PostgreSQL
PostgreSQL is an open-source object-relational database management system hosted either in the cloud or on-premise.
Supported editions
All releases of PostgreSQL are supported.
How to connect to PostgreSQL on Workato
The PostgreSQL connector uses basic authentication to authenticate with PostgreSQL. 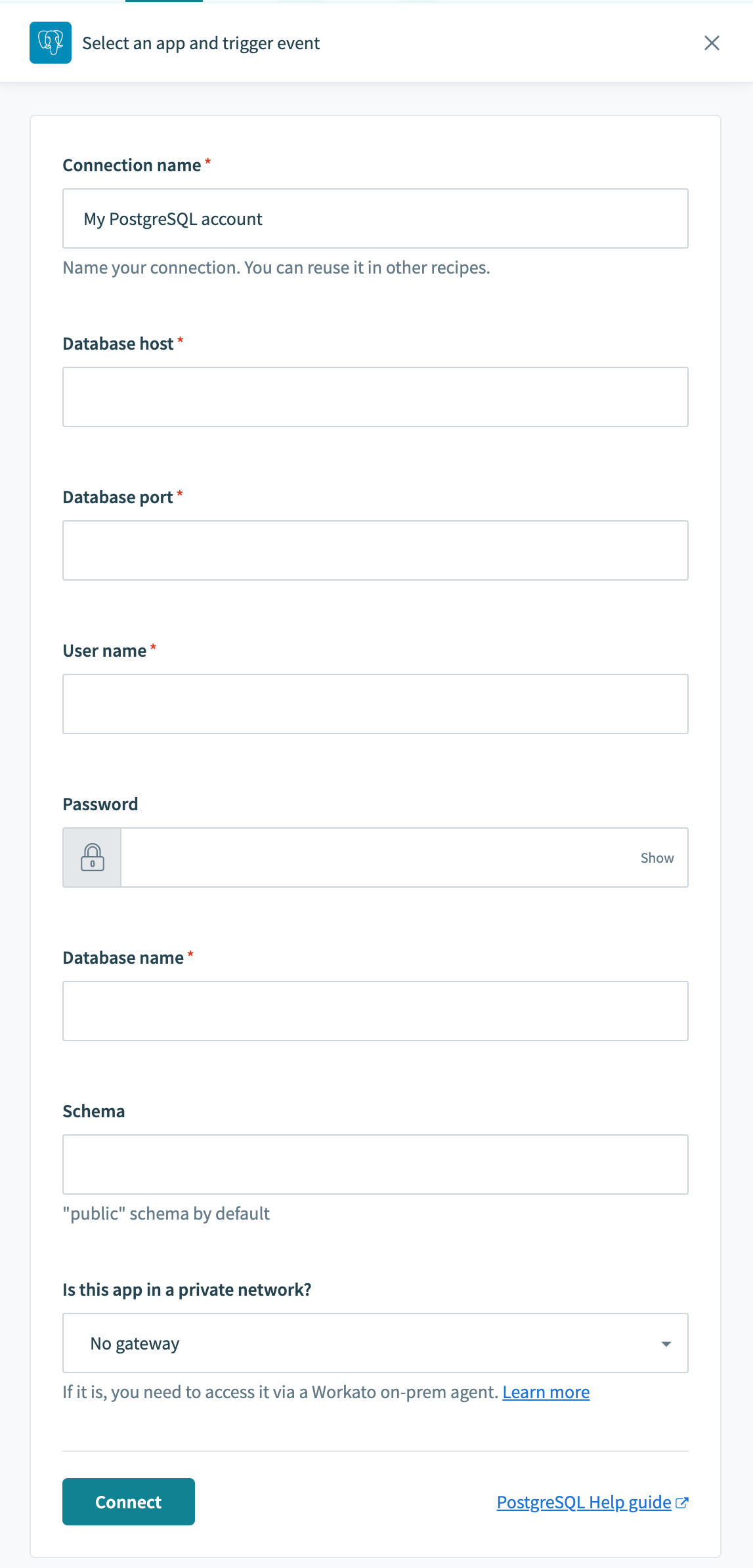
| Field | Description |
|---|---|
| Connection name | Give this PostgreSQL connection a unique name that identifies which PostgreSQL instance it is connected to. |
| On-prem secure agent | Choose an on-prem agent if your database is running in a network that does not allow direct connection. Before attempting to connect, make sure you have an active on-prem agent. Refer to the On-premise connectivity guide for more information. |
| Username | Username to connect to PostgreSQL. |
| Password | Password to connect to PostgreSQL. |
| Host | URL of your hosted server. |
| Port | Port number that your server is running on, typically 5432. |
| Database name | Name of the PostgreSQL database you wish to connect to. |
| Schema | Name of the schema within the PostgreSQL database you wish to connect to. Defaults to public. |
Permissions required to connect
At minimum, the database user account must be granted SELECT permission to the database specified in the connection.
If we are trying to connect to a PostgreSQL instance, using a new database user workato, the following example queries can be used.
First, create a new user dedicated to integration use cases with Workato.
CREATE USER workato WITH PASSWORD 'password';The next step is to grant access to customer table in the schema. In this example, we only wish to grant SELECT and INSERT permissions.
GRANT SELECT,INSERT ON customer TO workato;Finally, check that this user has the necessary permissions. Run a query to see all grants.
SELECT grantee, table_name, privilege_type
FROM information_schema.role_table_grants
WHERE grantee = 'workato';This should return the following minimum permission to create a PostgreSQL connection on Workato.
+---------+------------+----------------+
| grantee | table_name | privilege_type |
+---------+------------+----------------+
| workato | customer | SELECT |
+---------+------------+----------------+
| workato | customer | INSERT |
+---------+------------+----------------+
2 rows in set (0.26 sec)Working with the PostgreSQL connector
Table, view, and stored procedure
The PostgreSQL connector works with all tables, views, and stored procedures. These are available in pick lists in each trigger/action or you can provide the exact name.
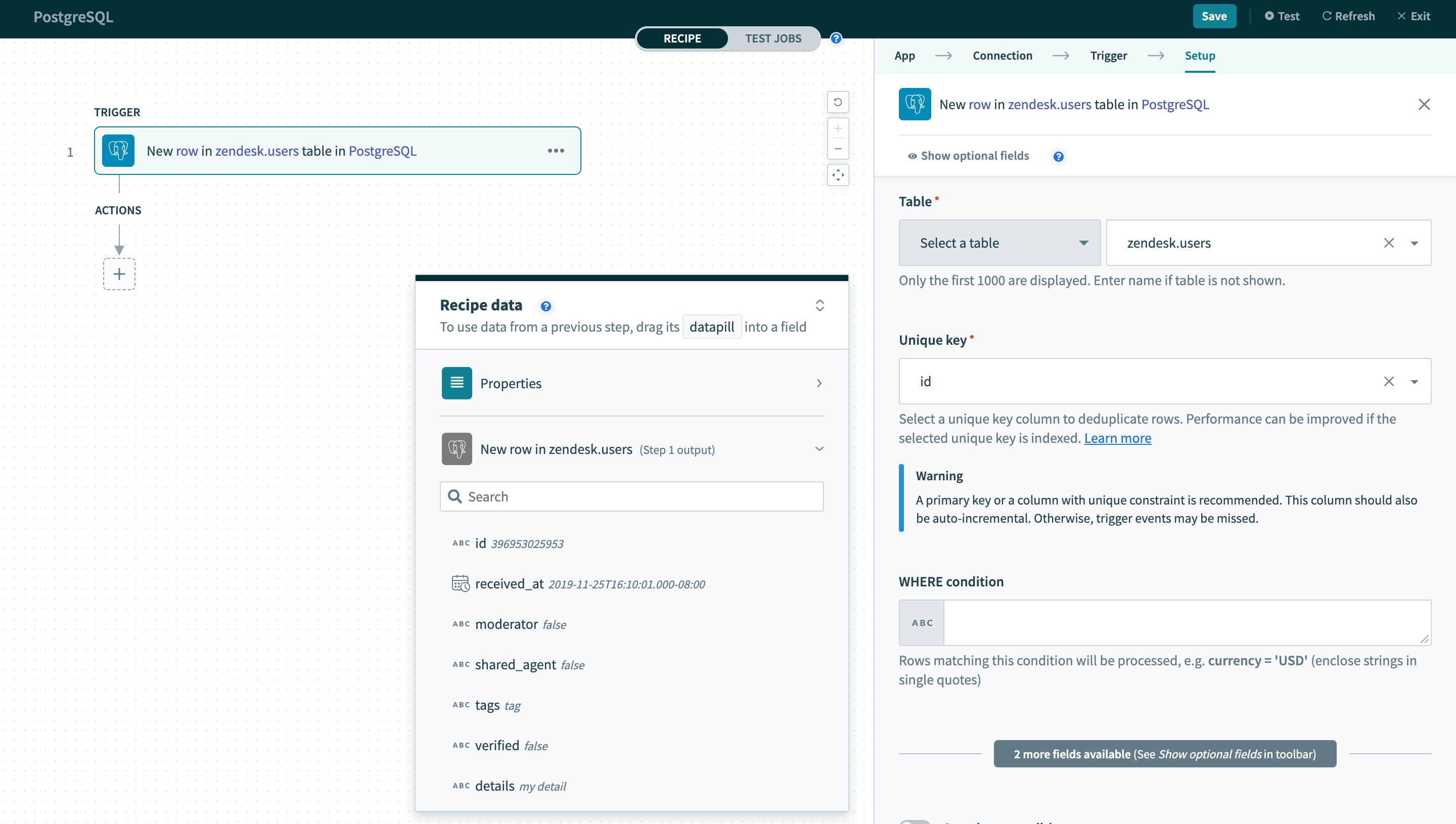 Select a table/view from pick list
Select a table/view from pick list
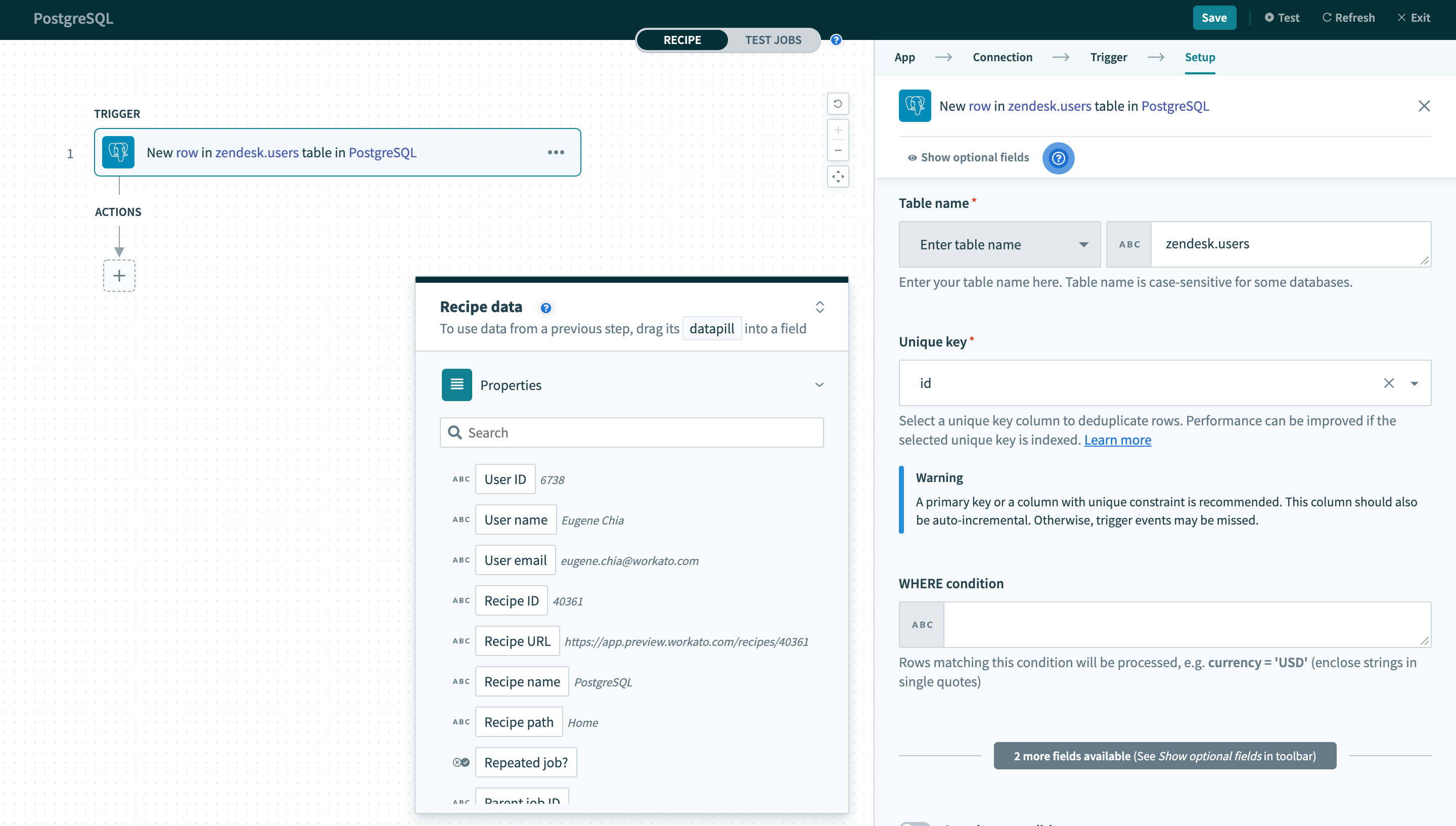 Provide exact table/view name in a text field
Provide exact table/view name in a text field
In PostgreSQL, unquoted identifiers are case-insensitive. Thus,
SELECT ID FROM USERSis equivalent to
SELECT ID FROM usersHowever, quoted identifiers are case-sensitive. Hence,
SELECT ID FROM "USERS"is NOT equivalent to
SELECT ID FROM "users"Single row vs batch of rows
PostgreSQL connector can read or write to your database either as a single row or in batches. When using batch triggers/actions, you have to provide the batch size you wish to work with. The batch size can be any number between 1 and 100, with 100 being the maximum batch size.
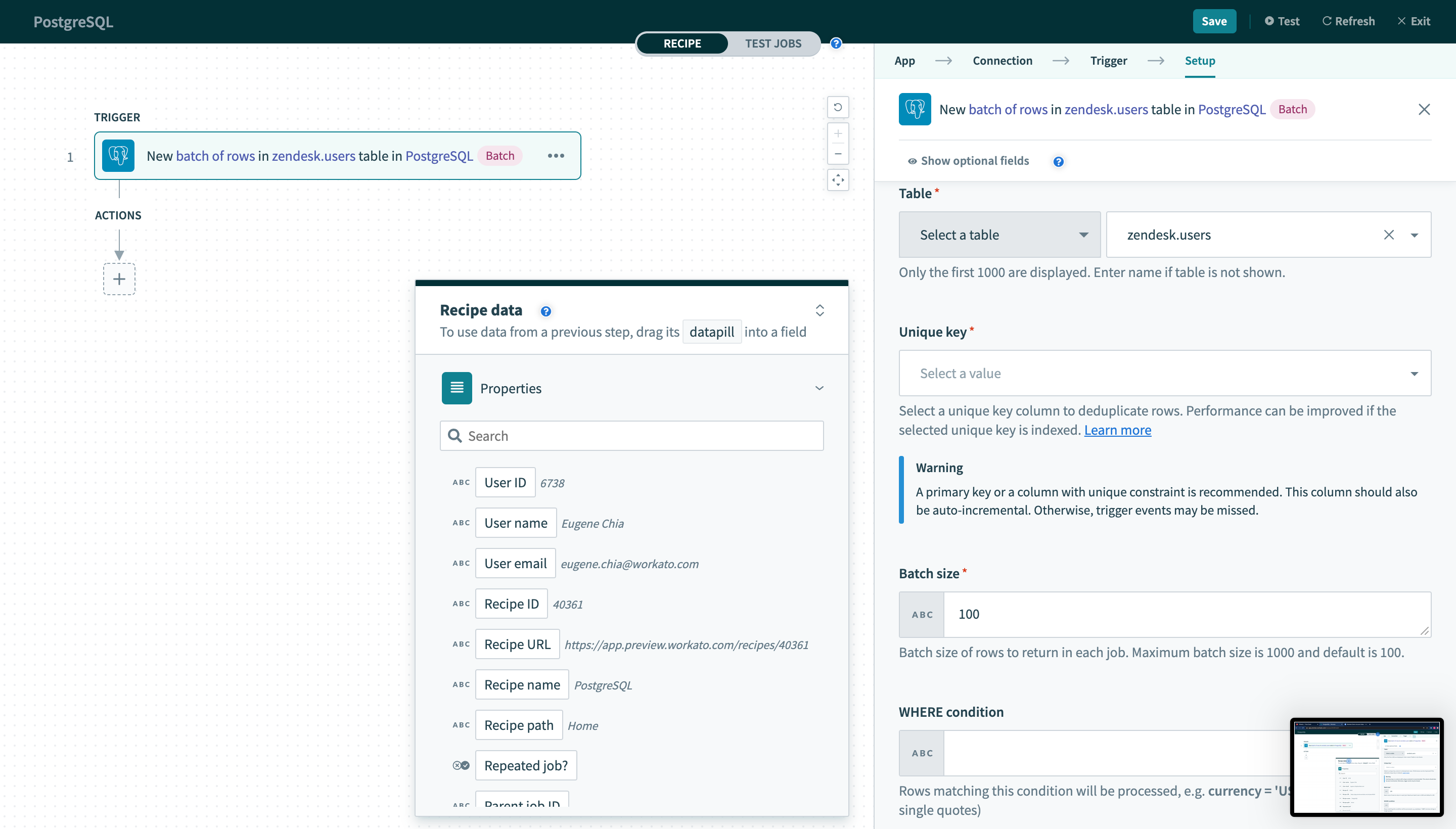 Batch trigger inputs
Batch trigger inputs
Besides the difference in input fields, there is also a difference between the outputs of these 2 types of operations. A trigger that processes rows one at a time will have an output datatree that allows you to map data from that single row.
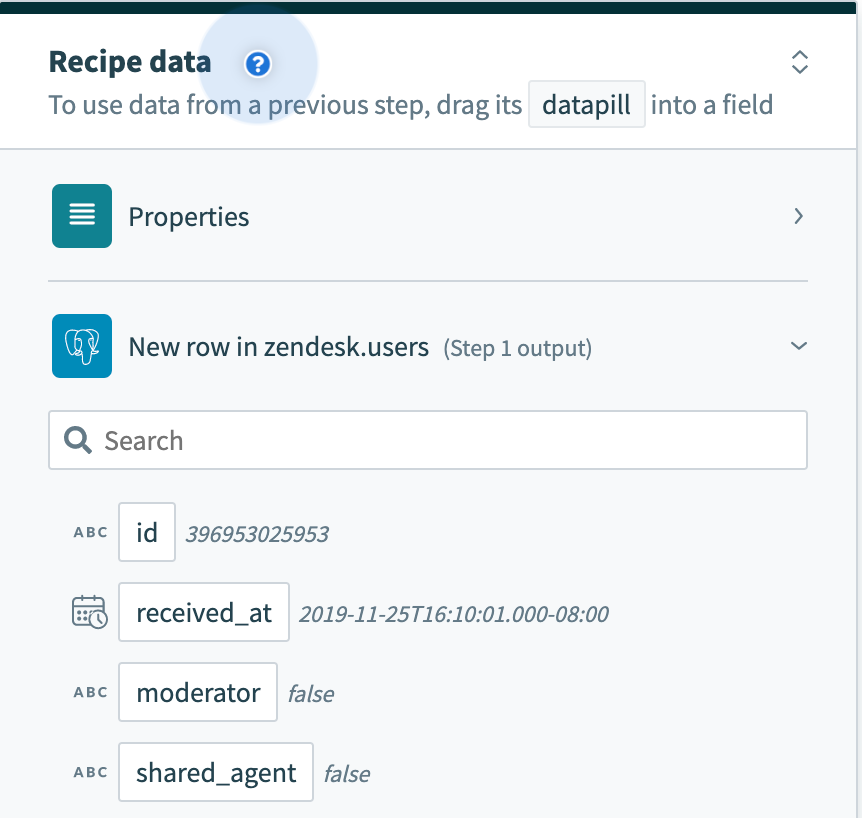 Single row output
Single row output
However, a trigger that processes rows in batches will output them as an array of rows. The Rows datapill indicates that the output is a list containing data for each row in that batch.
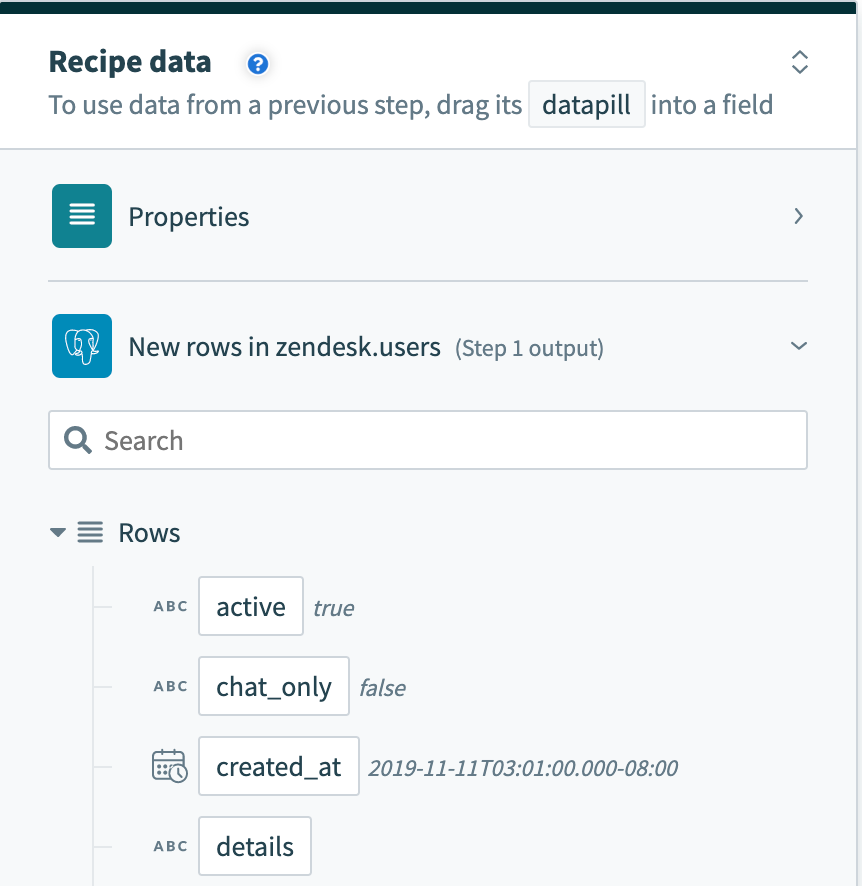 Batch trigger output
Batch trigger output
As a result, the output of batch triggers/actions needs to be handled differently. This recipe uses a batch trigger for new rows in the users table. The output of the trigger is used in a Salesforce bulk create action that requires mapping the Rows datapill into the source list.
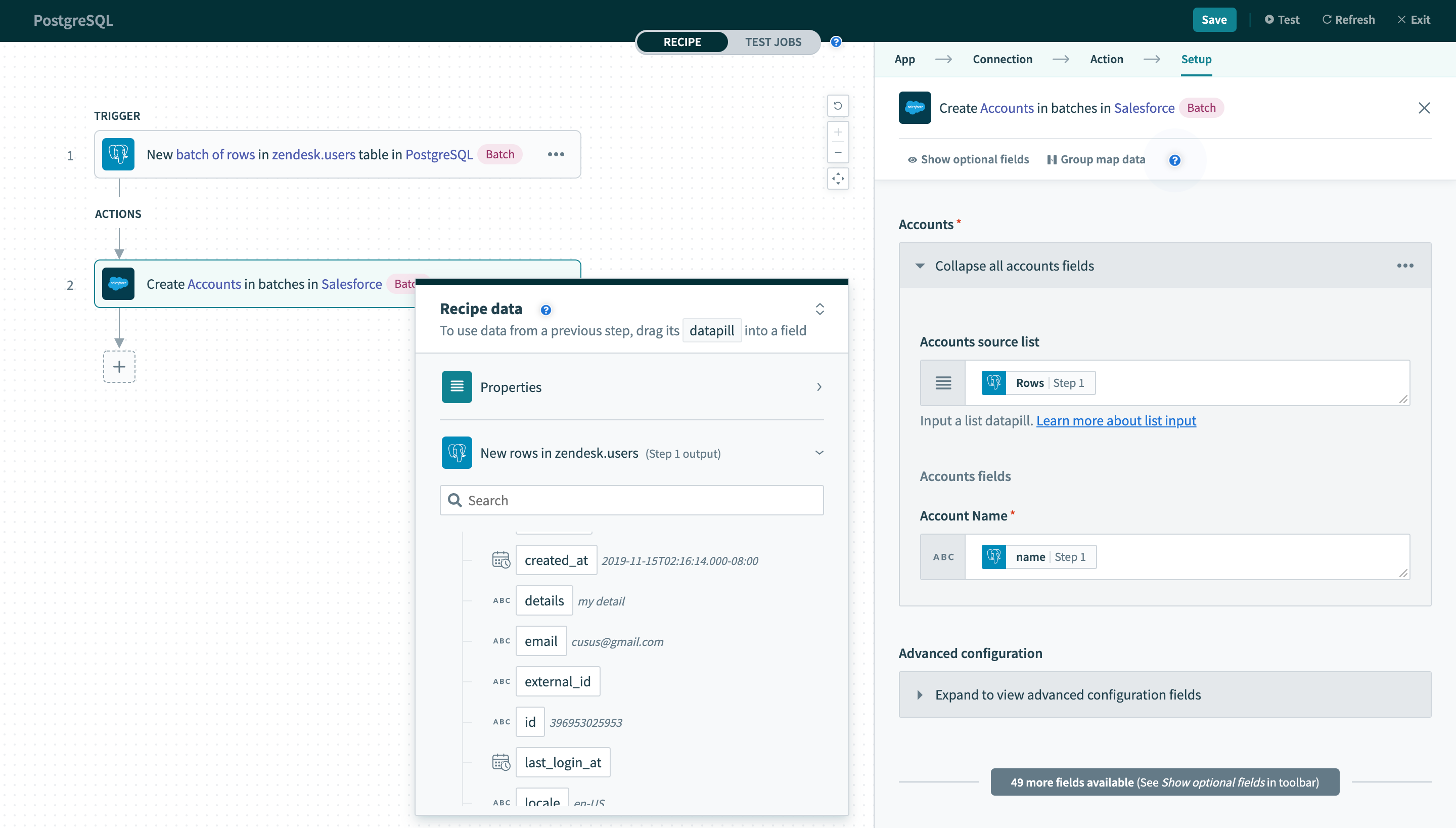 Using batch trigger output
Using batch trigger output
WHERE condition
This input field is used to filter and identify rows to perform an action on. It is used in multiple triggers and actions in the following ways:
- filter rows to be picked up in triggers
- filter rows in Select rows action
- filter rows to be deleted in Delete rows action
TIP
Examples below showcase how to use WHERE conditions directly with user input. For added security, use WHERE conditions with parameters to prevent SQL injection. Learn more
This clause will be used as a WHERE statement in each request. This should follow basic SQL syntax. Refer to this PostgreSQL documentation for a full list of rules for writing PostgreSQL statements.
Operators
| Operator | Description | Example |
|---|---|---|
| = | Equal | WHERE ID = 445 |
| != <> | Not equal | WHERE ID <> 445 |
| > >= | Greater than Greater than or equal to | WHERE PRICE > 10000 |
| < <= | Less than Less than or equal to | WHERE PRICE > 10000 |
| IN(...) | List of values | WHERE ID IN(445, 600, 783) |
| LIKE | Pattern matching with wildcard characters (% and _) | WHERE EMAIL LIKE '%@workato.com' |
| BETWEEN | Retrieve values with a range | WHERE ID BETWEEN 445 AND 783 |
| IS NULL IS NOT NULL | NULL values check Non-NULL values check | WHERE NAME IS NOT NULL |
Simple statements
String values must be enclosed in single quotes ('') and columns used must exist in the table.
A simple WHERE condition to filter rows based on values in a single column looks like this.
role = 'admin'If used in a Select rows action, this WHERE condition will return all rows that have the value 'admin' in the role column. Just remember to wrap datapills with single quotes in your inputs.
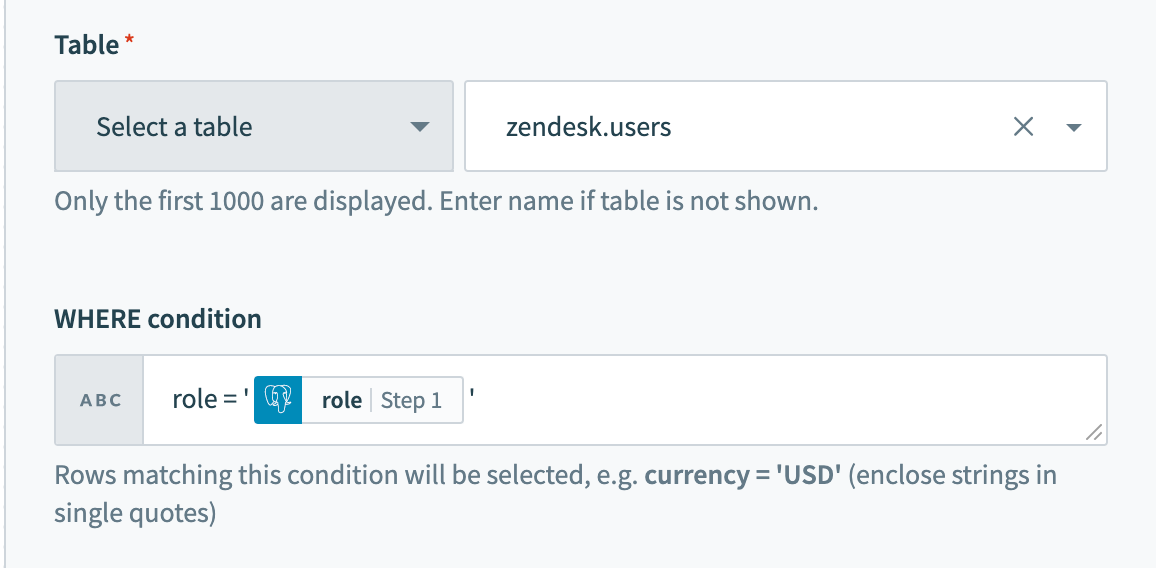 Using datapills in
Using datapills in WHERE condition
Column names with spaces must be enclosed in double quotes (""). For example, currency code must to enclosed in brackets to be used as an identifier. Note that all quoted identifiers are case-sensitive.
"created date" = '2020-05-06'In a recipe, remember to use the appropriate quotes for each value/identifier.
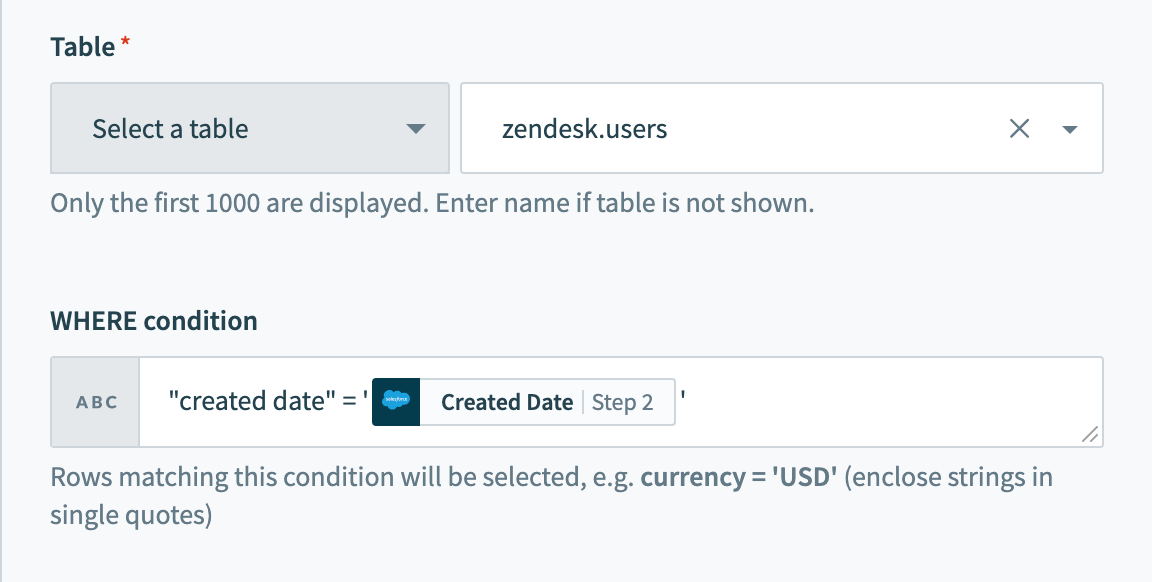
WHERE condition with enclosed identifier
Complex statements
Your WHERE condition can also contain subqueries. The following query can be used on the users table.
id in (select user_id from tickets where priority = 2)When used in a Delete rows action, this will delete all rows in the users table where at least one associated row in the tickets table has a value of 2 in the priority column.
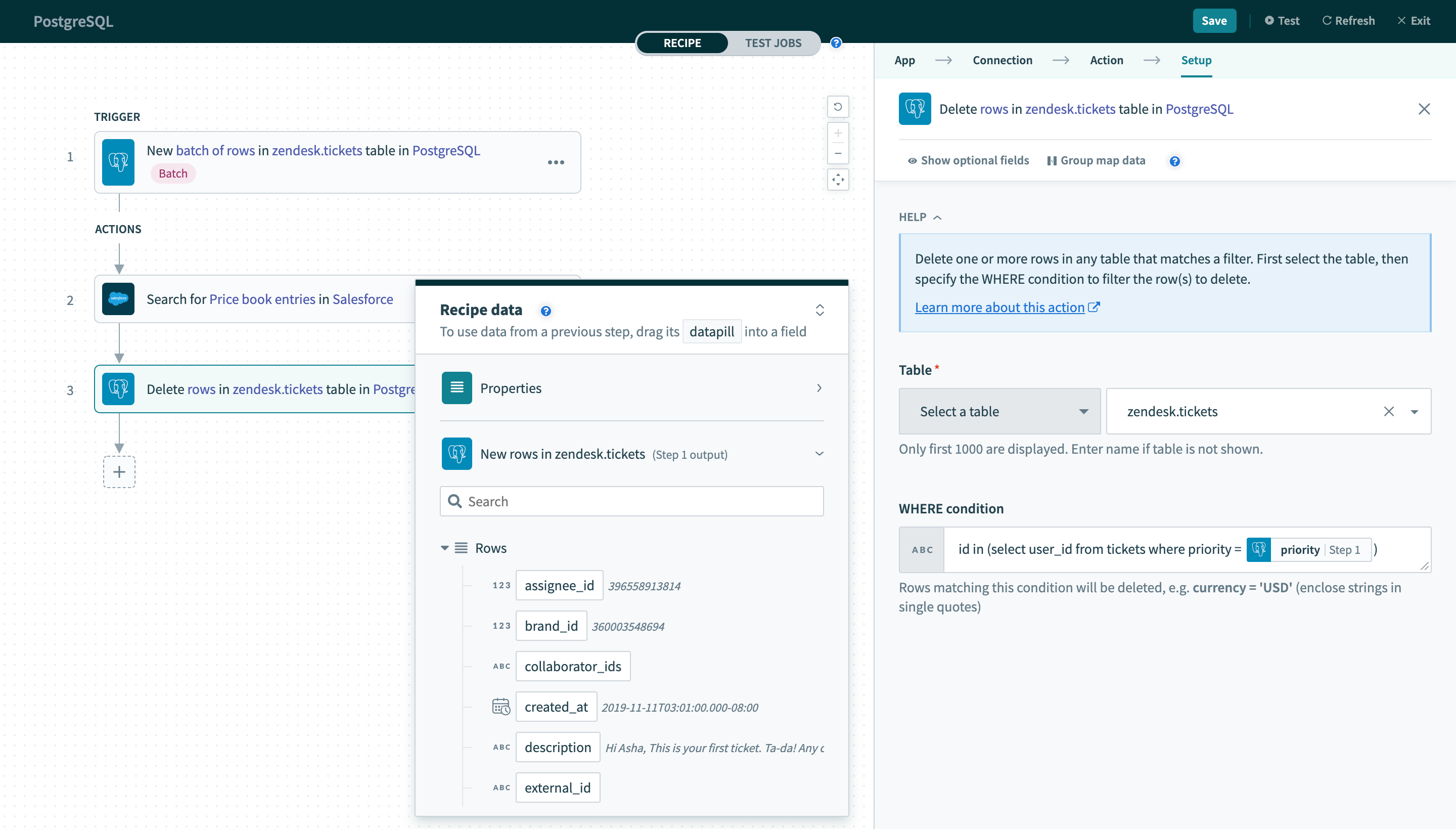 Using datapills in
Using datapills in WHERE condition with subquery
Using parameters
Parameters are used in conjunction with WHERE conditions to add an additional layer of security against SQL injection. To use parameters in your WHERE conditions, you will first need to declare bind variables in your input. Bind parameters must be declared in the form :bind_variable where the variable name is preceded with a :. After this is done, declare the parameter in the section directly below using the exact name you have given.
TIP
Bind variables should only be used in place of column values and not column names.
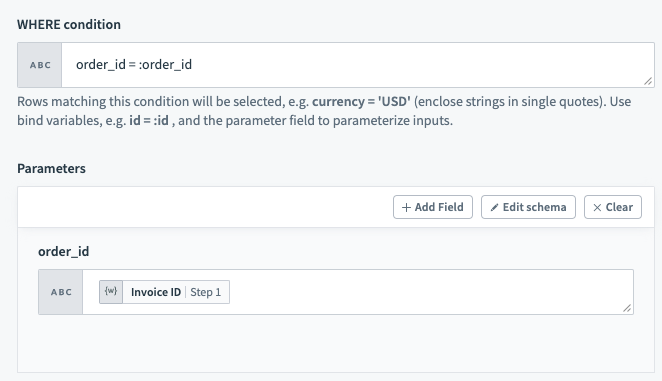
WHERE condition with bind variable
You can provide as many bind variables as you'd like and each one should have a unique name. We distinguish bind variables from column names and static values by ignoring any : inside single quotes ('), double quotes (") and square brackets ([]).
Unique key
In all triggers and some actions, this is a required input. Values from this selected column are used to uniquely identify rows in the selected table.
As such, the values in the selected column must be unique. Typically, this column is the primary key of the table (for example, ID).
