サンプルユースケース - データの検証とクレンジング
データクレンジングと検証は、適切なデータセットをビジネスアプリケーションに追加するための鍵です。 多くの場合、ソースからの受信データはさまざまな理由で正確でない可能性があるため、ダウンストリームに送信する前に、送信先側の制約を満たすように検証、標準化、フォーマットする必要があります。
SQL Transformationsには、ユーザーが次のことを行えるさまざまな関数が用意されています。
データの検証とクレンジング
SQL Transformationsでは、パターンマッチング、メールアドレスや電話番号の有効性チェック、特定の列にある不要なスペースや特殊文字のトリミングと削除などをサポートしています。
標準化
SQL Transformationsでは、電話番号への国番号や市外局番の追加、名前の各部分の分割または結合、指定された郵便番号が有効であることの確認などを実行できます。
変換
整数と小数を最も近い値に丸める、日付/時刻をある形式から別の形式に変換する、null値を特定のデフォルト値に置き換えるなどを実行します。
サンプルレシピ: オンプレミスソースからリードを抽出し、Marketoにロードする前にデータを検証およびクレンジングする
次のシナリオを考えてみます。
ある会社がオンラインおよびオフラインのマーケティングキャンペーンを積極的に実施しており、その結果、大量のリードが生成されています。 リードはまとめて蓄積され、オンプレミスシステムにCSVファイルとして保存されます。 その会社は、リードを抽出し、基本的な検証ロジックに合格することを確認して、フィルタリングしたリードをMarketoに一括送信することを計画しています。
リード情報は非常に大きいため(約100Kレコード)、通常はWorkatoを使用してすべてのリードを外部データベースに保存し、クエリを実行してリードを検証する必要があります。 次に、クレンジングされたリードを取得してWorkatoに戻し、フィルタリングしてからMarketoにロードする必要があります。
これは非常に面倒で、外部データベースシステムへの依存が生じます。
SQL Transformationsを使用すると、同じワークフローをいくつかの簡単な手順で実現できます。
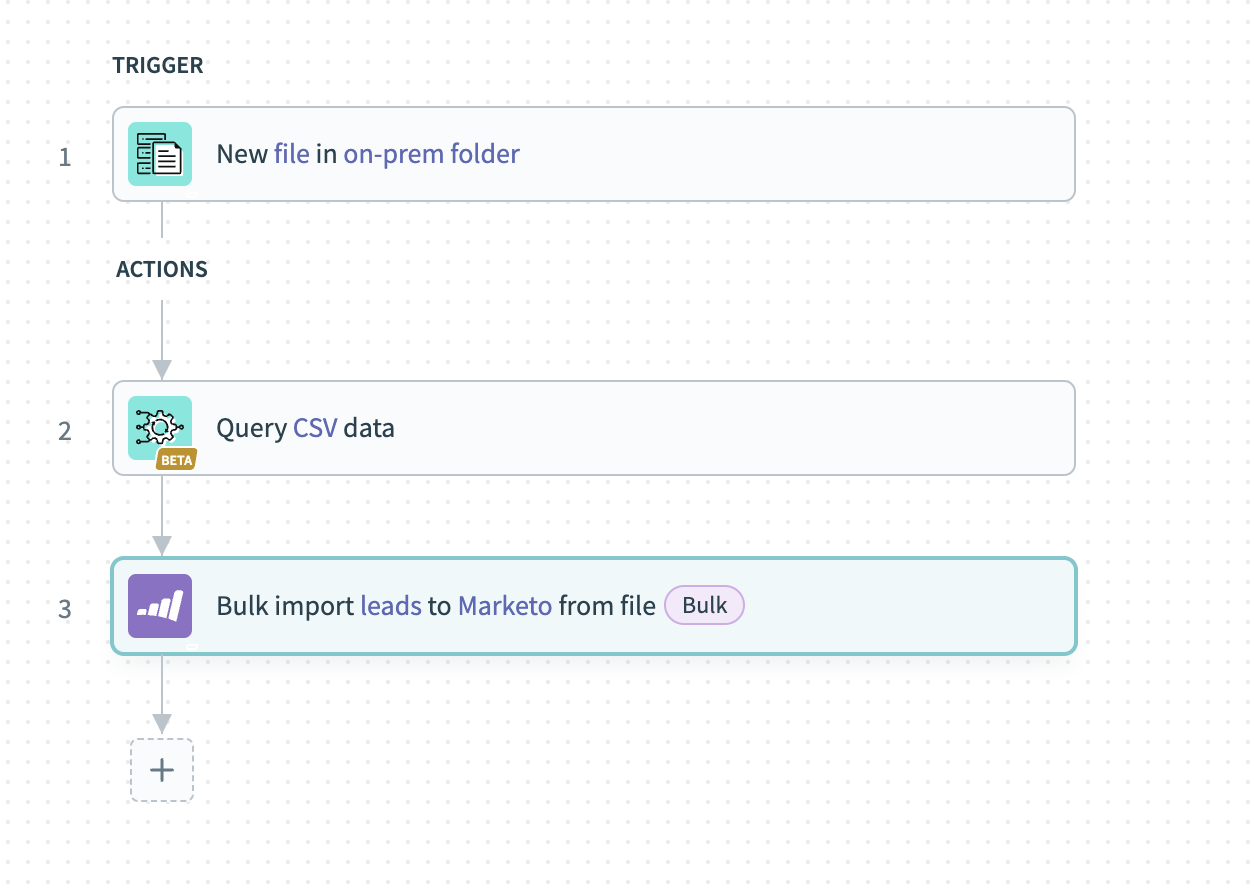
トリガーで、ファイルのソースであるオンプレミスシステムを設定し、新しい受信ファイルを検索するように構成します。
ファイルが使用可能になったら、そのファイルを取得してWorkato FileStorageシステムに保存します。 これはWorkato内のファイルのバックアップとして機能し、何らかの理由でロードに失敗した場合に再利用できます。
次に、SQL TransformationsコネクターからQuery CSVアクションを設定します。このアクションはリードを検証およびフィルタリングして、クレンジングされたデータを生成します。
データをCSVファイルとしてMarketoに送信します。
データの検証とクレンジングにSQL Transformationsを活用する方法
このセクションでは、Query CSVアクションの設定方法について説明します。これにより、データの検証とクレンジングにSQL Transformationsを活用できるようになります。
一緒に進める
このレシピリンクを参照して、サンプルレシピを自分のワークフローに合わせて変更しながら進めてください。
データソースのセットアップ
SQL Transformationsがクエリを実行するさまざまなデータソースを接続します。 ここでは2つのデータソースがあります。
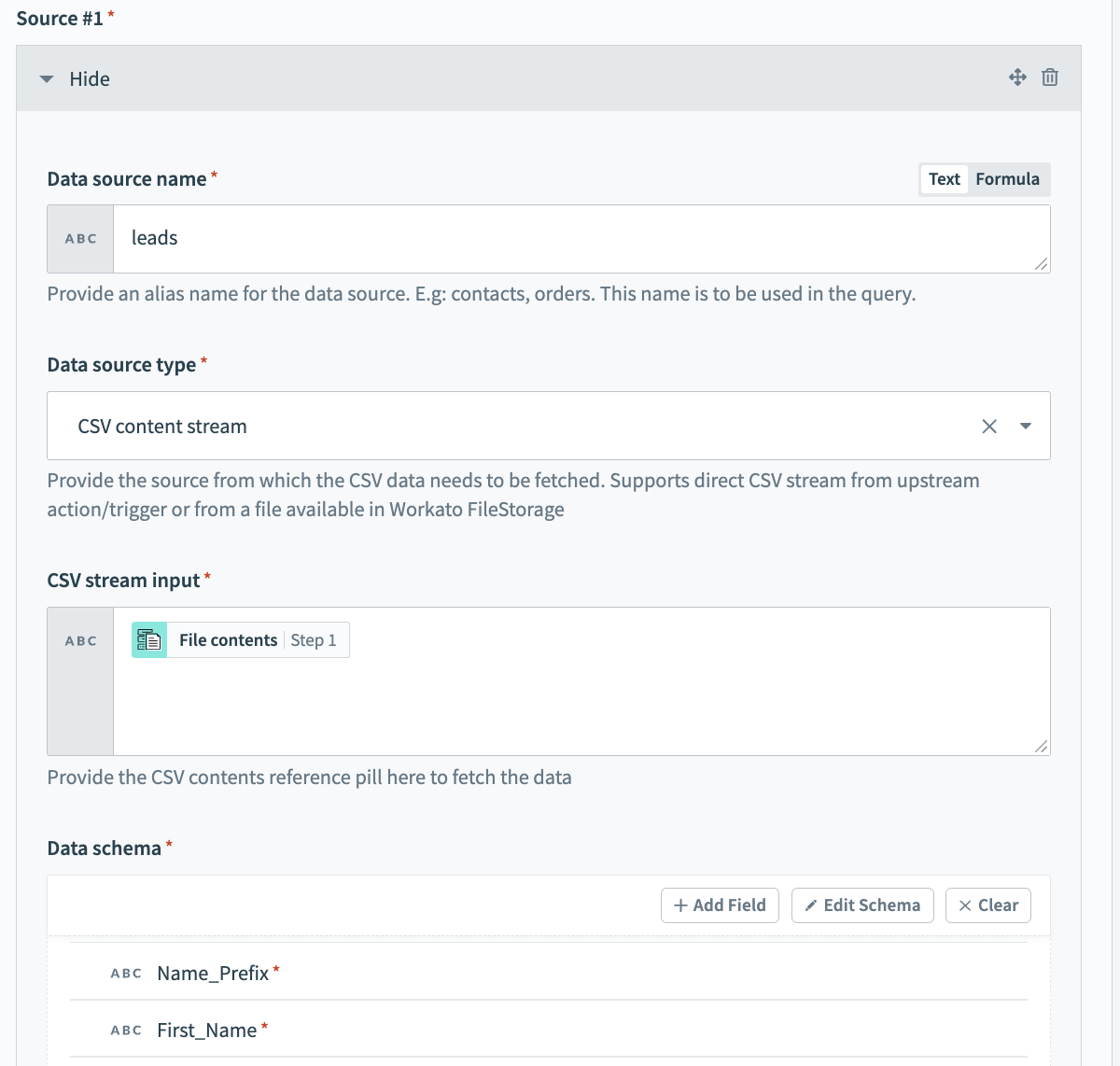
ソース#1を接続するには、次のフィールドに入力します。 この例では、ソース#1はオンプレミスシステムからの受信抽出データです。
データソース名
データソース名にわかりやすい名前を付けます。例: leads。
データソースタイプ
データソースタイプを選択します。 この例では、CSVデータが上流のオンプレミスシステムから送られてくるため、これはCSVコンテンツストリームです。
CSVストリーム入力
データソースをCSVコンテンツストリームとして設定したら、CSVストリーム入力を設定できます。 ここで、オンブレミスファイルトリガーから送られてくるファイルコンテンツを渡します。
データスキーマ
データスキーマを設定します。 これは、いくつかのサンプル連絡先データを含むCSVファイルをインポートすることで簡単に実行できます。
 ソース#1を接続
ソース#1を接続
CSV固有のオプションを構成します。 これには次のフィールドが含まれます。
CSVヘッダー行を無視
これによりユーザーは、受信データに、無視してデータの一部として扱わない見出し列があるかどうかを指定できます。
列区切り文字
CSVファイルで列を区切るために使用する区切り文字を選択します。 使用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
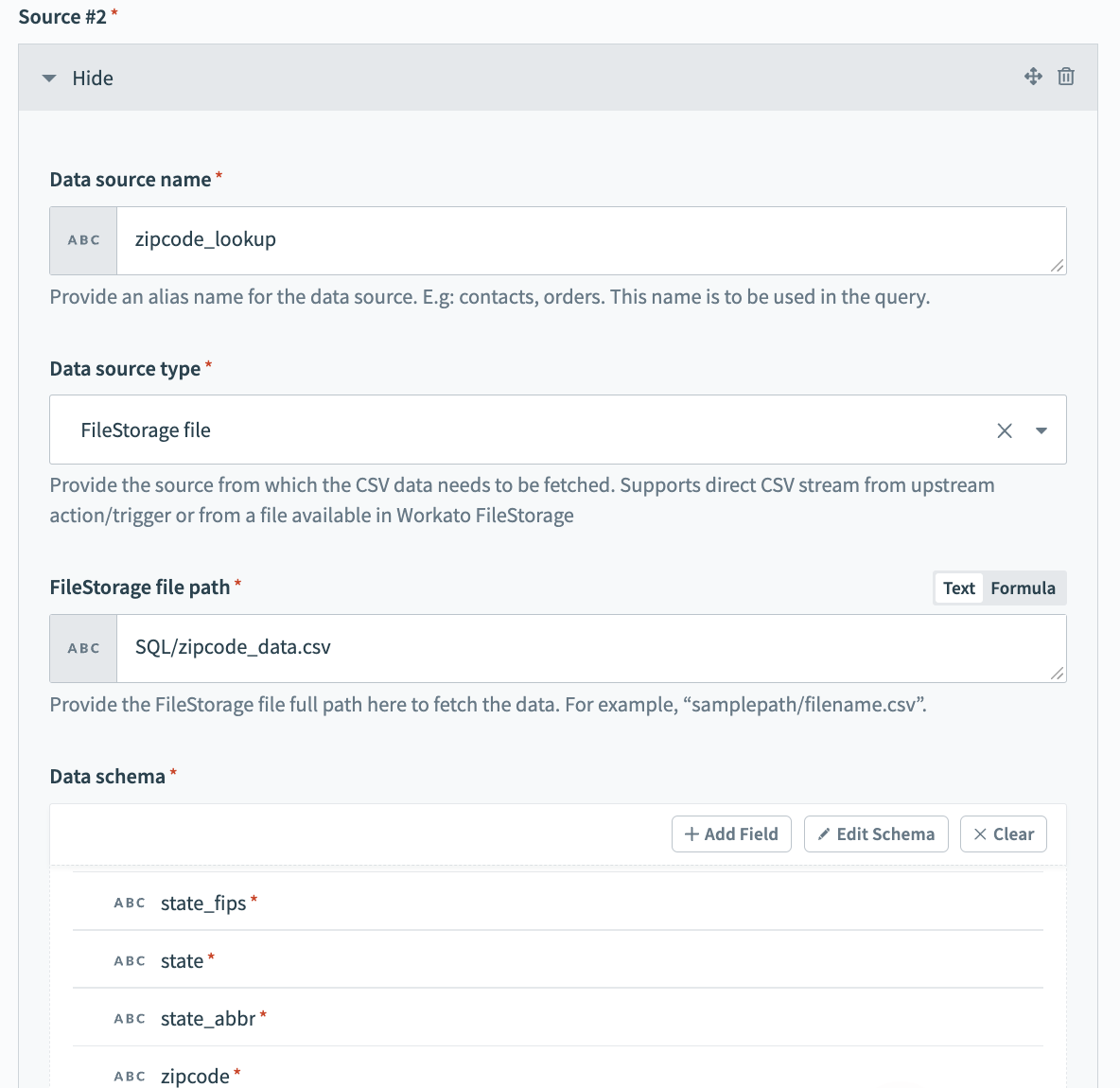
ソース#2を接続するには、次のフィールドに入力します。
データソース名
データソース名にわかりやすい名前を付けます。例: zipcode_lookup。
データソースタイプ
データソースタイプを選択します。 この例では、これはFileStorageファイルです。 このデータは頻繁に再利用でき、あまり変更されないため、Workato独自の内部永続ファイルストレージシステムであるFileStorageを使用すると、このデータを簡単に保存および処理できます。
CSVストリーム入力
データを取得するには、CSV参照データピルを指定します。 この例では、Google Driveのダウンロードアクションからのコンテンツを使用します。
データスキーマ
データスキーマを設定します。 これは、いくつかのサンプル連絡先データを含むCSVファイルをインポートすることで簡単に実行できます。
 ソース#2を接続
ソース#2を接続
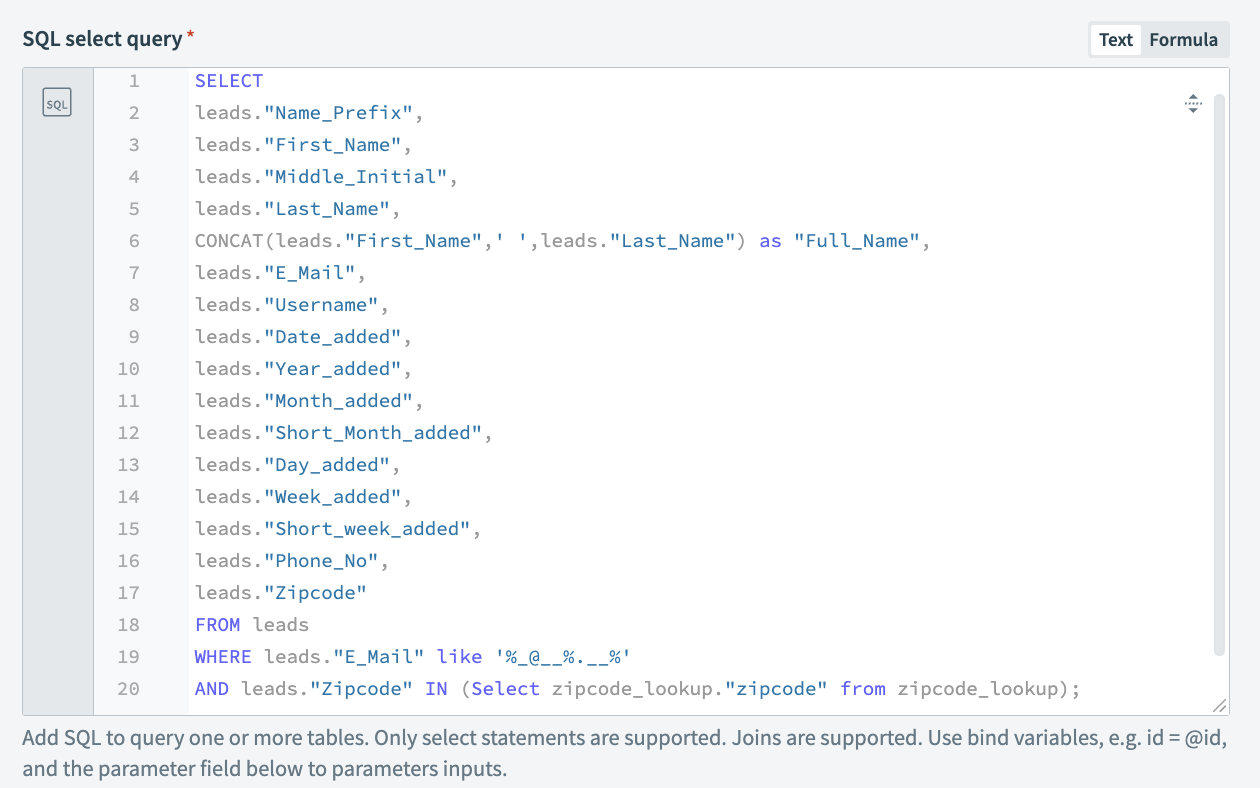
クエリのセットアップ
データソースに対して機能し、変換された出力を生成するクエリを設定します。 この例では、クエリは姓と名を連結してフルネームを標準化し、指定されたメールIDが特定のパターンに従っているかどうかを確認します。また、郵便番号ルックアップファイルと結合することで、指定された郵便番号が有効かどうかも検証します。
出力のセットアップ
最後に、出力の形式を定義します。 クレンジングされたリードをMarketoに送信する予定のため、出力タイプとしてCSVコンテンツストリームを選択します。 つまり、Query CSVデータのCSVコンテンツ出力データピルをMarketo一括アクションのファイル入力セクションに渡すことができ、コンテンツはQuery CSVアクションからMarketoに自動的にストリーミングされます。 また、データソースのセットアップと同様に、ここでは出力CSVコンテンツで使用する区切り文字と、列ヘッダーを含めるかどうかを選択するオプションがあります。
以下のフィールドに入力します:
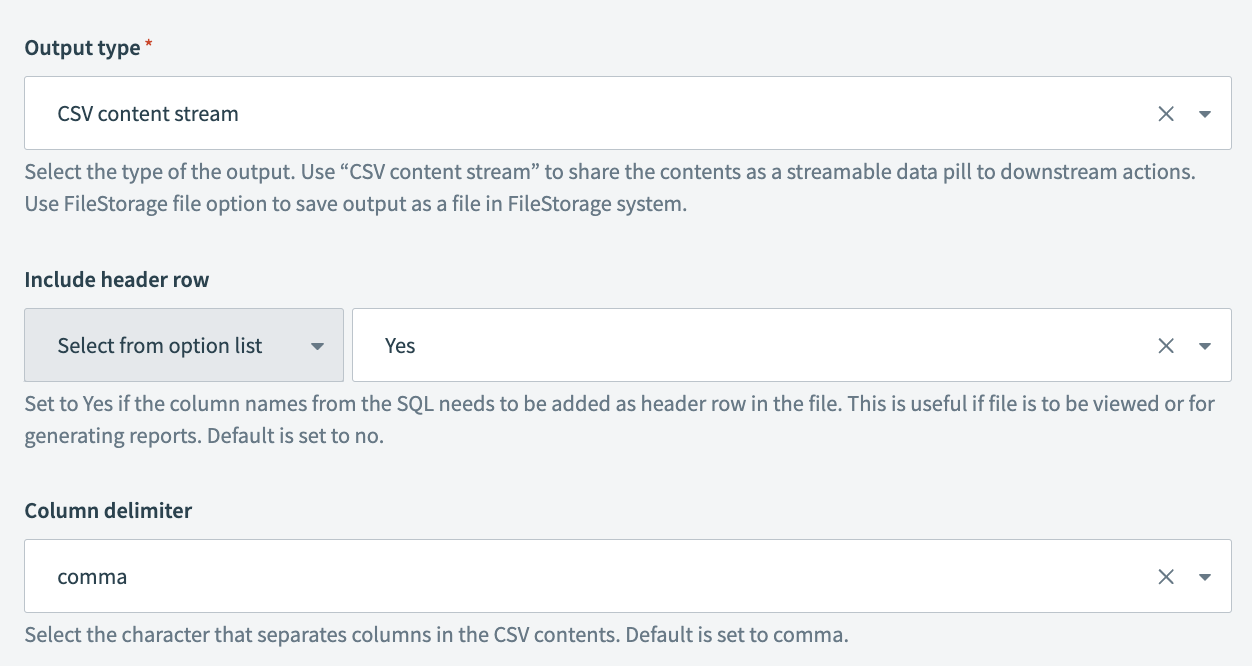
出力タイプ
出力のタイプを選択します。 CSVコンテンツストリームを使用して、コンテンツをダウンストリームアクションにストリーミング可能なデータピルとして共有します。
ヘッダー行を含める
データの列名をファイルにヘッダー行として追加する必要がある場合は、はいに設定します。 これは、ファイルを使用してレポートを生成する予定がある場合に便利です。 デフォルト値はいいえです。
列区切り文字
CSVファイルで列を区切るために使用する区切り文字を選択します。 使用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
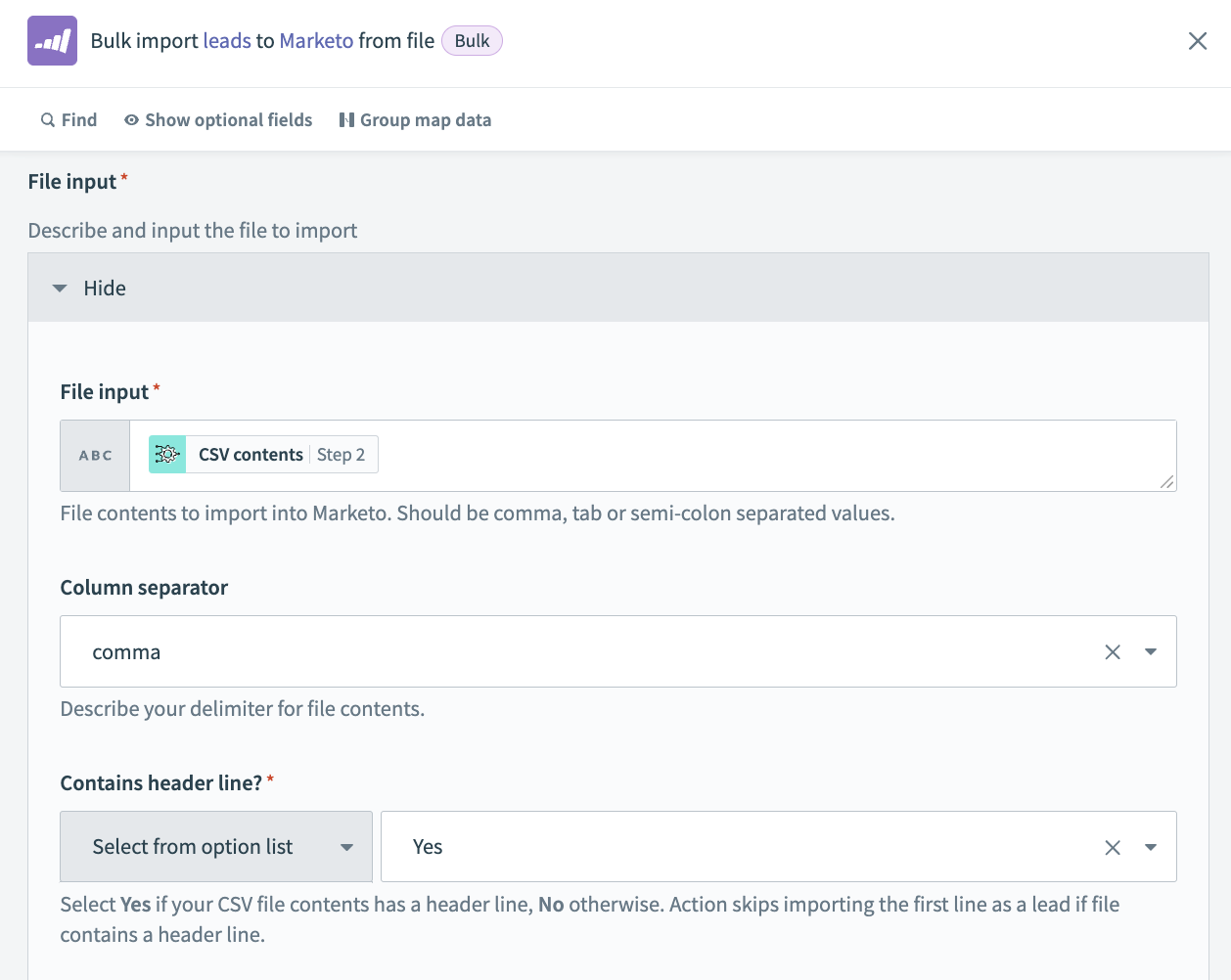
Bulk import leads to Marketo from fileアクションを選択します。
ファイル入力
Marketoにインポートするファイルコンテンツ。 ステップ2のCSVコンテンツをマッピングします。
列区切り文字
CSVファイルで列を区切るために使用する区切り文字を選択します。 使用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
ヘッダー行を含むか?
CSVコンテンツにヘッダー行が含まれている場合は、はいを選択します。 それ以外の場合は、いいえを選択します。 ファイルにヘッダー行が含まれている場合、アクションは最初の行をリードとしてインポートすることをスキップします。
次に読む
最終更新日: