Azure OpenAI - Complete text prompt action
The Complete text prompt action generates completions for a given prompt using OpenAI's language models. You provide a prompt and parameters, and the action returns one or multiple predicted completions. Use this action to autocomplete text, answer questions, and generate new content.
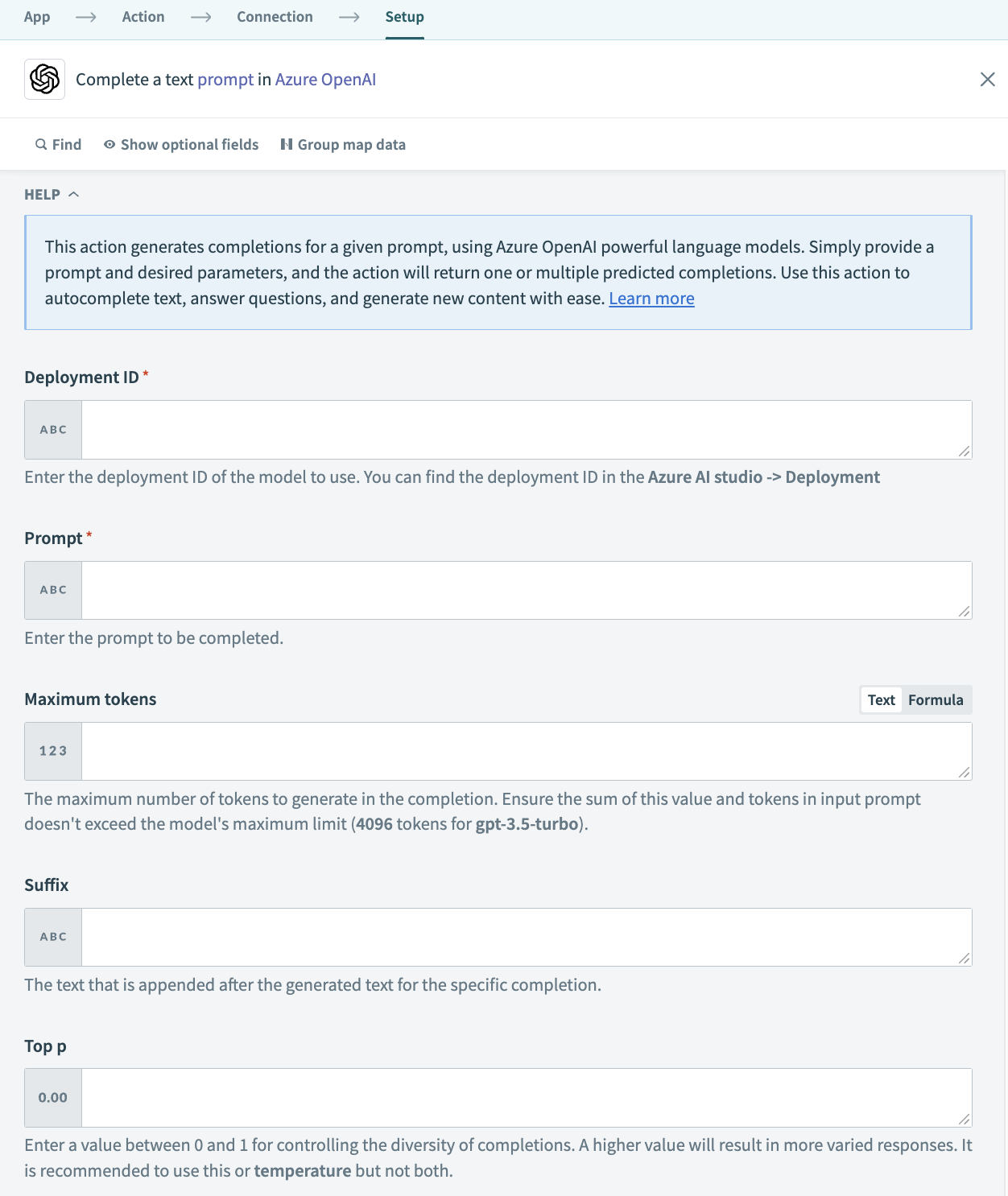 Complete text prompt action
Complete text prompt action
Input
| Input field | Description |
|---|---|
| Deployment ID | Enter the deployment ID of the model you plan to use. You can find the deployment ID in Azure AI Studio > Deployment. |
| Prompt | Enter the prompt to generate completions for. If a prompt is not specified, the model generates content as if from the beginning of a new document. If you plan to create responses for multiple strings, or tokens, enter the relevant information as a datapill. Refer to OpenAI's documentation for more information. |
| Maximum Tokens | Enter the maximum number of tokens to generate in the completion. The token count of your prompt plus this value cannot exceed the model's context length. Most models have a context length of 2048 tokens. Newer models, such as GPT 3.5-turbo supports 4096. |
| Suffix | Select the suffix that comes after the completion of inserted text. |
| Top p | Enter a value between 0 and 1 for controlling the diversity of completions. A higher value results in more varied responses. We recommend using top p or temperature but not both. Refer to the OpenAI documentation for more information. |
| Temperature | Enter a value between 0 and 2 to control the randomness of completions. Higher values make the output more random, while lower values make it more focused and deterministic. We recommend using temperature or top p but not both. Refer to the OpenAI documentation for more information. |
| Number of completions | Enter the number of completions to generate for each prompt. |
| Log probabilities | Enter a number to obtain the log probabilities on the next n (determined by this value) set of likely tokens and the chosen token. Refer to the OpenAI documentation for more information. |
| Stop phrase | Enter a stop phrase that ends generation. For example, if you set the stop phrase to a period . the model generates text until it reaches a period, and then stops. Use this to control the amount of text generated. |
| Presence penalty | Enter a number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics. |
| Frequency penalty | Enter a number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood of repeating the same line verbatim. |
| Best of | Enter a value that controls how many results are generated before being sent. The number of completions cannot be less than the value input here. |
| Logit bias | Enter JSON containing the tokens and the change in logit for each of those specific tokens. For example, you can pass {"50256": -100} to prevent the model from generating the <|endoftext|> token. Refer to the OpenAI documentation for more information. |
| User | Enter a unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. |
Output
| Output field | Description |
|---|---|
| Created | The datetime stamp of when the response generated. |
| ID | The unique identifier denoting the specific request and response that was sent. |
| Model | The model used to generate the text completion. |
| Text | The response of the model for the specified input. |
| Finish reason | The reason the model stopped generating more text. This is often due to stop words or length. |
| Logprobs | An object containing the tokens and their corresponding probabilities. For example, if log probabilities are set to five, you receive a list of the five most likely tokens. The response contains the logprob of the sampled token. There may be up to logprobs+1 elements in the response. |
| Response | Contains the response which OpenAI probabilistically considers to be the ideal selection. |
| Prompt tokens | The number of tokens used by the prompt. |
| Completions tokens | The number of tokens used for the completions of text. |
| Total tokens | The total number of tokens used by the prompt and response. |
Last updated: