S3 Data Lake - データのクエリアクション
データのクエリアクションはGlue Icebergテーブルに対してSQLクエリを実行し、結果をJSON形式でS3に書き込みます。
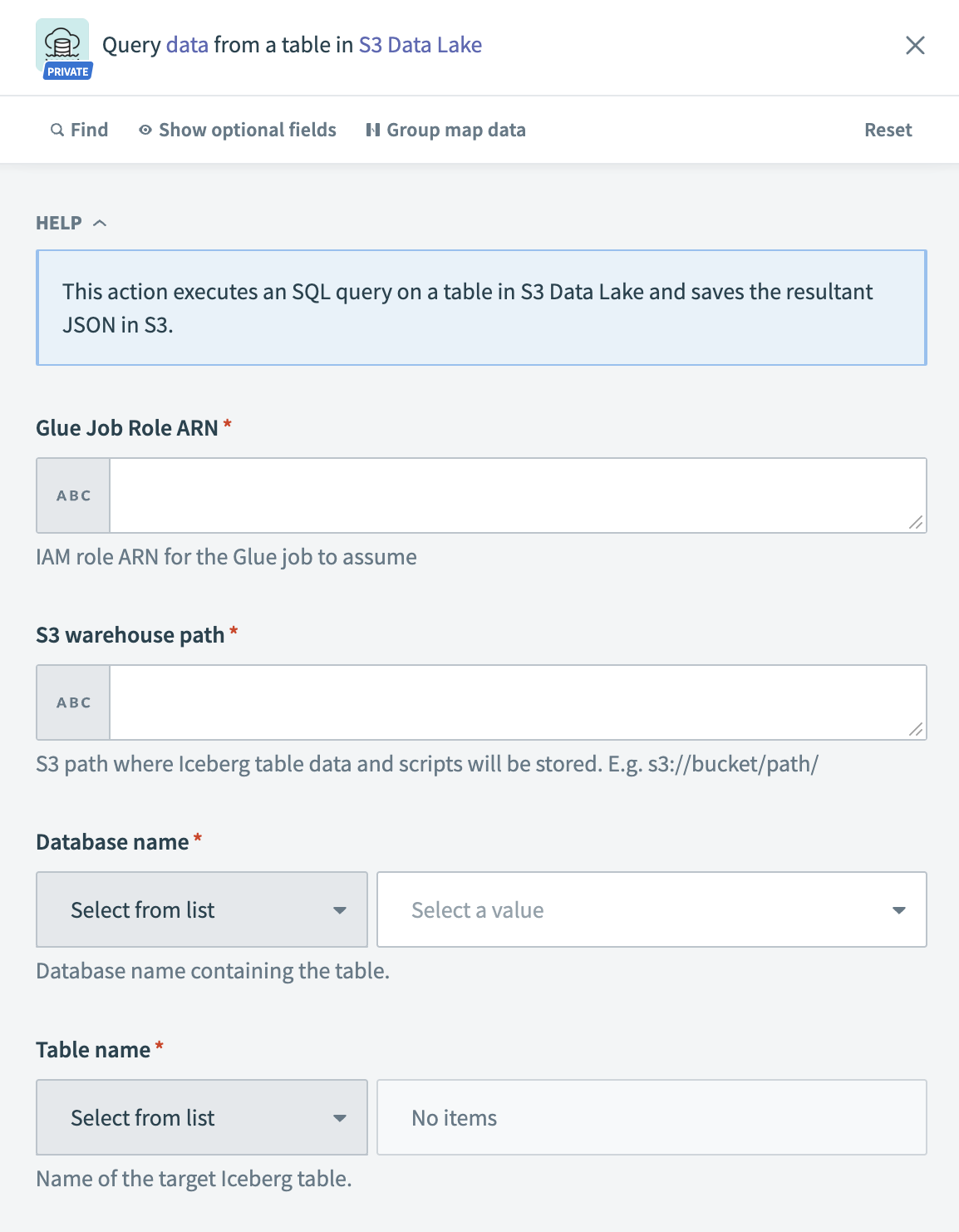 S3 Data Lake:データのクエリアクション
S3 Data Lake:データのクエリアクション
入力
| 入力フィールド | 説明 |
|---|---|
| GlueジョブロールARN | Glueジョブが引き受けるIAMロールARNを入力します。 |
| S3ウェアハウスパス | Icebergテーブルのデータおよびスクリプトを保存するS3パスを指定します。 例:s3://bucket/path/。 |
| データベース名 | Icebergテーブルを含むGlueデータベースを選択します。 |
| テーブル名 | クエリするIcebergテーブルを選択します。 |
| 列 | クエリに含める列を選択します。 すべての列を返すには空白のままにします。 |
| SQL WHERE句 | WHERE句を入力して、クエリ内のレコードをフィルタリングします。 |
| 制限 | 返すレコードの最大数を設定します。 |
| Glueバージョン | 使用するAWS Glueバージョンを選択します。 空白のままにすると、デフォルトで4.0になります。 |
| ワーカータイプ | AWS Glueワーカータイプを選択します。 |
| ワーカー数 | 割り当てるワーカー数を指定します。 空白のままにすると、デフォルトで2になります。 |
出力
| 出力フィールド | 説明 |
|---|---|
| ジョブ実行ID | Glueジョブ実行のID。 |
| ジョブ名 | Glueジョブの名前。 |
| クエリステータス | クエリ実行のステータス。 |
| 出力パス | JSON結果が保存されるS3パス。 |
| エラーメッセージ | ジョブが失敗した場合に返されるメッセージ。 |
| 開始日時 | ジョブが開始されたときのタイムスタンプ。 |
| 完了日時 | ジョブが完了したときのタイムスタンプ。 |
最終更新日: