OpenAI - Generate text embedding action
Text embedding is a technique for representing text data as numerical vectors. It uses deep neural networks to learn the patterns in large amounts of text data and generate vector representations that capture the meaning and context of the text. These vectors are used for a variety of natural language processing tasks such as sentiment analysis, text classification, and text similarity. Generating text embedding is commonly used as a preliminary step before other machine learning tasks. Refer to the OpenAI text embeddings guide for more information.
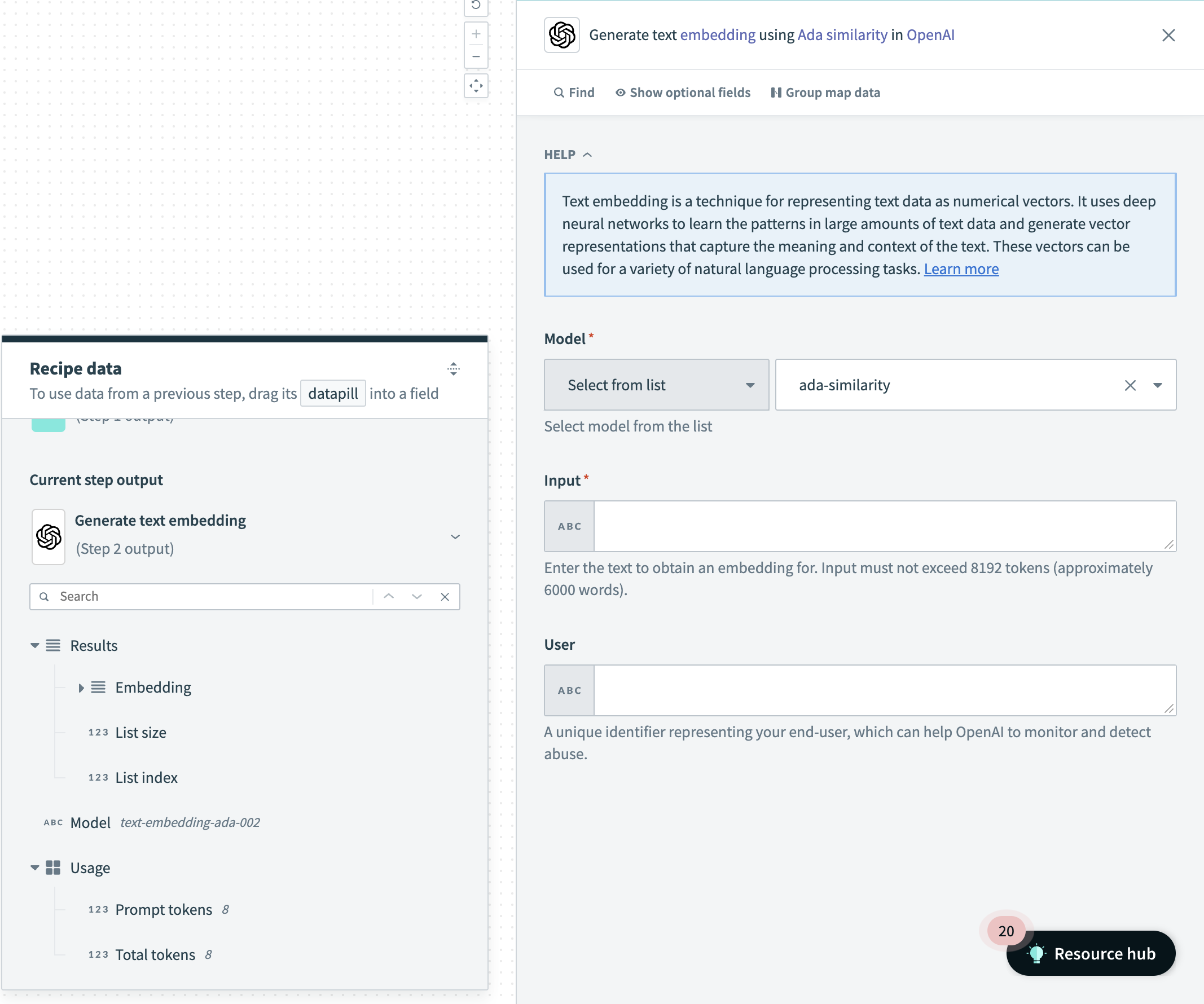 Generate Text Embedding Action
Generate Text Embedding Action
Input
| Field | Description |
|---|---|
| Input | Enter the text for which to obtain an embedding. The input must not exceed 8192 tokens (approximately 6000 words). |
| Model | Use the Model drop-down menu to select the OpenAI model you plan to use. You can click into the Model field and enter the model if it isn't listed. |
| User | A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. |
Output
| Field | Description | |
|---|---|---|
| Object | The type of object the data value is. Commonly this is a list with a single value. | |
| Model | The model used for text embedding. | |
| Embedding | A list containing the embedding scores for the text that you have inputted. This is generally used in tandem with another machine learning model. An array of embeddings are returned if an array of inputs were provided. | |
| Usage | Prompt Tokens | The number of tokens utilized by the prompt. |
| Total Tokens | The total number of tokens utilized by the prompt and response. | |
Last updated: