Regex overview
Regex, or regexp (regular expressions) are powerful tools used for matching patterns in text. Regex is a sequence of symbols and characters that expresses a string or pattern. Regex provides a concise and flexible way to identify strings of text that follow a specific pattern. In Workato, you can use regex to extract specific information from a body of text, validate user input, and more.
This document serves as a basic introduction to regex and its usage in Workato. Refer to Ruby doc for a comprehensive guide on regex and its usage.
Use regex in Workato
You can use regex can in various Workato products and features, including:
Formulas: Regex can be used within string formulas to perform complex text manipulations. For example, you can use regex to extract specific parts of a string, validate input formats, or replace text patterns.
Utilities: Workato provides utility connectors that support regex for tasks such as parsing JSON or XML documents. This allows for more precise data extraction and transformation.
Recipes: When you're building recipes, you can use regex in conditions and actions to filter and manipulate data based on specific patterns.
Workbot: Validate that user input matches the format you expect. For example, you can use regex to validate email addresses, URLs, and more.
Workflow apps: Validate that user input matches the format you expect. For example, you can use regex to validate SSNs (Social Security Numbers), IBANs (International Bank Account Numbers), and more.
LIMITATIONS
Workbot and Workflow apps do not support interpolation (the insertion or inclusion of variable content within a regex pattern).
Basic syntax
Regex consists of literal characters (which match themselves) and metacharacters (which have special meanings). Here are some basic elements:
Literal characters
Literal characters match themselves, such as:
a1!
Refer to the literal characters reference table for more examples.
Metacharacters
Metacharacters are special characters with predefined meanings. For example:
.: Matches any single character.*: Permits zero or more occurrences of a character or range of characters.+: Permits one or more occurrences of a character or range of characters.
Refer to the metacharacters reference table for more examples.
Usage examples
Match a specific pattern
The following example demonstrates how to use regex to match a specific pattern:
/hello/matches the sequencehelloin a string.
Character classes
Character classes are a way to specify a set of characters that you plan to match. By using a character class, you can tell the regex engine to match any one of several characters or ranges of characters.
/[a-z]/matches any lowercase letter./[0-9]/matches any digit.
Quantifiers
Quantifiers in regex specify how many times an element in the pattern should be matched. They are crucial for controlling the repetition of characters, groups, or character classes in regex patterns.
/a*/matches zero or more occurrences ofa./b+/matches one or more occurrences ofb./c?/matches zero or one occurrence ofc.
Anchors
Anchors are special characters that specify positions within a string rather than matching characters. They are used to indicate the beginning or end of a string or a line or to define positions relative to other characters.
^matches the start of a line.$matches the end of a line.
Escape sequences
\dmatches any digit.\wmatches any word character, including alphanumeric characters and_(underscore).
Grouping and capturing
/(abc)+/matchesabc,abcabc, and similar repetitions of a pattern that you define.
Practical examples
The following examples demonstrate how to use regex to match specific strings of text, such as email addresses, SSNs, URLs, and more.
IBAN (International Banking Account Number)
IBAN (International Banking Account Number) formats vary by country. The following regex pattern covers many standard IBAN formats:
^[A-Z]{2}[0-9]{2}[A-Z0-9]{1,30}$View a detailed explanation
^[A-Z]{2}: Two uppercase letters (country code)[0-9]{2}: Two digits (check digits)[A-Z0-9]{1,30}: Between 1 and 30 alphanumeric characters
Social Security Number (SSN)
The following pattern matches US SSNs (Social Security Numbers).
^\d{3}-\d{2}-\d{4}$View a detailed explanation
^\d{3}: Three digits at the beginning\d{2}: Hyphen followed by two digits\d{4}: Hyphen followed by four digits
ZIP Codes/postal codes
ZIP Codes (US)
US ZIP Codes can be either five digits or nine digits (ZIP+4 format). The following regex covers both:
^\d{5}(-\d{4})?$EU zip codes
^\d{4,5}([-\s]?\d{3})?$View a detailed explanation
^\d{4,5}: Matches four or five digits at the beginning, which is common in many EU postal codes.([-\s]?\d{3})?: Optionally matches a space or hyphen followed by 3 digits, accommodating formats like those in the Netherlands or Portugal.$: Asserts the end of the string.
Japan postal codes
Japanese postal codes are formatted as three digits, a hyphen, and four digits:
^\d{3}-\d{4}$View a detailed explanation
^\d{3}: Three digits at the beginning\d{4}: Hyphen followed by four digits
Singapore postal codes
Singapore postal codes are six digits:
^\d{6}$View a detailed explanation
^\d{6}: Matches exactly six digits.
Australian postal codes
Australian postal codes are four digits:
^\d{4}$View a detailed explanation
^\d{4}: Matches exactly four digits.
Email addresses
Use the following regex to match email addresses:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$View a detailed explanation
^: Anchors the regex to the beginning of the string, ensuring that the entire string starts with the pattern defined next.[a-zA-Z0-9._%+-]+: This represents the local part of an email address before the @ symbol. It matches one or more occurrences (+quantifier) of any alphanumeric character (a-z,A-Z,0-9), as well as the characters._%+-. This represents the local part of an email address before the@symbol.@: Matches the literal@character that separates the local part from the domain part of the email address.[a-zA-Z0-9.-]+: This represents the domain name part of the email address. It matches one or more occurrences (+quantifier) of any alphanumeric character (a-z,A-Z,0-9), as well as the characters.and-.\.: Escapes the.character so that it matches a literal.. In regex,.is a metacharacter that matches any single character, so it must be escaped with\to match a literal..[a-zA-Z]{2,}: This represents the top-level domain (TLD) part of the email address, and ensures it consists of at least two letters (such as,.com,.net, or.org). It matches any uppercase or lowercase letter (a-z,A-Z) that occurs at least two times ({2,}).$: Anchors the regex to the end of the string. This ensures that the entire string matches the pattern defined from start (^) to end ($).
URLs
/^(https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([\/\w .-]*)*\/?$/View detailed explanation
^: Anchors the match at the start of the string.(https?:\/\/)?:https?matcheshttporhttps. Thes?makes the "s" optional, so it matches bothhttpandhttps.:\/\/matches the literal://.- The entire part is optional because of the
?at the end. This allows matching URLs without the protocol (www.example.com).
([a-zA-Z0-9-]+(\.[a-zA-Z0-9-]+)+):[a-zA-Z0-9-]+matches the domain name parts (exampleorsub-domain).(\.[a-zA-Z0-9-]+)+matches the.followed by another domain part (.com,.co.uk). The+allows multiple such sections (for subdomains, TLDs, and others).
(:[0-9]{1,5})?:(:[0-9]{1,5})matches an optional port number. It starts with a colon:and is followed by 1 to 5 digits (:8080).- The
?makes the port section optional.
(\/[^\s]*)?:\/matches the forward slash/that typically starts the path.[^\s]*matches any character that is not a whitespace ([^\s]), zero or more times (*), which covers the rest of the URL path, query parameters, and fragments.- The
?makes this part optional, so it matches URLs without paths as well.
$: Anchors the match at the end of the string.
Process multiple regex matches
When parsing unstructured text that contains multiple records, use .scan() with a Repeat while loop to extract and structure the data.
Why this pattern is needed
Many systems output unstructured text rather than JSON:
- Email alerts from monitoring systems
- Log files from applications
- Exported reports from legacy systems
When this text contains multiple records, you need to extract each field and recombine them into structured data.
Example: Extract structured data from text
Given text with multiple records like this:
Order: #1001, Customer: Alice, Status: Shipped
Order: #1002, Customer: Bob, Status: Pending
Order: #1003, Customer: Carol, Status: DeliveredFollow these steps to extract and structure this data into a list of objects:
Create a variable to store your text data. Use the Create variable action and name it email_content.
View screenshot
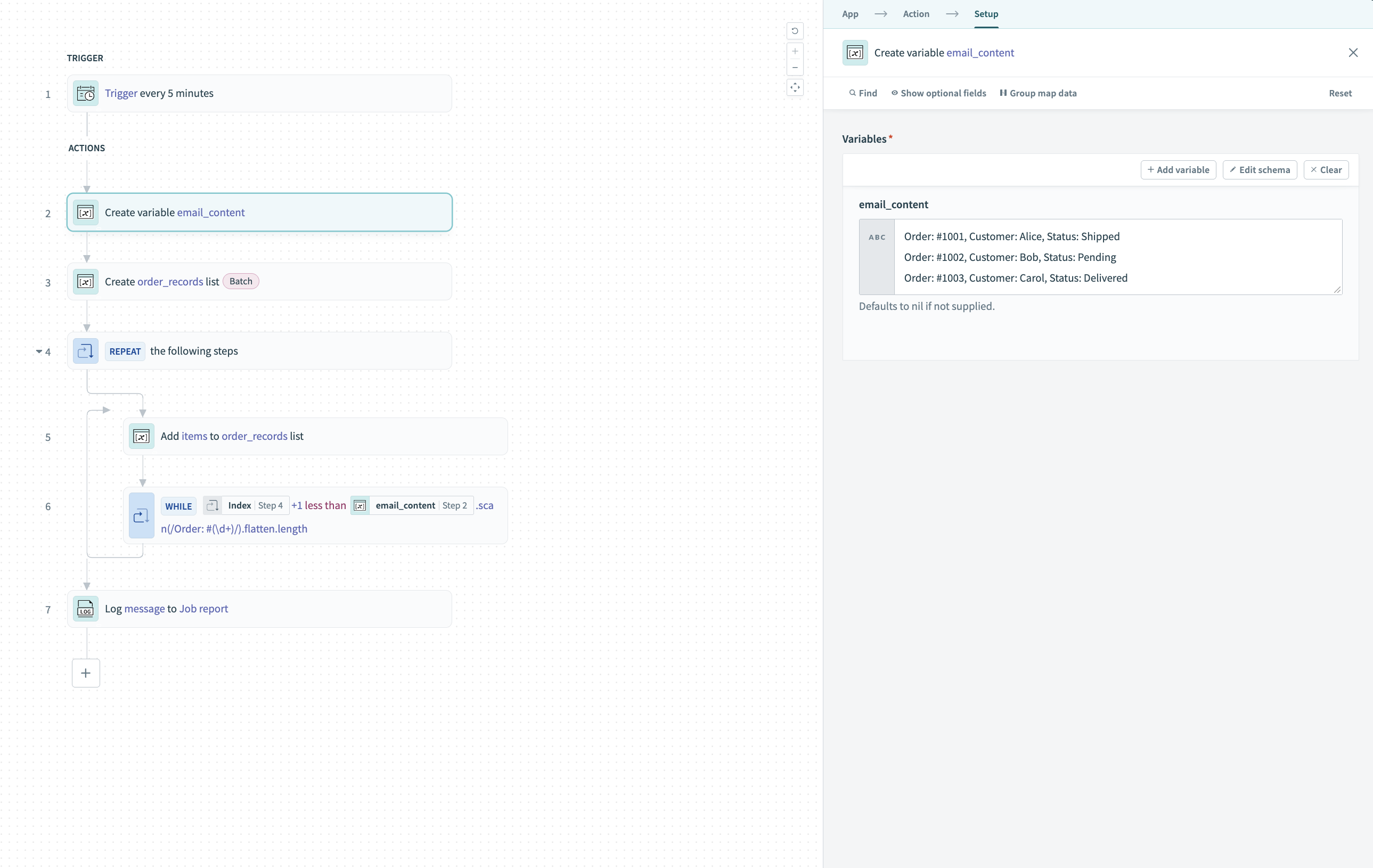 Configure the email_content variable
Configure the email_content variable
Create an empty list with your desired schema. Use the Create list action with:
- List name:
order_records - List item schema with three fields:
order_numbercustomer_nameorder_status
View screenshot
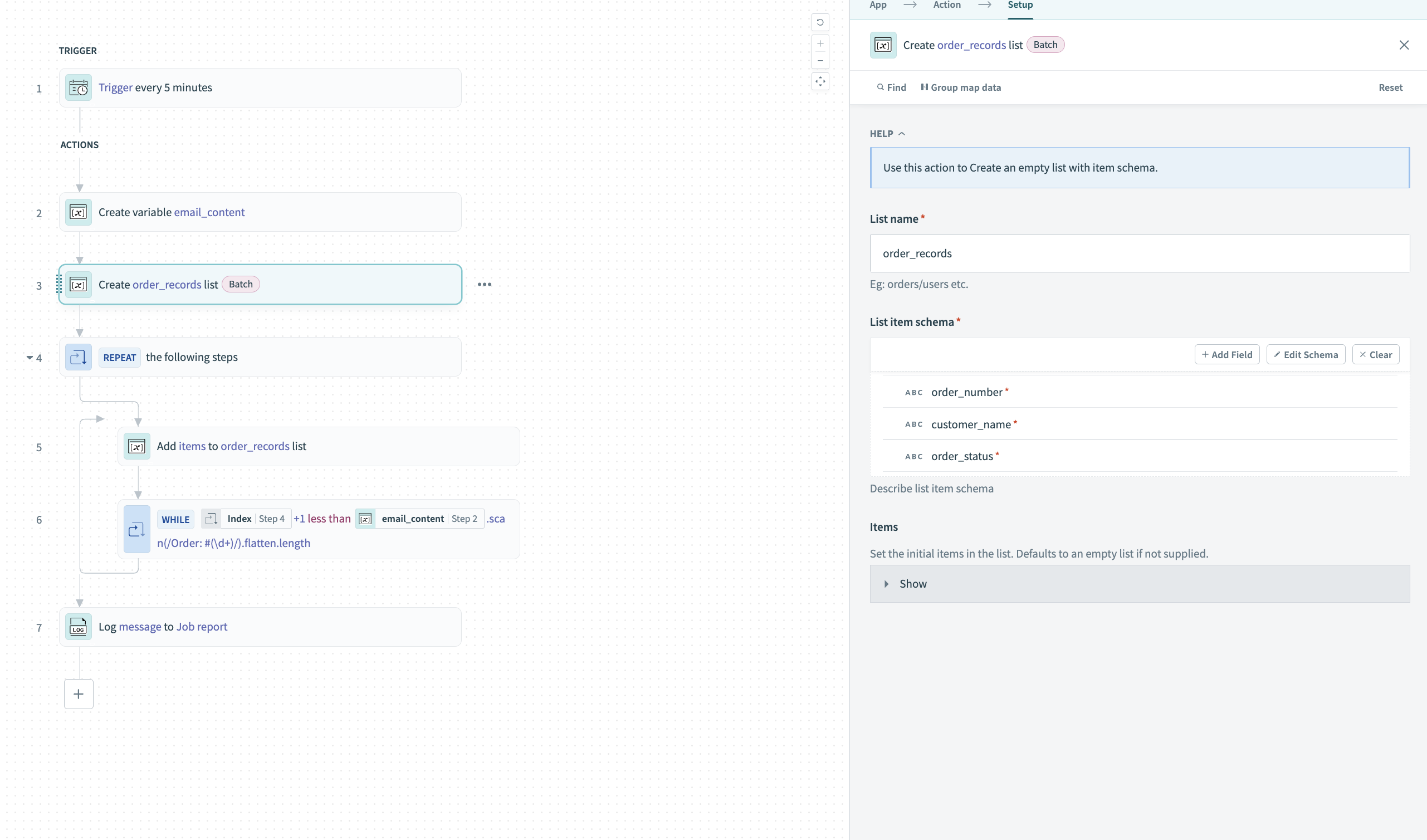 Define the list schema
Define the list schema
Add a Repeat while action to your recipe. This creates a loop that will iterate through each record in your text.
View screenshot
 Add Repeat while loop
Add Repeat while loop
Inside the Repeat while loop, add an Add items to list action and select the order_records (step 3) list.
Configure each field with an inline .scan() formula that extracts data using the loop's IndexStep 4:
Each formula runs .scan() on the text, extracts all matches, flattens the result, then accesses the current position using IndexStep 4.
View screenshot
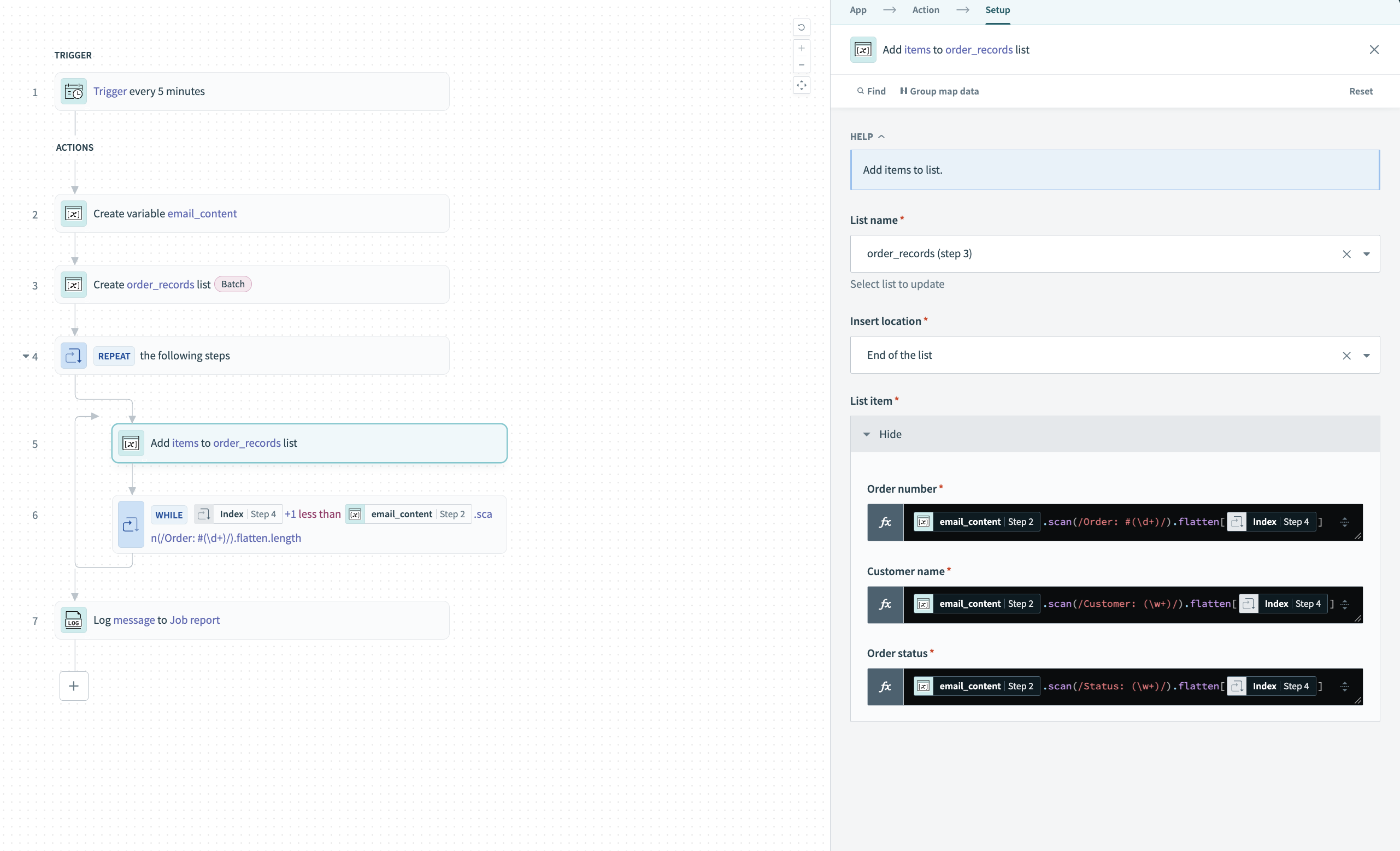 Configure the fields with inline formulas
Configure the fields with inline formulas
Configure the Repeat while loop's WHILE condition to continue looping while there are more records to process.
Condition: less than
This compares the current IndexStep 4 to the total number of records found by running .scan() and counting the array length.
View screenshot
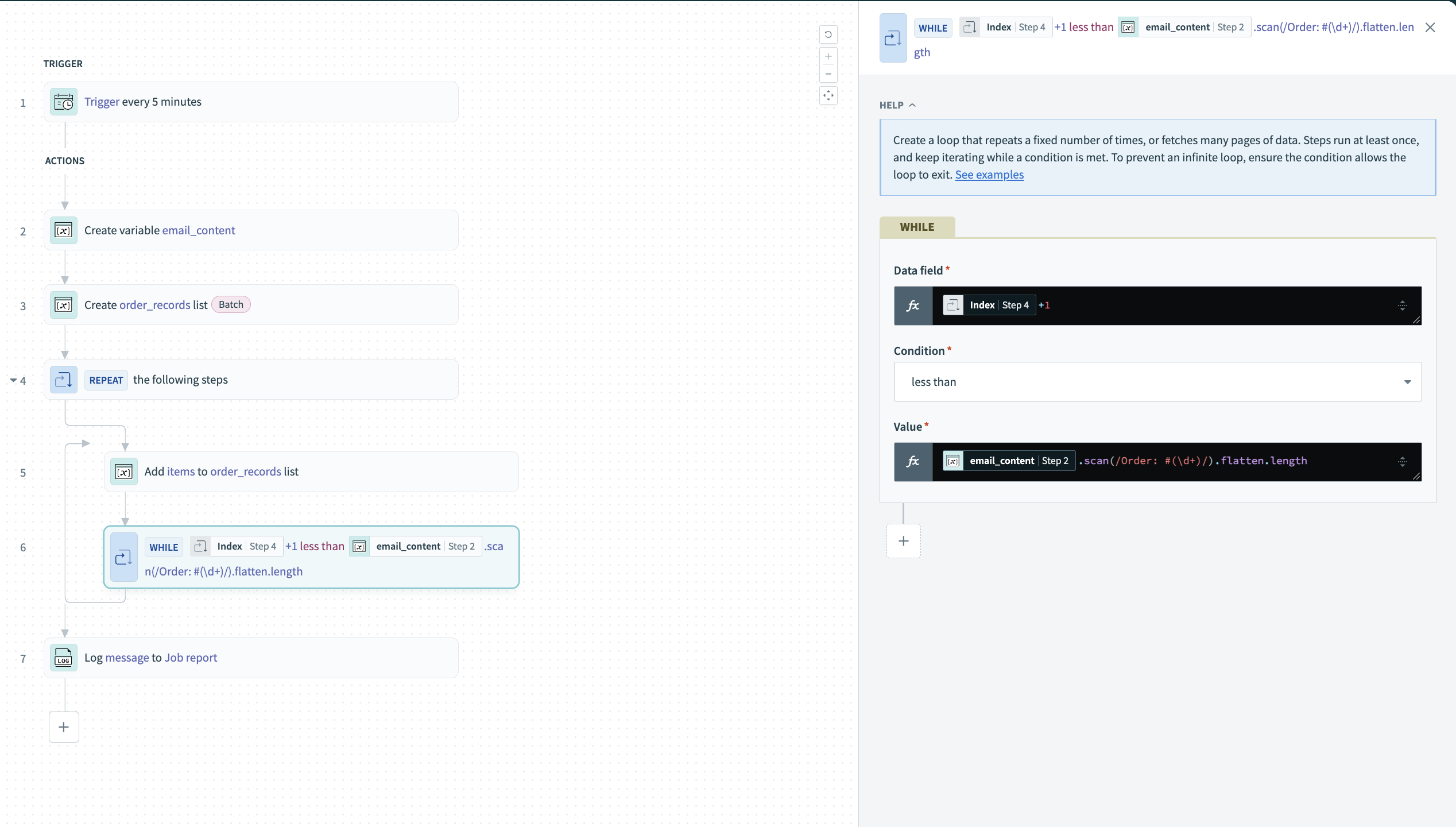 Set the loop condition
Set the loop condition
Add a Log message to Job report action to output the structured list. This helps verify the results and makes the data available for subsequent recipe steps.
Use the order_recordsStep 3 list datapill to log the complete structured data.
View screenshot
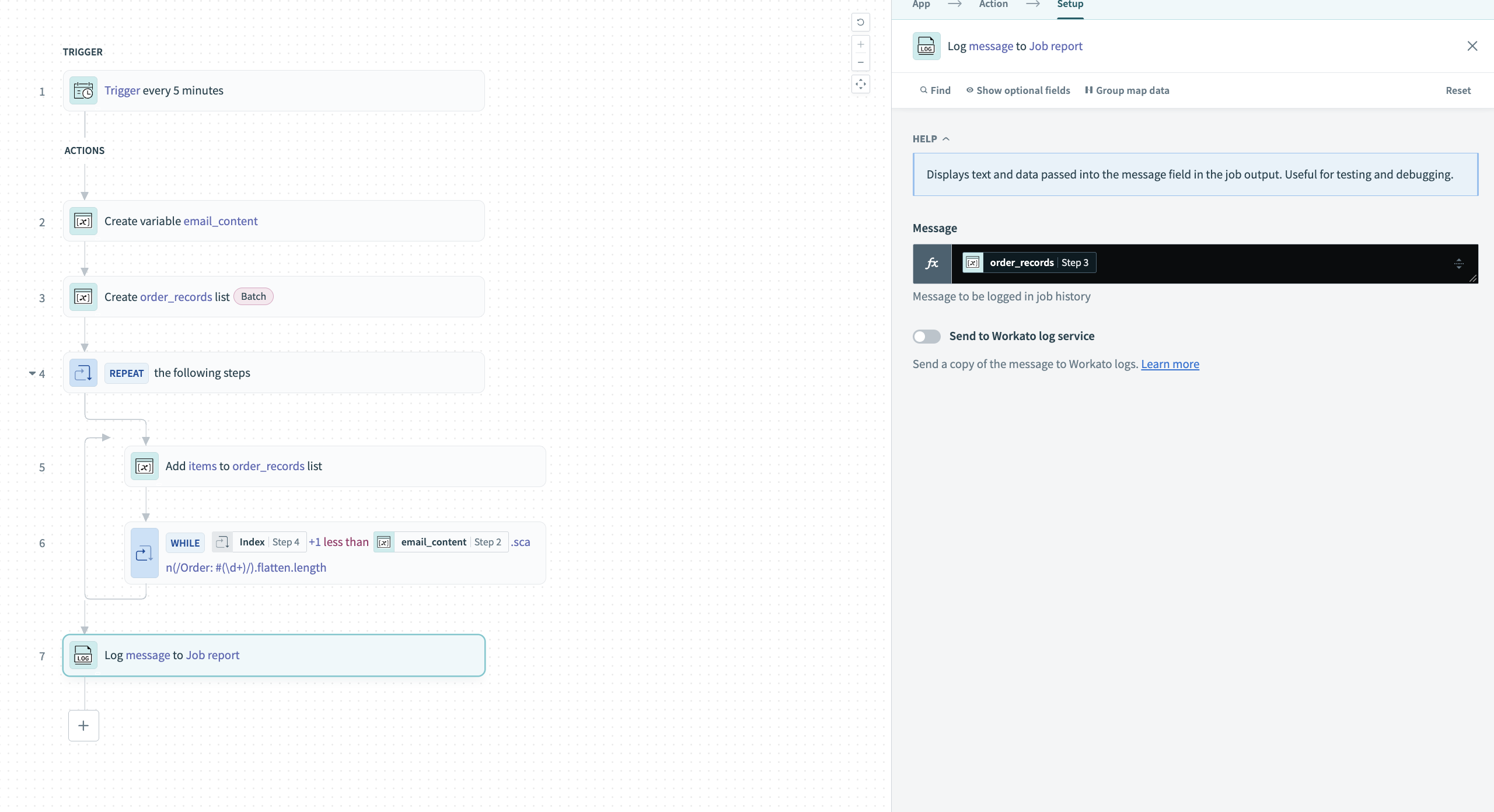 Log the structured order_records list
Log the structured order_records list
Result: After the recipe runs, the order_records list contains three structured records:
- Order #1001, Alice, Shipped
- Order #1002, Bob, Pending
- Order #1003, Carol, Delivered
View output screenshot
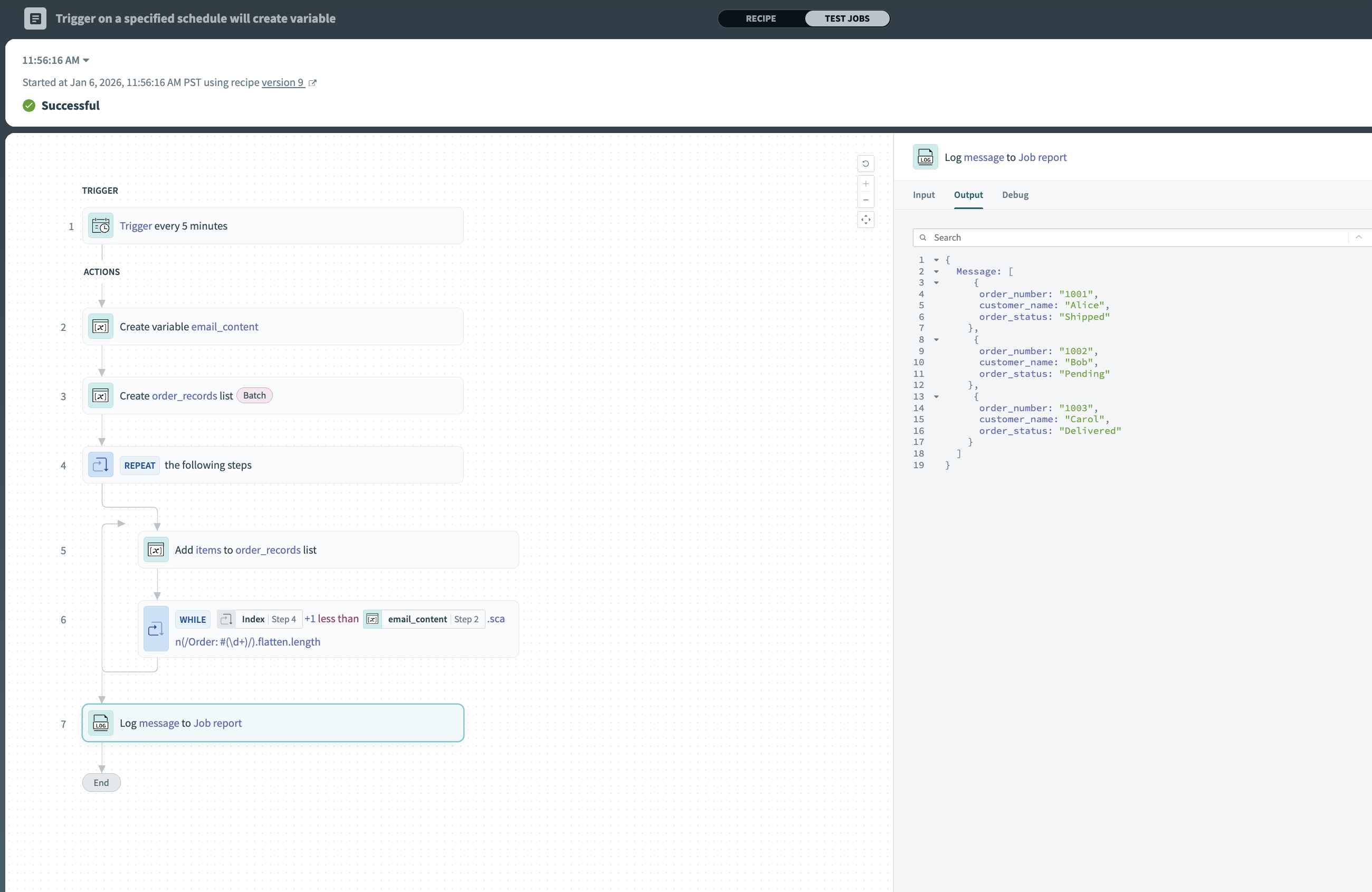 The structured list output in the job report
The structured list output in the job report
Reference
Literal characters
| Literal Character | Description |
|---|---|
All letters, a to z | Matches the lowercase letter (a-z). |
All letters, A to Z | Matches the uppercase letter (A-Z). |
All numbers, 0 to 9 | Matches the digit (0-9). |
! | Matches the exclamation mark. |
" | Matches the double quote. |
# | Matches the hash symbol. |
% | Matches the percent sign. |
& | Matches the ampersand. |
' | Matches the single quote. |
, | Matches the comma. |
- | Matches the hyphen (except when used in a character class). |
: | Matches the colon. |
; | Matches the semicolon. |
< | Matches the less-than sign. |
= | Matches the equals sign. |
> | Matches the greater-than sign. |
@ | Matches the at symbol. |
_ | Matches the underscore. |
` | Matches the backtick. |
~ | Matches the tilde. |
Metacharacters
| Metacharacter | Description |
|---|---|
. | Matches any single character except newline (\n). |
^ | Anchors the regex to the beginning of the string. |
$ | Anchors the regex to the end of the string. |
\ | Escapes a metacharacter, allowing it to be used as a literal character. |
[] | Defines a character class, allowing any character within the brackets to match. |
[^] | Defines a negated character class, matching any character not within the brackets. |
- | Indicates a range within a character class. |
| ` | ` |
() | Groups expressions together, allowing quantifiers (*, +, ?, {}) to apply to the entire group. |
* | Matches zero or more occurrences of the preceding element. |
+ | Matches one or more occurrences of the preceding element. |
? | Matches zero or one occurrence of the preceding element (optional). |
{} | Specifies the exact number of occurrences or a range of occurrences of the preceding element. |
\b | Matches a word boundary. |
\B | Matches a non-word boundary. |
\d | Matches any digit character (equivalent to [0-9]). |
\D | Matches any non-digit character (equivalent to [^0-9]). |
\w | Matches any word character (alphanumeric plus underscore, equivalent to [a-zA-Z0-9_]). |
\W | Matches any non-word character (equivalent to [^a-zA-Z0-9_]). |
\s | Matches any whitespace character. |
\S | Matches any non-whitespace character. |
(?...) | Specifies non-capturing groups, lookaheads, lookbehinds, and more, depending on what follows the ?. |
Last updated: