データの抽出
データ抽出により、さまざまなアプリケーションから情報を取得できます。 Workatoは、ETL(Extract, Transform, Load)およびELT(Extract, Load, Transform)プロセスに不可欠な一括抽出とバッチ抽出の両方をサポートしています。
イベントまたはトリガーベースの抽出
Workatoのイベント駆動型またはトリガーベースの抽出では、ソースシステムで特定のイベントが発生したときにデータを自動的に抽出できます。 このアプローチは、レコードの作成や更新など、イベントの直後にデータを処理する必要があるシナリオに最適です。
イベント駆動型またはトリガーベースのデータ抽出を設定して、リアルタイムまたは指定した間隔でイベントを監視できます。 これにより、タイムリーなデータのキャプチャと処理が可能になり、データを最新の状態に保ち、リアルタイム分析をサポートし、最小限のレイテンシで自動化されたワークフローをトリガーできます。
イベントまたはトリガーベースの抽出を使用して、次のソースから一括またはバッチでデータを抽出します。
SaaS
SaaSアプリケーションは、顧客、営業、運用情報などの重要なビジネスデータをクラウドに保存します。 Workatoを使用すると、イベントまたはスケジュールに基づいてこのデータを抽出し、データウェアハウス、分析プラットフォーム、その他のアプリケーションと同期できます。
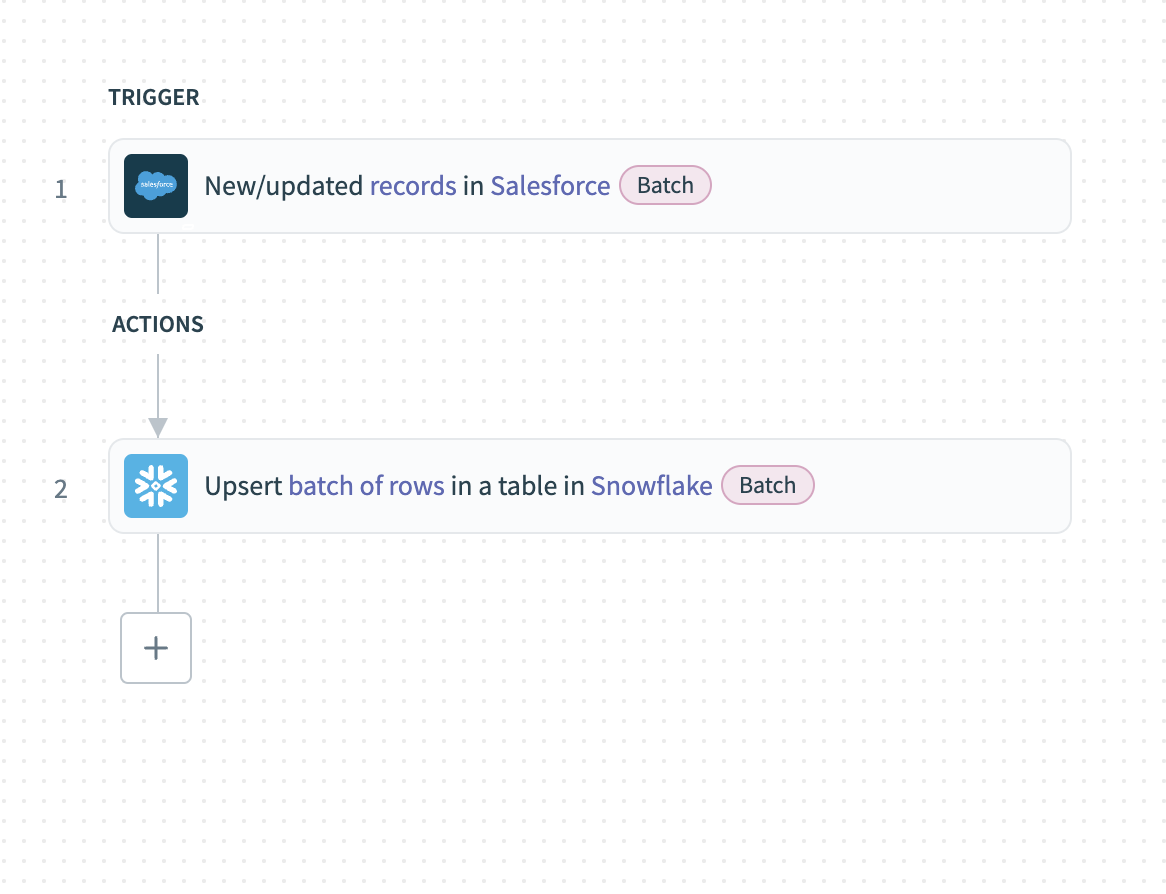
サンプルレシピ: Salesforceからのバッチ抽出
この例では、Salesforceから新規または更新されたレコードをバッチ抽出し、Snowflakeにロードする方法を示します。
 Salesforceからのバッチ抽出
Salesforceからのバッチ抽出
Salesforceレコードをバッチで抽出し、Snowflakeにロードするには、次の手順を実行します。
Salesforceの新規/更新レコードバッチトリガーを設定する。
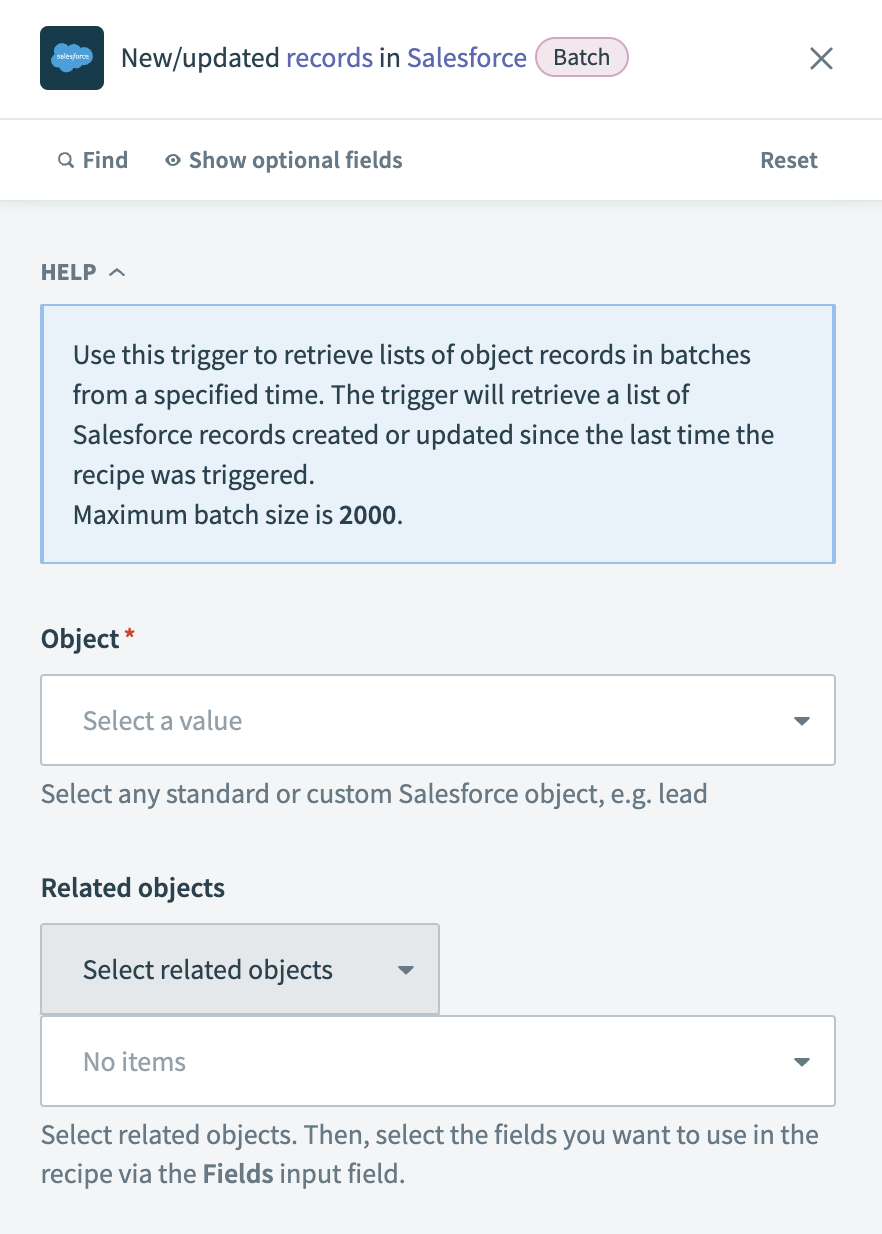
抽出するデータを含むObjectを選択します。 たとえば、新規または更新されたアカウントレコードを抽出するには、Accountを選択します。
 New/updated records batchトリガーを設定する
New/updated records batchトリガーを設定する
任意です。 追加フィールドを抽出するには、Related objectsを選択します。 関連オブジェクトを選択したら、取得するフィールドを指定します。
パフォーマンスを向上させるには、特定のFields to retrieveを選択します。 空白のままにすると、Workatoはすべてのフィールドを取得します。
任意です。 結果を絞り込むには、SOQL WHERE clauseフィールドにSOQLクエリを入力します。 たとえば、クエリStageName = 'Closed Lost' AND IsClosed = falseを使用すると、StageNameがClosed Lostに設定され、IsClosedがfalseであるレコードを抽出できます。 これにより、失注としてマークされているものの完全にはクローズされていない商談が取得され、さらなる処理が可能になります。
任意です。 各バッチで抽出されるレコード数を制御するには、Batch sizeを設定します。 バッチあたりの最大レコード数は2,000ですが、Workatoはレコードサイズに応じてこの制限を引き下げる場合があります。 デフォルトのバッチサイズは100です。
任意です。 新しく追加または変更されたカスタムフィールドをトリガー出力に含めるかどうかを指定するには、Detect new or updated custom dataフィールドを使用します。
データ抽出の開始点を、When first started, this recipe should pick up events fromフィールドで選択します。 相対時間または特定の日付と時刻を選択します。 レシピを実行またはテストした後は、この値を変更できません。
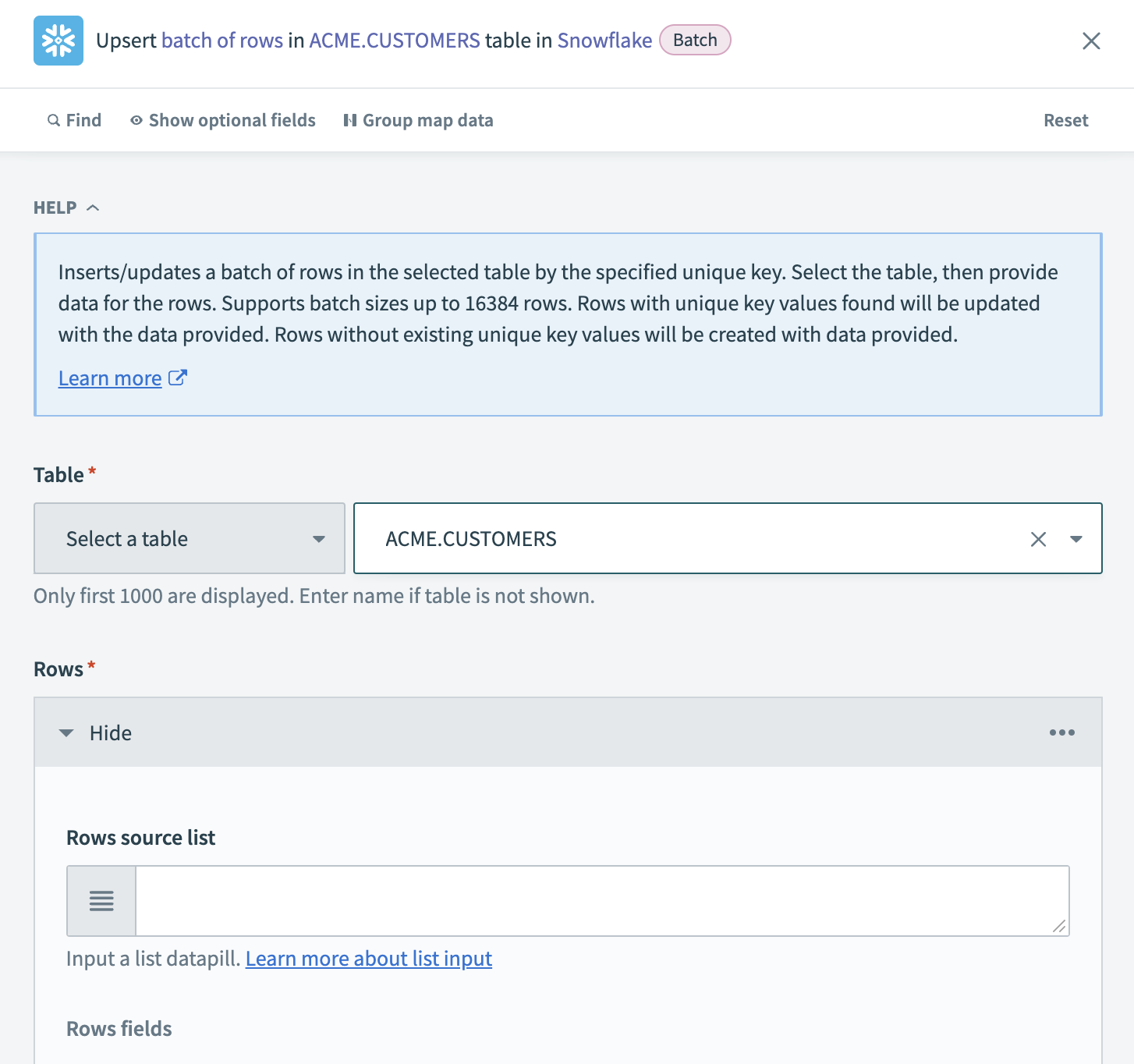
行のアップサートアクションを設定する。
Workatoが抽出したレコードをアップサートするSnowflakeのTableを選択します。 テーブルが一覧にない場合は、テーブル名を手動で入力します。
 Upsert rows batchアクションを設定する
Upsert rows batchアクションを設定する
指定したオブジェクトのリストデータピルを、Rows source listフィールドにマッピングします。 たとえば、Salesforceからアカウントをバッチで抽出する場合は、アカウントステップ 1データピルをマッピングします。 リストデータピルをマッピングしたら、Salesforceの対応する各データピルを、Snowflakeアクションの適切なRows fieldsにマッピングします。
任意です。 行の重複を排除するには、Unique key列を選択します。 これによりパフォーマンスが向上し、Workatoが重複を作成する代わりに既存のレコードを更新するようになります。 一意キーにインデックスが付けられている場合、パフォーマンスを向上できます。
データベース
データベースには、分析、レポート、運用プロセスに不可欠な構造化データが保存されます。 Workatoを使用すると、データベースからクラウドストレージ、データウェアハウス、その他のアプリケーションへ、データの抽出、変換、ロード(ETL)または抽出、ロード、変換(ELT)を実行できます。
Workatoは、2つの主要なデータベース抽出方法をサポートしています。
次の例では、両方の方法を使用してPostgreSQLからデータを抽出し、Snowflakeにロードする方法を示します。
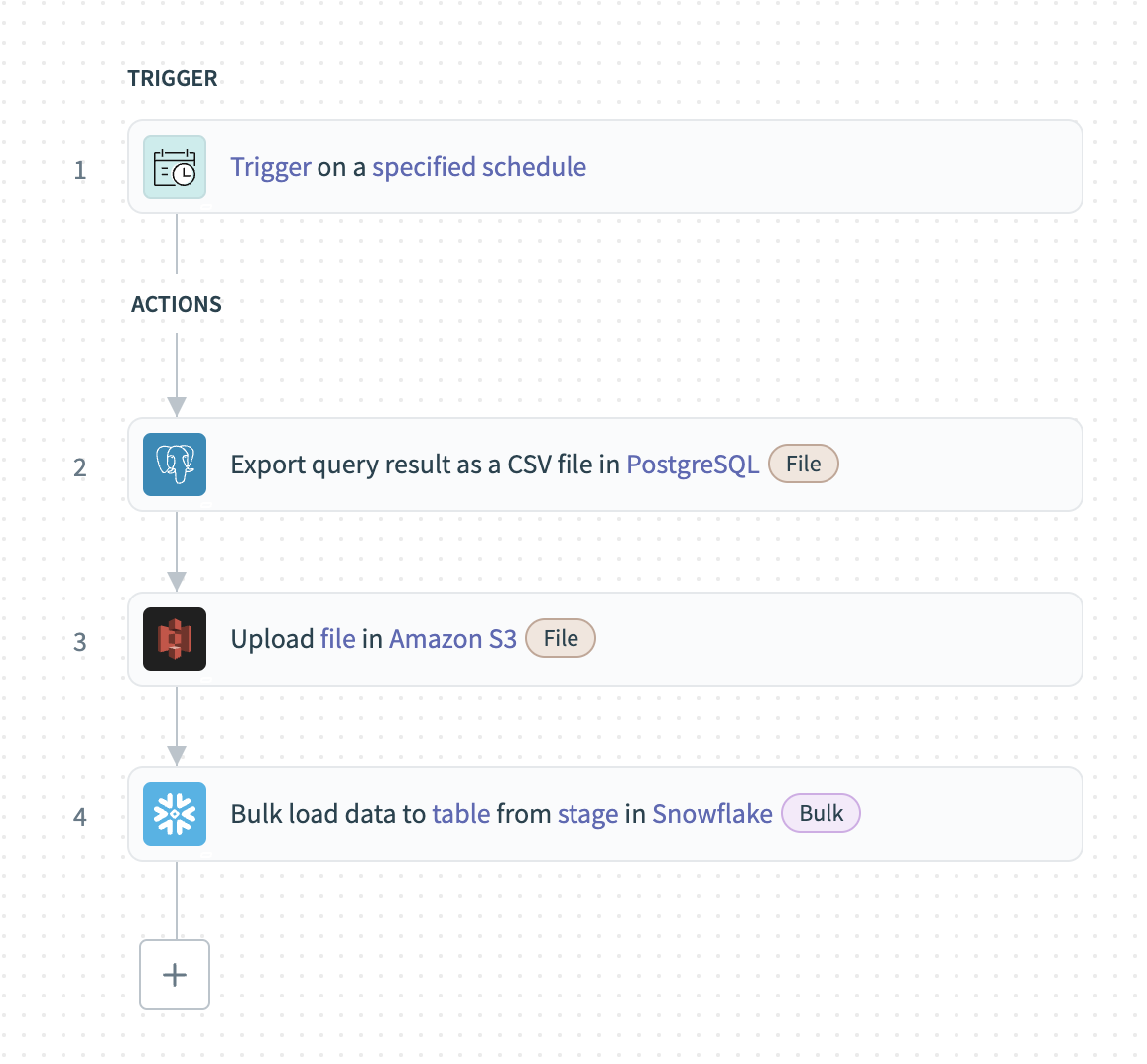
サンプルレシピ: データベースからのスケジュールされた一括抽出
この例では、PostgreSQLから大規模なデータセットを一括抽出し、Snowflakeにロードする方法を示します。 一括抽出では、スケジュールされた間隔でデータを転送して、分析とレポートの効率を高め、パフォーマンスを最適化します。
 PostgreSQLからの一括抽出
PostgreSQLからの一括抽出
PostgreSQLレコードを一括で抽出し、Snowflakeにロードするには、次の手順を実行します。
Workatoがデータを抽出する頻度を定義するには、Schedulerトリガーを設定します。
クエリ結果のエクスポート一括アクションを設定する
SQLフィールドで、必要なデータを取得するSELECTクエリを定義します。 たとえば、次のクエリは過去24時間に更新されたアカウントレコードを抽出します。
SELECT id, name, updated_at FROM accounts WHERE updated_at >= NOW() - INTERVAL '1 day'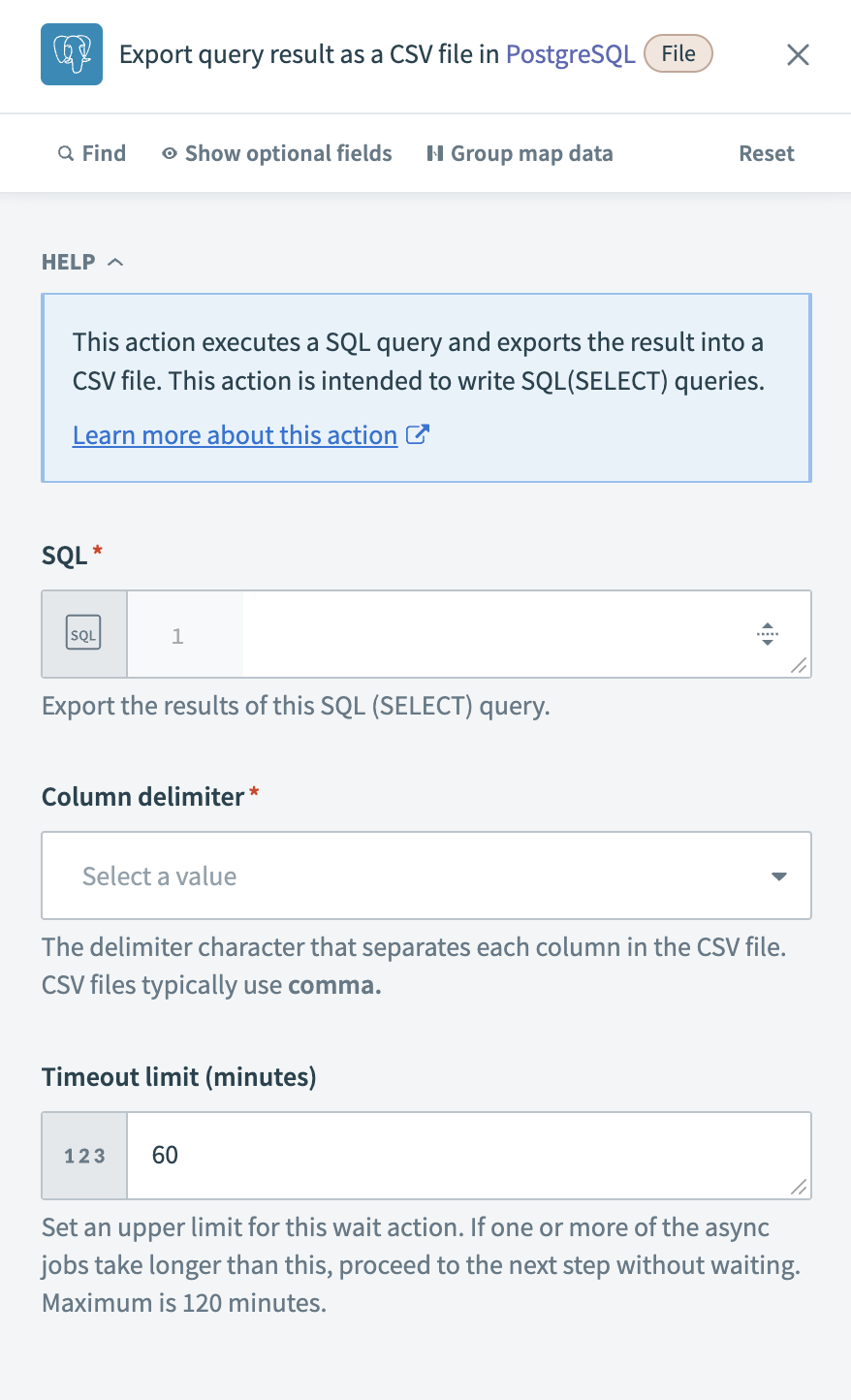 Export query resultアクションを設定する
Export query resultアクションを設定する
エクスポートされたCSVファイル内の値を区切るには、Column delimiterを選択します。 最も一般的なオプションはカンマ(,)ですが、システム要件に基づいて他の区切り文字を選択できます。
アクションのタイムアウト制限(分)を定義します。 クエリの実行がこの制限を超えた場合、Workatoは次のステップに進みます。 デフォルト値は60 minutesで、最大制限は120 minutesです。
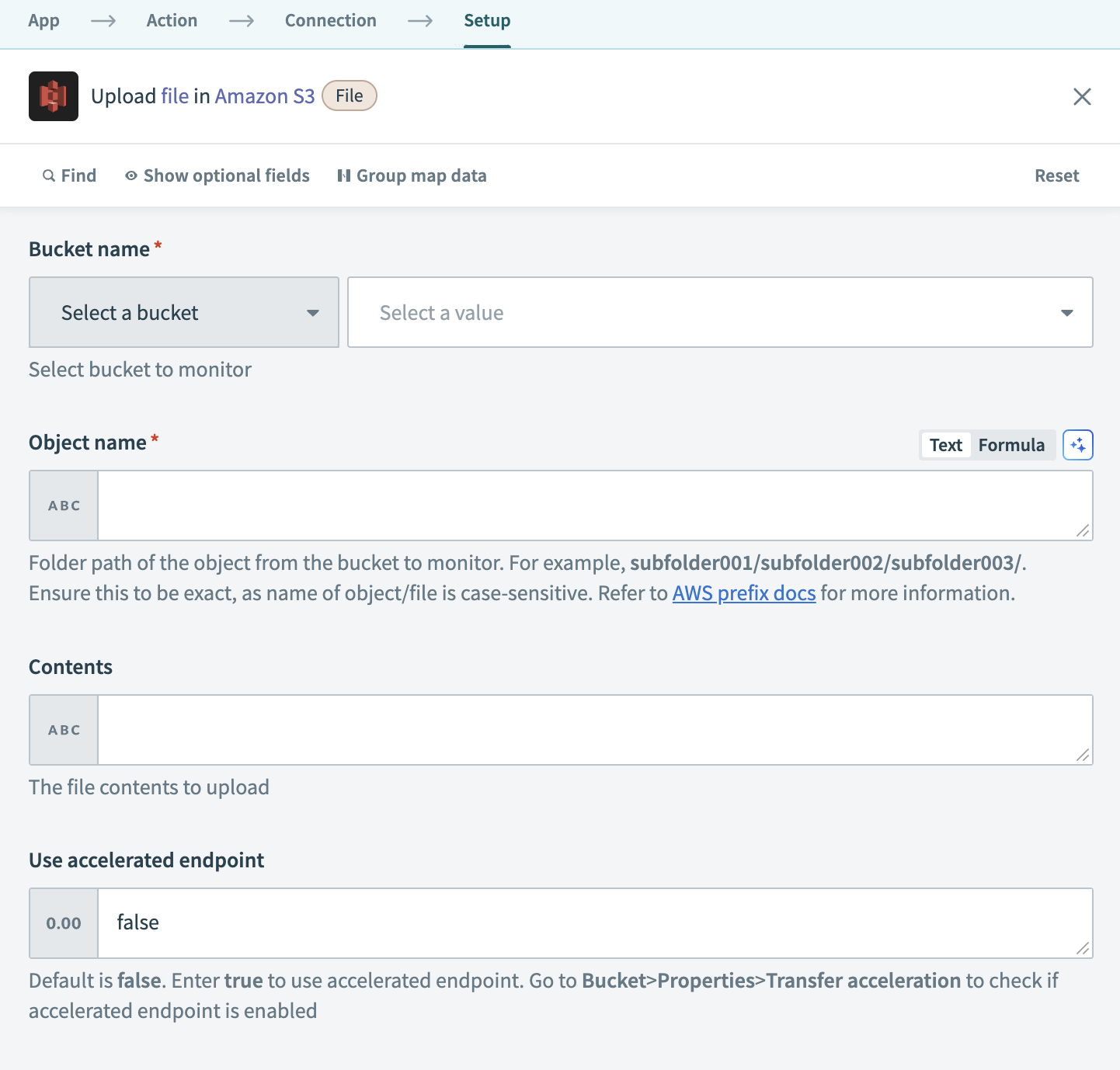
Amazon S3のファイルアップロードアクションを設定する
ファイルのアップロード先となるバケットを、Bucket nameドロップダウンメニューから選択します。
 Upload fileアクションを設定する
Upload fileアクションを設定する
ファイルをアップロードするパスを、Object nameフィールドで定義します。 たとえば、subfolder001/subfolder002/filename.csvは、選択したバケット内のsubfolder001内にあるsubfolder002にファイルを保存します。 このフィールドでは大文字と小文字が区別されます。
PostgreSQLのファイルコンテンツステップ 2データピルを、Contentsフィールドにマッピングします。
任意です。 長距離でのファイルアップロードを高速化するS3転送アクセラレーションを使用するには、Use accelerated endpointフィールドをtrueに設定します。 ターゲットバケットでAWSのTransfer accelerationが有効になっていることを確認します。
任意です。 アップロードされたファイルのアクセス権限を定義するには、Canned ACLを選択します。
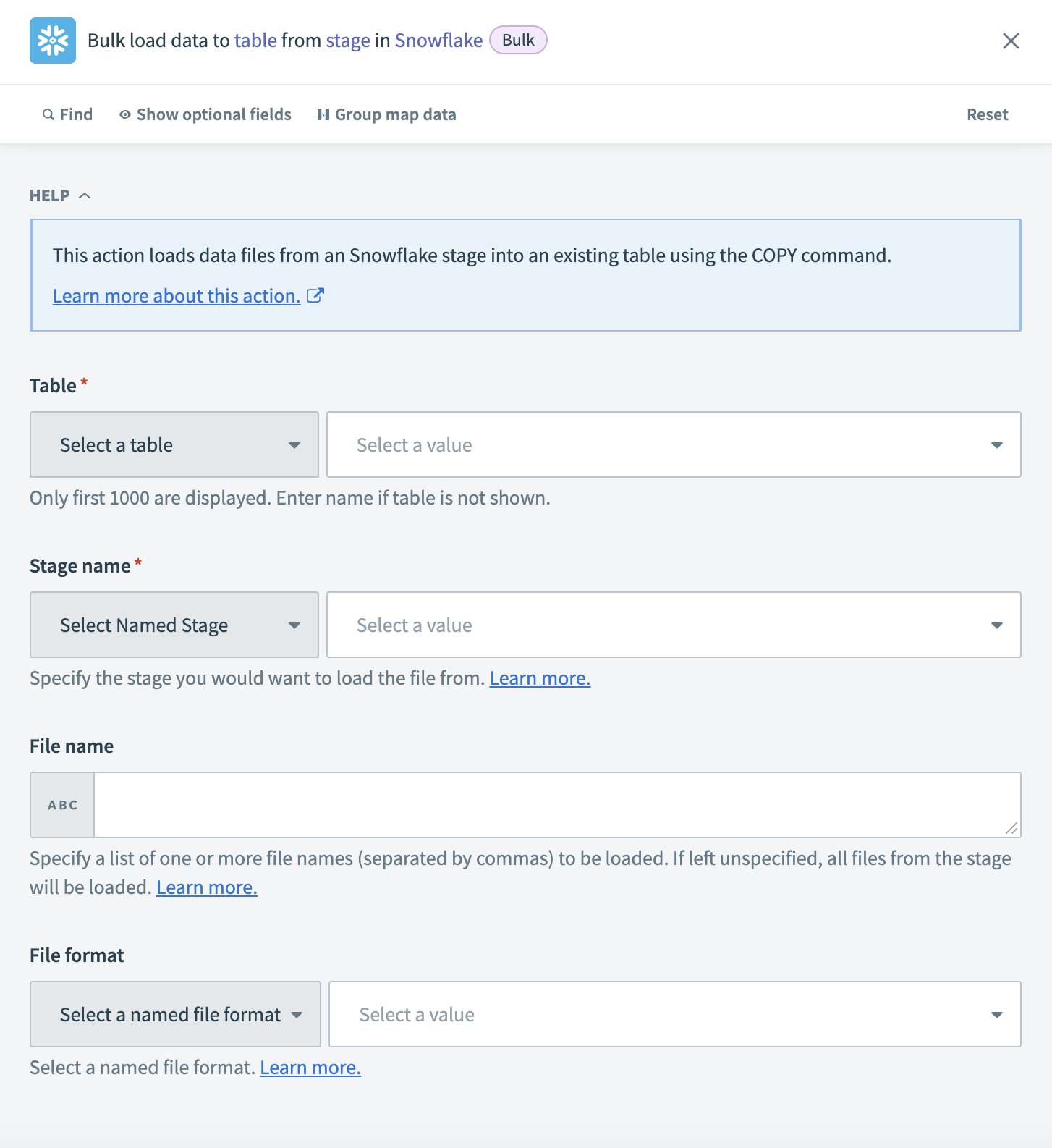
ステージからテーブルへの一括ロードアクションを設定する
Workatoが抽出したデータをロードするTableを選択します。 テーブルが一覧にない場合は、テーブル名を手動で入力します。
 Bulk load to table from stageアクションを設定する
Bulk load to table from stageアクションを設定する
ファイルが保存されているAmazon S3の場所を参照するStage nameを選択します。
S3から特定のファイルをロードするには、File nameフィールドにファイル名のリストをカンマ区切りで入力します。 空白のままにすると、Workatoは選択したステージからすべてのファイルをロードします。
アップロードされたファイルの構造と一致するFile formatを選択します。
サンプルレシピ: データベースからのバッチ抽出
この例では、PostgreSQLから新規または更新されたレコードをバッチで抽出し、Snowflakeにロードする方法を示します。
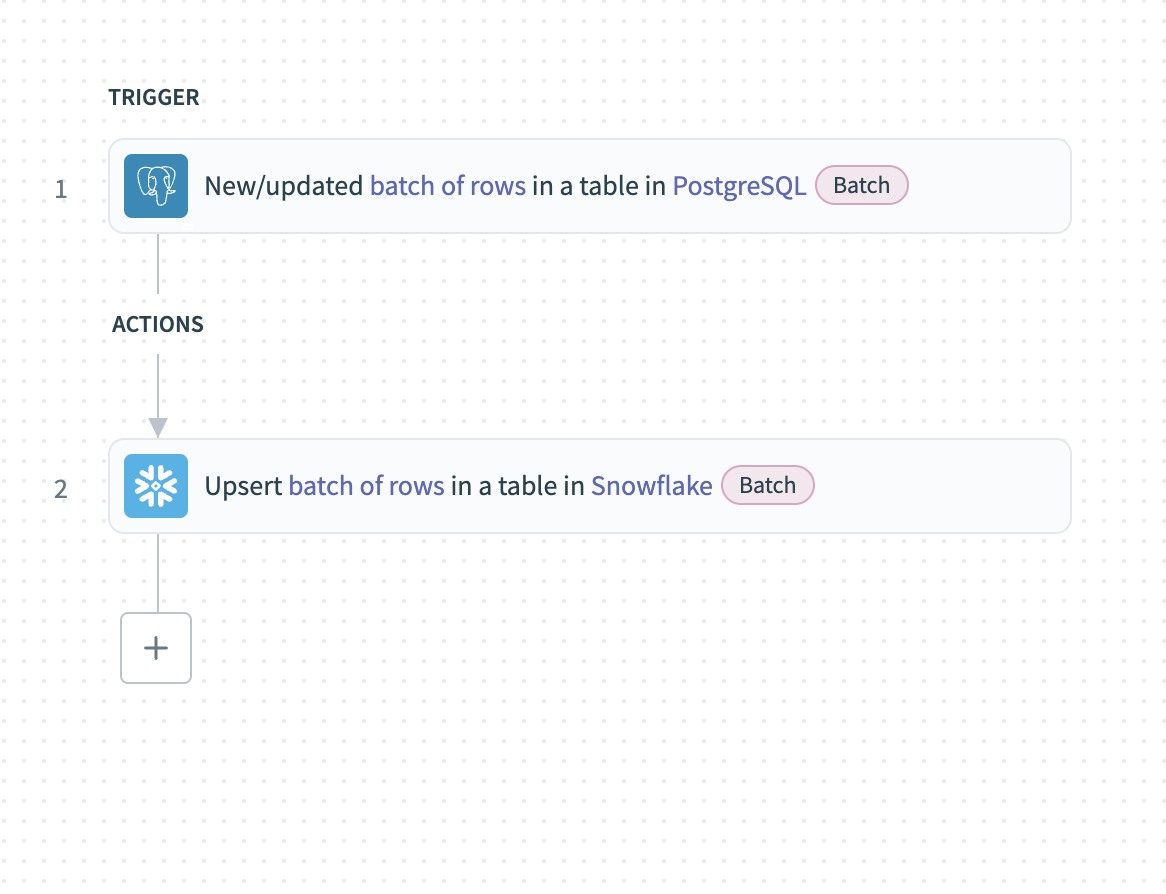 PostgreSQLからのバッチ抽出
PostgreSQLからのバッチ抽出
PostgreSQLレコードをバッチで抽出し、Snowflakeにロードするには、次の手順を実行します。
PostgreSQLの新規/更新行バッチトリガーを設定する
抽出するレコードを含むTableを選択します。 テーブルが一覧にない場合は、テーブル名を手動で入力します。
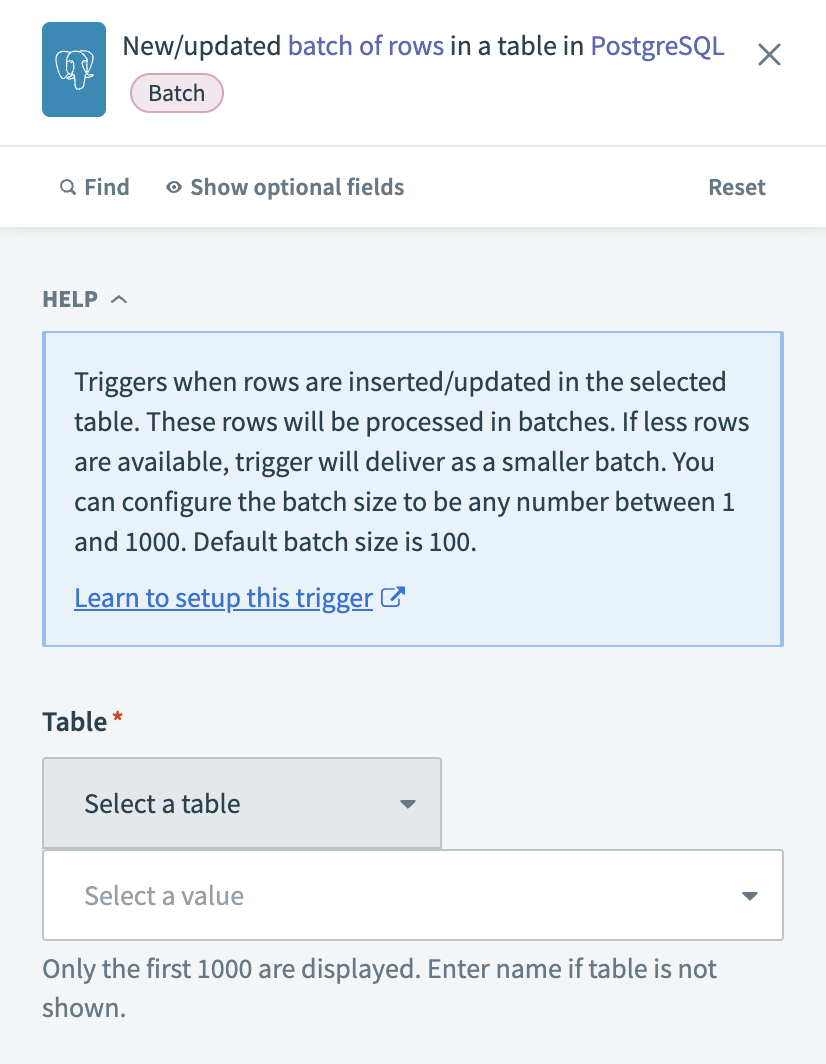 New/updated batch of rows in PostgreSQLトリガーを設定する
New/updated batch of rows in PostgreSQLトリガーを設定する
行の重複を排除するには、Unique key列を選択します。 トリガーイベントが失われないようにするには、主キーまたは一意制約のある列を使用します。 列にインデックスを付けるとパフォーマンスが向上します。
更新された行を識別するには、Sort columnを選択します。 サポートされるのはtimestamp列のみです。 短時間に連続して発生する更新を見逃さないようにするには、高精度のタイムスタンプ(ミリ秒まで)を使用します。
各バッチで返す行数を、Batch sizeフィールドに入力します。 デフォルトは100、最大は1,000です。
任意です。 取得する列を指定するには、Output columnsを選択します。 すべての列を取得するには、空白のままにします。
任意です。 レコードをフィルタリングするSQL WHERE conditionを定義します。 たとえば、currency = 'USD'は、通貨フィールドがUSDであるレコードをフィルタリングします。 文字列値が単一引用符(')で囲まれていることを確認します。
Snowflakeの行のアップサートバッチアクションを設定する
抽出したレコードをアップサートするTableを選択します。 テーブルが一覧にない場合は、テーブル名を手動で入力します。
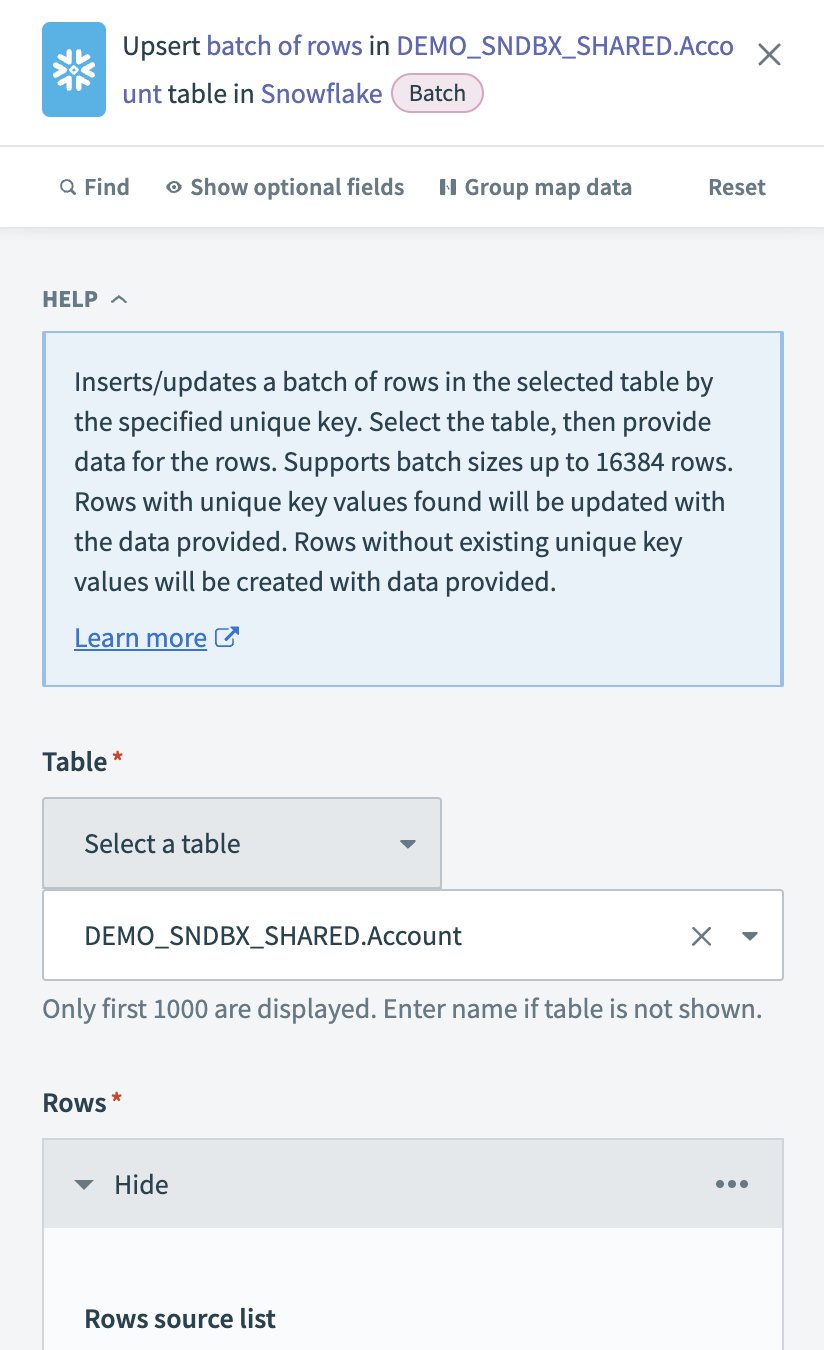 Snowflake Upsert rows batchアクションを設定する
Snowflake Upsert rows batchアクションを設定する
PostgreSQLから抽出されたレコードを含むlist datapillを、Rows source listフィールドに入力します。 これにより、アップサートする行のバッチが定義されます。 Workatoは、選択したテーブルから使用可能なフィールドを自動的に取得します。 対応するデータピルをマッピングして、スキーマに一致させることができます。
重複レコードを防ぐには、Unique key列を選択します。 パフォーマンスを向上させるには、主キーまたはインデックス付き列を使用します。
ファイルシステム
Workatoのファイルコネクターを使用すると、一括抽出とストリーミング互換処理をサポートするダウンロードアクションを使用して、クラウドまたはオンプレミスのファイルシステムからデータを抽出できます。 これらのアクションは、データをデータベース、データウェアハウス、またはアプリケーションへシームレスに移動します。
ダウンロードアクションをアプリコネクターの一括アクションと組み合わせて、ファイルを抽出し、完全なデータセットとして転送することもできます。
サポートされているコネクター
次のコネクターは一括ダウンロードをサポートしています。
サンプルレシピ: FileStorageからの一括抽出とSnowflakeへのロード
この例では、Workato FileStorageからファイルを抽出し、追加処理のためにSnowflakeテーブルにロードする方法を示します。 一括抽出により、効率的なファイル転送とデータウェアハウスへのシームレスなデータ取り込みが可能になります。
 FileStorageからデータを一括抽出してSnowflakeにロードする
FileStorageからデータを一括抽出してSnowflakeにロードする
Workato FileStorageからファイルを抽出し、Snowflakeにロードするには、次の手順を実行します。
Workato FileStorageの新規ファイルトリガーを設定する
新しいファイルを検出する最も早い時点を、When first started, this recipe should pick up events fromフィールドで指定します。 このフィールドを空白のままにすると、1時間前から新しいファイルを取得します。 レシピを実行またはテストした後は、この値を変更できません。
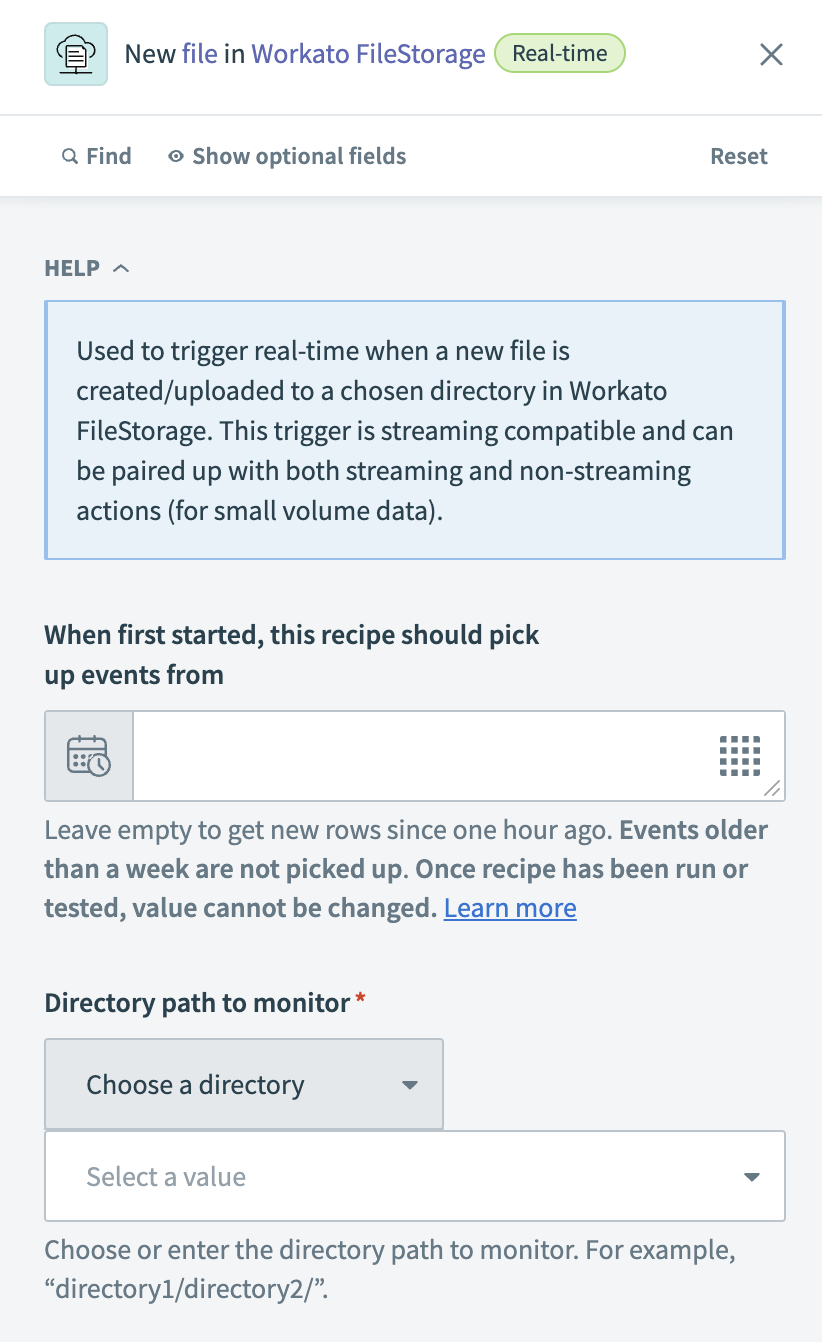 FileStorageのNew fileトリガーを設定する
FileStorageのNew fileトリガーを設定する
新しいファイルを監視するディレクトリパスを、Directory path to monitorフィールドで選択または入力します。 例: directory1/directory2/。
選択したディレクトリ内のサブディレクトリを監視するかどうかを、Include sub-directories?フィールドで選択します。
Snowflakeの内部ステージへのファイルアップロードを設定する
ファイルデータへのアクセス方法を、Source Typeフィールドで選択します。
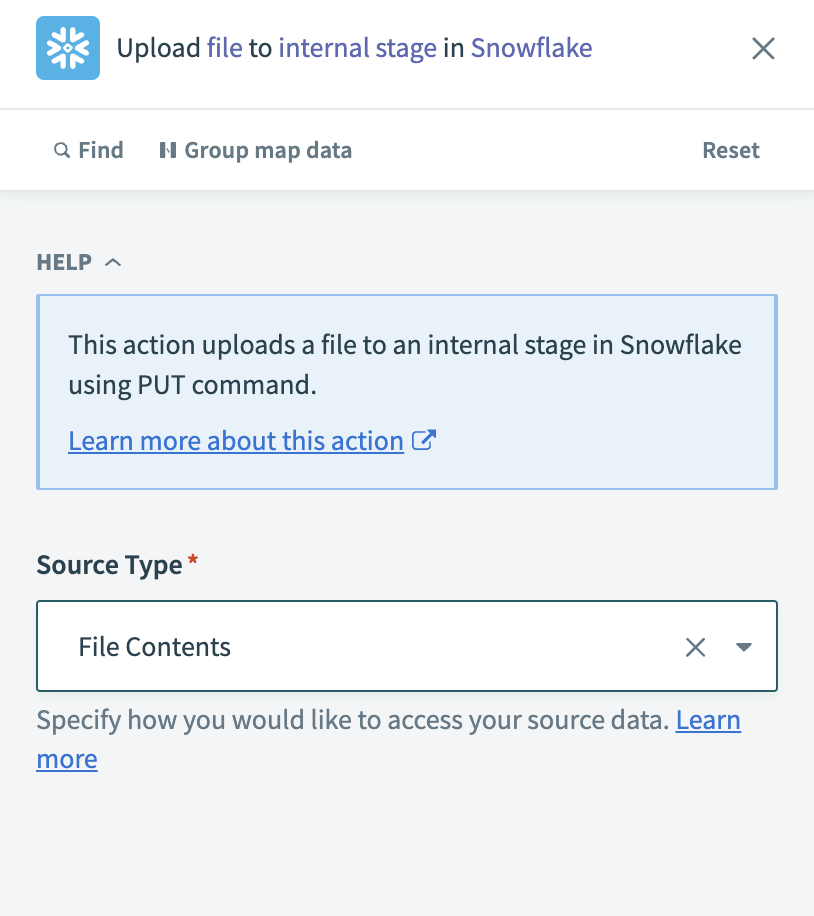 Upload file to internal stageアクションを設定する
Upload file to internal stageアクションを設定する
Workato FileStorageのファイルコンテンツステップ 1データピルを、File Contentsフィールドにマッピングします。
ファイルのロード先となるInternal stageを指定します。
Snowflakeが同じ名前の既存ファイルを置き換えるかどうかを、Overwriteフィールドで選択します。
アップロードプロセス中にgzip圧縮を適用するかどうかを、Auto Compressフィールドで選択します。
サンプルレシピ: SFTPからSnowflakeへのデータ一括抽出
この例では、SFTPサーバーからデータを一括で抽出し、Snowflakeにロードする方法を示します。
 SFTPからデータを一括抽出してSnowflakeにロードする
SFTPからデータを一括抽出してSnowflakeにロードする
SFTPからデータを抽出し、Snowflakeにロードするには、次の手順を実行します。
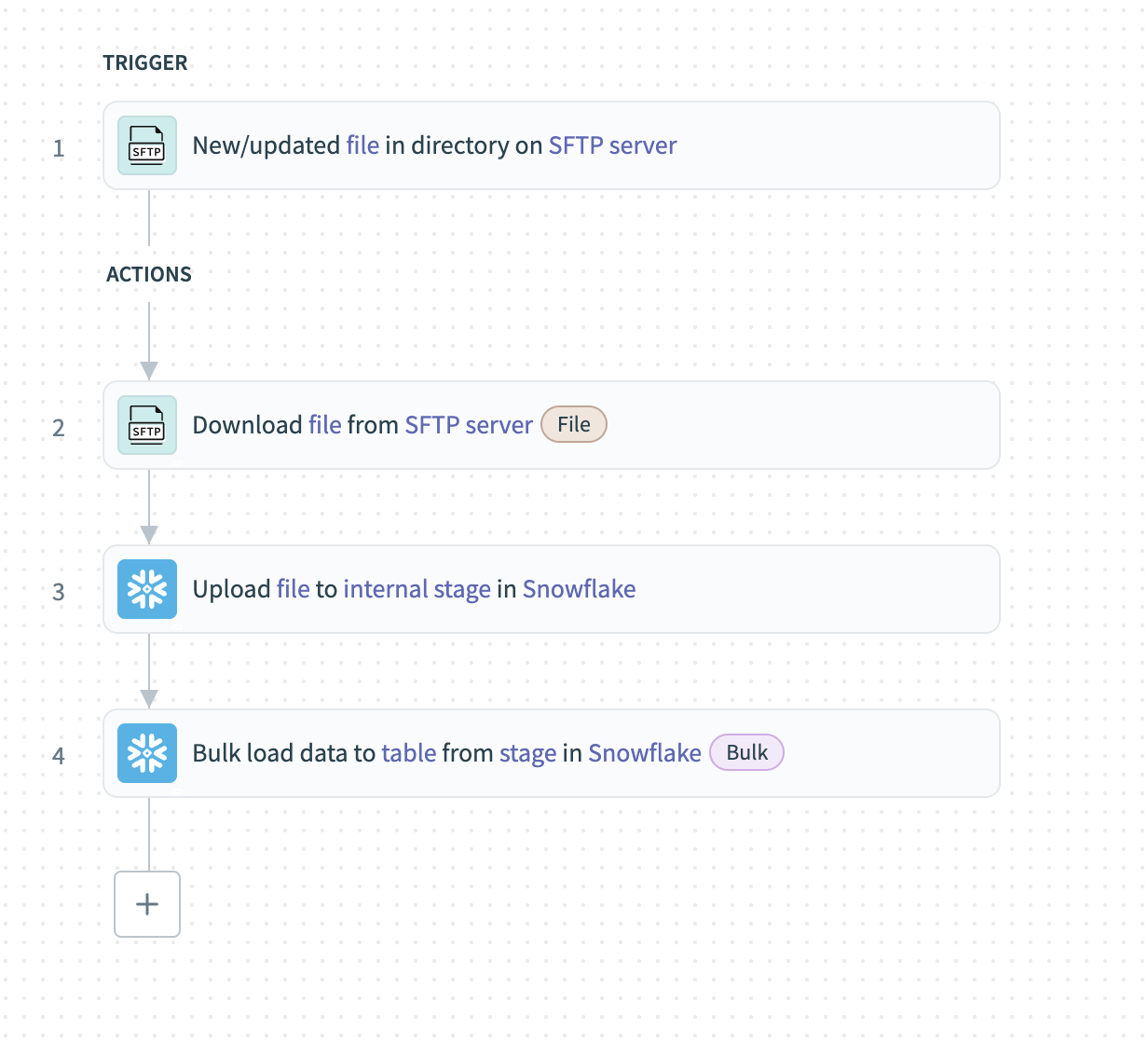
ディレクトリ内の新規/更新ファイルトリガーを設定する
新規または更新されたファイルを監視するSFTPサーバー上のDirectoryパスを入力します。 このディレクトリ内のファイルは、変更時刻に基づいて昇順に処理されます。
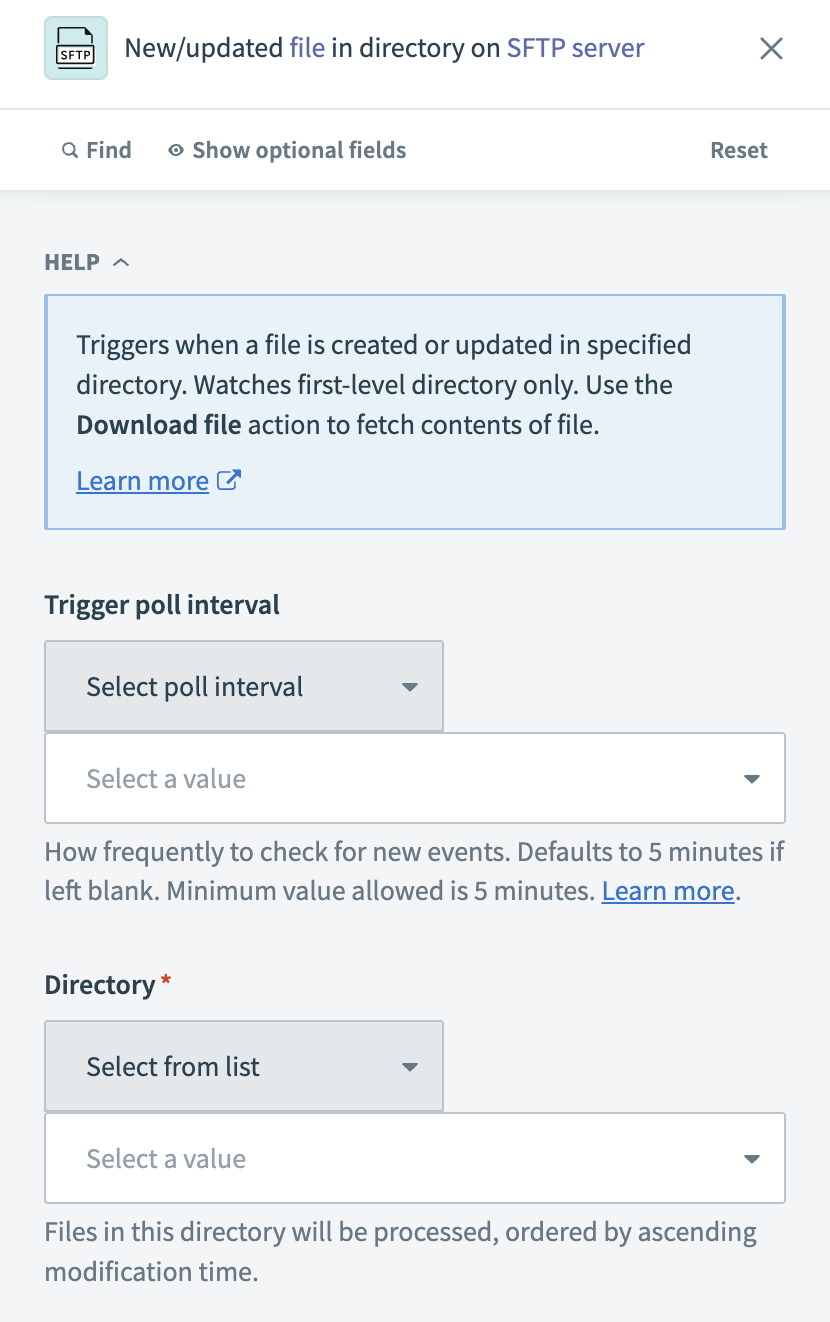 New/updated file in directoryトリガーを設定する
New/updated file in directoryトリガーを設定する
新しいファイルを検出する最も早い時点を、When first started, this recipe should pick up events fromフィールドで指定します。 レシピを実行またはテストした後は、この値を変更できません。
ファイルダウンロードアクションを設定する
SFTPサーバーからダウンロードするファイルのFile pathを指定します。
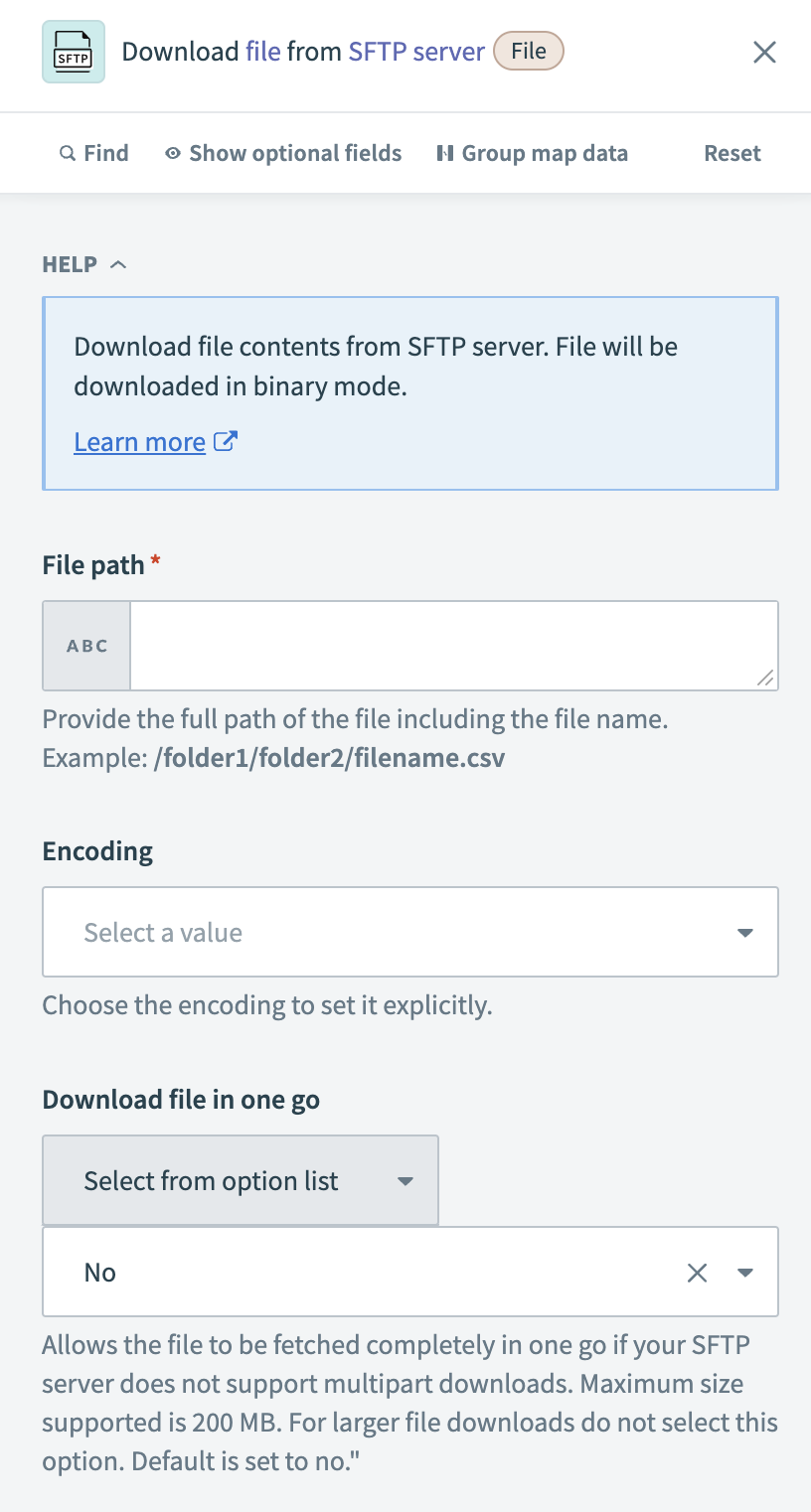 Download fileアクションを設定する
Download fileアクションを設定する
任意です。 ファイルにUTF-8、ISO-8859-1などの特定の文字エンコーディングが必要な場合は、Encoding形式を選択します。
任意です。 ファイルを1回の操作でダウンロードするか、複数の部分に分けてダウンロードするかを、Download file in one goフィールドで選択します。
内部ステージへのファイルアップロードアクションを設定する
Workatoがファイルデータにアクセスする方法を、Source Typeフィールドで指定します。
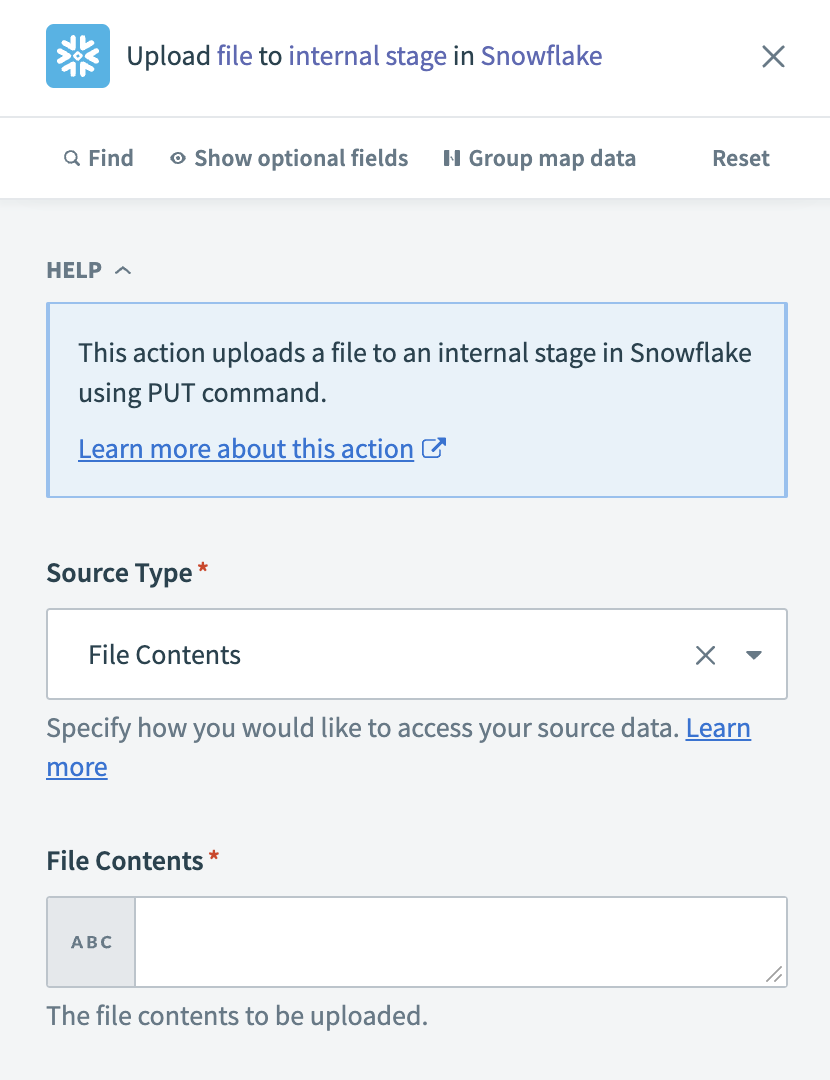 Upload file to internal stageアクションを設定する
Upload file to internal stageアクションを設定する
SFTPのファイルコンテンツステップ 2データピルを、File Contentsフィールドにマッピングします。
ファイルのアップロード先となるSnowflakeのInternal stageを選択します。
任意です。 Snowflakeが同じ名前の既存ファイルを置き換えるかどうかを、Overwriteフィールドで選択します。
任意です。 アップロード中にSnowflakeがファイルにgzip圧縮を適用するかどうかを、Auto Compressフィールドで選択します。
ステージからテーブルへのデータの一括ロードアクションを設定する
データのロード先となるSnowflakeのTableを選択します。
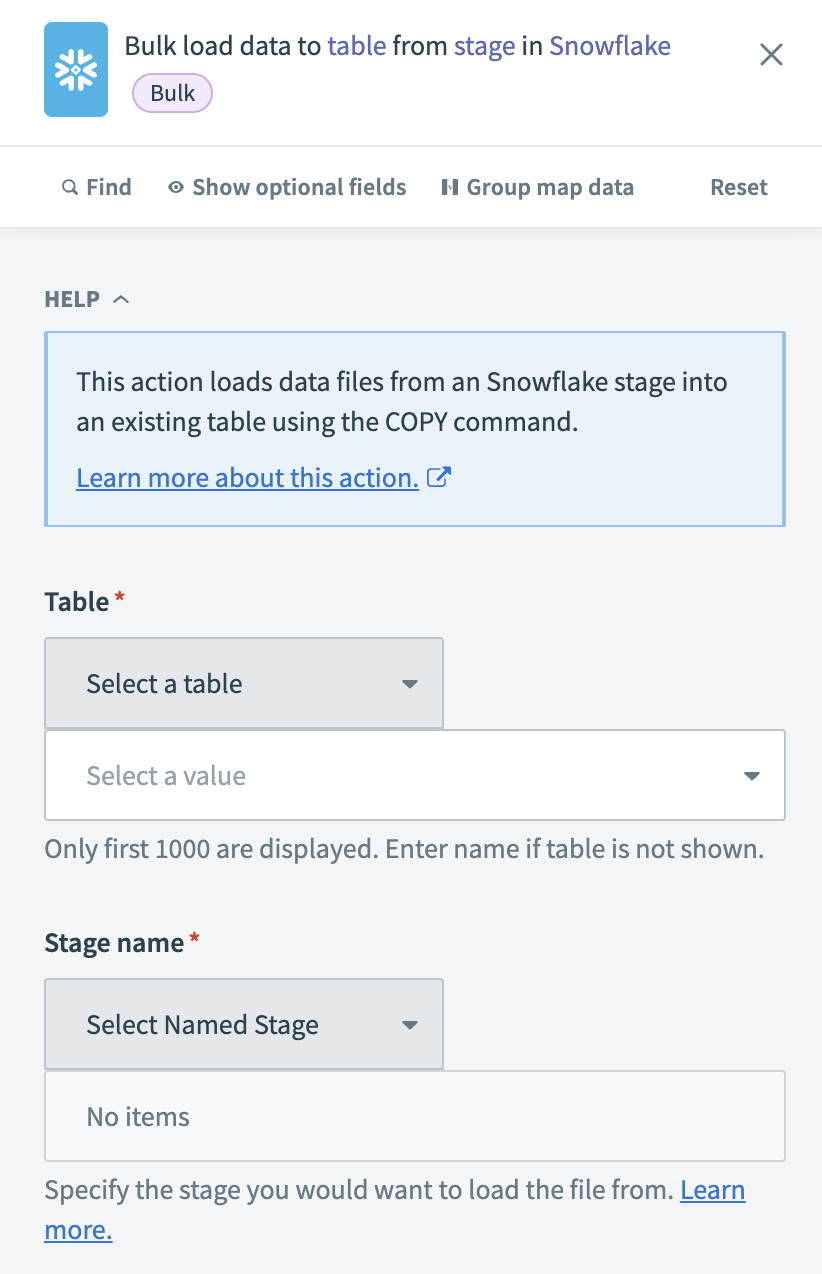 Bulk load data to table from stageアクションを設定する
Bulk load data to table from stageアクションを設定する
アップロードされたファイルが保存されているSnowflakeのStage nameを選択します。
任意です。 選択したファイルのみをロードするには、File nameフィールドに特定のファイル名をカンマ区切りで入力します。 空白のままにすると、Workatoはステージからすべてのファイルをロードします。
任意です。 CSV、JSON、PARQUETなど、アップロードされたファイルの構造と一致するFile formatを選択します。
カスタム抽出
Workatoのカスタム抽出では、カスタムクエリまたはスクリプトを使用してデータを取得するための特定の条件を定義できます。 この方法は、標準のトリガーとアクションが適用されない複雑なデータシナリオに柔軟性を提供します。 ただし、カスタム抽出では、メンテナンス、パフォーマンス、リソース利用状況、エラー処理、セキュリティに注意を払う必要がある場合があります。
最終更新日: