テキストのモデレーション
このアクションを使用して、入力テキストがOpenAIのコンテンツポリシーに違反しているかどうかをチェックします。詳細については、こちらをご覧ください。 このアクションでは、特定の基準に基づいてテキストコンテンツをフィルタリング、モデレート、および分類することができます。このAPIは、以下のようなさまざまなユースケースで使用することができます。
- コンテンツのモデレーション: 企業は、ソーシャルメディアプラットフォームやフォーラムなどのユーザー生成コンテンツから不適切または攻撃的なコンテンツを自動的にフィルタリングするために、このアクションを使用することができます。
- カスタマーサービス: このアクションを使用して、顧客の問い合わせやクレームをメッセージの内容に基づいて適切な部署やエージェントに自動的に分類およびルーティングすることができます。
- 感情のモニタリング: ユーザーは、テキストのモデレーションアクションを使用して、ソーシャルメディアや他のオンラインプラットフォームで自社ブランドの言及を監視し、感情に基づいて自動的に分類することができます。これにより、ネガティブなコメントや顧客のクレームに迅速に対応することができます。
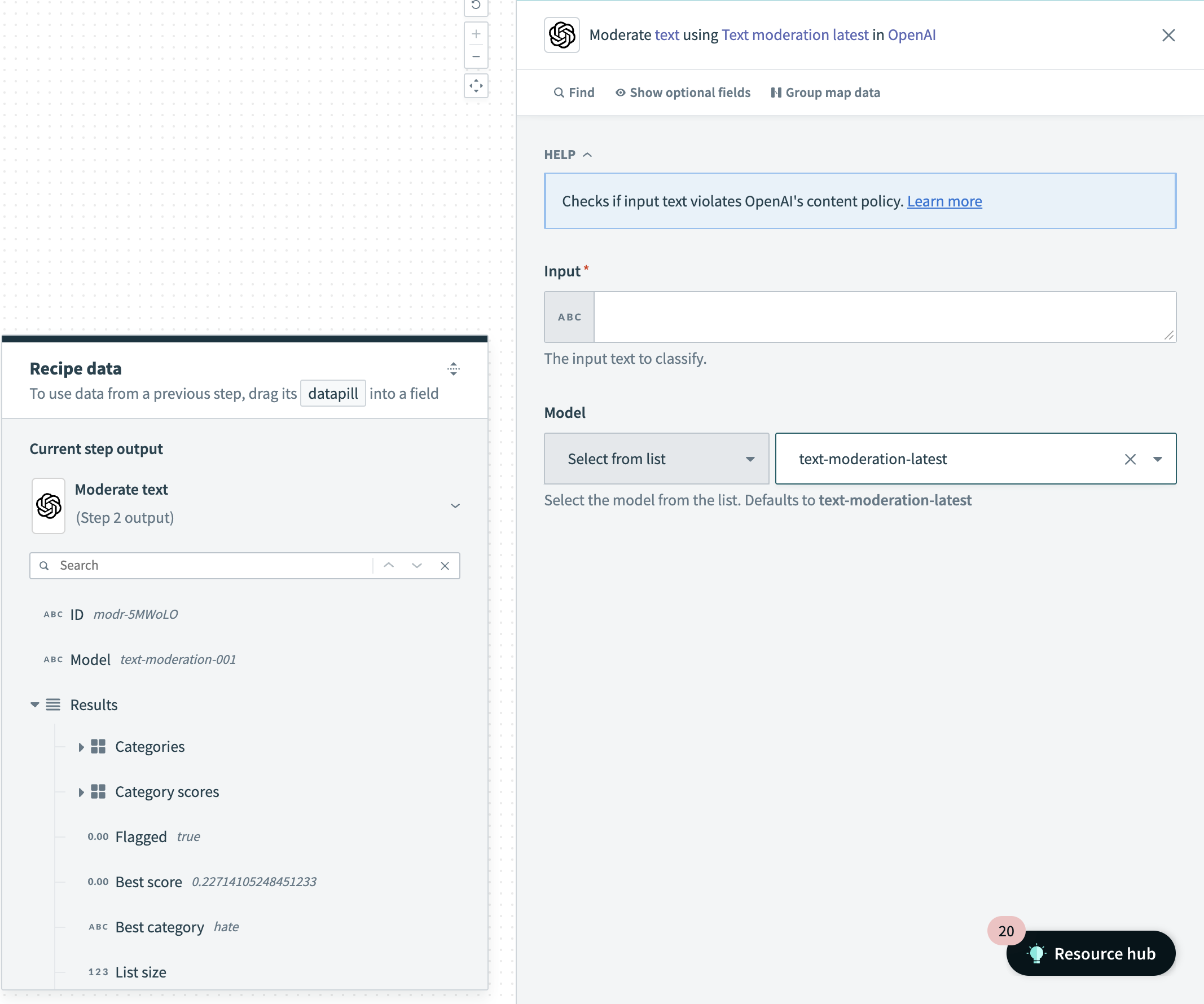 テキストのモデレーションアクション
テキストのモデレーションアクション
入力
| フィールド | 説明 |
|---|---|
| Input | 分類する入力テキスト。関連するテキストのリストを入力することもできます。 |
| Model | テキストをモデレーションするために使用するOpenAIモデルを選択します。デフォルトではtext-moderation-latestが選択され、OpenAIが自動的にアップグレードします。text-moderation-stableを使用する場合、OpenAIはモデルを更新する前に事前通知を提供します。text-moderation-stableの精度は、text-moderation-latestよりもわずかに低い場合があります。 |
出力
| フィールド | 説明 | |
|---|---|---|
| ID | OpenAIに送信されたリクエストの一意の識別子です。 | |
| Model | テキストモデレーションに使用されるモデルです。 | |
| Results | Categories | カテゴリごとのバイナリ使用ポリシー違反フラグの辞書を含みます。各カテゴリについて、モデルが対応するカテゴリを違反としてフラグ付けした場合はtrue、それ以外の場合はfalseです。 |
| Category scores | モデルによって出力されるカテゴリごとの生のスコアの辞書を含みます。これは、モデルが入力がOpenAIのポリシーに違反していると判断する確信度を示しています。値は0から1の間であり、値が高いほど確信度が高いことを示します。スコアは確率として解釈すべきではありません。 | |
| Flagged | モデルがコンテンツをOpenAIの使用ポリシーに違反していると分類した場合はtrue、それ以外の場合はfalseです。 | |
| Best score | 違反が可能性のあるさまざまなカテゴリの中で最も高いスコアです。 | |
| Best category | 可能な違反に対応する最も高いスコアを持つカテゴリです。 | |
Last updated: