サンプルユースケース - 変更データキャプチャ
ソースシステムでは毎日新しいデータが利用可能になり、そのデータを取得して宛先システムにロードする必要があります。 多くの場合、ソースアプリケーションは、新規または更新されたデータだけを抽出として提供するのではなく、データの完全な抽出しか提供できません。 そのため、受信データを履歴データと照合し、比較して2つの差分のみを抽出する必要があるため、新規/更新データの取得と取り込みが困難になります。
SQL Transformationsを使用すると、ユーザーは1つのアクションで履歴データと受信抽出を簡単に比較し、差分のみを取得できます。 履歴データはWorkato FileStorage内に永続的に保存できるため、外部データベースへの依存関係を軽減でき、抽出ごとに更新できます。 受信データは、任意のビジネスアプリケーション、データベース、またはファイルシステムから取得できます。
SQL Transformationsは抽出を取得し、永続化された履歴データと比較して、変更されたデータを出力として生成します。 このユーティリティは、数百万行規模のデータ量を簡単に処理できるほど強力です。
サンプルレシピ:オンプレミスシステムから抽出を取得し、変更されたデータを見つけてS3にロード
次のビジネスプロセスを持つ会社のシナリオを考えてみます。
その会社は毎日すべての連絡先を抽出し、オンプレミスシステム上でCSVデータファイルとしてレコードを利用できるようにします。 会社は、この抽出から新しく追加された連絡先のみを取得し、S3などのクラウドストレージ宛先に送信したいと考えています。 その後、別のWorkatoレシピがここからこの情報を取得して、ターゲットマーケティングを実行します。
連絡先の量が非常に多いため(約150万レコード)、この会社の一般的なワークフローは多数のステップで構成されます。 Workatoレシピがソースからデータを抽出し、会社はすべての連絡先を履歴データとして外部データベースに保存し、新しい抽出を別のテーブルにロードして、変更されたデータを取得するために2つのテーブルの差分を見つける必要があります。 その後、さらに処理するためにデータをWorkatoにロードし直す必要があります。
このプロセスは非常に煩雑で、外部データベースシステムへの依存関係が生じます。
SQL Transformationsを使用すると、同じワークフローを3つの簡単なステップで実現できます。
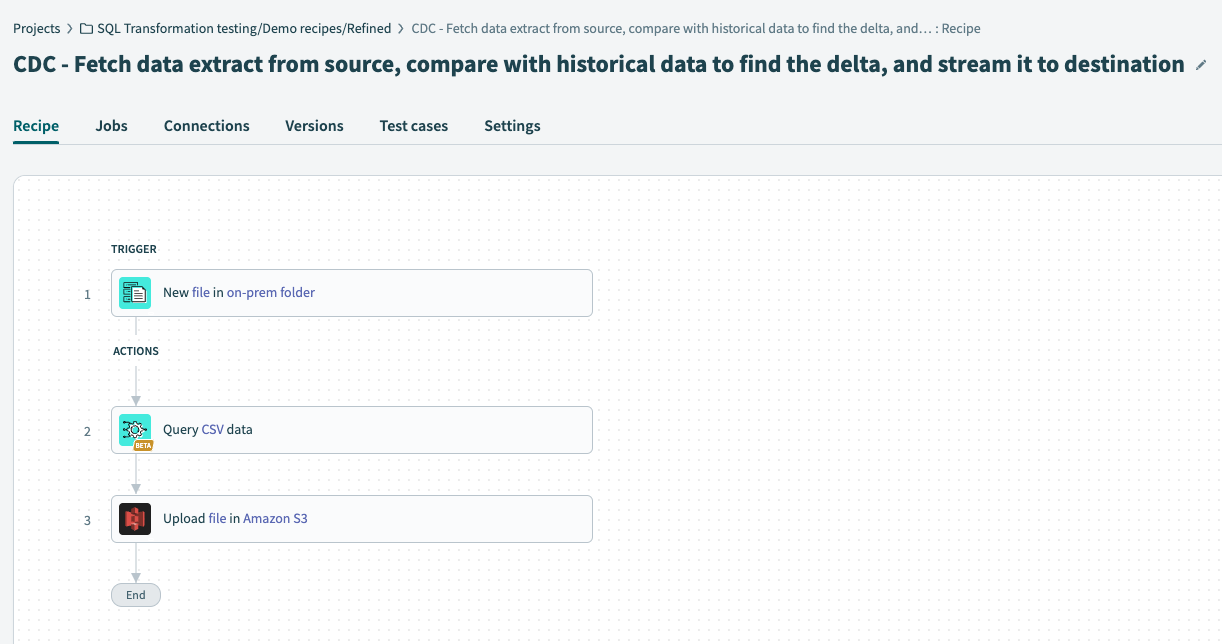 レシピワークフロー
レシピワークフロー
レシピトリガーで、データを抽出する予定のソース(オンプレミスシステム)を設定し、新しい受信抽出を探すように設定します。
SQL TransformationsコネクターのQuery CSVアクションを設定します。このアクションは、抽出を履歴データと比較し、変更されたデータを出力として生成できます。
データをS3などのクラウドストレージ宛先に送信します。
変更データキャプチャにSQL Transformationsを活用する方法
このセクションでは、Query CSVアクションのさまざまなセクションを設定し、変更データキャプチャにSQL Transformationsを活用する方法について説明します。
一緒に進める
このレシピリンクを参照して、サンプルレシピを確認し、自分のワークフローに合わせて変更してください。
データソースのセットアップ
SQL Transformationsがクエリを実行するさまざまなデータソースを接続します。
ソース#1を接続するには、次のフィールドに入力します。 この例では、ソース#1はオンプレミスシステムからの受信抽出データです。
データソース名
Data source nameにわかりやすい名前を付けます。例:contacts_extract。
データソースタイプ
データソースタイプを選択します。 この例では、CSVデータが上流のオンプレミスシステムから送られてくるため、これはCSVコンテンツストリームです。
CSVストリーム入力
データソースをCSVコンテンツストリームとして設定したら、CSVストリーム入力を設定できます。 ここで、オンブレミスファイルトリガーから送られてくるファイルコンテンツを渡します。
データスキーマ
データスキーマを設定します。 これは、いくつかのサンプル連絡先データを含むCSVファイルをインポートすることで簡単に実行できます。
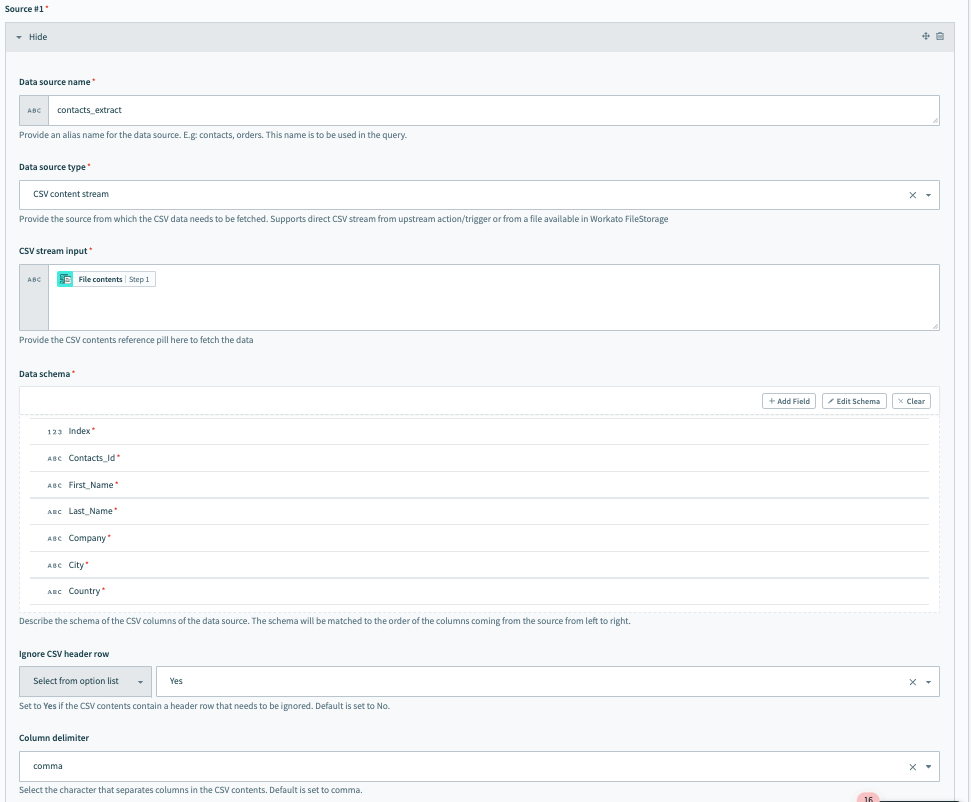 Source #1、受信データ抽出の設定
Source #1、受信データ抽出の設定
CSV固有のオプションを構成します。 これには次のフィールドが含まれます。
CSVヘッダー行を無視
これによりユーザーは、受信データに、無視してデータの一部として扱わない見出し列があるかどうかを指定できます。
列区切り文字
CSVファイルで列を区切るために使用する区切り文字を選択します。 使用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
Source 2に接続するには、次のフィールドに入力します。 この例では、このソースは履歴データを指します。 Workatoの内部永続ファイルストレージシステムであるFileStorageを使用すると、このデータを簡単に保存および処理できます。
データソース名
Data source nameには、contacts_historicalなどのわかりやすい名前を付けます。
データソースタイプ
データソースタイプを選択します。 この例では、これはFileStorageファイルです。
FileStorageファイルパス
履歴データファイルが利用可能なFileStorage内のパスを指定します。
データスキーマ
データスキーマを設定します。 これは、いくつかのサンプル連絡先データを含むCSVファイルをインポートすることで簡単に実行できます。 スキーマは、ソースから渡される列の順序に左から右へ一致します。
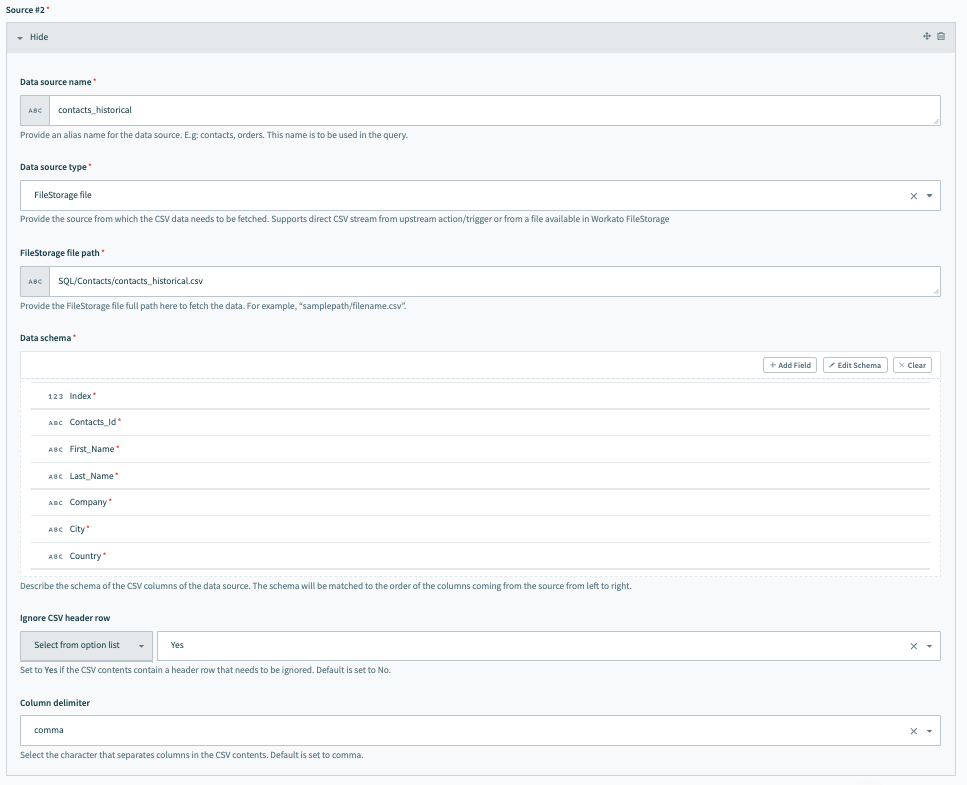 Source #2、履歴データの設定
Source #2、履歴データの設定
CSV固有のオプションを構成します。 これには次のフィールドが含まれます。
CSVヘッダー行を無視
これによりユーザーは、受信データに、無視してデータの一部として扱わない見出し列があるかどうかを指定できます。
列区切り文字
CSVファイルで列を区切るために使用する区切り文字を選択します。 使用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
クエリのセットアップ
次に、データソースに対して動作し、変換済みの出力を生成するクエリを設定します。
この例の目的は、連絡先抽出から新しいレコードのみを取得することです。 そのため、このクエリは2つのデータソース(contacts_extractとcontacts_historical)間でContacts_Idを比較し、Contacts_Idがcontacts_extractには存在するがcontacts_historicalには存在しないレコードを返します。 これは、履歴データに存在しない新しく作成された連絡先をWorkatoが返すことを意味します。
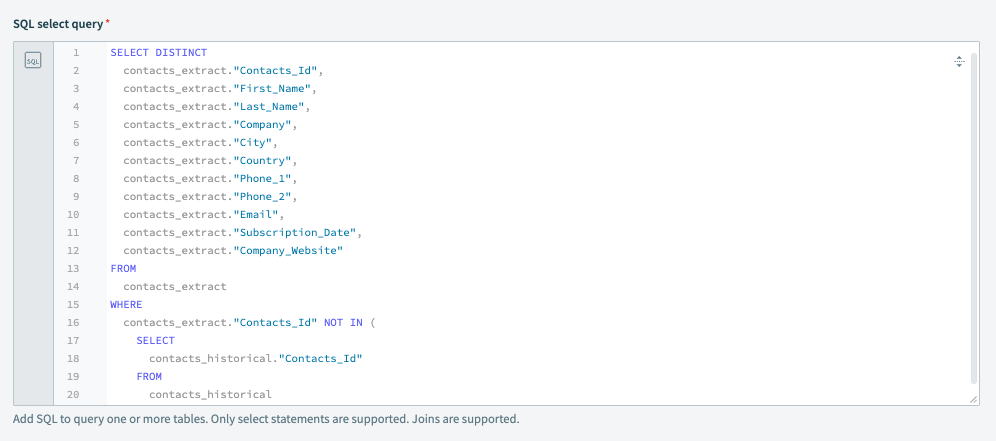
出力のセットアップ
最後に、次のフィールドを設定して出力形式を定義します。
この例では、さらに処理するために新しいレコードデータをS3に送信します。
以下のフィールドに入力します:
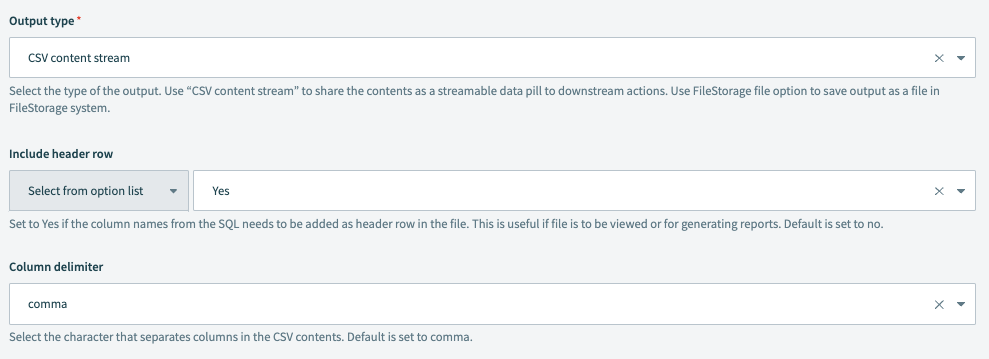
出力タイプ
出力のタイプを選択します。 CSVコンテンツストリームを使用して、コンテンツをダウンストリームアクションにストリーミング可能なデータピルとして共有します。
ヘッダー行を含める
データの列名をファイルにヘッダー行として追加する必要がある場合は、はいに設定します。 これは、ファイルを使用してレポートを生成する予定がある場合に便利です。 デフォルト値はいいえです。
列区切り文字
CSVファイルで列を区切るために使用する区切り文字を選択します。 使用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
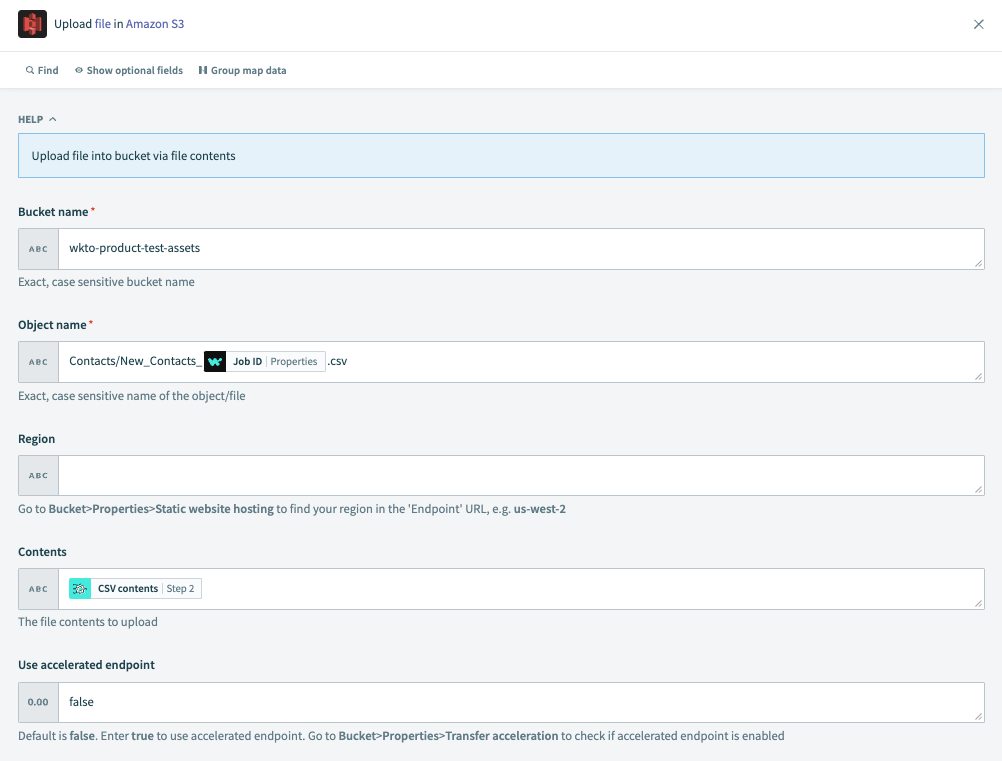
Upload file in Amazon S3アクションを選択します。
次のフィールドを設定します。
バケット名
バケットの正確な名前。大文字と小文字は区別されます。
オブジェクト名
オブジェクト/ファイルの正確な名前。大文字と小文字は区別されます。
地域
リージョンを見つけるには、S3でBucket > Properties > Static website hostingに移動し、
Endpoint URLでリージョンを確認します。 例:us-west-2。内容
アップロードする予定のファイルコンテンツ。 Step 2 Query CSV dataアクションからCSV contentsデータピルを渡します。
Use accelerated endpoint
デフォルトはfalseです。 高速化エンドポイントを使用するには、trueに設定します。 S3でBucket > Properties > Transfer accelerationに移動し、高速化エンドポイントが有効になっているかどうかを確認します。
次に読む
最終更新日: