Amazon S3 - 新規CSVファイルトリガー
新規CSVファイルトリガーは、Amazon S3で選択したbucketまたはフォルダにCSVファイルが追加されたときに監視します。
選択したフォルダで、新規または更新されたCSVファイルをpoll intervalごとに1回確認します。 出力には、ファイルのメタデータとファイルコンテンツが含まれます。ファイルコンテンツはバッチで配信されるCSV行です。
Amazon S3では、ファイル名を変更すると、新規ファイルとみなされます。 ファイルをアップロードして既存の同名ファイルを上書きすると、更新されたファイルとみなされますが、新規ファイルとはみなされません。
 Amazon S3 - 新規CSVファイルトリガー
Amazon S3 - 新規CSVファイルトリガー
入力
| 入力フィールド | 説明 |
|---|---|
| 初回開始時、このレシピがイベントを取得する開始時点 | レシピが初めて開始されたとき以降に作成されたCSVファイルを、レシピが取得する開始時刻を指定します。 レシピを実行またはテストした後は、この値を変更できません。 この入力フィールドの詳細については、トリガーを参照してください。 |
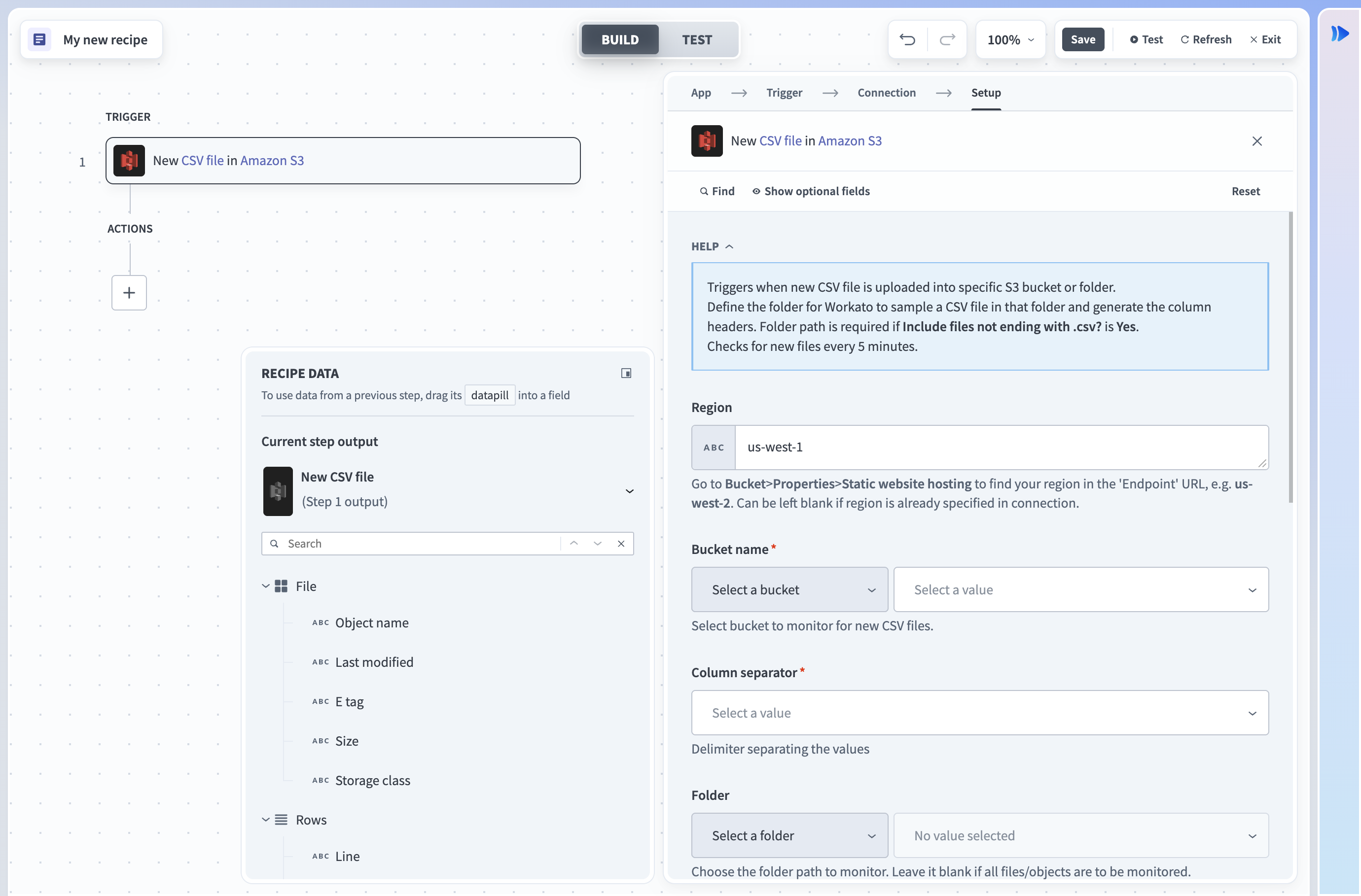
| 地域 | 新規または更新されたファイルを監視するbucketのリージョンを選択します。 例: us-west-2。 Amazon S3で、バケット > プロパティ > 静的ウェブサイトホスティングに移動し、Endpoint URLでリージョンを確認します。 |
| Bucket | 新規CSVファイルを監視するbucketを選択または入力します。 ピックリストからbucketを選択するか、bucket名を直接入力できます。 |
| 列区切り文字 | CSVファイルの列を区切る区切り文字を入力します。 |
| フォルダパス | 新規CSVファイルを監視するフォルダを選択します。 完全なパスを定義します_(例: folder 1/subfolder 1)_。 サブフォルダは監視されません。 デフォルトはルートフォルダまたは制限付きフォルダです。 |
| 末尾が.csvでないファイルを含めますか? | 他のシステムからエクスポートされたCSVファイルに.csv拡張子がない場合の処理方法を指定します。 このフォルダ内のすべてのファイルがCSVとして解析可能であることを確認してください。 |
| 列名 | CSVファイルの列名を入力します。 1行につき1つの列ヘッダーで、列名を手動で定義できます。 |
| バッチサイズ | 各バッチで処理するCSV行数を定義します。 最大はバッチあたり1000行です。 WorkatoはCSVファイルをより小さいバッチに分割して、より効率的に処理します。 データスループットを向上させるには、より大きいbatch sizeを使用します。 Workatoは、API limitを超えないようにbatch sizeを自動的に減らすことがあります。 詳細はBatch Processingを参照してください。 |
| ヘッダー行をスキップしますか? | CSVファイルにヘッダー行が含まれている場合はYesを選択します。 Workatoはその行をデータとして処理しません。 |
このトリガーはTrigger Conditionをサポートしており、トリガーイベントをフィルタできます。
出力
| 出力フィールド | 説明 |
|---|---|
| オブジェクト名 | ファイルの完全な名前。 |
| 最終更新日時 | ファイルの最終更新タイムスタンプ。 |
| 最終更新日時 | ファイルの最終更新タイムスタンプ。 |
| Eタグ | Amazon S3によって生成された、ファイルオブジェクトのハッシュ。 |
| サイズ | ファイルサイズ(バイト)。 |
| ストレージクラス | このファイルオブジェクトのstorage class。 通常はS3 Standardです。 |
| 行 | このCSV行の番号。 |
| 列 | このCSV行のすべての列値が含まれます。 ネストされたデータピルを使用して、各列値をマッピングできます。 |
| リストサイズ | CSV行リスト内の行数。 |
最終更新日: