# テキストプロンプトの完了アクション
このアクションは、OpenAIの言語モデルを使用して、指定されたプロンプトの補完を生成します。プロンプトとパラメータを提供するだけで、アクションは1つまたは複数の予測された補完を返します。このアクションを使用して、テキストの自動補完、質問への回答、新しいコンテンツの生成を行います。
 テキストプロンプトの完了アクション
テキストプロンプトの完了アクション
# 入力
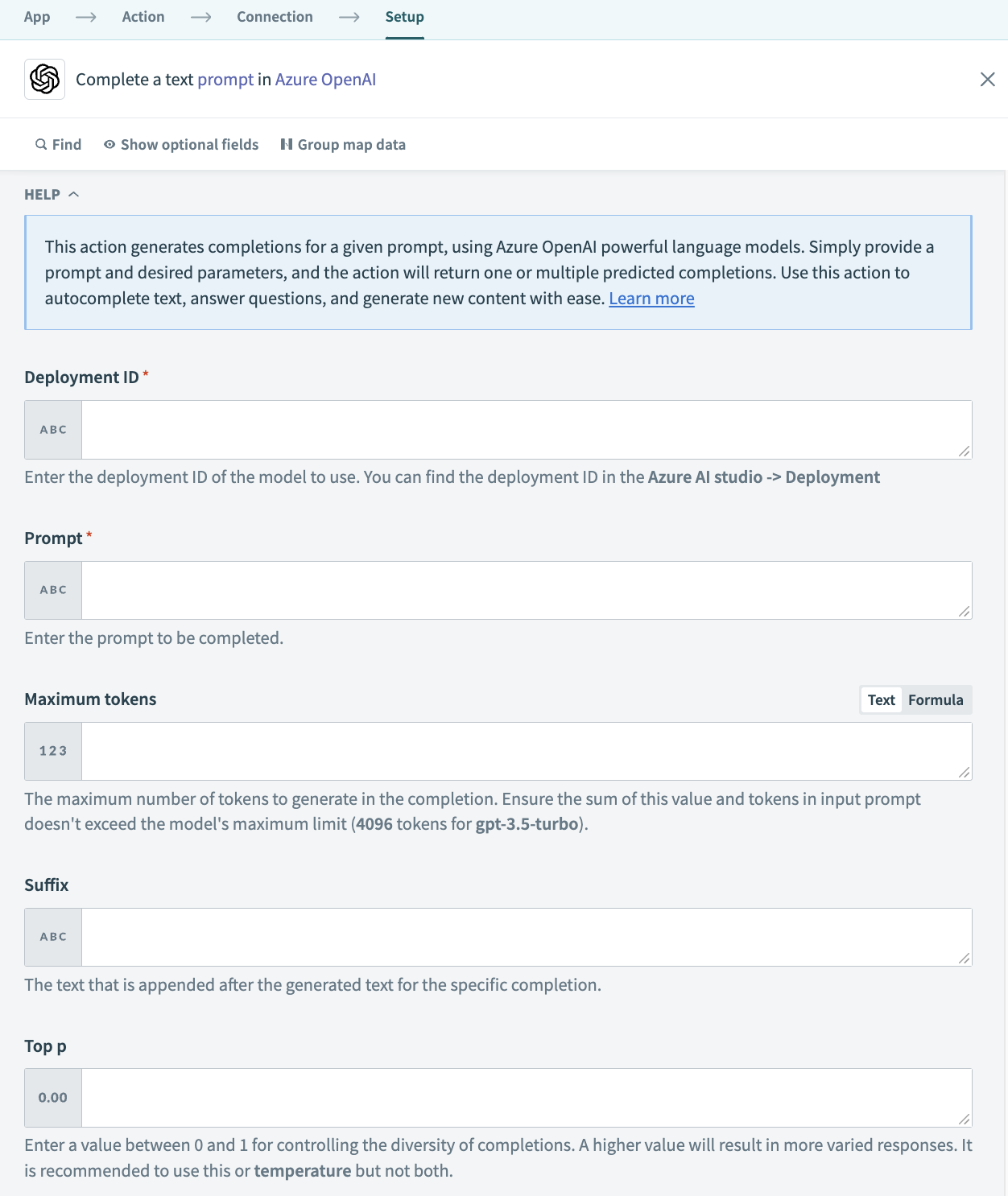
| フィールド | 説明 |
|---|---|
| Deployment ID | 使用するモデルのデプロイメントIDを入力します。デプロイメントIDは Azure AI Studio > Deployment で確認できます。 |
| Prompt | 補完を生成するためのプロンプトです。プロンプトが指定されていない場合、モデルは新しいドキュメントの最初からのようにコンテンツを生成します。複数の文字列(またはトークン)に対して応答を作成する場合は、関連情報をデータピルとして入力します。形式の詳細については、OpenAI's documentation (opens new window) を参照してください。 |
| Maximum Tokens | 補完で生成するトークンの最大数です。プロンプトのトークン数とここでの値の合計がモデルのコンテキスト長を超えることはできません。ほとんどのモデルはコンテキスト長が2048トークンですが、GPT 3.5-turboのような最新のモデルは4096をサポートしています。 |
| Suffix | 挿入されたテキストの補完後に続くサフィックスです。 |
| Top p | 補完の多様性を制御するために0から1の値を入力します。高い値はより多様な応答をもたらします。これかtemperatureのいずれかを使用することをお勧めしますが、両方は使用しないでください。詳細はこちら (opens new window)を参照してください。 |
| Temperature | 補完のランダム性を制御するために0から2の値を入力します。高い値は出力をよりランダムにし、低い値はより焦点を絞り決定的にします。これかtop pのいずれかを使用することをお勧めしますが、両方は使用しないでください。詳細はこちら (opens new window) |
| Number of completions | 各プロンプトに対して生成する補完の数です。 |
| Log probabilities | 次のn(この値によって決定される)セットの可能性の高いトークンと選択されたトークンの対数確率を取得するための数値を入力します。詳細はこちら (opens new window)を参照してください。 |
| Stop phrase | 生成を終了するための特定の停止フレーズです。例えば、停止フレーズをピリオド(.)に設定すると、モデルはピリオドに達するまでテキストを生成し、その後停止します。生成されるテキストの量を制御するためにこれを使用します。 |
| Presence penalty | -2.0から2.0の間の数値です。正の値は、これまでのテキストに存在するかどうかに基づいて新しいトークンをペナルティし、モデルが新しいトピックについて話す可能性を高めます。 |
| Frequency penalty | -2.0から2.0の間の数値です。正の値は、これまでのテキストに既存する頻度に基づいて新しいトークンをペナルティし、モデルが同じ行をそのまま繰り返す可能性を減少させます。 |
| Best of | 実際に生成される結果の数を制御します。補完の数はここに入力した値より少なくてはなりません。 |
| Logit bias | 特定のトークンごとのトークンとロジットの変化を含むJSONを入力します。例えば、{"50256": -100} を渡すことで、モデルが <|endoftext|> トークンを生成するのを防ぐことができます。詳細はこちら (opens new window)を参照してください。 |
| User | OpenAIが不正使用を監視および検出するのに役立つ、エンドユーザーを表す一意の識別子です。 |
# 出力
Last updated: 2025/1/28 7:29:31