When used in a trigger, this column must be incremental. This constraint is required because the trigger uses values from this column to look for new rows. In each poll, the trigger queries for rows with a unique key value greater than the previous greatest value.
Let's use a simple example to illustrate this behavior. We have a New row trigger that processed rows from a table. The unique key configured for this trigger is ID. The last row processed has 100 as it's ID value. In the next poll, the trigger will use ID >= 101 as the condition to look for new rows.
Performance of a trigger can be improved if the column selected to be used as the unique key is indexed.
Sort column
This is required for New/updated row triggers. Values in this selected column are used to identify updated rows.
When a row is updated, the Unique key value remains the same. However, it should have it's timestamp updated to reflect the last updated time. Following this logic, Workato keeps track of values in this column together with values in the selected Unique key column. When a change in the Sort column value is observed, an updated row event will be recorded and processed by the trigger.
For PostgreSQL, only timestamp and timestamp with time zone column types can be used.
Parameter limits
PostgreSQL supports a maximum of 65,535 bind parameters in a single SQL statement. You may encounter a query failure if you exceed this limit.
To avoid this, reduce the batch size, split the query into smaller parts, use array binding, or load data in bulk using COPY.
Workato recommends that you structure recipes and SQL operations to operate within this parameter limit to ensure stability.
Last updated: