レプリケーションパイプライン
Workatoのレプリケーションパイプラインは、あるシステムから別のシステムへデータを継続的にコピーし、データの正確性と一貫性を確保します。 これらのパイプラインは、リアルタイム分析、バックアップ、災害復旧、およびシステム間同期をサポートし、プラットフォーム全体でデータを最新かつ信頼できる状態に保ちます。
レプリケーション用パイプラインの設定
Workatoでは、効率性、スケーラビリティ、およびリアルタイムのデータ整合性を確保する機能を使用して、レプリケーションパイプラインを設定できます。
トリガーによる変更データキャプチャ(CDC)
Workatoのトリガーはデータ変更を迅速かつ効率的にキャプチャし、データレプリケーションをリアルタイムまたはほぼリアルタイムで最新の状態に保ちながら、システムへの影響を最小限に抑えます。
スキーマレプリケーション
Workatoは、手動でスキーマを定義しなくても、ソースシステムから宛先へスキーマをレプリケートします。 これにより、データ構造の整合性を維持し、設定を簡素化できます。
スケーラビリティ
Workatoは需要に合わせて柔軟にスケールし、大量のデータ負荷を処理するために必要なリソースを提供します。
バルク処理とバッチ処理
Workatoは、大量のデータを効率的に処理するためのバルク処理とバッチ処理をサポートしています。 バルク処理では大規模なデータセットを1つのジョブで移動し、バッチ処理では増分更新を移動します。 どちらの方法もETLおよびELTワークフローをサポートしています。
スキーマドリフト
スキーマドリフトとは、時間の経過に伴うデータセット構造の変化を指し、通常はデータオーケストレーションプロセスを実装した後に発生します。 これらの変更には、フィールド、データ型、またはその他のスキーマ要素の追加、削除、変更が含まれる場合があります。
スキーマドリフトにより、ソースシステムとターゲットシステムの間に不整合が生じます。適切に対処しない場合、データ変換エラー、データ損失、または不正確な分析につながる可能性があります。
Workatoがスキーマドリフトを検出および管理する方法
Workatoは、自動スキーマ検出と適応を通じてスキーマドリフトを検出します。 データ構造を定期的に監視および検証し、スキーマ変更が発生すると通知を送信します。 これにより、必要に応じて手動で介入し、ソースシステムと宛先システムの間の一貫性を維持できます。
Snowflake、BigQuery、およびSQL ServerのReplicate schemaアクション
Workatoは、Google BigQuery、SQL Server、およびSnowflakeのスキーマレプリケーションをサポートしています。
Snowflakeでのスキーマレプリケーションの仕組み
Workatoのスキーマレプリケーションにより、ソースデータの構造がSnowflakeの宛先テーブルと一致するようになります。 このプロセスにより、ソーススキーマが変更された場合でも、データパイプラインの一貫性が保たれ、最新の状態に維持されます。
Workatoは、次のプロセスを通じてSnowflakeのスキーマレプリケーションを管理します。
テーブルの自動作成
指定した宛先テーブルがSnowflakeに存在しない場合、Workatoが自動的に作成します。
スキーマの比較と更新
Workatoは、ソーススキーマを宛先Snowflakeテーブルと比較します。 ソースには存在するが宛先には存在しないカラムがある場合、WorkatoはDDLコマンド(
ALTER TABLE)を使用して不足しているカラムを追加します。データ型の一貫性
新しいカラムは、ソースで提供されたデータ型に従います(スキーマベースのソースに適用されます)。
非破壊的な更新
Workatoはカラムを追加しますが、削除することはありません。 Snowflakeの宛先には存在するがソースには存在しないカラムがある場合、変更は発生しません。
カラムの順序
Workatoは、ソースデータの正確なカラム順序を宛先Snowflakeテーブルで維持します。
ソーススキーマに一致するようにSnowflakeテーブルを変更する
Replicate schemaアクションは、ソースデータスキーマを検査し、一致するようにSnowflakeテーブルを更新します。
Snowflakeテーブルをソーススキーマに一致するように変更するには、次の手順を実行します。
Workatoに移動し、SnowflakeのReplicate schemaアクションを設定します。
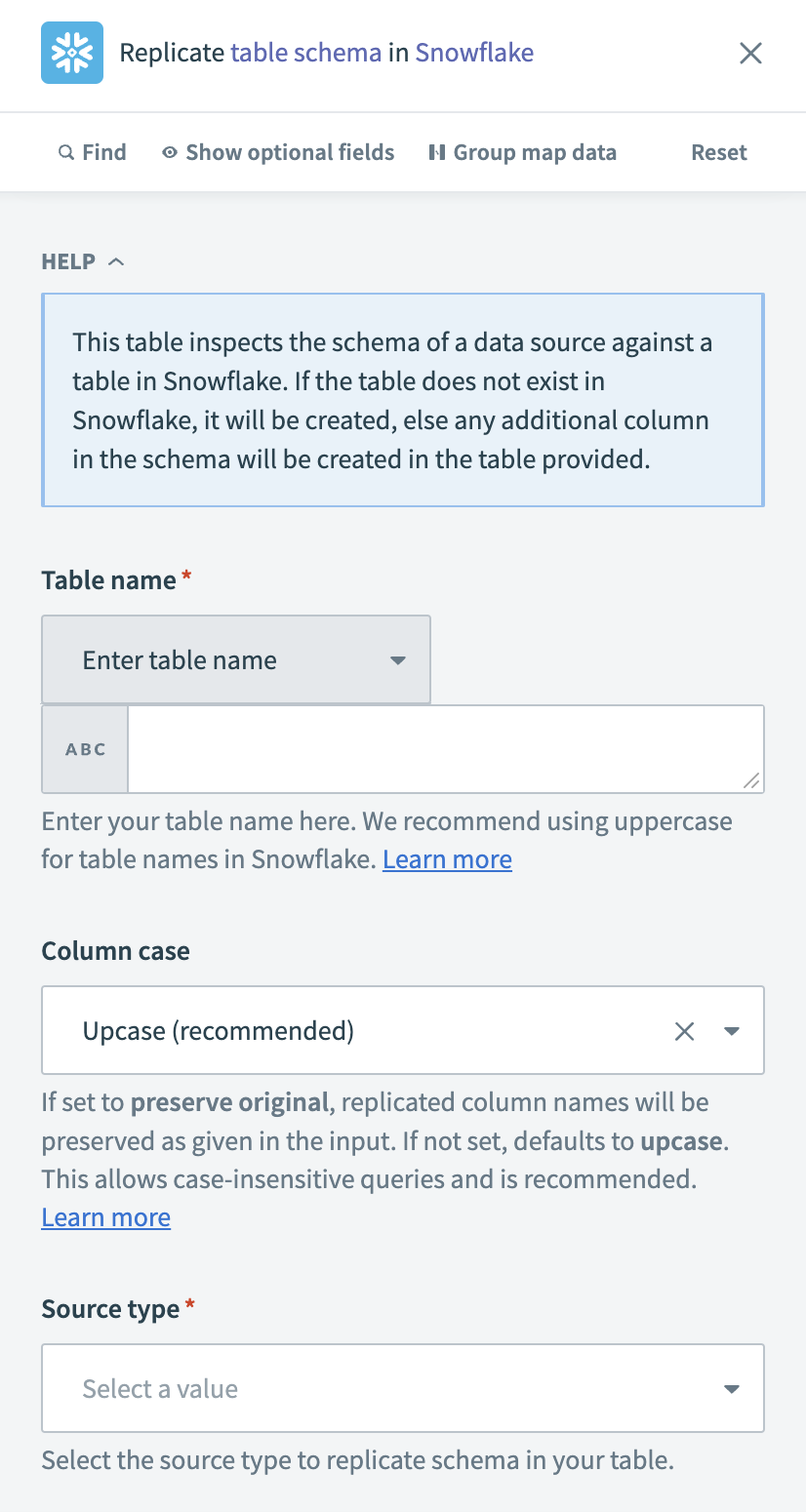 Replicate schemaアクションを設定
Replicate schemaアクションを設定
Table nameフィールドでSnowflakeの宛先テーブルを選択します。 Snowflakeの既存テーブルのリストから選択するか、テーブル名を手動で入力できます。
テーブル名の大文字と小文字の区別
Workatoがテーブル名を二重引用符で囲むため、テーブル名では大文字と小文字が区別されます。 これにより、テーブル名に特殊文字を使用できます。 詳細については、Double-quoted identifiersのドキュメントを参照してください。
任意です。 Column caseフィールドで、レプリケートされたカラム名の書式設定方法を選択します。
Source typeがCSVかSchemaかを選択します。
選択したデータ型に基づいて、次のスキーマフィールドを設定します。
任意です。 Key columnsフィールドに、重複行を識別するための一意キーを1つ以上入力します。
任意です。 Exclude columnsフィールドで、レプリケーションから除外するカラムを1つ以上指定します。
最終更新日: