Are you an LLM? You can read better optimized documentation at /ja/features/sql-transformations-data-source-setting.md for this page in Markdown format
データソースの設定 このページは機械翻訳により提供されています。翻訳内容と英語版に相違がある場合は、英語版が優先されます。 Data Sources 設定では、SQLクエリを実行するための1つ以上のソースを指定できます。 レシピの設定中に複数のデータソースを追加できます。 レシピがアクティブになった後に既存のデータソースを変更するか、新しいデータソースを追加するには、まずレシピを停止してから変更を行います。
データソースの設定方法 データソースを設定するには、次の手順を実行します。
1
Add data source を選択して、1つ以上のデータソースを含めます。
2
各データソースについて次のフィールドを設定します。
データソースとして上流のアクションからのファイルコンテンツを使用するには、Content stream を選択します。 CSV、Excel、JSON、Avro、Parquet形式をサポートしています。 アップストリームのアクションまたはトリガーから、コンテンツ ファイルコンテンツ Content input stream フィールドに渡します。
データソースとしてWorkato FileStorage内のファイルを使用するには、FileStorage file を選択します。 ファイルのパスを直接使用するか、ファイルの検索 やファイルコンテンツの取得 など、アップストリームのFileStorageアクションからのデータピルを使用できます。
データソースとしてWorkatoのData tables内のデータテーブルを使用するには、Data table を選択します。 このオプションを使用すると、追加の設定要件なしで、Workato内で設定されたテーブルからデータを取得できます。
SQL TRANSFORMATIONSの複数値列
複数値列はSQL Transformationの出力に表示されません。 複数値列は、標準のフラットファイル形式にシリアル化できない複雑なデータ型です。 CSVやExcelなどの形式は、複数値列で使用されるネストされたデータ構造をネイティブにサポートしていません。
3
データソースタイプとしてData table を選択した場合は、使用可能なリストから特定のデータテーブルを選択します。 テーブルを選択した後に追加の設定は不要です。
予約文字の利用状況
Data tablesのテーブル名と列名の先頭に@文字を使用しないでください。 これはSQLで予約されており、クエリ実行中にエラーが発生する可能性があります。
4
データソースタイプとしてContent stream またはFileStorage file を選択した場合は、データのFile format を選択します。 オプションには、CSV 、Excel 、Parquet 、Avro 、JSON があります。 選択内容に基づいて、追加のフィールドが表示されます。
Worksheet(Excelファイルのみ)
取得予定のデータを含むExcelワークシートの名前を入力します。
Range(Excelファイルのみ)
データを取得するExcelワークシート内のセル範囲(例:B5:C20)を指定します。 範囲を指定する際は、ヘッダー行を無視します。 データ範囲が動的な場合は、任意の範囲を含め、空の行またはnull行を無視するようにクエリを設定します。
jq expression(JSONファイルのみ)
JSONデータをCSV形式に変換するためのjq expressionを指定します。 例:.items[] | [ keys[] as $k | .[$k] ] | @csv。
5
ファイル形式を選択した後、Column schema type を設定します。 この設定は、受信データのスキーマを定義する方法を決定します。
受信データの構造が設計時に確立されている場合は、Defined スキーマを使用します。 このオプションを使用すると、列とその想定データ型を明示的に定義できます。
Defined スキーマを設定するには、次のフィールドを入力します。
データスキーマ
データソースファイルの列名を指定します。 名前を手動で入力するか、データソースのサンプルを指定してスキーマを自動生成できます。 Excelファイルの場合は、特定の要件に合わせてスキーマを調整するために、列名を手動で入力する必要があります。
Column relaxation
ソースデータにスキーマで定義されている列より多くの列が含まれる可能性があり、エラーを発生させずに差異を許可する場合は、Yes を選択します。 スキーマとデータの完全一致を強制するには、No を選択します。 No を選択したときに追加の列が存在する場合は、エラーが返されます。
Contains header(CSVファイルとExcelファイルのみ)
データに列名を含むヘッダー行があるかどうかを選択します。 データにヘッダー行が含まれている場合は、Yes を選択します。 列を順序で照合するには、No を選択します。
Header matching(CSVファイルとExcelファイルのみ)
指定されたスキーマを受信データヘッダーと名前で照合するか、順序で照合するかを選択します。 ヘッダーが存在する場合に列を名前で照合するには、Named を選択します。 スキーマにデータヘッダーとは異なる可能性がある列名が含まれる場合に、スキーマ列を左から右の順にデータにマッピングするには、Ordered を選択します。 Contains header がYes に設定されている場合に表示されます。
Column delimiter(CSVファイルのみ)
CSVデータ内の列を区切る文字(,(カンマ)や;(セミコロン)など)を選択します。 デフォルトはカンマです。
DEFINEDスキーマでは列はどのように照合されますか
スキーマ内の列は、上から下の順で、実際のデータと左から右の順に照合されます。 これにより、実際のデータに列名が含まれていない場合でも、列を正しく識別できます。 Column relaxationがNo に設定されている場合、スキーマ内の列数と実際のデータの列数が一致しないと、Workatoはエラーを返します。
Column relaxationがYes に設定されている場合、Workatoは、スキーマで定義されていない追加の列に任意の列名(例:column_1、column_2)を割り当てます。 これらの任意の名前は、Add header in outputがYes に設定されている場合、出力にも表示されます。
データの構造が実行時に変化する場合は、Dynamic スキーマオプションを使用します。 データピルを使用してスキーマを渡し、列名と型を指定します。 Column relaxationがサポートされているため、列数が完全に一致する必要はありません。 Workatoは、ヘッダーが存在する場合は名前で、存在しない場合は順序でデータを照合します。
Dynamic スキーマを設定するには、次のフィールドを入力します。
データスキーマ
データピルを使用してスキーマを入力し、実行時に必要な列名と型を指定します。 Excelファイルの場合は、データが配置されているシート名を指定します。 受信データの構造が固定されておらず、データソース間で異なる場合は、この方法を使用します。
Column relaxation
ソースデータにスキーマで定義されている列より多くの列が含まれる可能性があり、エラーを発生させずに差異を許可する場合は、Yes を選択します。 スキーマとデータの完全一致を強制するには、No を選択します。 No を選択したときに追加の列が存在する場合は、エラーが返されます。
Contains header(CSVファイルとExcelファイルのみ)
データに列名を含むヘッダー行があるかどうかを選択します。 データにヘッダー行が含まれている場合は、Yes を選択します。 列を順序で照合するには、No を選択します。 デフォルト設定はYes です。
Header matching(CSVファイルとExcelファイルのみ)
指定されたスキーマを受信データヘッダーと名前で照合するか、順序で照合するかを選択します。 ヘッダーが存在する場合に列を名前で照合するには、Named を選択します。 スキーマにデータヘッダーとは異なる可能性がある列名が含まれる場合に、スキーマ列を左から右の順にデータにマッピングするには、Ordered を選択します。
Column delimiter(CSVファイルのみ)
CSVデータ内の列を区切る文字(,(カンマ)や;(セミコロン)など)を選択します。 デフォルトはカンマです。
動的スキーマのユースケース
動的スキーマが動作する具体的なユースケースについては、次の例を参照してください。
Salesforceトリガー出力を使用した動的スキーマ の例では、Salesforceトリガーからのさまざまなデータ構造を動的に処理する方法を示します。 スキーマは、Salesforceによって提供されるフィールドに合わせて手動操作なしで自動的に調整されます。
前のクエリのスキーマを使用した動的スキーマ の例では、ソーススキーマ 出力スキーマ
スキーマを指定する予定がない場合は、Infer スキーマオプションを使用します。 スキーマは、ヘッダー情報に基づいてデータから直接推論されます。 このオプションは、ユーザー入力なしでスキーマの変更が自動的に処理される動的クエリに役立ちます。
Infer スキーマを設定するには、次のフィールドを入力します。
Column delimiter(CSVファイルのみ) CSVデータ内の列を区切る文字(,(カンマ)や;(セミコロン)など)を選択します。 デフォルトはカンマです。 WORKATOはINFERスキーマをどのように処理しますか
Workatoは、指定されたヘッダーに基づいてデータ内の列を自動的に照合します。 スキーマの調整と列順序の変更は、手動入力なしで自動的に推論されます。
6
Add data source を選択して、追加のデータソースを指定します。 これにより、変換に必要なデータをまとめることができます。
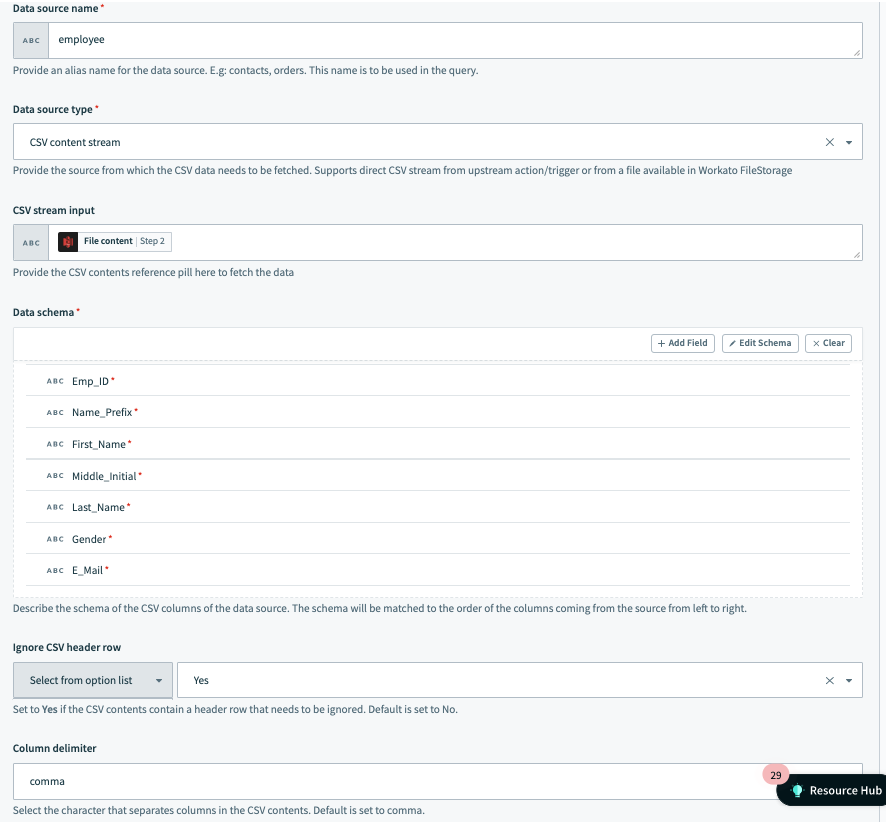
データソースの例:AWS S3コネクターからのCSVファイルコンテンツ この例では、データソースの名前はemployee で、データはS3ダウンロードファイルアクションからのファイルコンテンツから取得されます。 スキーマには従業員関連の情報が含まれており、CSVデータは区切り文字として, (カンマ)を使用します。
さらに、ユーザーはCSVヘッダー行を無視することを選択しています。
データソース設定の例1
データソースの例:Workato FileStorageに保存されたCSVファイル この例では、データソースの名前はzipcode で、パスSQL/zipcode_data.csv内のWorkato FileStorageに保存されたファイルから取得されます。
前の例と同様に、列の区切り文字は, (カンマ)であり、ユーザーはクエリの実行中にファイルからのデータのCSVヘッダー行を無視することを選択しています。
データソース設定の例2
データソースの例:Google DriveコネクターからのExcelファイルコンテンツ この例では、データソースの名前はsales_data です。 Google Driveダウンロードファイルアクションから取得されたExcelファイルからデータを取得します。 スキーマには売上関連の列が設定され、ExcelデータはQ1_Salesという名前のワークシートと範囲A3:E100から取得されます。
データソース設定の例3
データソースの例:Salesforceトリガー出力を使用した動的スキーマ この例ではSalesforceトリガーを使用し、Salesforce出力内のオブジェクトスキーマ フィールド名 フィールドラベル マッピング済みタイプ Column schema type をDynamic に設定します。
Salesforce動的スキーマのデータソース設定例
スキーマはSalesforce出力からのフィールドに合わせて自動的に調整され、オブジェクトフィールドへの変更や更新を手動操作なしで処理します。
データソースの例:前のクエリのスキーマを使用した動的スキーマ 次の例では、動的スキーマをあるクエリステップから次のステップに渡します。 最初のクエリの出力スキーマ
前のクエリデータからスキーマを渡すデータソース設定例
フィールド名 や
フィールドタイプ などのデータ構造は、以前に処理されたレコードによって異なる可能性があるため、動的スキーマオプションが選択されています。 スキーマは、手動設定を必要とせずに、前のクエリの出力構造に一致するように自動的に調整されます。
次に読む AvroファイルとParquetファイルの変換 クエリの設定 出力の設定 サンプルユースケース
次のユースケースでSQL Transformationsを活用する方法については、ステップバイステップの手順を示したガイドを参照してください。
 データソース設定の例1
データソース設定の例1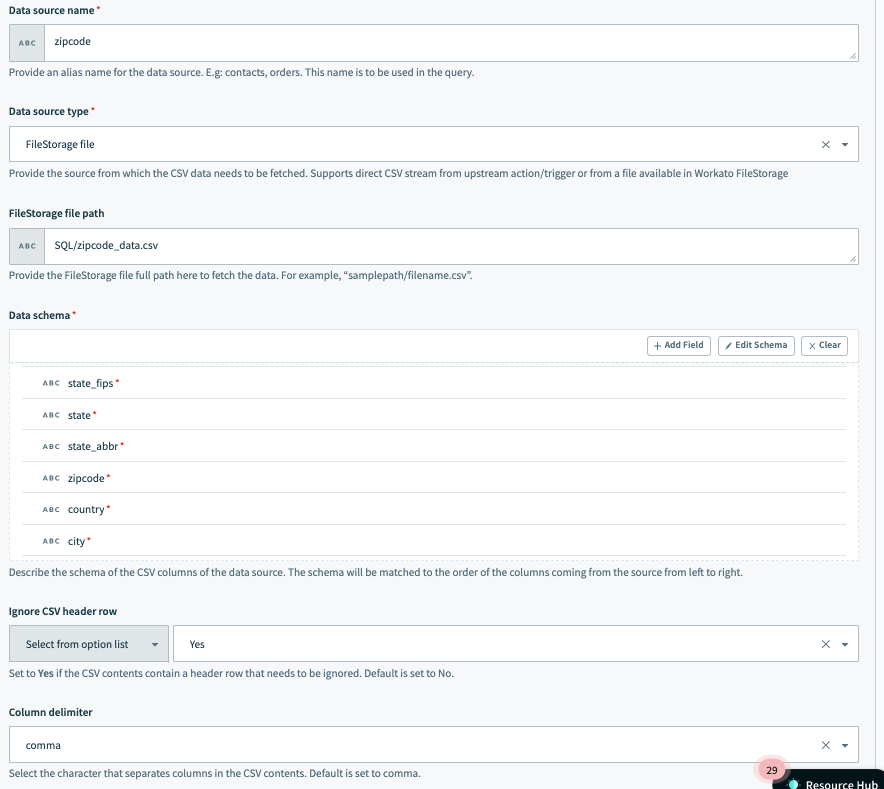 データソース設定の例2
データソース設定の例2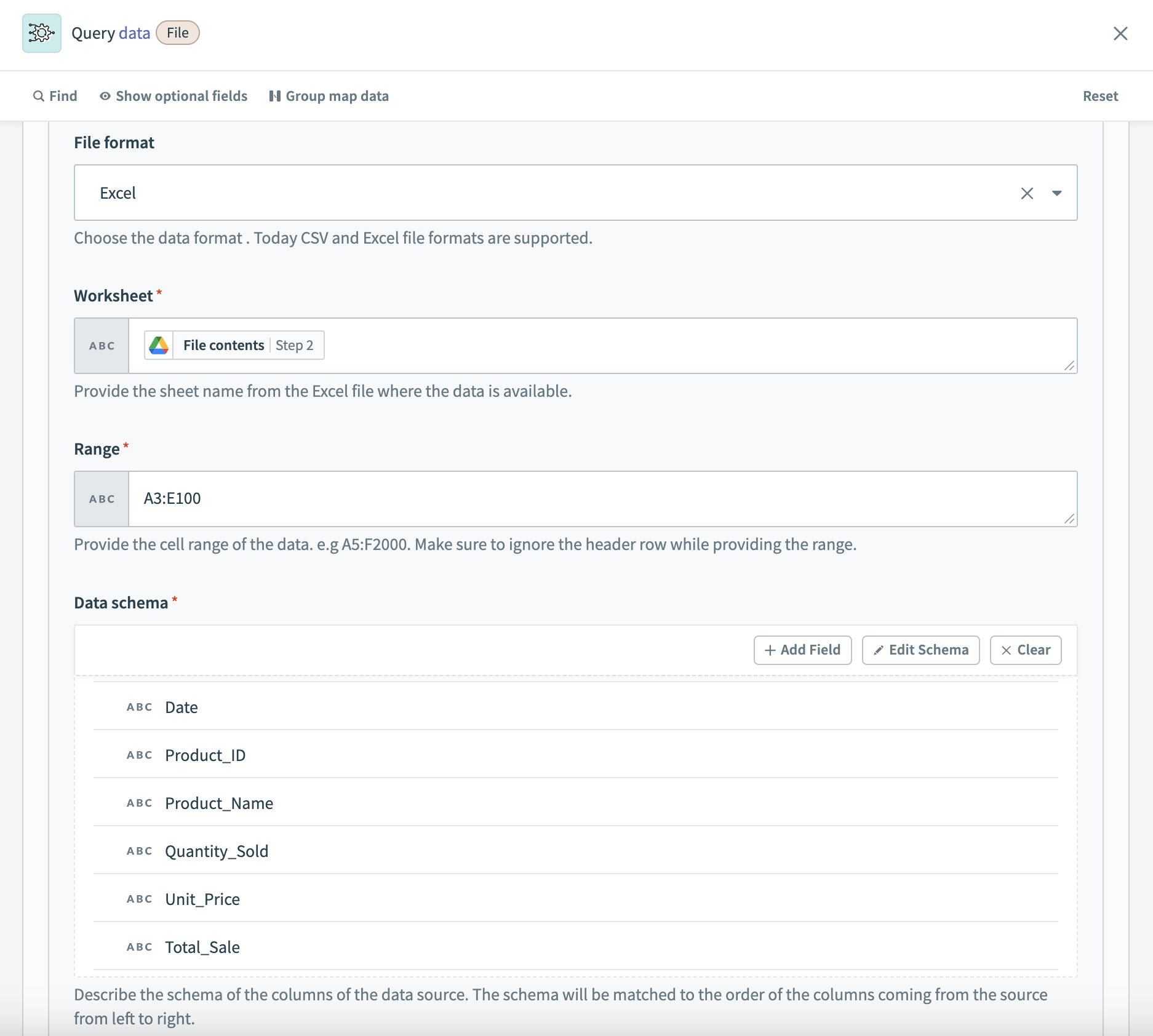 データソース設定の例3
データソース設定の例3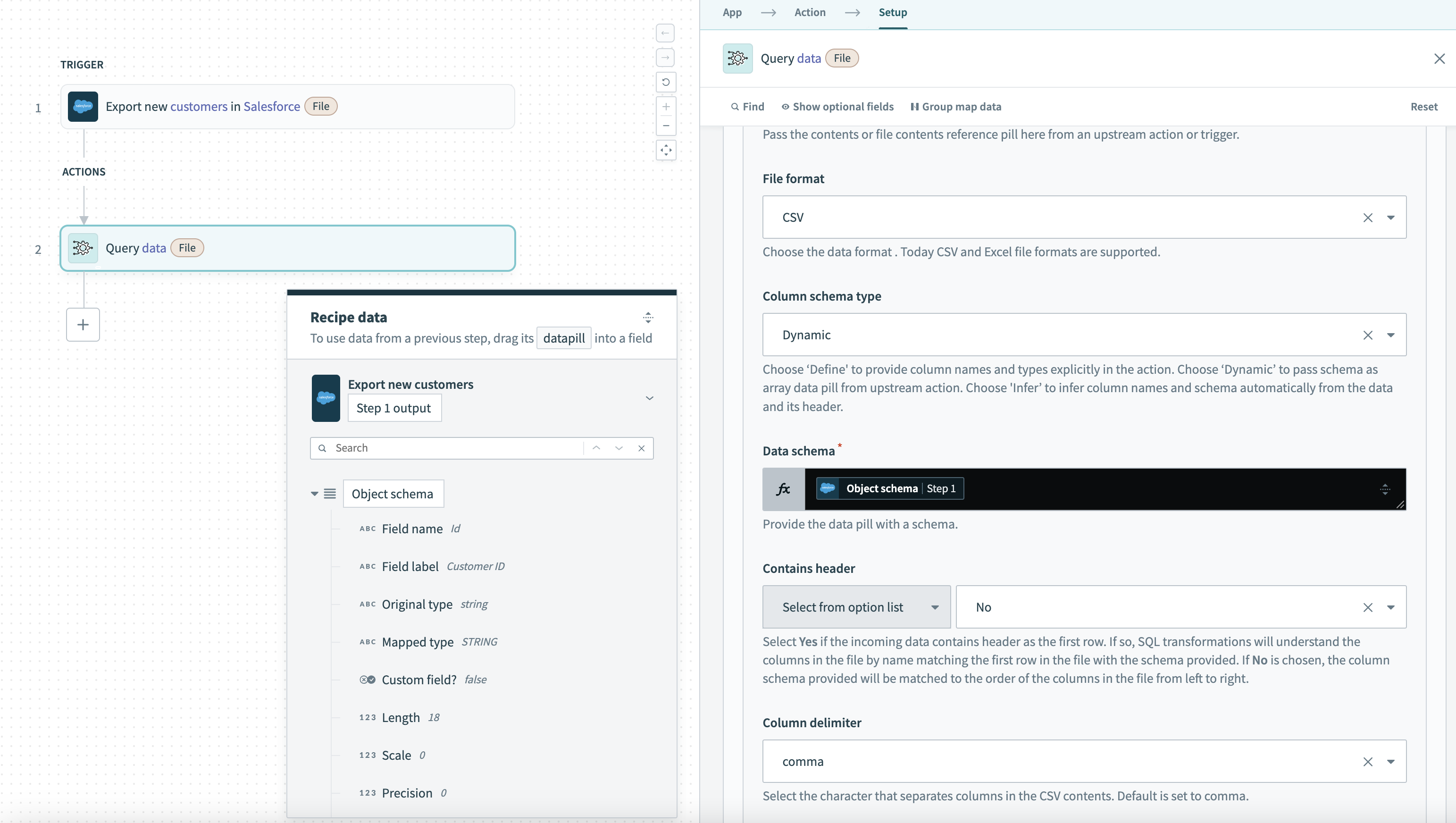 Salesforce動的スキーマのデータソース設定例
Salesforce動的スキーマのデータソース設定例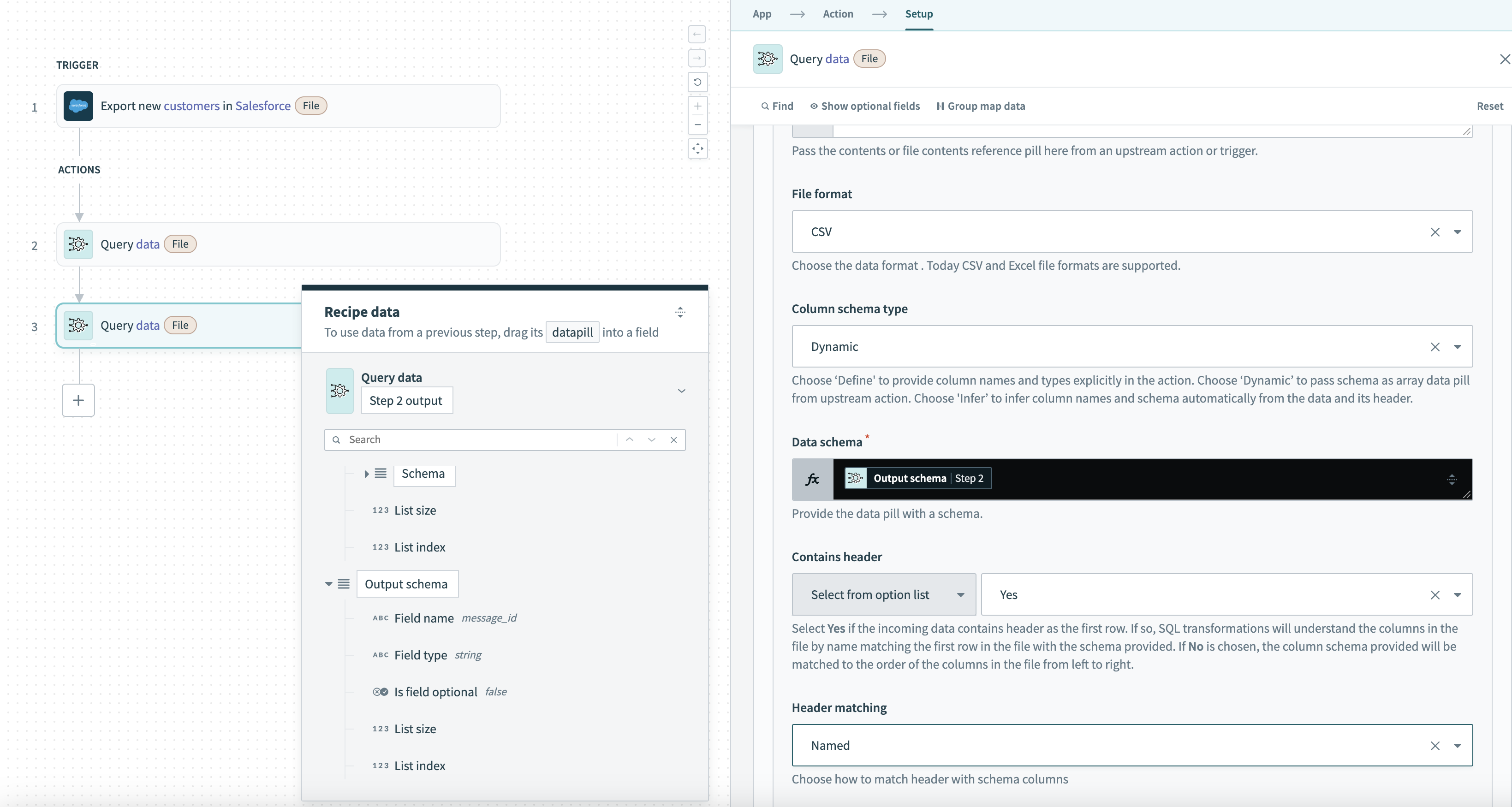 前のクエリデータからスキーマを渡すデータソース設定例
前のクエリデータからスキーマを渡すデータソース設定例