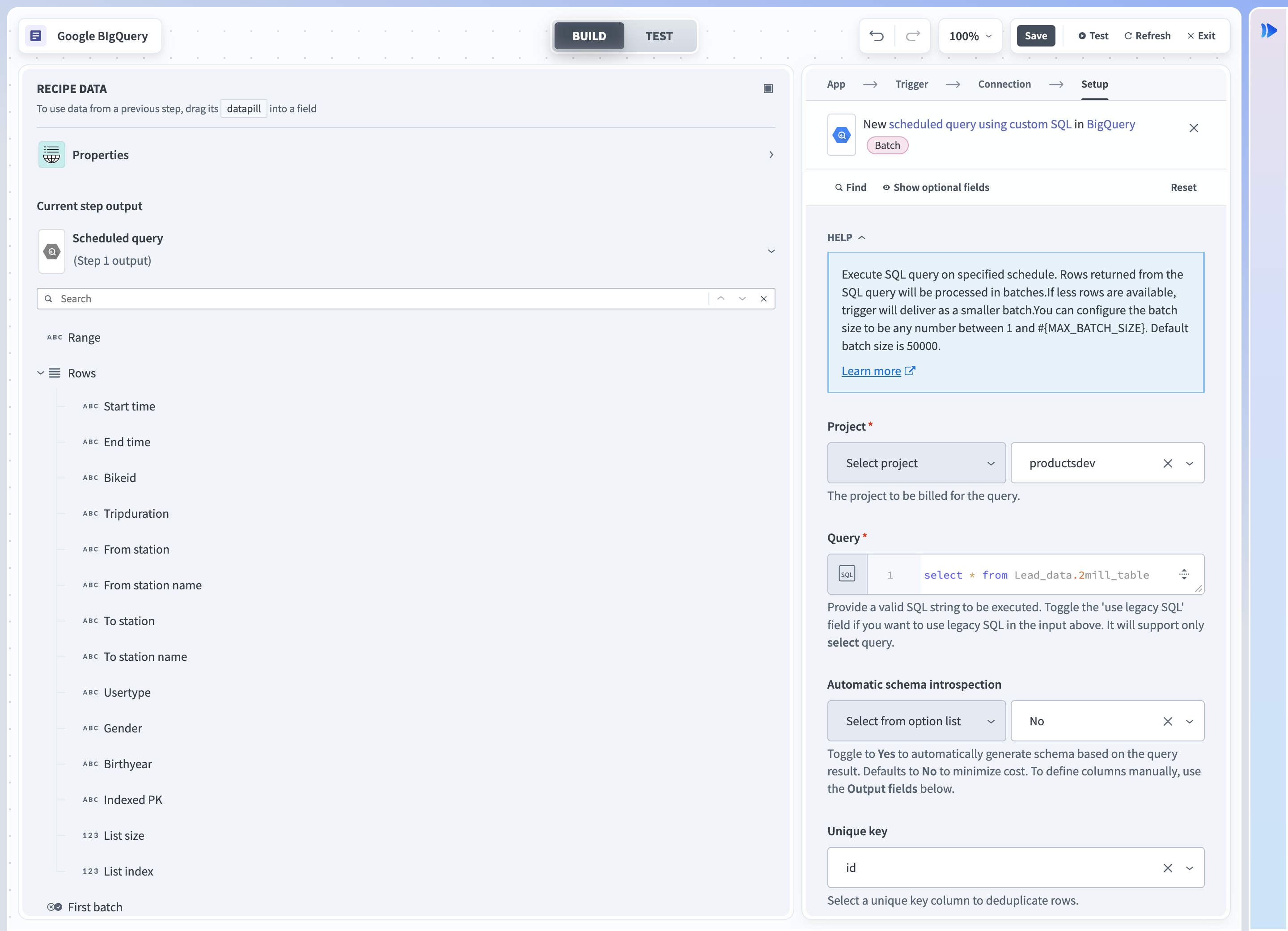 スケジュール設定されたクエリトリガー
スケジュール設定されたクエリトリガー
入力
| 入力フィールド | 説明 |
|---|---|
| プロジェクト | クエリに課金するプロジェクトを選択します。 |
| クエリ | 実行するクエリを選択します。 limit句が使用されている場合、自動スキーマイントロスペクションは許可されません。 |
| バッチサイズ | 各ジョブの行数を選択します。 バッチサイズが小さいほど、ジョブの処理が速くなる場合があります。 |
| スケジュール設定 | このクエリを実行する頻度を設定します。 前のトリガーがバッチ処理され完了するために十分な時間を確保するため、最小期間は1時間です。 |
| 自動スキーマイントロスペクション | デフォルトはNoです。 Yesの場合、Workatoはクエリの出力を自動的にイントロスペクトしようとします。 クエリに時間がかかりすぎる場合、またはデータピルが使用されている場合は、これをNoに切り替えて、クエリの出力フィールドを手動で定義します。 |
| 出力フィールド | この入力フィールドは、Automatic schema introspectionがfalseの場合に表示されます。 これを使用して、クエリの出力フィールドを手動で定義します。 出力に指定する名前は、想定される列名と同一である必要があります。 出力フィールドをすばやく簡単に定義する方法を確認します。 |
| 一意キー | 行の重複排除に使用する一意キーを入力します。 スケジュール設定されたクエリを実行すると、すぐにこのキーで並べ替えられます。 |
| 場所 | ジョブを実行する地理的ロケーションを選択します。 ほとんどの場合、このフィールドは必須ではありません。 |
| レガシーSQL | デフォルトでは標準SQLが想定されます。 代わりにレガシーSQLを使用するには、trueを選択します。 |
出力
| 出力フィールド | 説明 |
|---|---|
| 範囲 | Unique keyによって定義される行の範囲。 |
| 行 | 行の配列。 行オブジェクト内の各データピルは、1つの列に対応します。 |
| 最初のバッチ | これがスケジュール設定されたクエリトリガーの最初のバッチである場合はTrueです。 |
| 最後のバッチ | これがスケジュール設定されたクエリトリガーの最後のバッチである場合はTrueです。 |
| 開始オフセット | このバッチ内の最初のレコードについて、クエリの先頭行からのオフセット。 |
| 終了オフセット | このバッチ内の最後のレコードについて、クエリの先頭行からのオフセット。 |
最終更新日: