# S3 Data Lake - Query data action
The Query data action runs a SQL query on a Glue Iceberg table and write the results to S3 in JSON format.
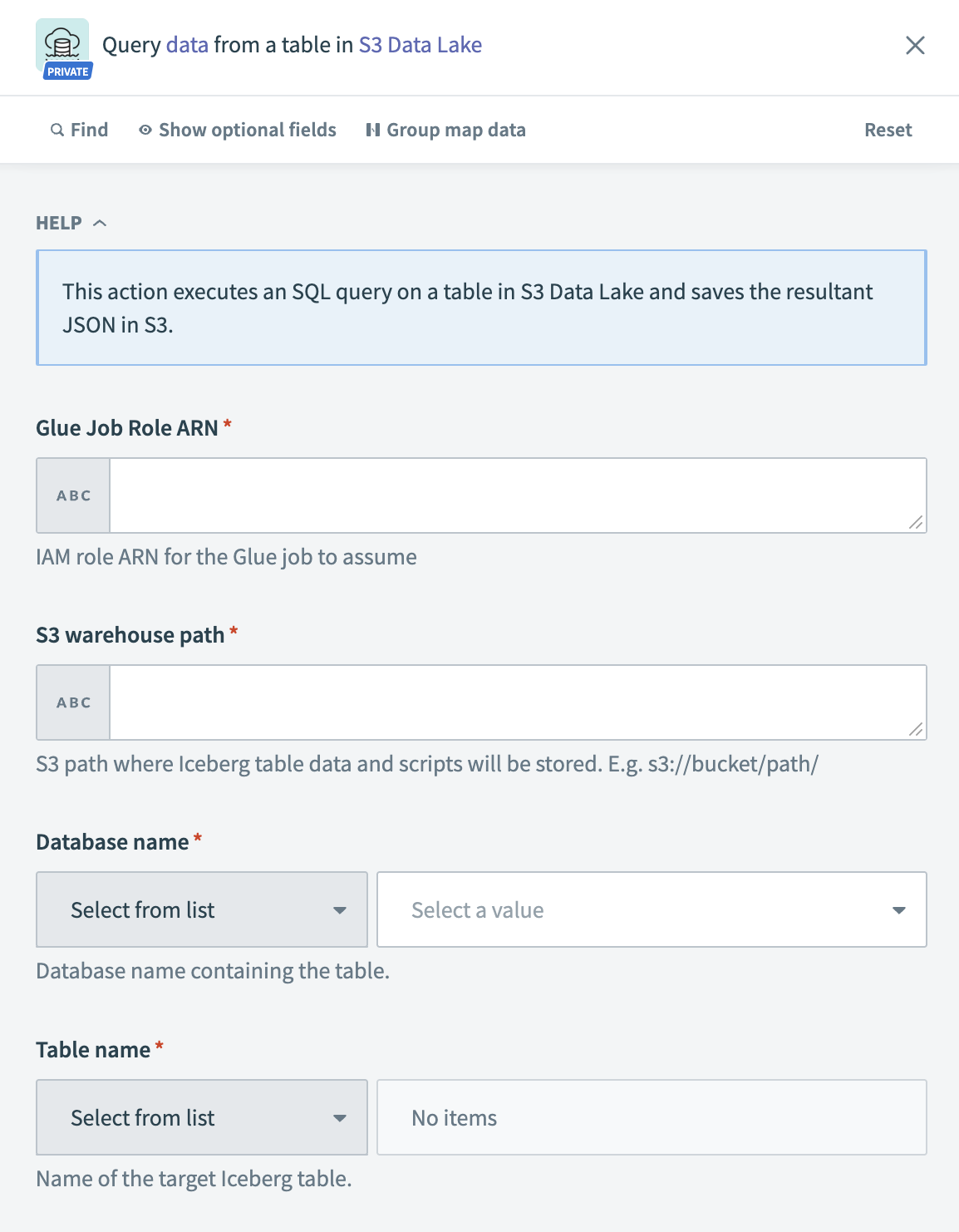 S3 Data Lake – Query data action
S3 Data Lake – Query data action
# Input
| Input field | Description |
|---|---|
| Glue Job Role ARN | Enter the IAM role ARN for the Glue job to assume. |
| S3 warehouse path | Provide the S3 path where you plan to store the Iceberg table data and scripts. For example, s3://bucket/path/. |
| Database name | Select the Glue database containing the Iceberg table. |
| Table name | Select the Iceberg table to query. |
| Columns | Select columns to include in the query. Leave blank to return all columns. |
| SQL WHERE Clause | Enter a WHERE clause to filter records in the query. |
| Limit | Set the maximum number of records to return. |
| Glue version | Select the AWS Glue version to use. Defaults to 4.0 if left blank. |
| Worker type | Choose the AWS Glue worker type. |
| Number of workers | Specify how many workers to allocate. Defaults to 2 if left blank. |
# Output
| Output field | Description |
|---|---|
| Job Run ID | ID of the Glue job run. |
| Job name | Name of the Glue job. |
| Query status | Status of the query execution. |
| Output path | S3 path where the JSON result is saved. |
| Error message | Message returned if the job fails. |
| Started on | Timestamp when the job started. |
| Completed on | Timestamp when the job finished. |
Last updated: 1/19/2026, 4:31:14 PM