OpenAI - Moderate text action
Use this action to check if the input text violates OpenAI's content policy. Refer to the OpenAI moderations API documentation for more information. The action allows users to filter, moderate, and classify text content based on specific criteria. This API can be used in a variety of use cases, such as:
- Content moderation: Companies can use the action to automatically filter out inappropriate or offensive content from user-generated content on their platforms, such as social media platforms or forums.
- Customer service: Use this action to automatically classify and route customer inquiries or complaints to the appropriate department or agent based on the content of the message.
- Sentiment monitoring: Users can use the moderate text action to monitor social media and other online platforms for mentions of their brand and automatically classify them based on sentiment, allowing them to quickly respond to negative comments or customer complaints.
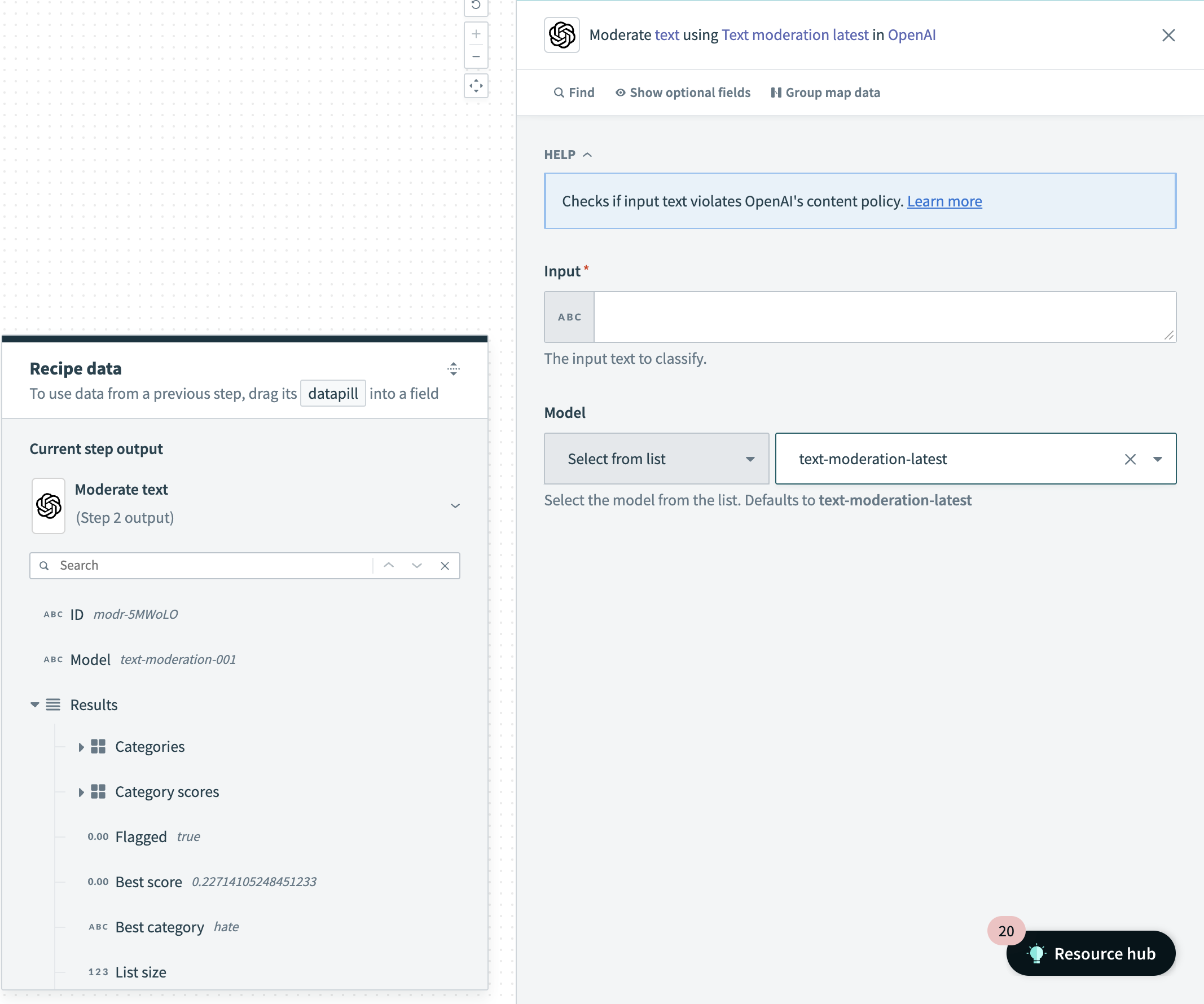 Moderate text action
Moderate text action
Input
| Field | Description |
|---|---|
| Input | The input text to classify. You can choose to input a list of relevant text to classify as well. |
| Model | Use the Model drop-down menu to select the OpenAI model you plan to use. You can click into the Model field and enter the model if it isn't listed. Defaults to text-moderation-latest which is automatically upgraded by OpenAI over time. If you use text-moderation-stable, OpenAI will provide advanced notice before updating the model. The accuracy of text-moderation-stable may be slightly lower than for text-moderation-latest. |
Output
| Field | Description | |
|---|---|---|
| ID | Unique identified for the request sent to OpenAI. | |
| Model | The model used for text moderation. | |
| Results | Categories | Contains a dictionary of per-category binary usage policies violation flags. For each category, the value is true if the model flags the corresponding category as violated, false otherwise. |
| Category scores | Contains a dictionary of per-category raw scores output by the model, denoting the model's confidence that the input violates the OpenAI's policy for the category. The value is between 0 and 1, where higher values denote higher confidence. The scores should not be interpreted as probabilities. | |
| Flagged | True if the model classifies the content as violating OpenAI's usage policies, false otherwise. | |
| Best score | The highest score within the various categories which could be violated. | |
| Best category | The category which corresponds to the highest score for the possible violation. | |
Last updated: