Google BigQuery - New row trigger
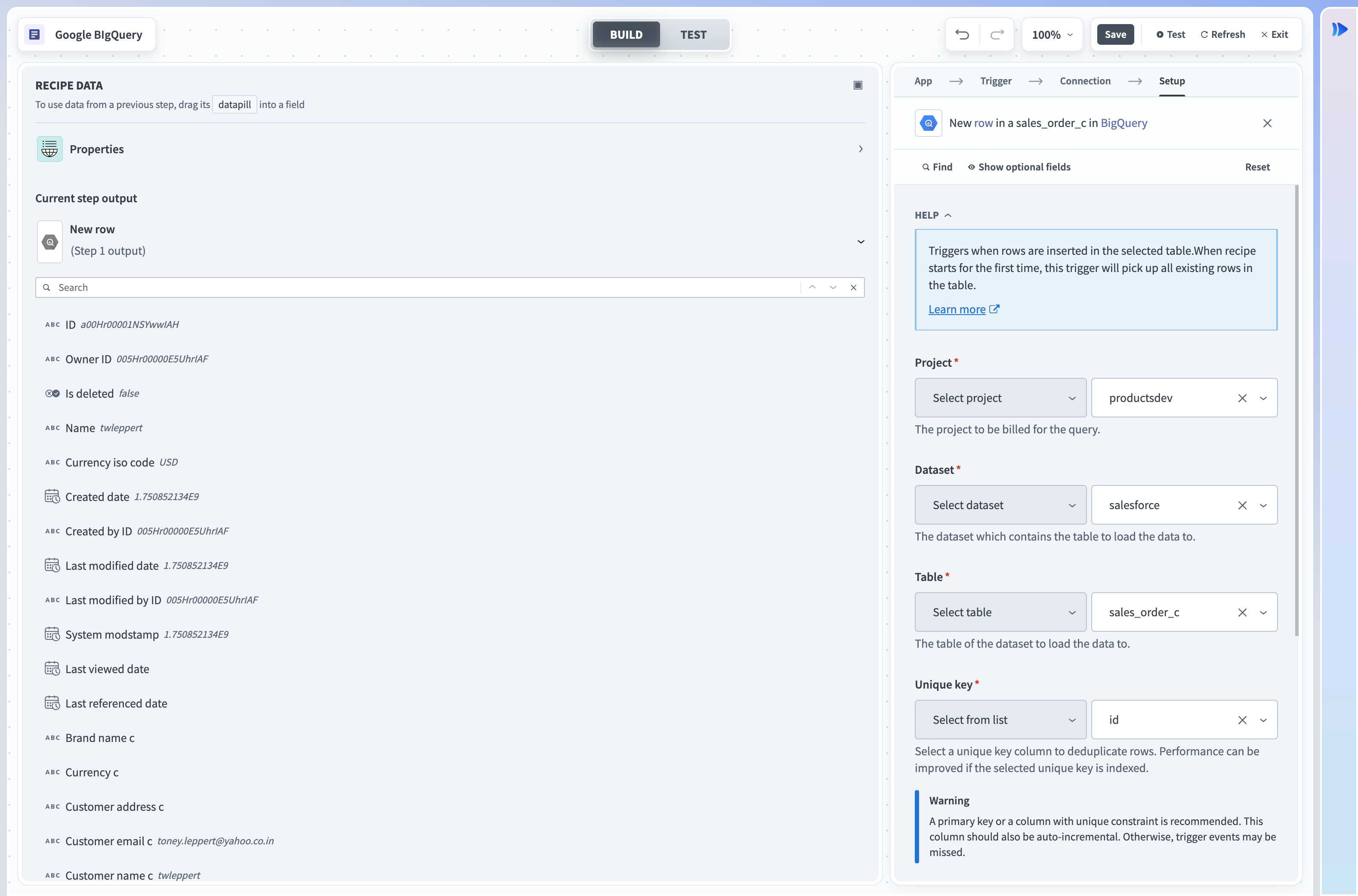
New row trigger
The New row trigger picks up rows that are inserted in the selected table. Each row is processed as a separate job. It checks for new rows once every poll interval.
 New row trigger
New row trigger
Input
| Input field | Description |
|---|---|
| Project | Select the project to bill for the query. |
| Dataset | Select the dataset to pull tables from. |
| Table | Select the table inside the dataset. |
| Table Fields | Only required if table ID is a datapill. Select table fields to declare the columns of the table. This should be the same across all possible values of the datapill. |
| Unique key | Select values from this column to deduplicate rows in the selected table, making sure that the same row is not processed twice in the same recipe. Do not repeat the values in the selected column in your table. This column must be of type integer. |
| Output columns | After selecting your table, you can also select which columns you want returned. Selecting only what you need for your recipe increases job throughput and overall efficiency of the recipe. |
| WHERE condition | Refer to the WHERE condition guide for more information. |
| Location | Select the geographical location of where the job should be run. This field isn't required in most cases. |
| Use Standard SQL | Specify whether to use Standard SQL or legacy SQL. |
Output
| Output field | Description |
|---|---|
| Columns | Workato introspects the table's schema and returns each column's value as a datapill. |
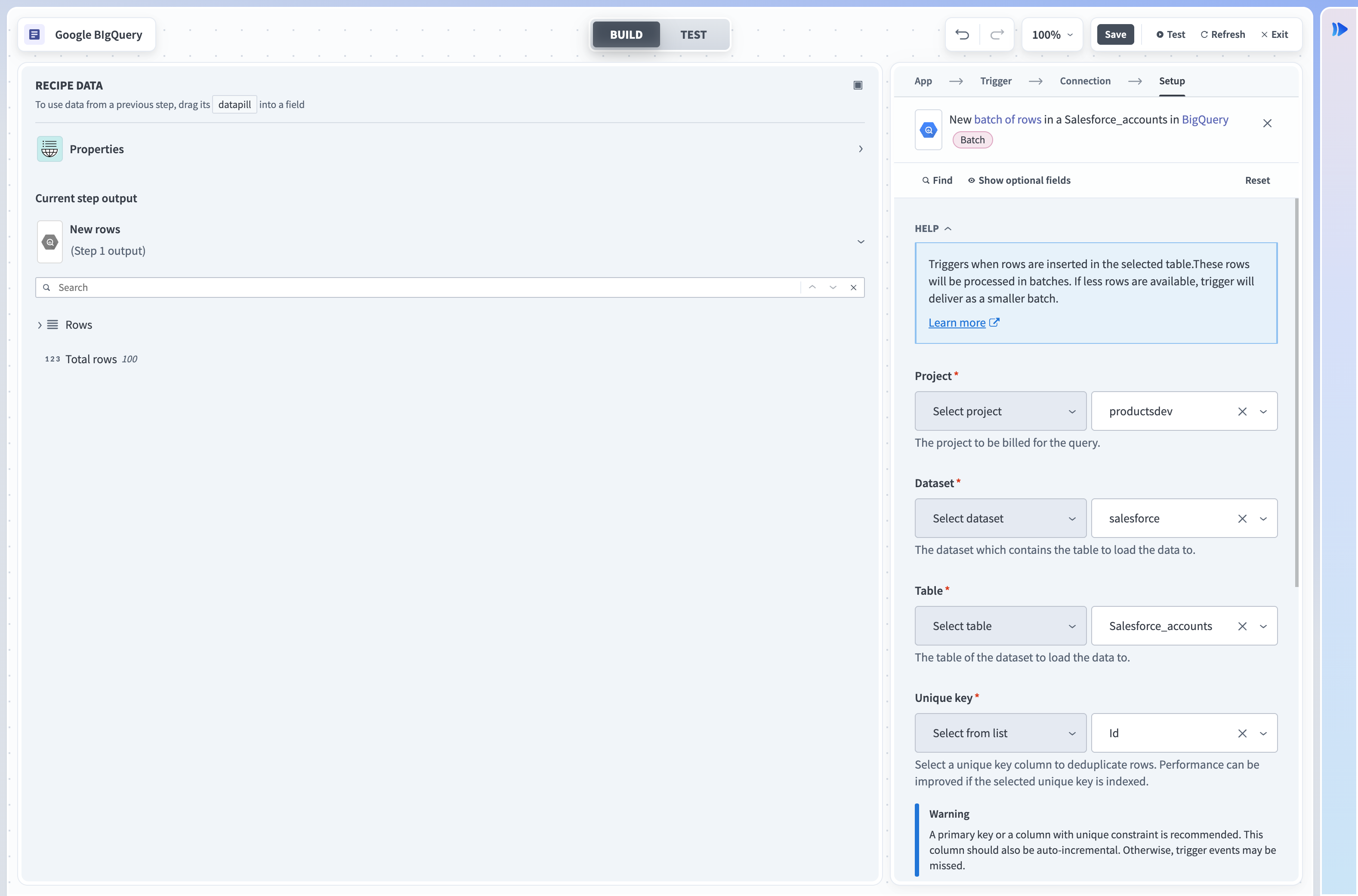
New rows batch trigger
This trigger picks up rows that are inserted in the selected table or view. These rows are processed as a batch of rows for each job. This batch size can be configured in the trigger input. It checks for new rows once every poll interval.
 New batch of rows trigger
New batch of rows trigger
Input
| Input field | Description |
|---|---|
| Project | Select the project to bill for the query. |
| Dataset | Select the dataset to pull possible tables from. |
| Table | The table inside the dataset. |
| Table Fields | Only required if table ID is a datapill. Select table fields to declare the columns of the table. This should be the same across all possible values of the datapill. |
| Unique key | Select values from this column to deduplicate rows in the selected table, making sure that the same row is not processed twice in the same recipe. Do not repeat the values in the selected column in your table. This column must be of type integer. |
| Output columns | Select which columns you want returned. Selecting only what you need for your recipe increases job throughput and overall efficiency of the recipe. |
| Batch size | Select the batch size of the rows to be returned in each job. This can be anywhere from 1 to 50,000 with 50,000 being the default. Larger batch sizes will increase data throughput. If more new rows are found than the batch size, multiple jobs will be created until all new rows are processed. |
| WHERE condition | Refer to the WHERE condition guide for more information. |
| Location | Select the geographical location of where the job should run. This field isn't required in most cases. |
| Use Standard SQL | Specify whether to use Standard SQL or legacy SQL. |
Output
| Output field | Description |
|---|---|
| Rows | An array of the rows. Each datapill in the row corresponds to a single column. |
| Total rows | Total rows returned from this poll. |
Last updated: