Replication pipelines
Replication pipelines in Workato continuously copy data from one system to another, ensuring data accuracy and consistency. These pipelines support real-time analytics, backups, disaster recovery, and cross-system synchronization, keeping your data current and reliable across platforms.
Set up a pipeline for replication
You can set up a replication pipeline in Workato with features that ensure efficiency, scalability, and real-time data consistency:
Change Data Capture (CDC) with triggers
Workato triggers capture data changes quickly and efficiently, which minimizes system impact while keeping data replication up to date in real-time or near-real-time.
Schema replication
Workato replicates schemas from source systems to destinations without manual schema definitions. This maintains data structure integrity and simplifies setup.
Scalability
Workato scales elastically to meet demand and provides the necessary resources to handle high-volume data loads.
Bulk and batch processing
Workato supports bulk and batch processing to handle large data volumes efficiently. Bulk processing moves large datasets in a single job, while batch processing moves incremental updates. Both methods support ETL and ELT workflows.
Schema drift
Schema drift refers to changes in the structure of a dataset over time and typically occurs after you implement a data orchestration process. These changes may include additions, deletions, or modifications of fields, data types, or other schema elements.
Schema drift creates inconsistencies between source and target systems, which can lead to data transformation errors, data loss, or inaccurate analysis if not properly addressed.
How Workato detects and manages schema drift
Workato detects schema drift through automated schema detection and adaptation. It regularly monitors and validates data structures, sending notifications when schema changes occur. This enables you to intervene manually when necessary to maintain consistency between source and destination systems.
Replicate schema actions for Snowflake, BigQuery, and SQL Server
Workato supports schema replication for Google BigQuery, SQL Server, and Snowflake.
How schema replication works in Snowflake
Schema replication in Workato ensures that the structure of your source data matches the destination table in Snowflake. This process keeps your data pipelines consistent and up to date, even when the source schema changes.
Workato manages schema replication in Snowflake through the following processes:
Automatic table creation
If the specified destination table does not exist in Snowflake, Workato creates it automatically.
Schema comparison and updates
Workato compares the source schema with the destination Snowflake table. If columns exist in the source but not in the destination, Workato adds the missing columns using DDL commands (
ALTER TABLE).Data type consistency
New columns follow the data type provided in the source (applies to schema-based sources).
Non-destructive updates
Workato adds columns but never removes them. If columns exist in the Snowflake destination but not in the source, no changes occur.
Column ordering
Workato maintains the exact column order from the source data in the destination Snowflake table.
Modify a Snowflake table to match a source schema
The Replicate schema action inspects the source data schema and updates the Snowflake table to match.
Complete the following steps to modify a Snowflake table to match a source schema.
Go to Workato and configure the Replicate schema action for Snowflake.
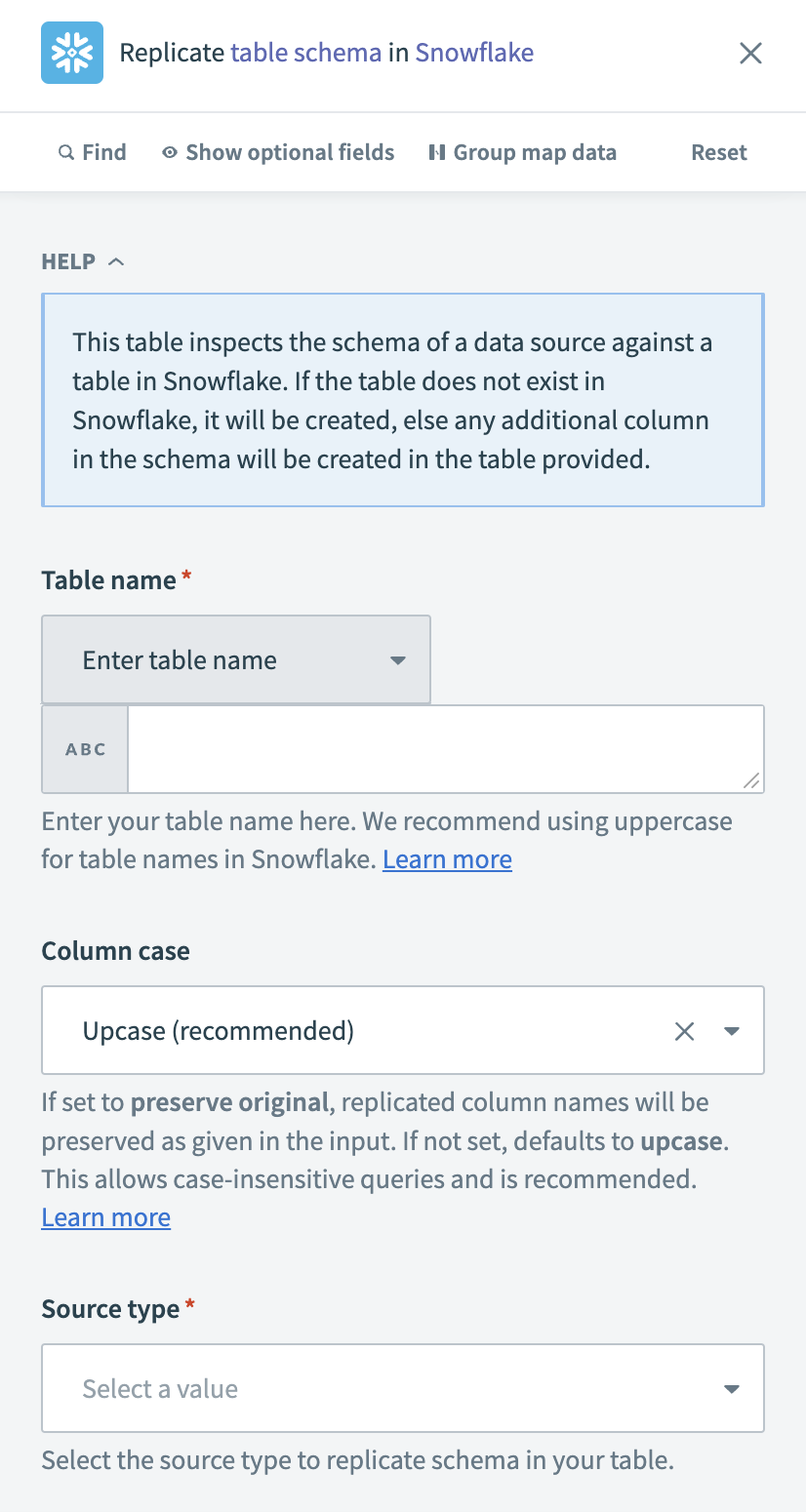 Configure the Replicate schema action
Configure the Replicate schema action
Select the destination table in Snowflake in the Table name field. You can select from a list of existing tables in Snowflake, or enter a table name manually.
CASE-SENSITIVITY IN TABLE NAMES
Table names are case-sensitive because Workato applies double-quotes around them. This allows you to use special characters in table names. Refer to the Double-quoted identifiers documentation for more information.
Optional. Select how to format replicated column names in the Column case field.
Choose whether the Source type is CSV or Schema.
Configure the following schema fields based on your selected data type:
Optional. Enter one or more unique keys to identify duplicate rows in the Key columns field.
Optional. Specify one or more columns to exclude from replication in the Exclude columns field.
Last updated: