データオーケストレーション - ETL/ELT
Extract, Transform, Load(ETL)およびExtract, Load, Transform(ELT)は、データ統合およびデータウェアハウジングで使用されるプロセスであり、さまざまなソースからデータを抽出、変換、ロードして、データウェアハウスやデータレイクなどのターゲット宛先に取り込みます。
このガイドでは、ELT/ETLの実践的なユースケースを表すサンプルレシピについて、説明付きで解説します。
一括とバッチの比較
一括/バッチアクション/トリガーはWorkato全体で利用できます。 一括処理では、単一のジョブで大量のデータを処理でき、特にETL/ELTに適しています。 バッチ処理はバッチサイズとメモリ制約によって制限されるため、一般にETL/ELTのコンテキストにはあまり適していません。
Extract, Transform, and Load(ETL)
ETLは抽出フェーズから始まり、データベース、ファイル、API、Webサービスなど、複数の異種ソースからデータを取得します。 次に、この生データは変換フェーズ(クレンジング、フィルタリングなど)の対象になります そして最後に、通常はデータウェアハウスであるターゲットシステムにロードされます。
サンプルETLレシピ
動作する例については、サンプルETLレシピを参照してください。
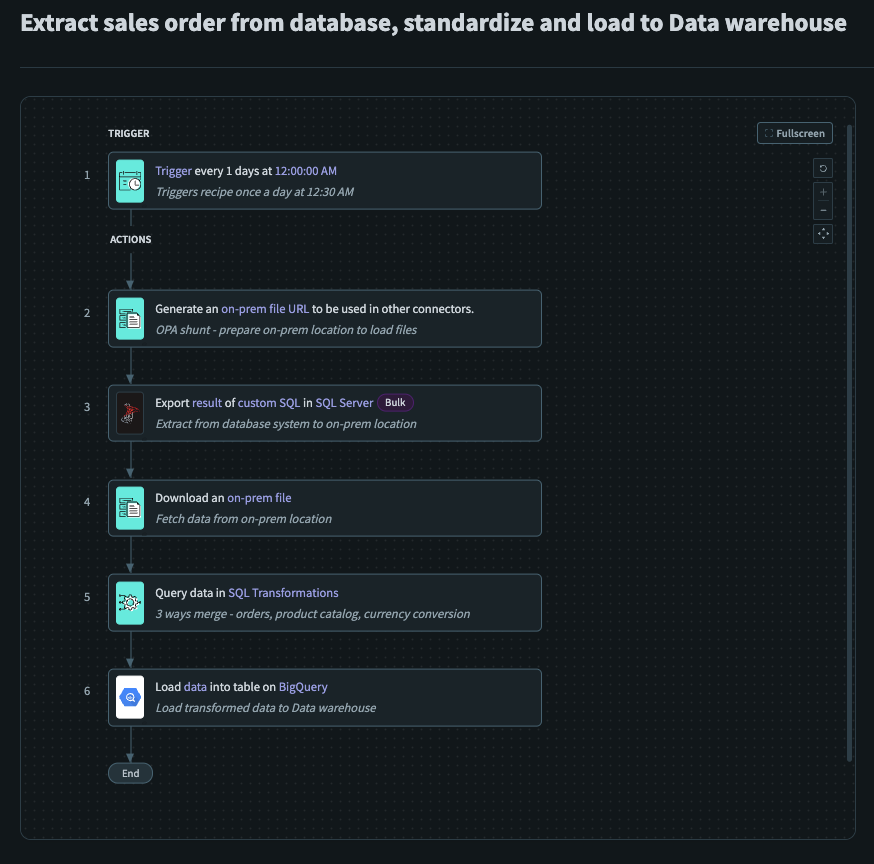 サンプルETLレシピ
サンプルETLレシピ
レシピの内訳
サンプルETLレシピは、オンプレミスデータソース(SQL Server)からデータを抽出し、Workato FileStorageに保存されている製品カタログとマージして、この変換済み出力をデータウェアハウス(BigQuery)にロードする方法のセットアップです。 さらに、Workatoのファイルストリーミング機能により、時間やメモリの制約を気にせずにデータを転送できます。 このレシピはETLレシピを構築する際の一般的なガイドとして機能し、オンプレミスデータソースから抽出したデータに基本的な変換を実行してから、データウェアハウスにロードします。
セットアップ
このレシピでは、背後で追加の手順は必要ありません。
このレシピは毎日0030にスケジュールに基づいてトリガーされます。 このトリガーは、ユースケースに合わせてカスタマイズする必要があります。
後続のファイルのロード先となるオンプレミスの場所を準備するために、オンプレミスファイルURLの生成を使用しました。
必要なSalesデータをSQL Serverから、前のステップで指定したオンプレミスの場所に抽出するために、クエリ結果のエクスポート(バルク)を使用しました。
- 前に作成したオンブレミスファイルにデータをロードします
以前に指定したオンプレミスの場所からSalesデータを取得するために、オンプレミスファイルのダウンロードを使用しました。
- 前に作成したオンブレミスファイルからCSVコンテンツを取得します
SalesデータをWorkato FileStorageから取得したProductデータとマージするために、SQL Transformationsを使用したデータのクエリを使用しました。
- SalesデータとProductデータをマージして、ビジネス要件に適した変換済み出力を生成します
変換されたデータをデータウェアハウスにロードするために、BigQueryへのデータのロードを使用しました。
- 変換済み出力をデータウェアハウスに最終ロードします
Extract, Load, and Transform(ELT)
ETLと同様に、ELTは抽出フェーズから始まり、さまざまなソースからデータが抽出されます。 ELTは、抽出されたデータをデータレイクや分散ストレージなどのターゲットシステムにロードすることに重点を置いています。 データがロードされると、変換はターゲットシステム内で行われます。
サンプルELTレシピ
動作する例については、サンプルELTレシピを参照してください。
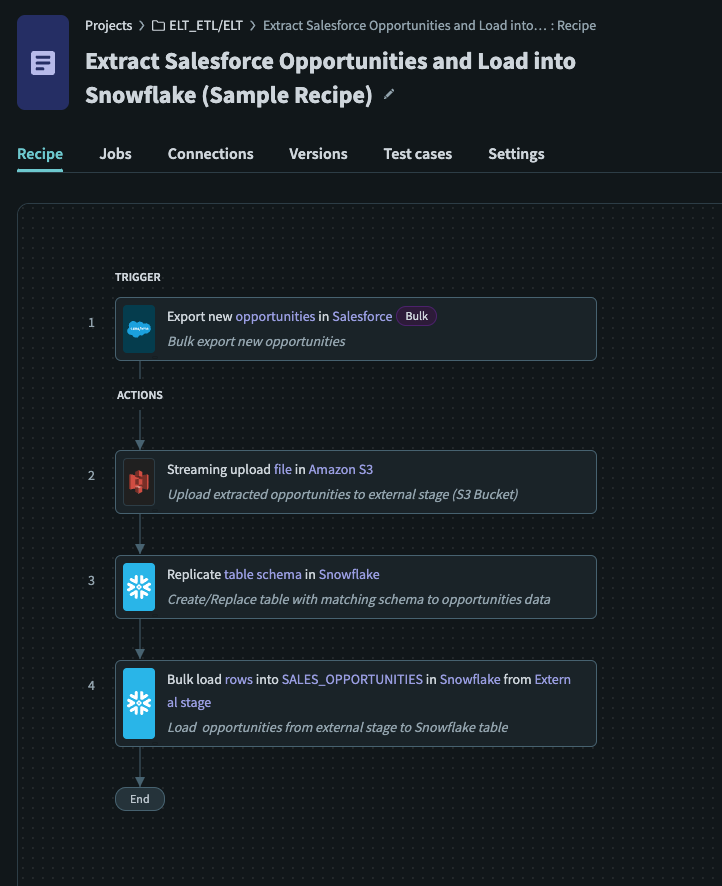 サンプルELTレシピ
サンプルELTレシピ
レシピの内訳
サンプルELTレシピは、クラウドデータソース(Salesforce)からデータウェアハウス(Snowflake)にデータを抽出する方法のセットアップです。 このレシピはELTレシピを構築する際のガイドとして機能し、クラウドデータソースから一括データを抽出してデータベースにロードする基本機能を実行します。
セットアップ
- 必要な権限を持つ外部ステージをSnowflakeで設定しておく必要があります。 詳細については、SnowflakeのCREATE STAGEドキュメントを参照してください。
Export new/updated records (Bulk)をトリガーとして使用して、新しいレシピを作成します。
- ユースケースに応じてトリガーを設定します
- 一括アクションは、1つのジョブで大量のデータを抽出する場合に最適です
抽出されたCSVファイルの内容を指定されたS3 bucketにアップロードするために、S3ファイルのアップロード(ストリーミング)アクションを使用しました。
- アクションは、抽出したデータを指定されたS3バケットにストリーミングします
新規/既存のテーブルを作成/更新するために、Snowflake Replicate Schemaアクションを使用しました。
- このステップは任意です。 ステージング済みデータのスキーマに一致する既存のテーブルがある場合、このステップは不要です
- スキーマの複製により、Snowflakeの宛先テーブルのスキーマが存在し、かつ/またはソースデータに一致する適切なスキーマを持つことが保証されます。
staged filesから既存のテーブルにデータをロードするために、external stageからテーブルへのデータのバルクロードを使用しました。
- 前のステップで設定したステージング済みファイルから、
COPYコマンドを使用して既存のテーブルにデータをロードします
データ変換
このレシピでは、Snowflakeで変換を実行する方法は示していません。 データ変換は、データをテーブルにロードした後、またはその前に実行できます。 詳細については、Snowflakeのステージング済みファイル内のデータのクエリドキュメントを参照してください。
最終更新日: