Monitor and manage data pipelines
Data pipelines provide the following options to monitor sync activity, track performance, and manage configurations:
Monitor pipeline status: View real-time sync activity and historical trends.
View synced objects and statuses: Check the current sync status of each object and trigger re-syncs as needed.
Monitor object runs: Track sync progress, review errors, and analyze performance metrics.
Manage connections: Verify existing connections, switch sources or destinations, and update credentials.
Pipeline statuses
After you start the pipeline, it syncs selected objects in parallel and continuously updates the destination. The first run loads historical data into the destination.
The pipeline status sidebar provides real-time updates on sync progress and pipeline activity. It displays different details based on the pipeline's status:
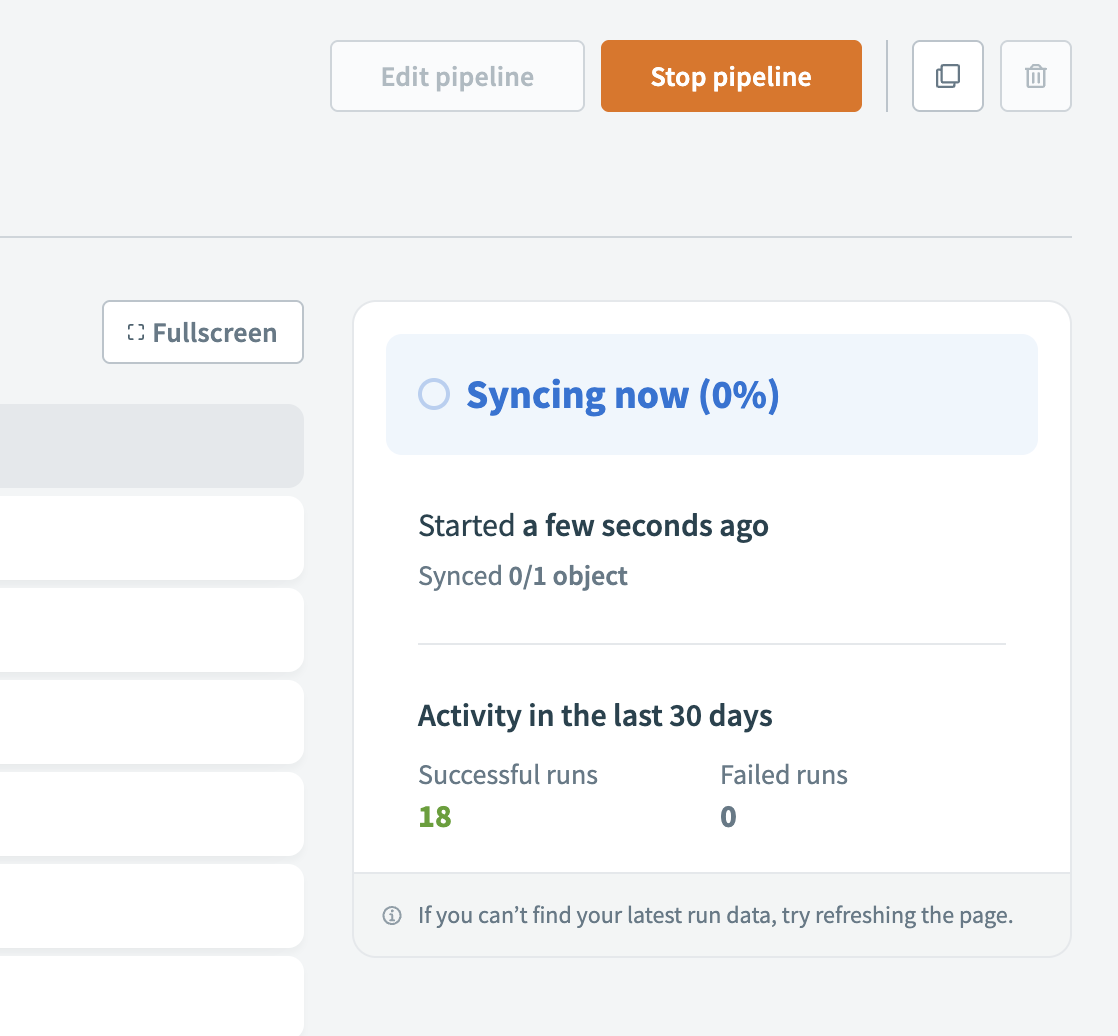 Data pipeline activity status during sync
Data pipeline activity status during sync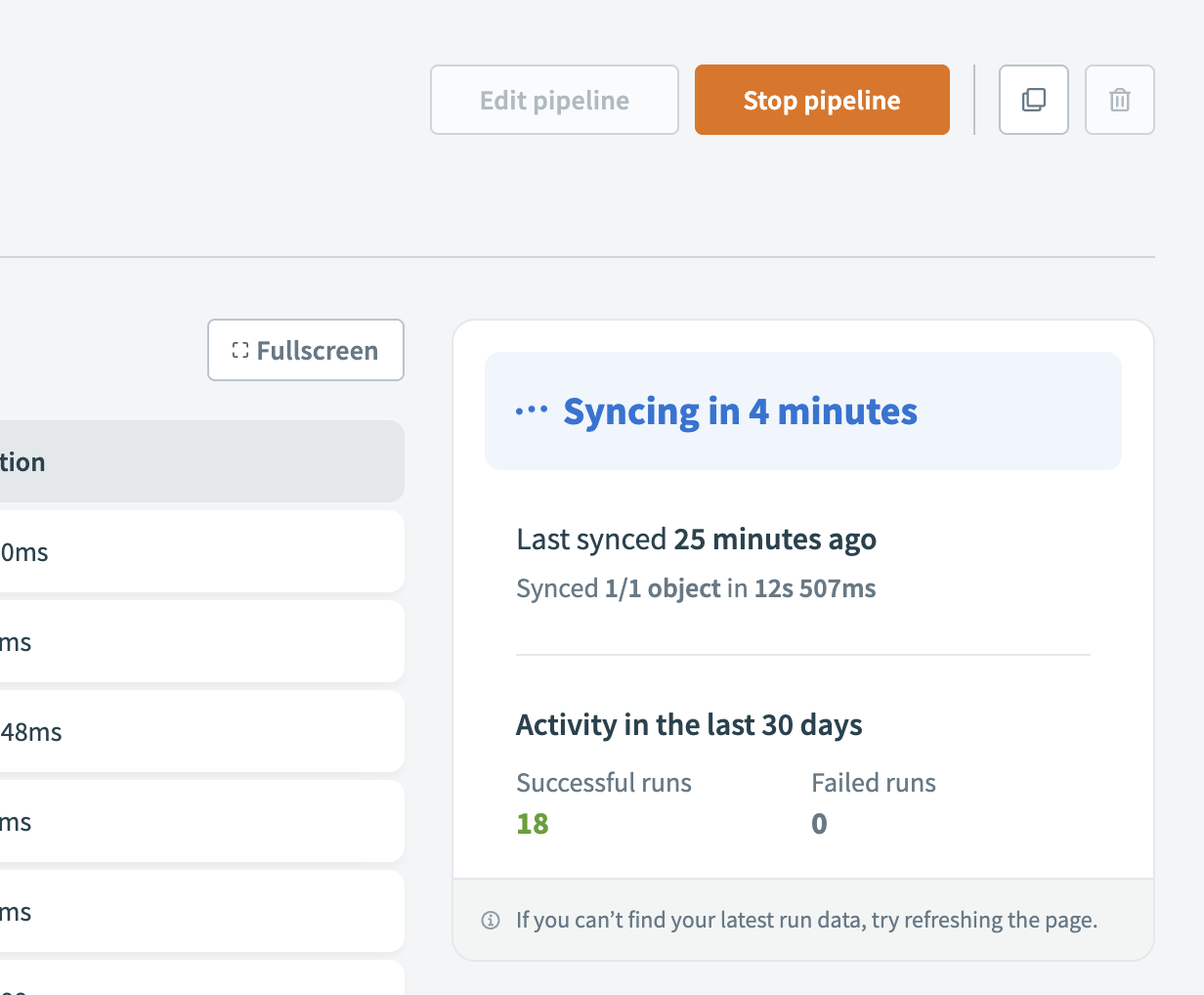 Data pipeline activity status during completed sync
Data pipeline activity status during completed sync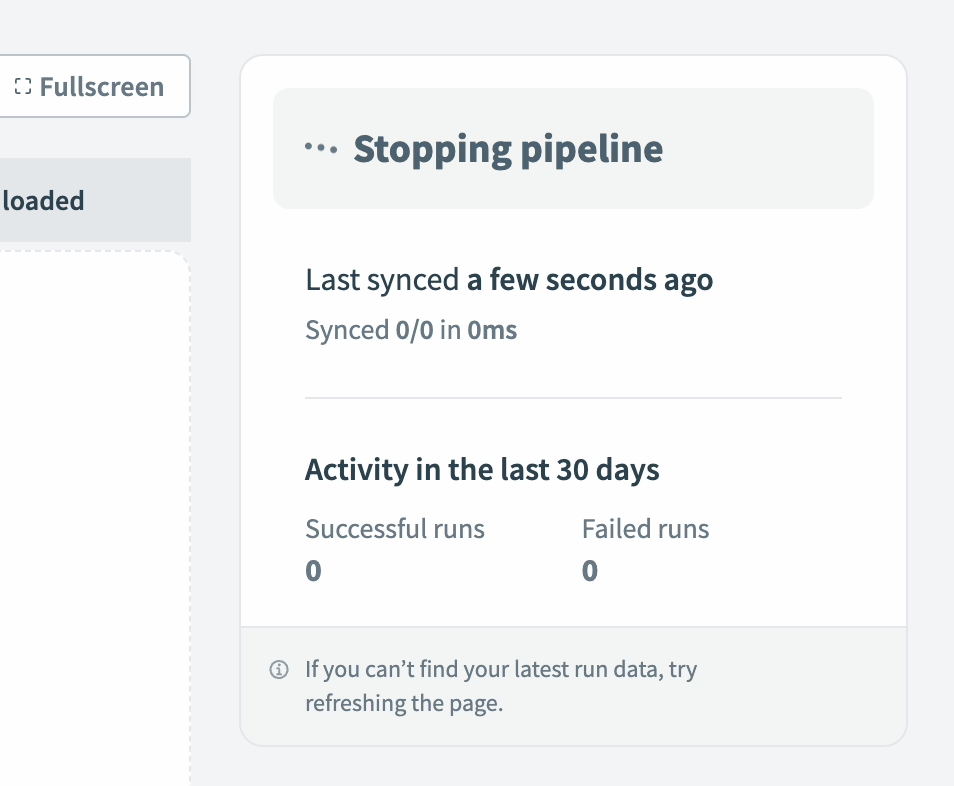 Stop pipeline
Stop pipeline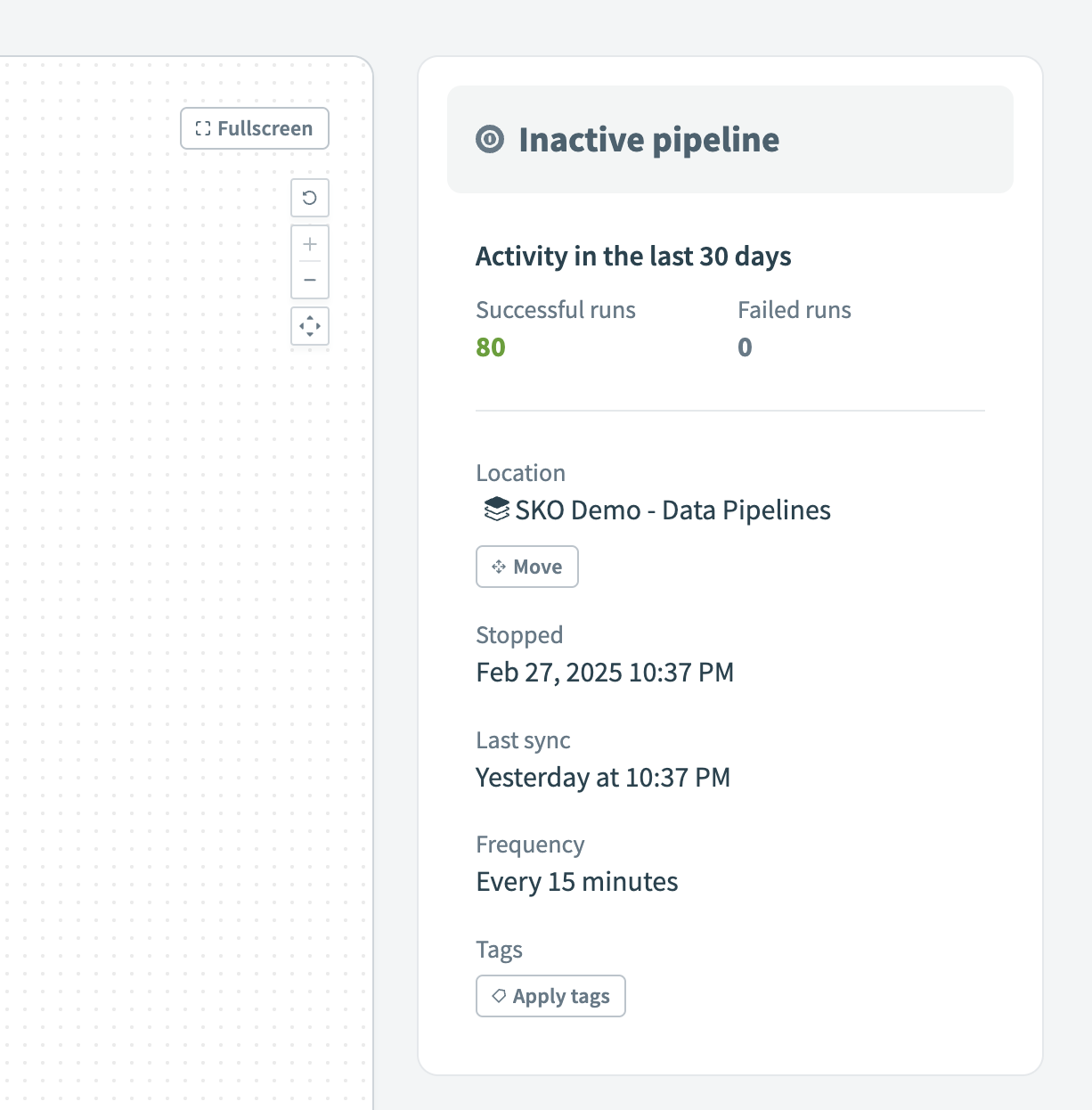 Inactive pipeline
Inactive pipelineMonitor orchestration activity
The data orchestration dashboard allows you to monitor pipeline run status, sync duration, and data volumes across all pipelines in your workspace. The dashboard displays 30 days of activity, including trends in run outcomes, row counts, and duration averages. You can filter by pipeline status, explore daily run timelines, and open specific syncs to investigate issues.
Go to Platform > Data Orchestration in Workato to open the dashboard.
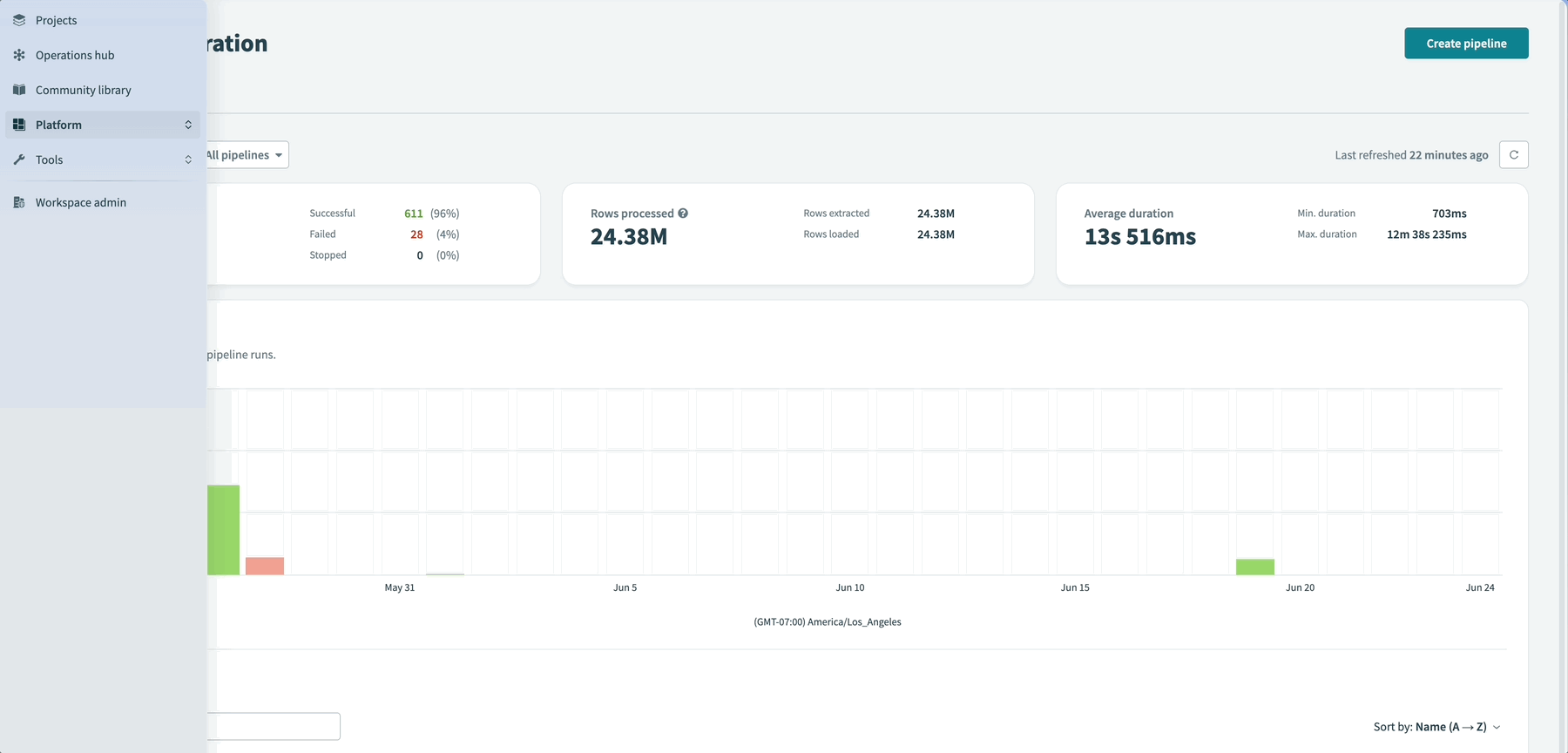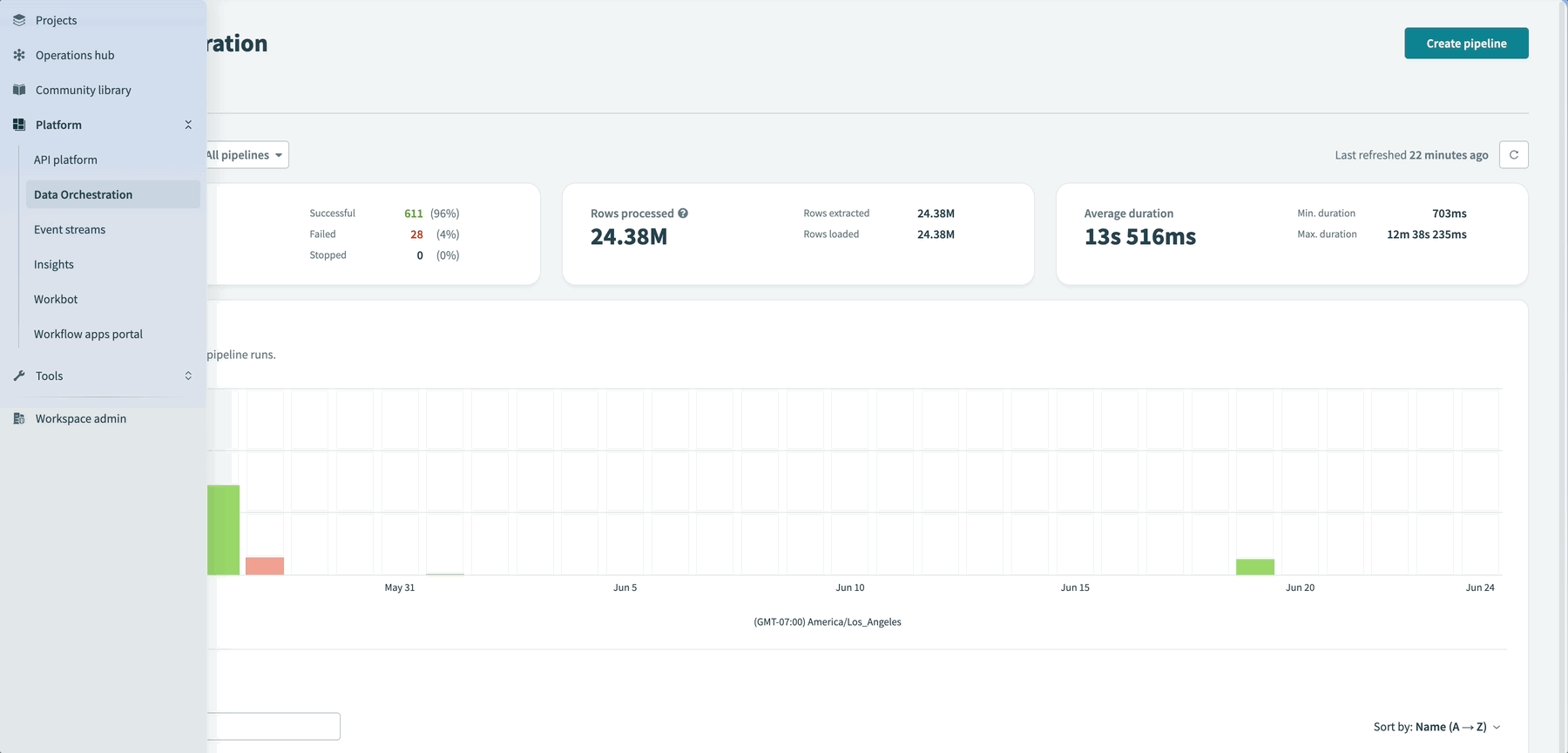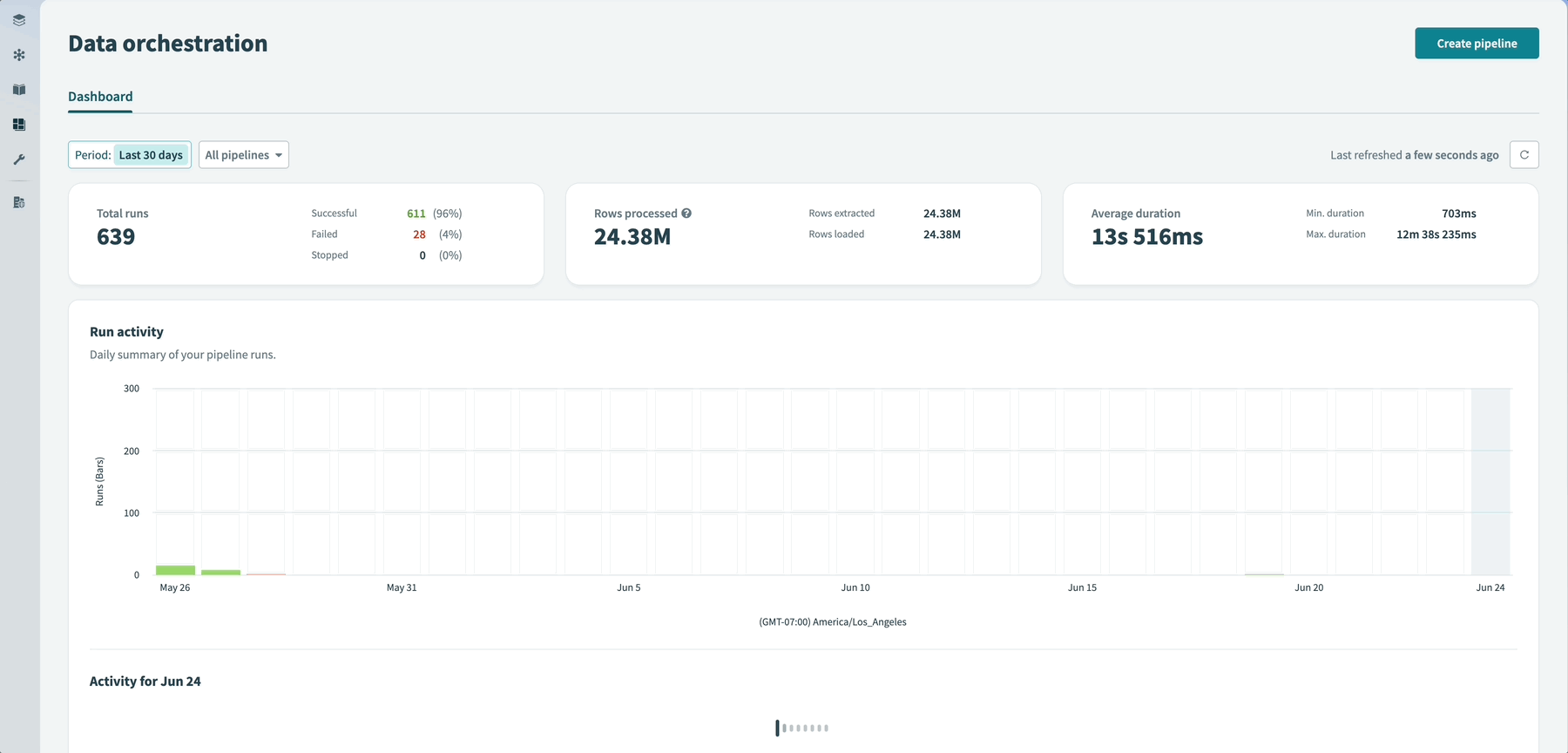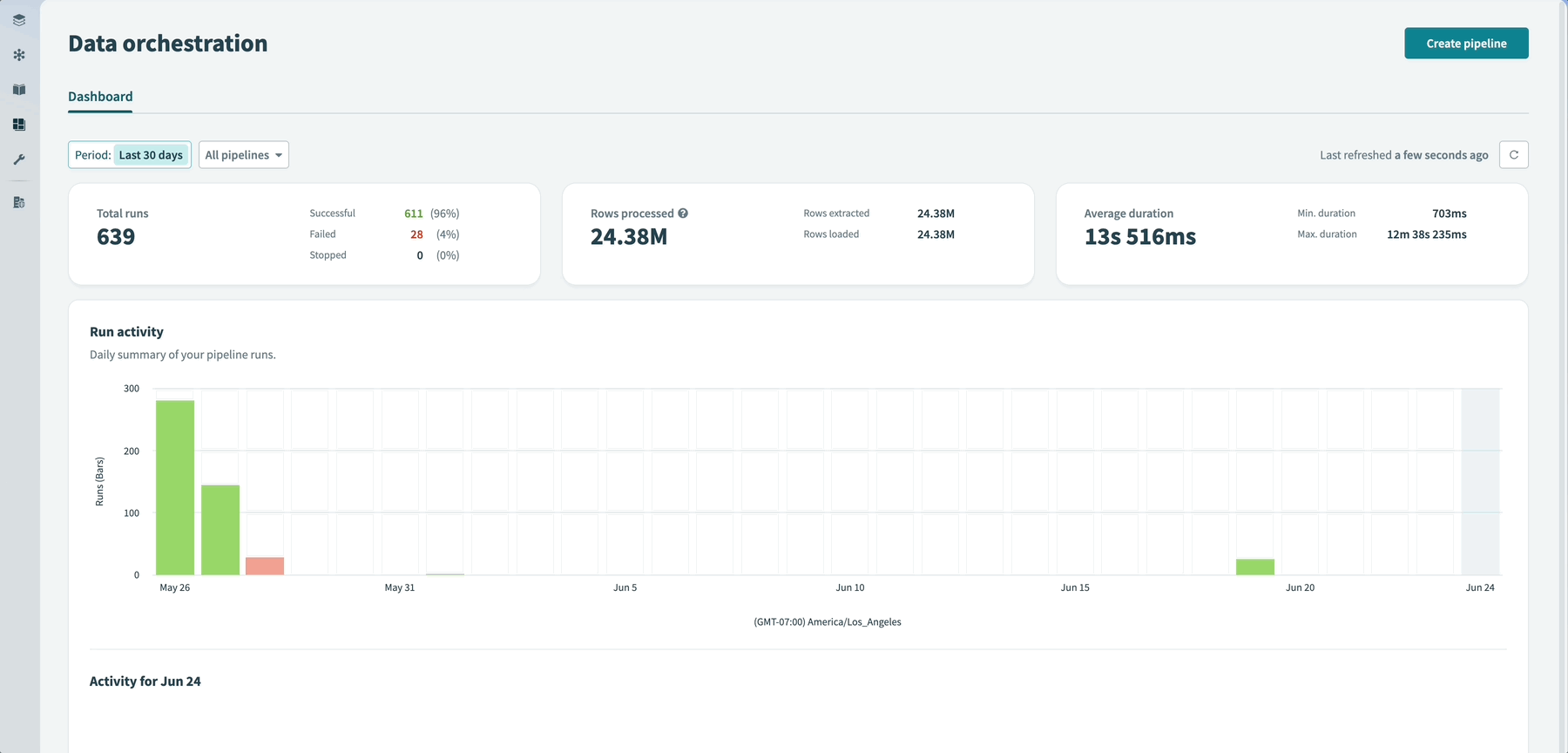 Data orchestration dashboard
Data orchestration dashboard
Refer to the Monitor orchestration activity section for more information.
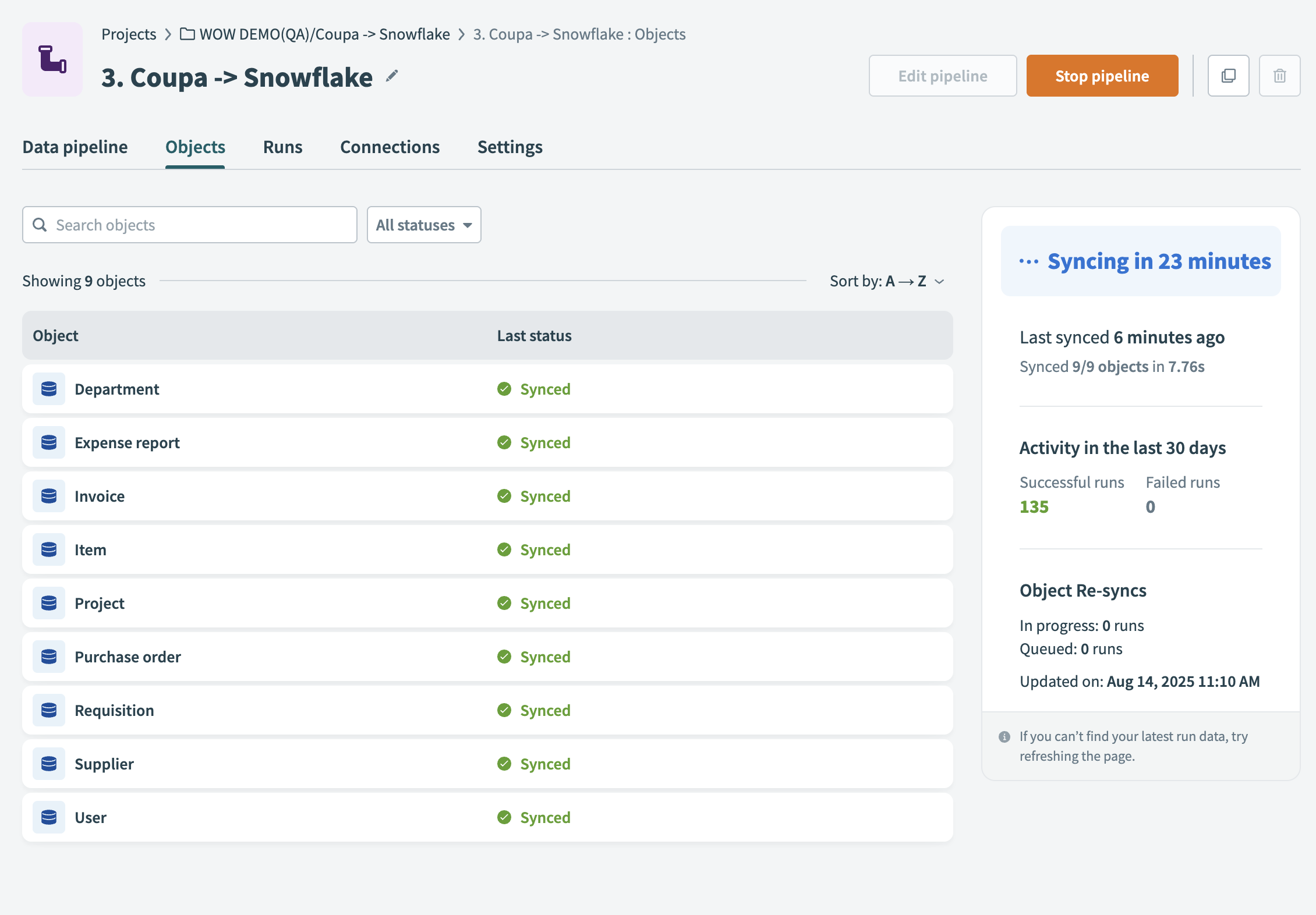
View synced objects and statuses
The Objects tab displays all objects selected in the pipeline and their current sync statuses. Use this tab to monitor sync status and re-sync specific objects when needed.
 Objects tab
Objects tab
Each row displays the following details:
Object name
The name of the source object.
Last status
The result of the most recent sync for this object. Workato marks it as Synced, Failed, Syncing..., Re-syncing..., or Queued.
Re-sync
Hover over the object row or open the object detail panel to access the Re-sync option. This triggers a one-time sync for that object. It extracts and loads the object data immediately, without waiting for the next scheduled sync.
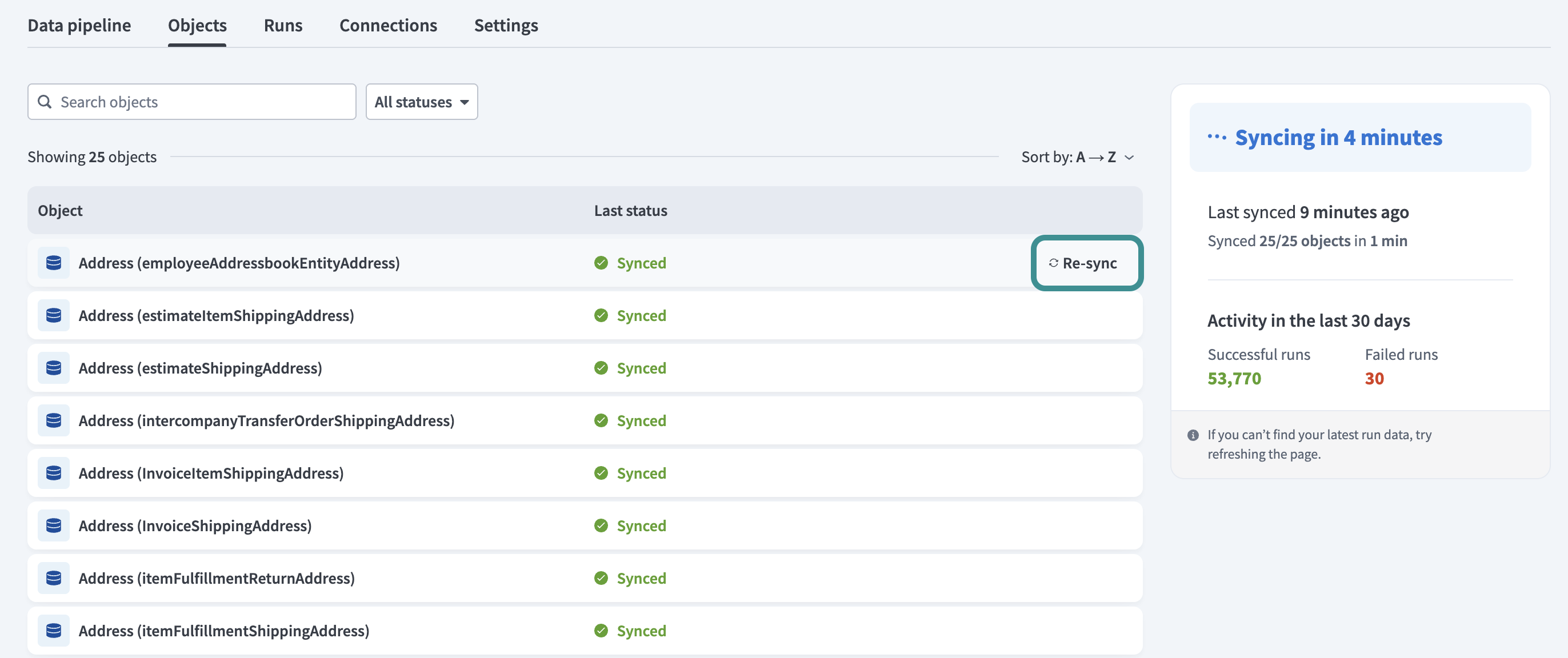 Re-sync object
Re-sync object
The sidebar summarizes the following pipeline activity:
Time until the next sync
Time and result of the last sync
Total successful and failed runs in the last 30 days
Number of object re-syncs in progress or queued
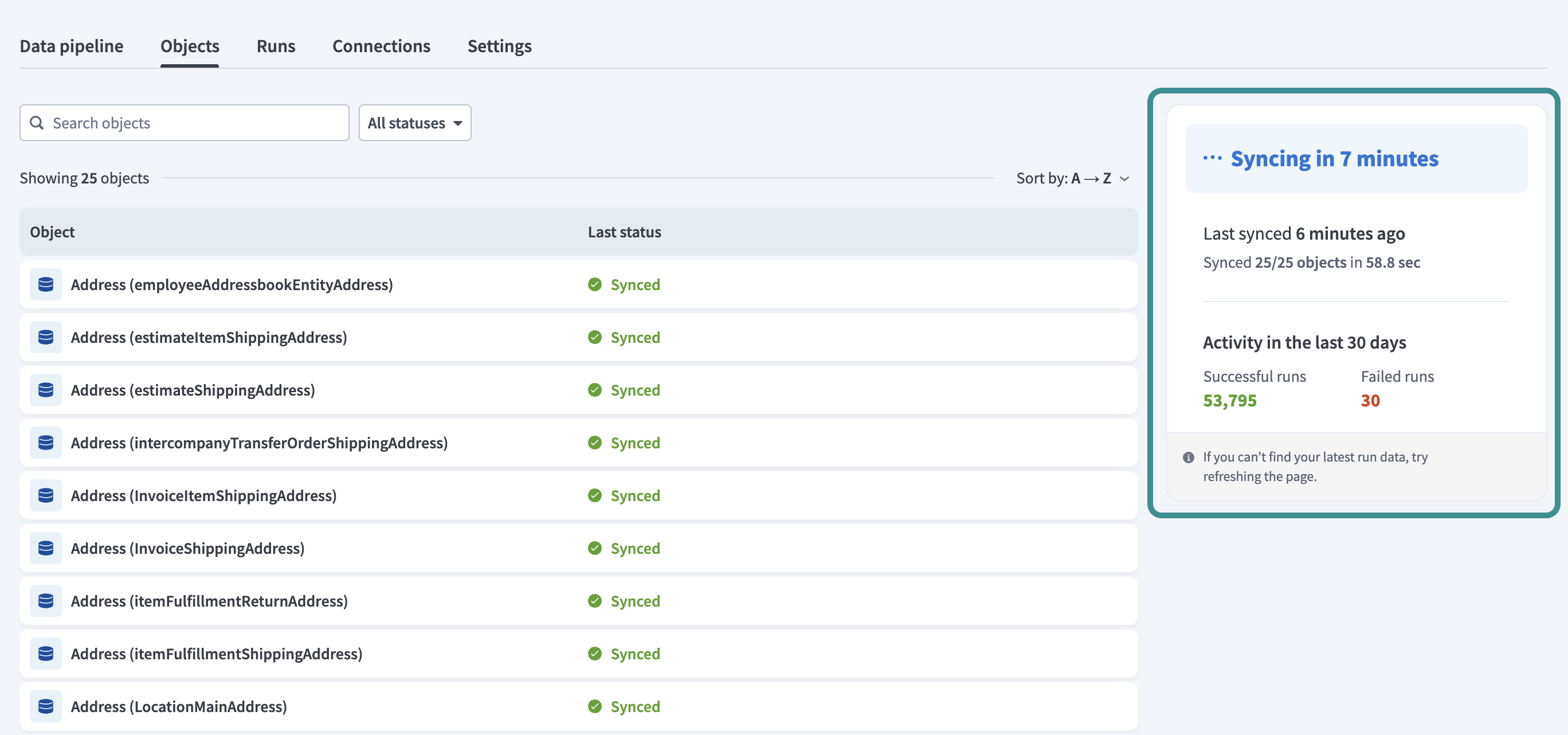 Object sidebar
Object sidebar
Object runs
The Runs tab provides real-time insights into execution progress, errors, and performance. Use this tab to track object run status, review the execution history, analyze pipeline activity, and troubleshoot failures.
Complete the following steps to access and utilize the Runs tab:
Go to the Runs tab to view execution logs, pipeline status, and performance statistics.
 Runs tab
Runs tab
Review the execution history table, which lists all object runs and their statuses.
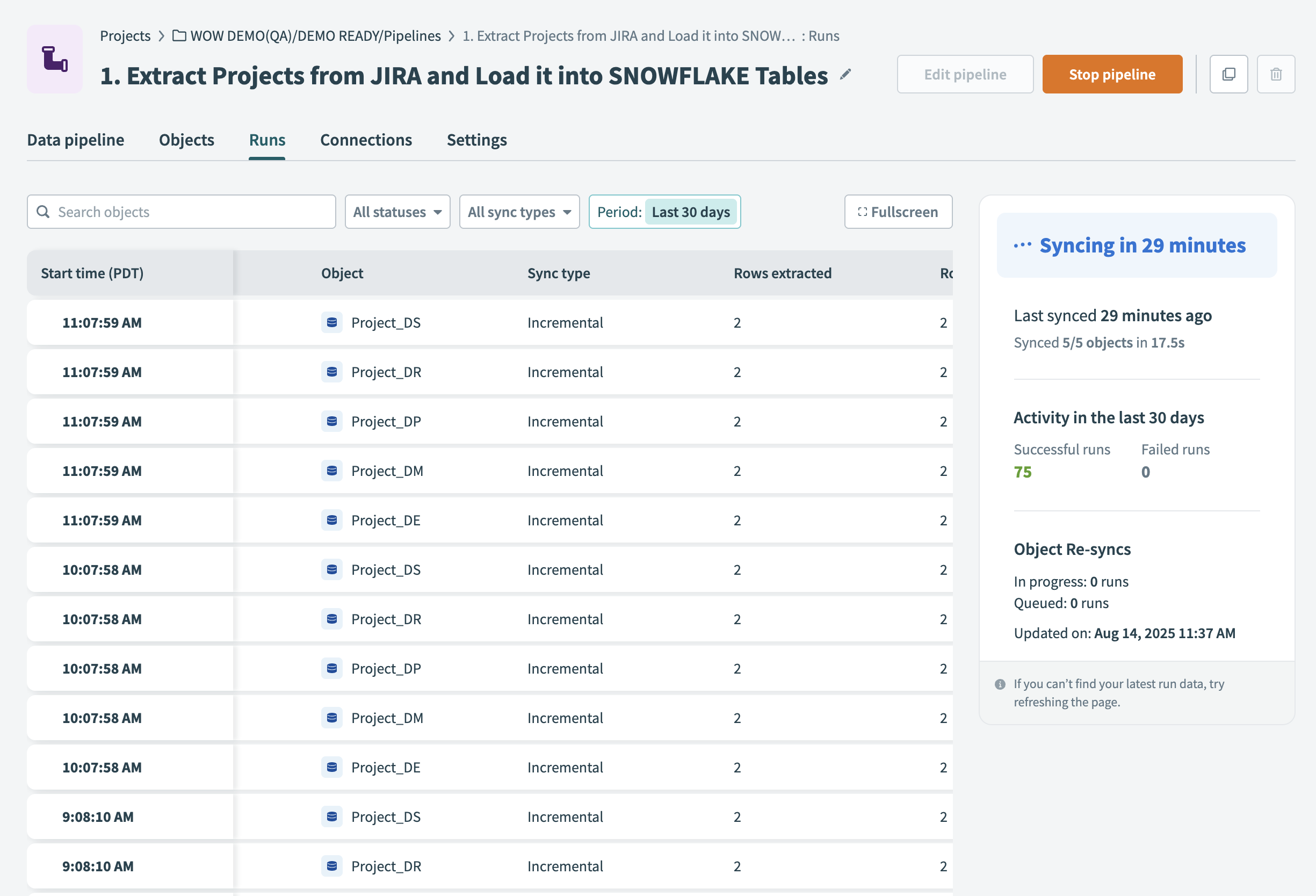 Object syncs page for a running pipeline
Object syncs page for a running pipeline
Each row in the execution history table provides the following details:
Start time
Displays when the run for that object began.
Object
The name of the object extracted from the source application.
Sync type
Indicates whether the run was an incremental sync or full sync. Refer to the Sync types and execution guide to learn more about sync types.
Rows extracted
Lists the number of records retrieved from the source during the run.
Rows loaded
Displays how many records were successfully written to the destination.
Duration
Total time taken to complete the run.
Use the following filters to refine the table and locate specific object runs:
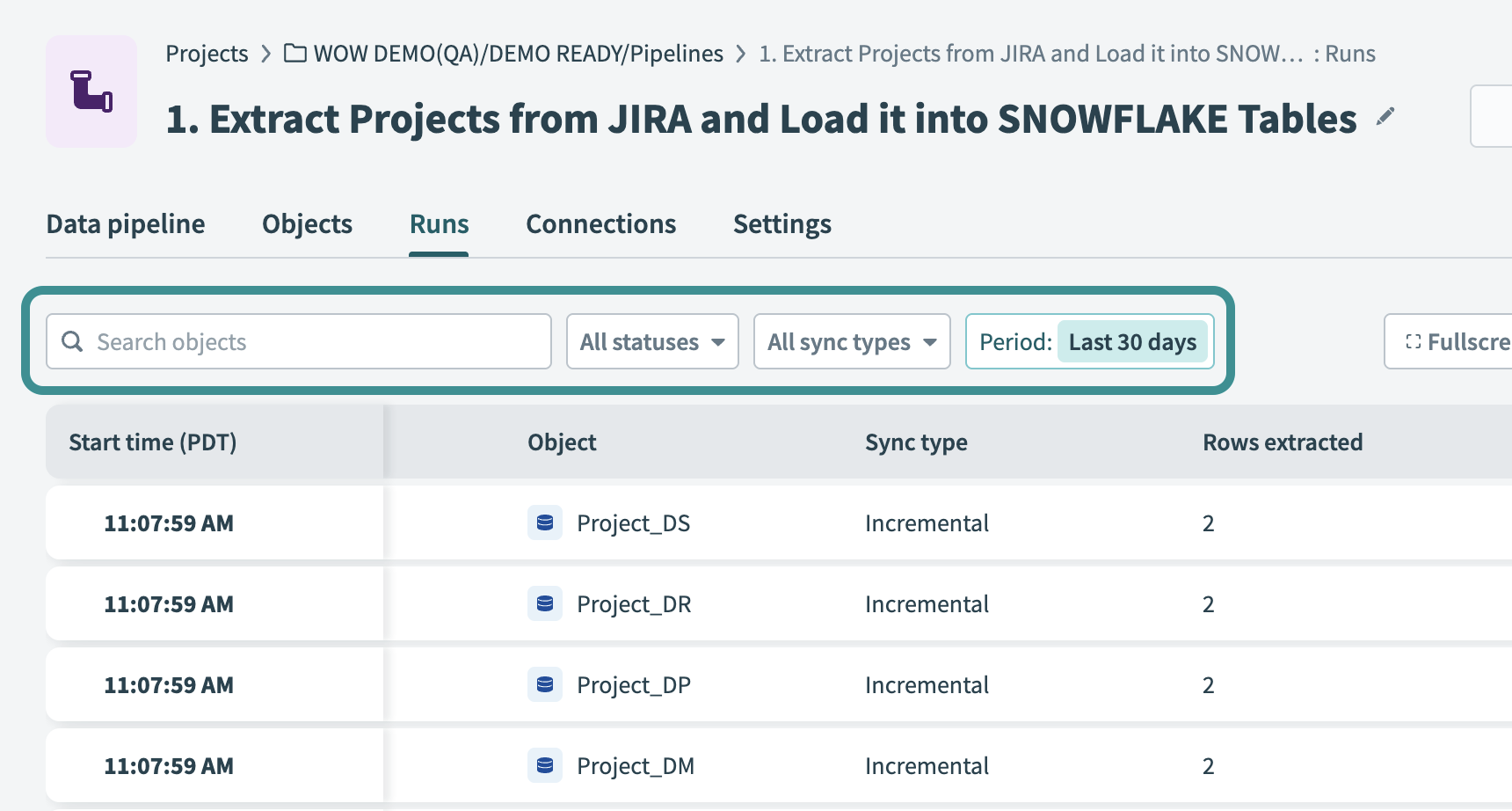 Filter the runs table
Filter the runs table
Search objects
Enter the name of an object to find matching runs.
Status
Filter by execution status, such as Successful, Syncing, Failed, or Canceled.
Sync type
Filter by Incremental or Full syncs.
Period
Define a time period to display syncs from a specific timeframe.
Sync types
The pipeline automatically applies different sync types based on the current state and configuration:
Full sync: Runs once when the pipeline starts. It loads either all historical records from the source or only from a specific date, based on the configuration settings. This is a full sync that occurs during the first pipeline execution.
Incremental sync: Runs at scheduled intervals to track and apply changes from the source.
Re-sync: A one-time manual sync for a specific object. It reloads current data for that object immediately, outside the regular schedule.
Refer to the Sync types and execution guide for more details.
View and manage connections
The Connections tab displays the source and destination connections used in the data pipeline.
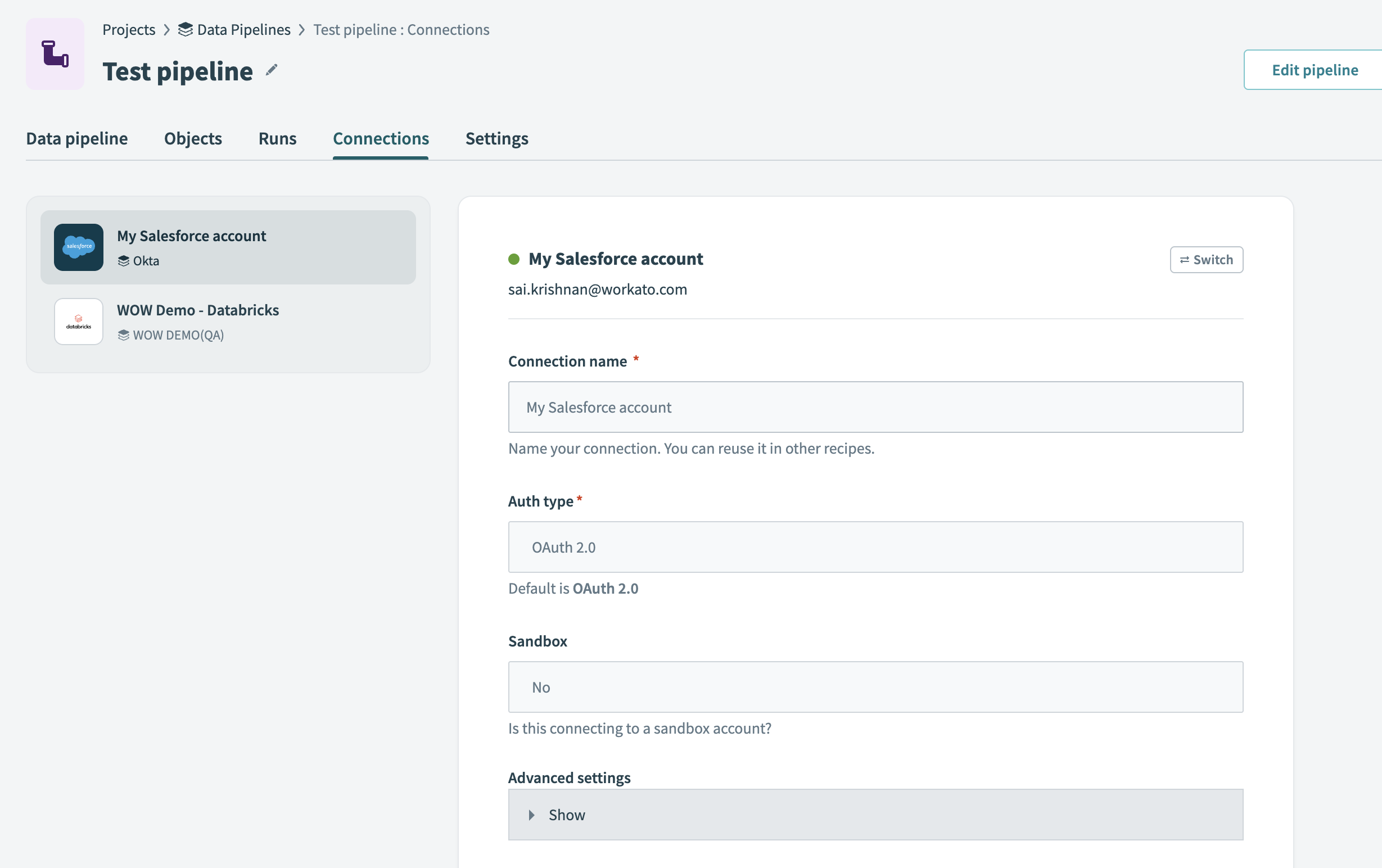 Connections tab
Connections tab
Each connection displays its name, authentication type, and configuration details.
You can switch a connection only when the pipeline isn't running. Stop the pipeline before you change the connection if it's active.
To switch a connection:
Select the source or destination to update.
Click Switch.
Choose a different connection from the list.
The pipeline applies the new connection immediately for all future syncs.
Concurrency
The pipeline processes selected objects in parallel during each scheduled sync. Workato automatically manages concurrency and optimizes it based on system availability.
The pipeline processes up to 100 objects in parallel per batch. Pipelines with more than 100 objects are processed in successive batches. You can't manually configure concurrency settings.
Edit pipeline
Click Edit pipeline to modify sync frequency, source objects, and field settings. Changes apply to future syncs and don't affect previously synced data.
 Edit data pipeline
Edit data pipeline
Pause and resume pipelines
Select Stop pipeline to stop all syncs while the pipeline remains intact. If the pipeline is mid-sync, it stops immediately. Objects that complete extraction and loading count as successful runs. The pipeline cancels any remaining runs and marks them as Canceled. These runs don't sync data to the destination.
The pipeline doesn't extract data while stopped. Logs and historical run data remain available for reference.
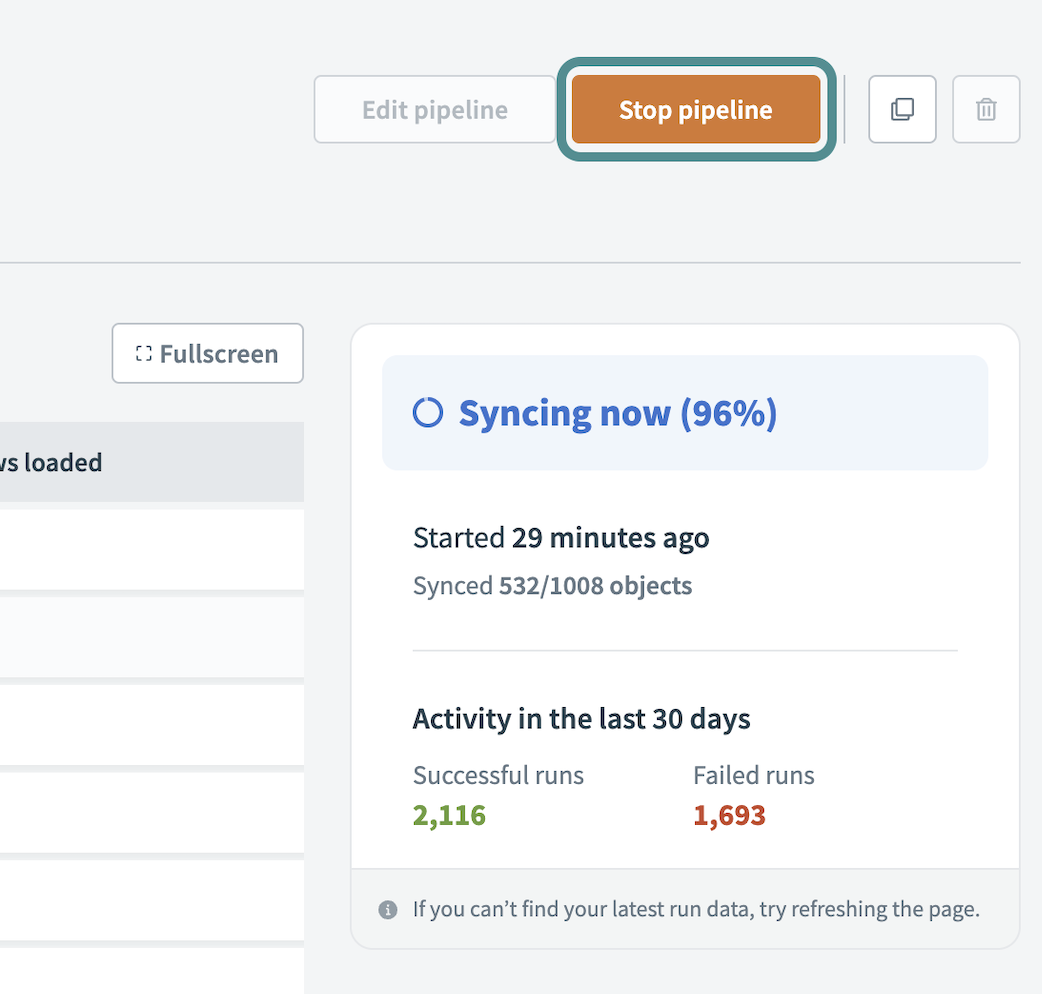 Stop data pipeline
Stop data pipeline
Select Start pipeline to resume syncs. The pipeline immediately resumes with the next incremental sync regardless of the schedule. After this run completes, it follows the configured sync frequency. The system doesn’t retry any syncs missed while the pipeline was paused, but it catches up on the missed data from those canceled runs during the next successful sync. If you update the sync frequency while the pipeline is paused, the pipeline applies the updated configuration when it resumes.
If the pipeline uses Block new fields, schema changes made while it's paused don't apply automatically. These changes take effect after the pipeline resumes.
Deployment considerations
You can export and deploy data pipelines using RLCM manifests or deployment packages.
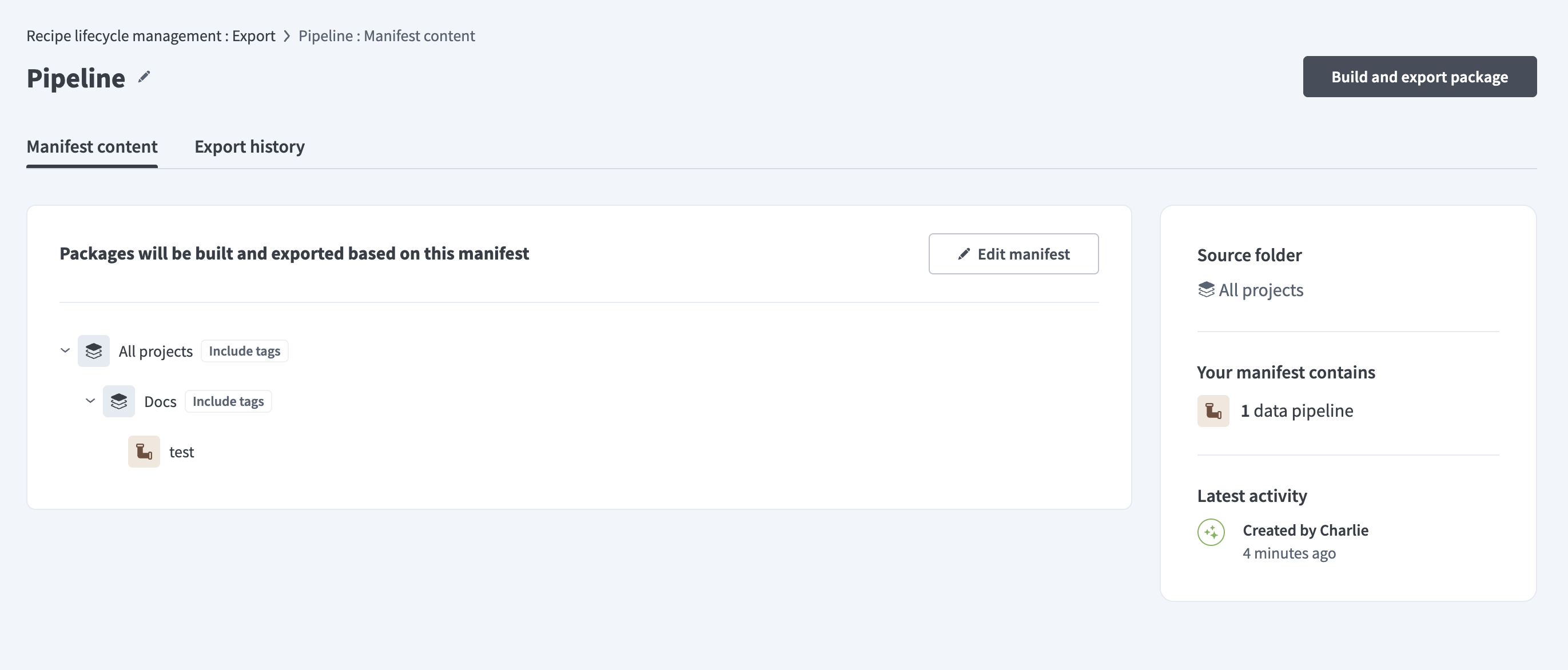 Data pipeline manifest
Data pipeline manifest
Workato blocks deployment if the pipeline doesn't include valid source and destination connections. This ensures the system can load schemas correctly and avoids errors during configuration. You must include all required connections before you can export or deploy a pipeline.
If you plan to use different connections in production, deploy the pipeline with test connections first, then switch to the appropriate production connections in the target environment.
Workato also blocks deployment if the same pipeline is already active in the target environment. You must stop the running pipeline before deploying an updated version to the same environment.
Data pipeline triggers in recipes
You can use the PipelineOps by Workato connector to trigger recipes when a data pipeline sync completes. This allows recipes to run immediately after data loads into the destination.
Use these triggers to run post-load transformations, monitor pipeline activity, and send customized error alerts or status reports.
Refer to the Monitor data pipelines using recipes guide for a step-by-step example.
Troubleshoot failed runs
The Runs tab displays detailed error information for each failed object run. Failed runs appear in the run history with a Failed status.
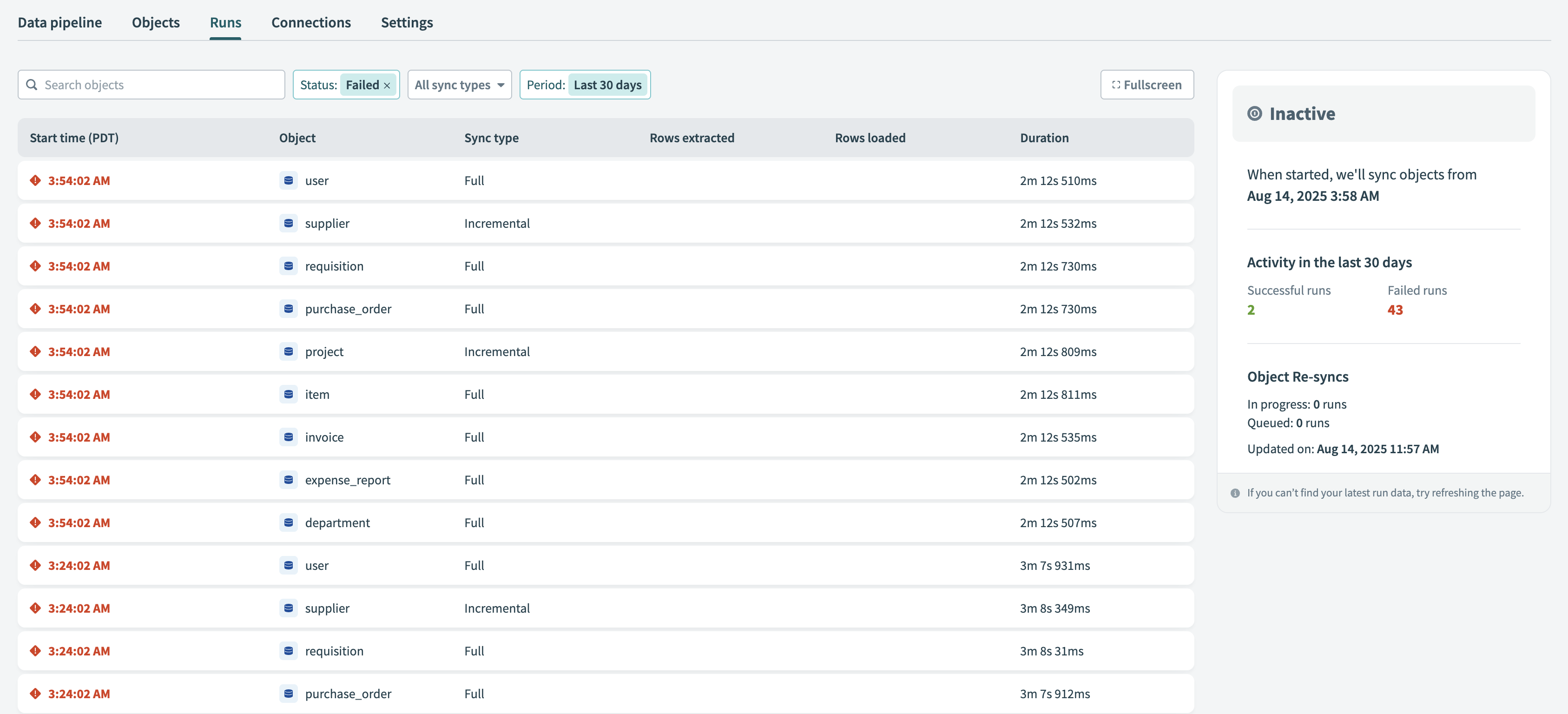 Failed runs
Failed runs
Click a failed run to open its details. The right-hand panel displays the Error type, Error ID, and Run ID. You can also select the source trigger or destination action to view specific error messages for that run.
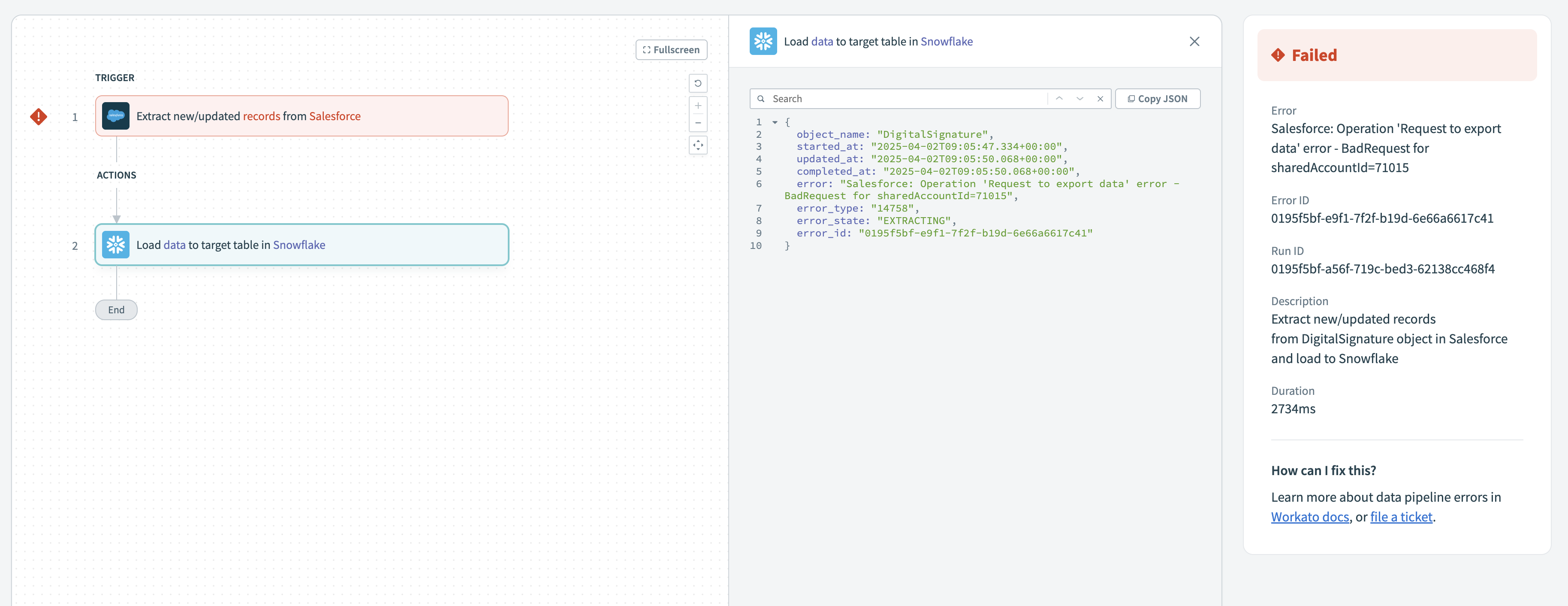 Failed run details
Failed run details
Refer to the Troubleshoot your data pipelines for more information about how to identify and troubleshoot errors.
Review pipeline logs
Workato's logging service captures detailed information for every pipeline sync. Use these logs to trace pipeline activity, confirm successful executions, and troubleshoot errors across syncs and individual object runs.
 Data pipeline logs
Data pipeline logs
Complete the following steps to locate specific logs:
Go to Tools > Logs
Use the following filters to locate specific logs:
Period
Choose a preset like Last 30 days or define a custom date range.
Log type
Select Data pipelines to view logs related to pipeline activity.
Log level
Select INFO to view successful events or ERROR to investigate failures.
Pipeline ID
Filter logs by the unique identifier of a specific pipeline.
Run ID
Filter logs by the unique identifier of a specific run.
Common log types
Workato generates structured log events for each stage of the pipeline sync process. These events help you track sync activity and identify issues at the object level:
PIPELINE_SYNC_START: The pipeline started a new sync across all selected objects.OBJECT_RUN_START: The pipeline started processing an object run.OBJECT_SCHEMA_SYNCHRONISATION_COMPLETED: The pipeline completed schema updates for one object run.OBJECT_EXTRACTION_COMPLETED: The pipeline finished extracting data from the source for one object run.OBJECT_LOADING_COMPLETED: The pipeline finished loading data into the destination for one object run.OBJECT_MERGE_COMPLETED: The pipeline merged incremental changes into the destination for one object run.OBJECT_RUN_COMPLETED: The pipeline completed all operations for one object run.PIPELINE_SYNC_COMPLETED: The pipeline completed a sync across all selected objects.PIPELINE_SYNC_CANCEL: The pipeline stopped before completing the sync.
View log entry details
Click any log row to view its full context. Each log entry includes values such as pipeline_id, pipeline_sync_id, and workato_pipeline_id to identify the pipeline and corresponding sync.
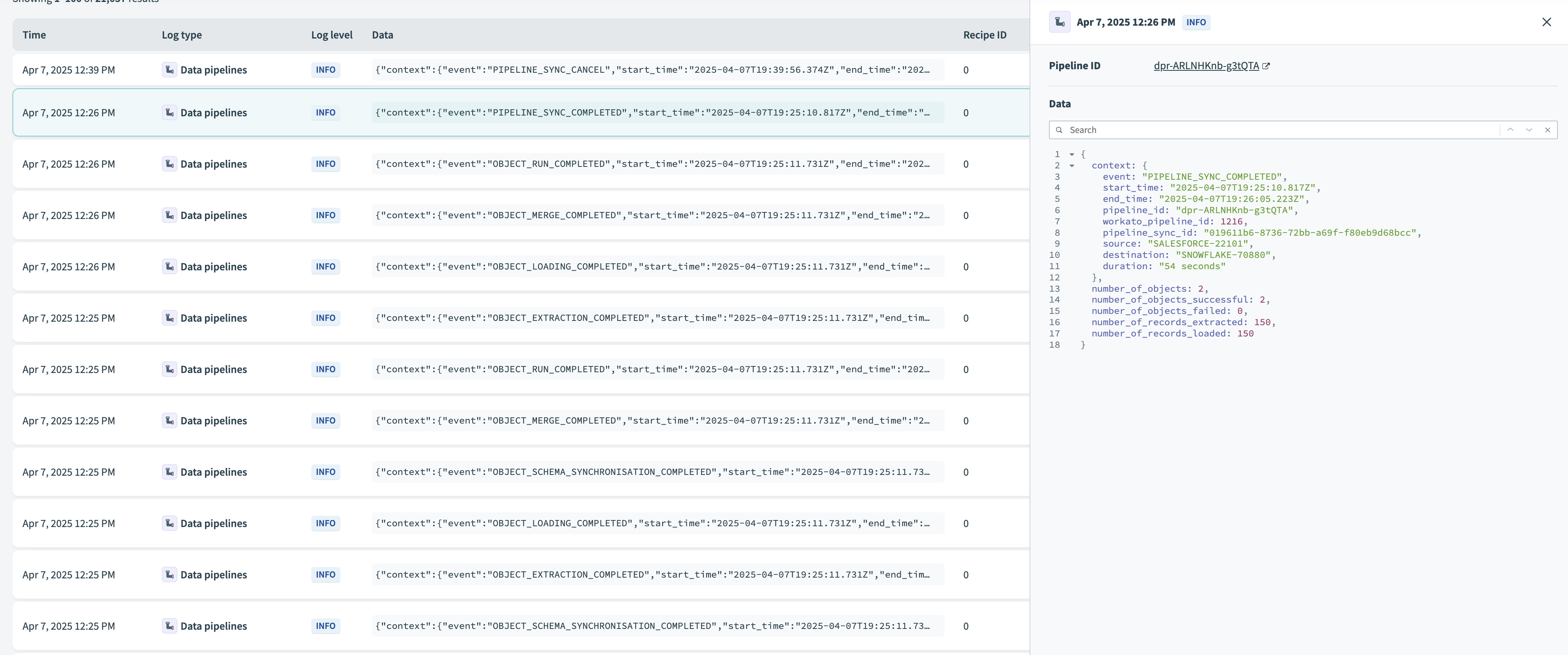 View log details
View log details
Log entries also capture the source and destination systems, object names, record counts, and any error messages for failed object runs.
Example log entry
The following example displays a PIPELINE_SYNC_COMPLETED log entry. It includes the sync durations, pipeline identifiers, systems involved, and object and record metrics:
{
"context": {
"event": "PIPELINE_SYNC_COMPLETED",
"start_time": "2025-04-15T14:00:17.088Z",
"end_time": "2025-04-15T14:03:45.562Z",
"pipeline_id": "dpr-ARQRRwxR-w4xLrt",
"workato_pipeline_id": "1275",
"pipeline_sync_id": "019639c0-1ae3-77fd-8eb9-14b20e4fed38",
"source": "SALESFORCE-70612",
"destination": "SNOWFLAKE-72522",
"duration": "208 seconds"
},
"number_of_objects": 8,
"number_of_objects_successful": 8,
"number_of_objects_failed": 0,
"number_of_records_extracted": 900,
"number_of_records_loaded": 900
}Last updated: