Google Cloud Storageをデータパイプラインソースとして設定する
Google Cloud Storageをデータパイプラインソースとして設定し、レコードを抽出して送信先に同期します。 このガイドでは、GCSバケットに保存された.csvファイルおよび.parquetファイルを操作するためのコネクション設定、パイプライン構成、主要な動作について説明します。
サポートされている機能
Google Cloud Storageをデータパイプラインソースとして使用する場合、次の機能がサポートされています。
- GCSバケット内の
.csvファイルおよび.parquetファイルからデータを抽出して同期 - ファイル検出による完全同期および増分同期のサポート
- データ抽出のためのフィールドレベルの選択
- フィールドレベルのデータマスキング
前提条件
次の設定とアクセス権が必要です:
.csvファイルまたは.parquetファイルを含むストレージバケットにアクセスできるGoogle Cloudアカウント- オブジェクトの一覧表示と読み取りの権限を持つGoogleサービスアカウント
- 同期するファイルのフォルダパスとファイルパターン
Google Cloud Storageに接続する
Google Cloud Storageにデータパイプラインソースとして接続するには、次の手順を完了します。 このコネクションにより、パイプラインはストレージバケットからレコードを抽出して同期できます。
Googleサービスアカウントを作成して秘密鍵をダウンロードする方法については、Google Cloud Storageへの接続方法を参照してください。
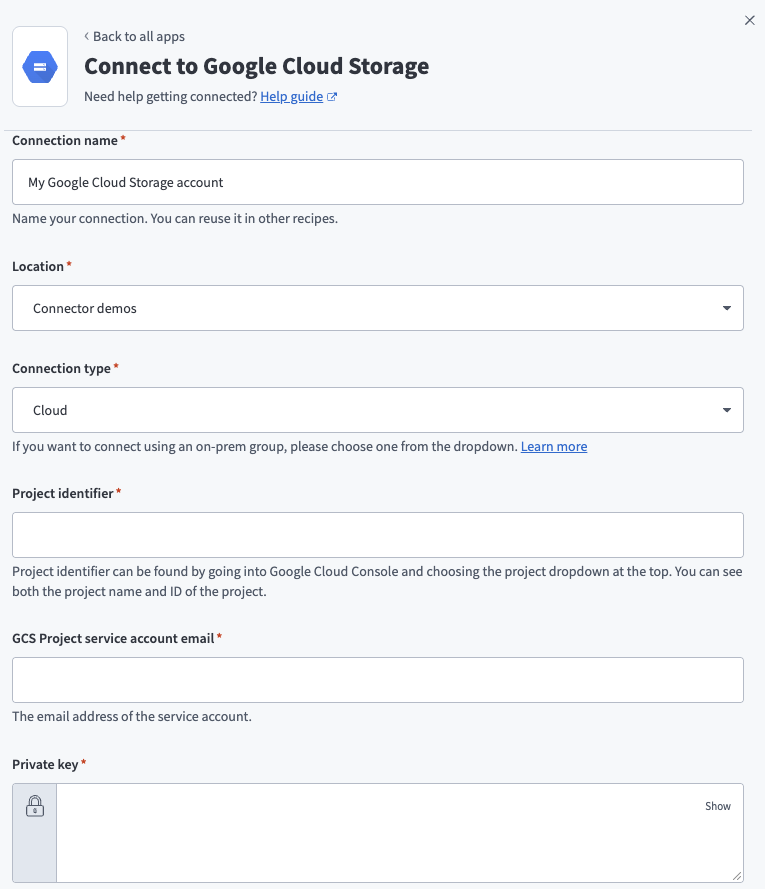
Google Cloud Storageへの接続
作成 > コネクションを選択するか、Cを2回押します。
新規コネクションページでGoogle Cloud Storageを検索して選択します。
コネクション名フィールドに名前を入力します。
 Google Cloud Storage
Google Cloud Storage
ロケーションドロップダウンを使用して、コネクションを保存するプロジェクトを選択します。
オンプレミスグループ経由で接続する必要がない限り、コネクションタイプフィールドでCloudを選択します。
Google Cloudのプロジェクト識別子を入力します。 これはGoogle Cloudコンソールで確認できます。
GCSプロジェクトサービスアカウントのメールアドレスを入力します。 これはGoogleサービスアカウントに関連付けられたメールアドレスです。
サービスアカウントのJSONファイルから秘密鍵を貼り付けます。 -----BEGIN PRIVATE KEY-----から-----END PRIVATE KEY-----までの完全なキーを含める必要があります。
任意です。 特定のバケットへのアクセスを制限するには、バケットに制限フィールドを使用します。 bucket-1,bucket-2など、カンマ区切りのリストを入力します。
任意です。 詳細設定を展開し、要求された権限(OAuthスコープ)を選択します。
認証してコネクションの設定を完了するには、Googleでログインをクリックします。
パイプラインの設定
Google Cloud Storageをデータパイプラインソースとして設定するには、次の手順を完了します。
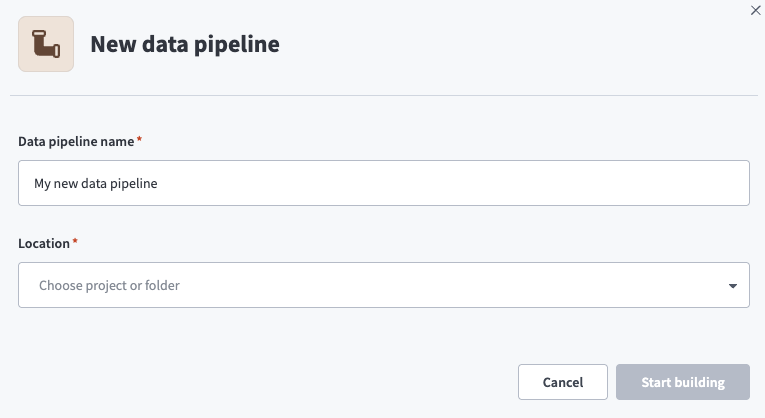
作成 > データパイプラインを選択するか、C+Iを押します。
データパイプライン名フィールドにデータパイプラインの名前を入力します。
 データパイプライン設定
データパイプライン設定
ロケーションドロップダウンメニューを使用して、データパイプラインを保存するプロジェクトを選択します。
構築を開始を選択します。
ソースアプリから新規/更新済みレコードを抽出トリガーをクリックします。 このトリガーは、パイプラインがソースアプリケーションからデータを取得する方法を定義します。
 ソースアプリから新規/更新済みレコードを抽出トリガーを設定
ソースアプリから新規/更新済みレコードを抽出トリガーを設定
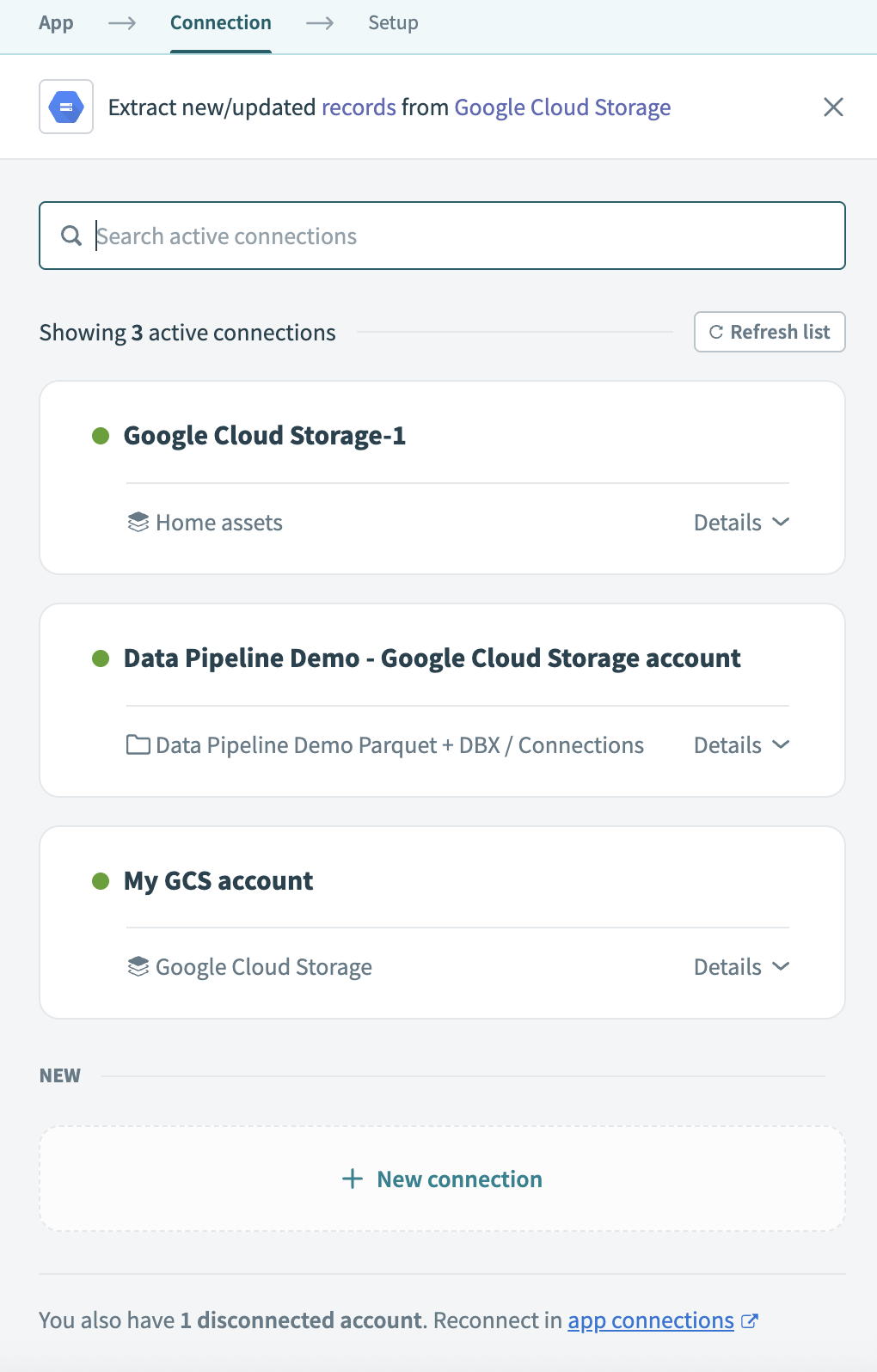
利用可能なソースアプリのリストからGoogle Cloud Storageを選択します。
このパイプラインで使用するGoogle Cloud Storageコネクションを選択します。 または、+ 新規コネクションをクリックして新しいコネクションを作成します。
 Google Cloud Storageコネクションを選択
Google Cloud Storageコネクションを選択
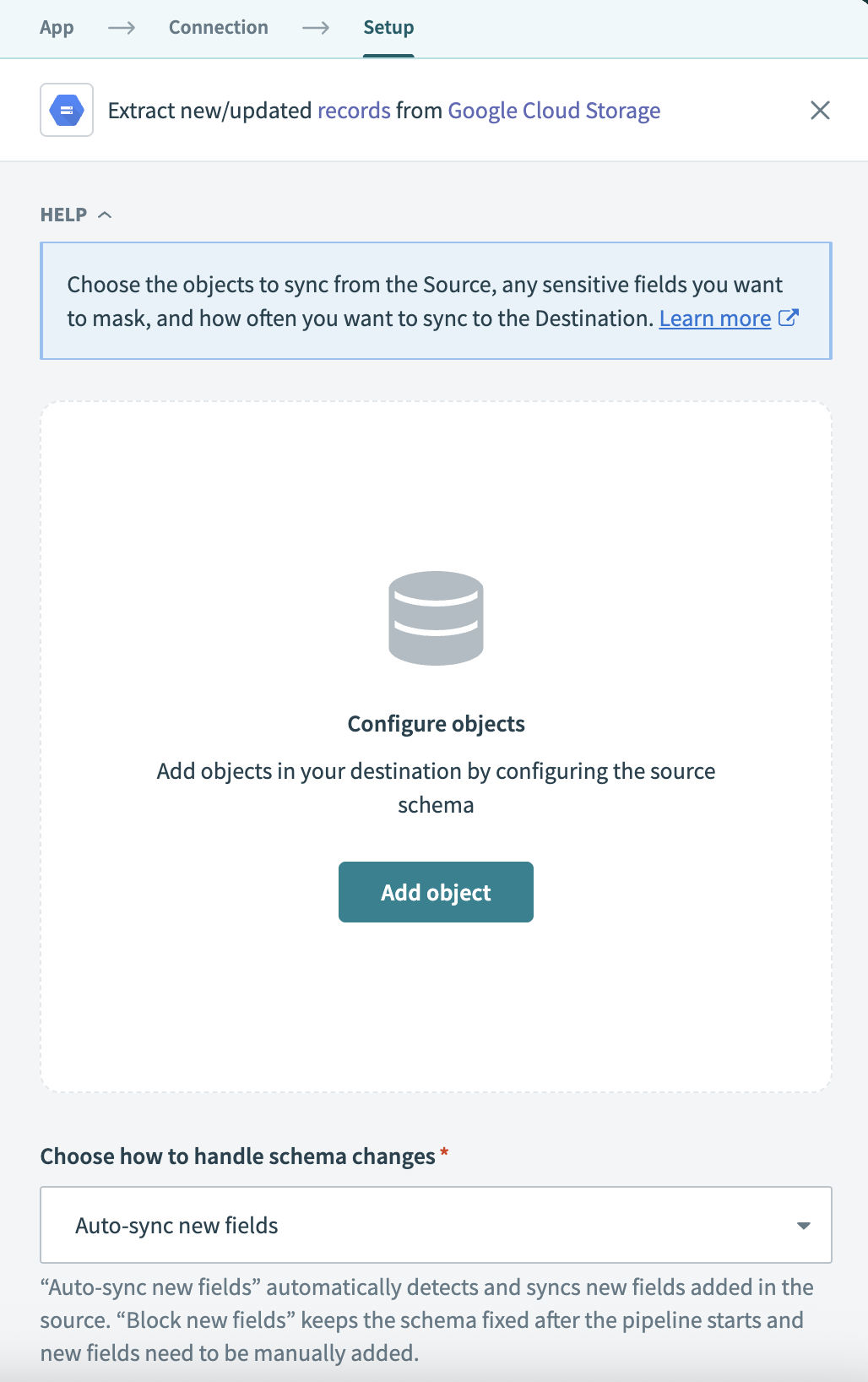
パイプラインが監視および同期するファイルを設定するには、オブジェクトを追加をクリックします。
 Google Cloud Storageオブジェクトを追加
Google Cloud Storageオブジェクトを追加
ソースフォルダパスフィールドに、監視するバケット内のフォルダを入力します。 パイプラインはこのフォルダを監視し、ファイル名パターンに一致するファイルを取得します。
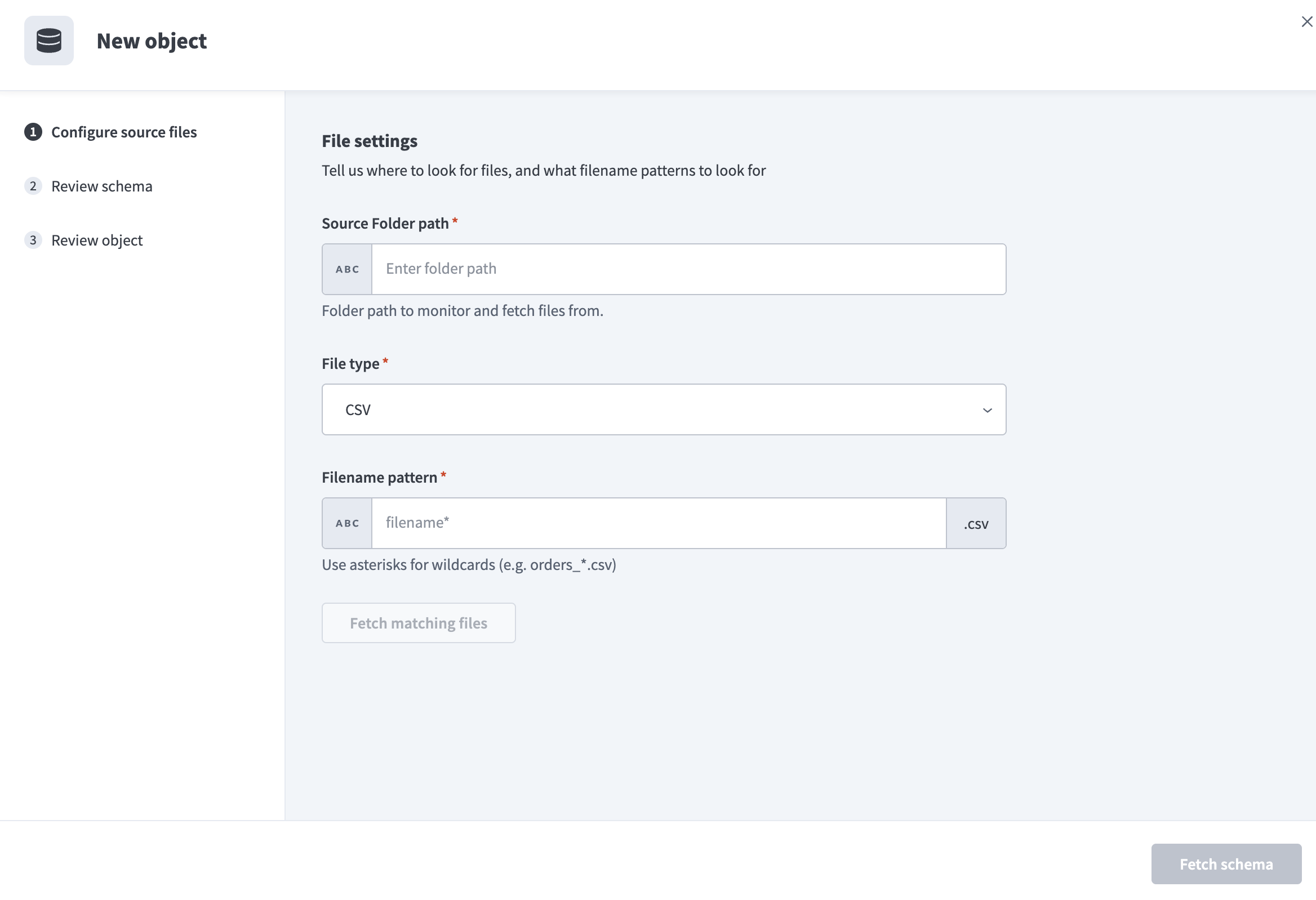 ファイル設定を構成
ファイル設定を構成
ファイルタイプドロップダウンメニューを使用して、抽出するファイル形式を選択します。 Workatoは次のファイルタイプをサポートしています。
- CSV:
.csvファイルからデータを抽出します。 追加のファイルタイプ設定の構成が必要です。 - Parquet:
.parquetファイルからデータを抽出します。 スキーマとデータ型はファイルから直接推測されます。
ファイル名パターンフィールドでパターンを使用して、取得するファイルを定義します。 複数のファイルを含めるには、orders_*などのワイルドカードを使用します。 ファイル拡張子は、選択したファイルタイプに基づいて自動的に追加されます。
一致するファイルを取得をクリックして、定義したパターンに一致するファイルをプレビューします。
宛先テーブルのスキーマを定義する参照ファイルを選択します。
ファイルタイプ設定を構成します。
参照ファイルからカラムを読み込んでプレビューするには、スキーマを取得をクリックします。
スキーマを確認し、想定されるテーブル構造と一致していることを確認します。 スキーマプレビューには、ソースファイルの列と、次のシステム生成列が含まれます。
_file: 各行の元になったソースファイルの名前。_line: ソースファイル内の各レコードの行番号またはロー番号。
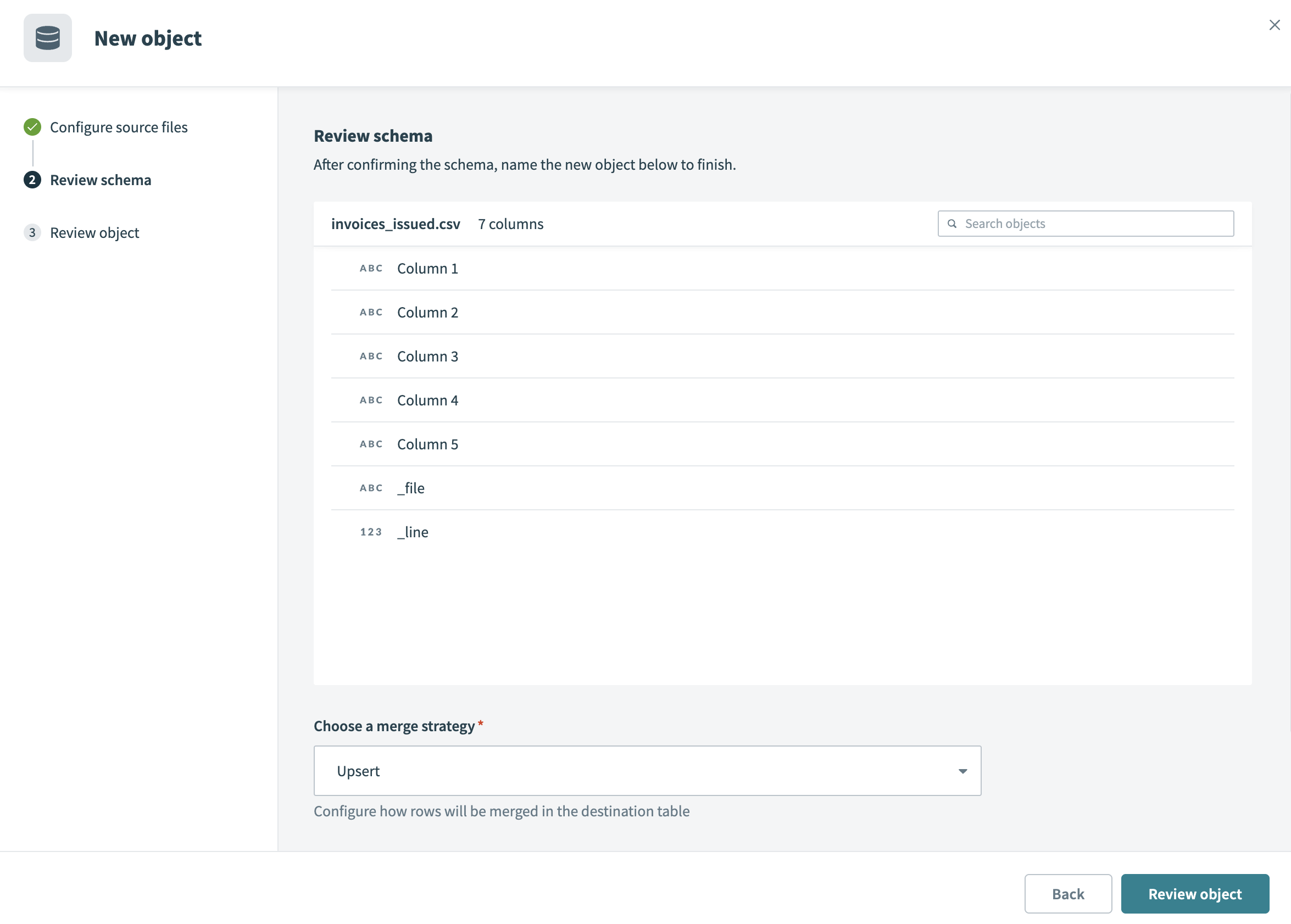 スキーマを確認
スキーマを確認
マージ戦略を選択フィールドで、宛先テーブル内の行をマージする方法を設定します。 Workatoは次のマージ戦略をサポートしています:
- アップサート: 新しい行を挿入し、既存の行を更新します。 アップサートを選択すると、マージ方法フィールドが表示されます。 宛先テーブルのプライマリキーとして使用する列を1つ以上選択できます。 マージ方法を空白のままにすると、パイプラインはシステム生成列
_fileと_lineを複合プライマリキーとして使用します。 - 追加のみ: 既存のレコードとの照合や更新を試みずに、すべての行を挿入します。 追加のみを選択すると、パイプラインはキーで照合せず、既存の行を更新しません。
オブジェクトを確認をクリックして、設定を確認します。 この画面には、ファイル設定、ファイルタイプ固有のオプション、マージの詳細が表示されます。
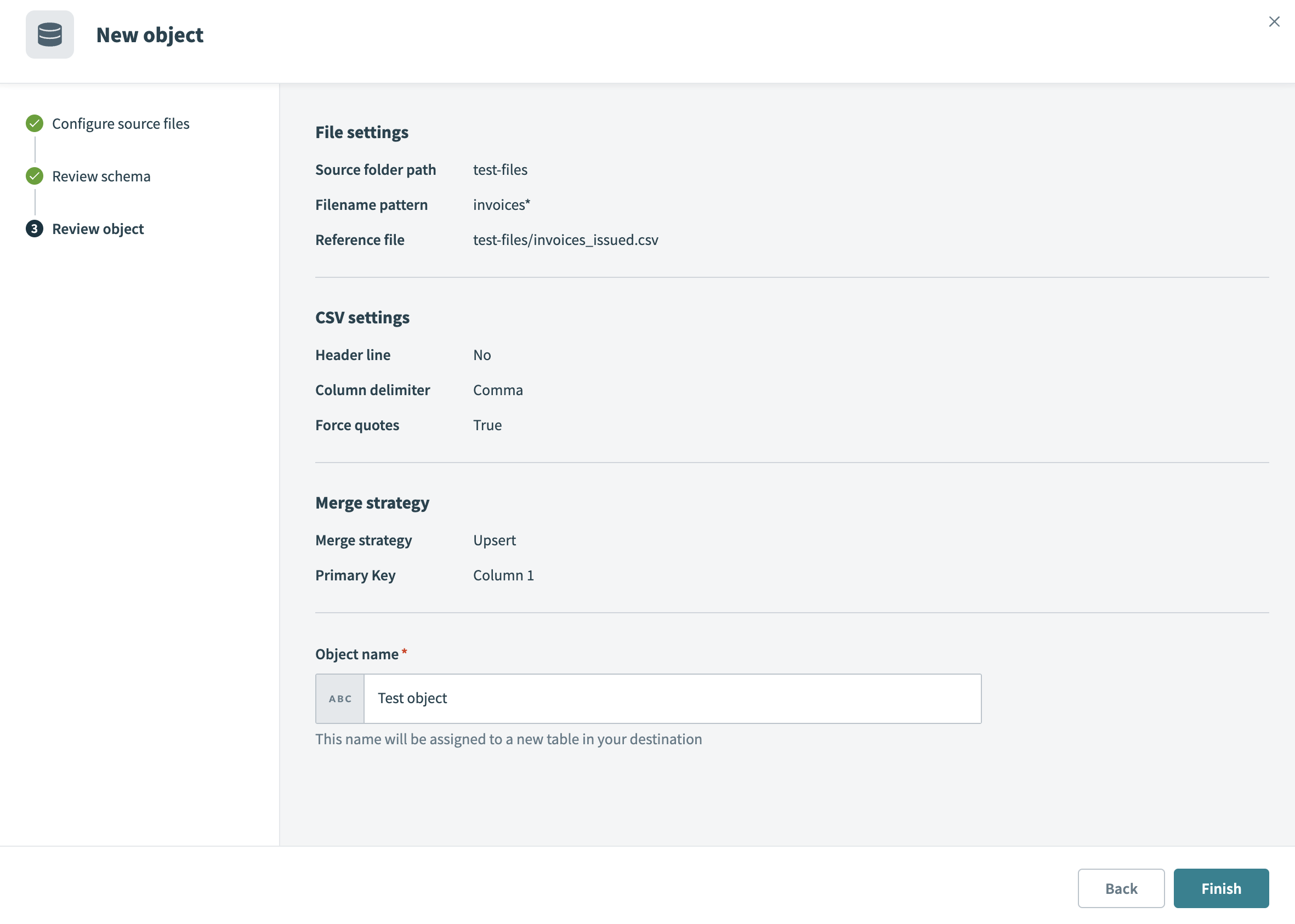 オブジェクトを確認
オブジェクトを確認
オブジェクト名を入力します。 この名前は宛先テーブル名を定義します。
完了をクリックして、オブジェクト設定を保存します。
選択した各オブジェクトのスキーマを確認してカスタマイズします。 オブジェクトを選択すると、パイプラインはそのスキーマを自動的に取得し、宛先がソースと一致するようにします。
任意のオブジェクトを展開して、そのフィールドを表示します。 使用可能なすべてのデータを抽出するにはすべてのフィールドを選択したままにし、データ抽出とスキーマレプリケーションから除外するには特定のフィールドの選択を解除します。
任意です。 フィールドレベルのデータ保護を設定します。 オブジェクトを展開した後、各フィールドの処理方法を選択します:
- そのままレプリケート(デフォルト): ソースのデータ値が宛先に同一にレプリケートされます。
- ハッシュ: 宛先に同期する前に、列内の機密データ値をハッシュ化します。
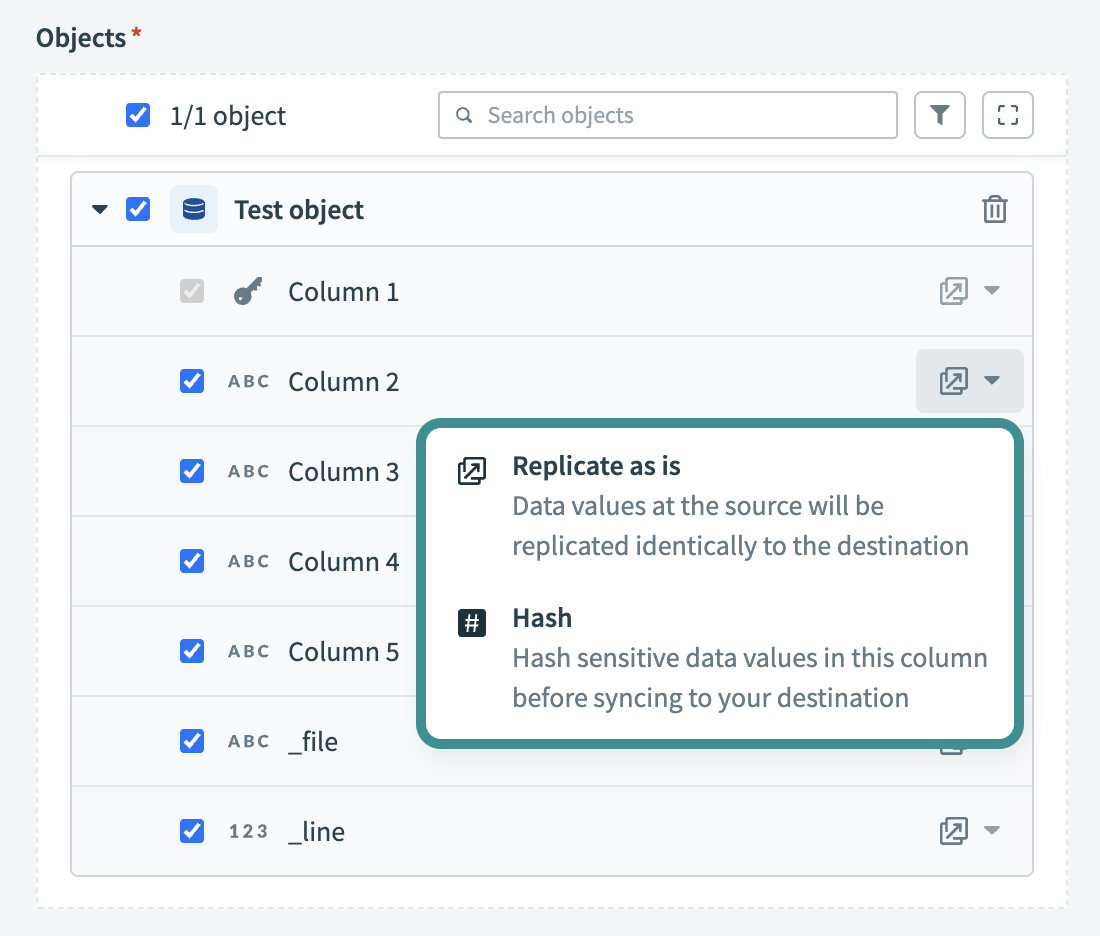 フィールドレベルのデータ保護を設定
フィールドレベルのデータ保護を設定
同じフローを使用してさらにオブジェクトを追加するには、もう一度オブジェクトを追加をクリックします。 この手順を繰り返して、パイプラインに複数のGoogle Cloud Storageオブジェクトを含めることができます。
スキーマ変更の処理方法を選択:
- スキーマ変更を自動的に検出して適用するには、新しいフィールドを自動同期を選択します。
- スキーマ変更を手動で管理するには、新しいフィールドをブロックを選択します。 このオプションを使用すると、ソーススキーマが更新された場合に宛先が同期されなくなる可能性があります。
ファイルベースのパイプラインでは、現在スキーマドリフト管理はサポートされていません。 スキーマの自動更新のサポートは、今後のリリースで予定されています。
頻度フィールドで、パイプラインがソースから宛先にデータを同期する頻度を設定します。 標準の時間ベースのスケジュールを選択するか、カスタムcron式を定義します。
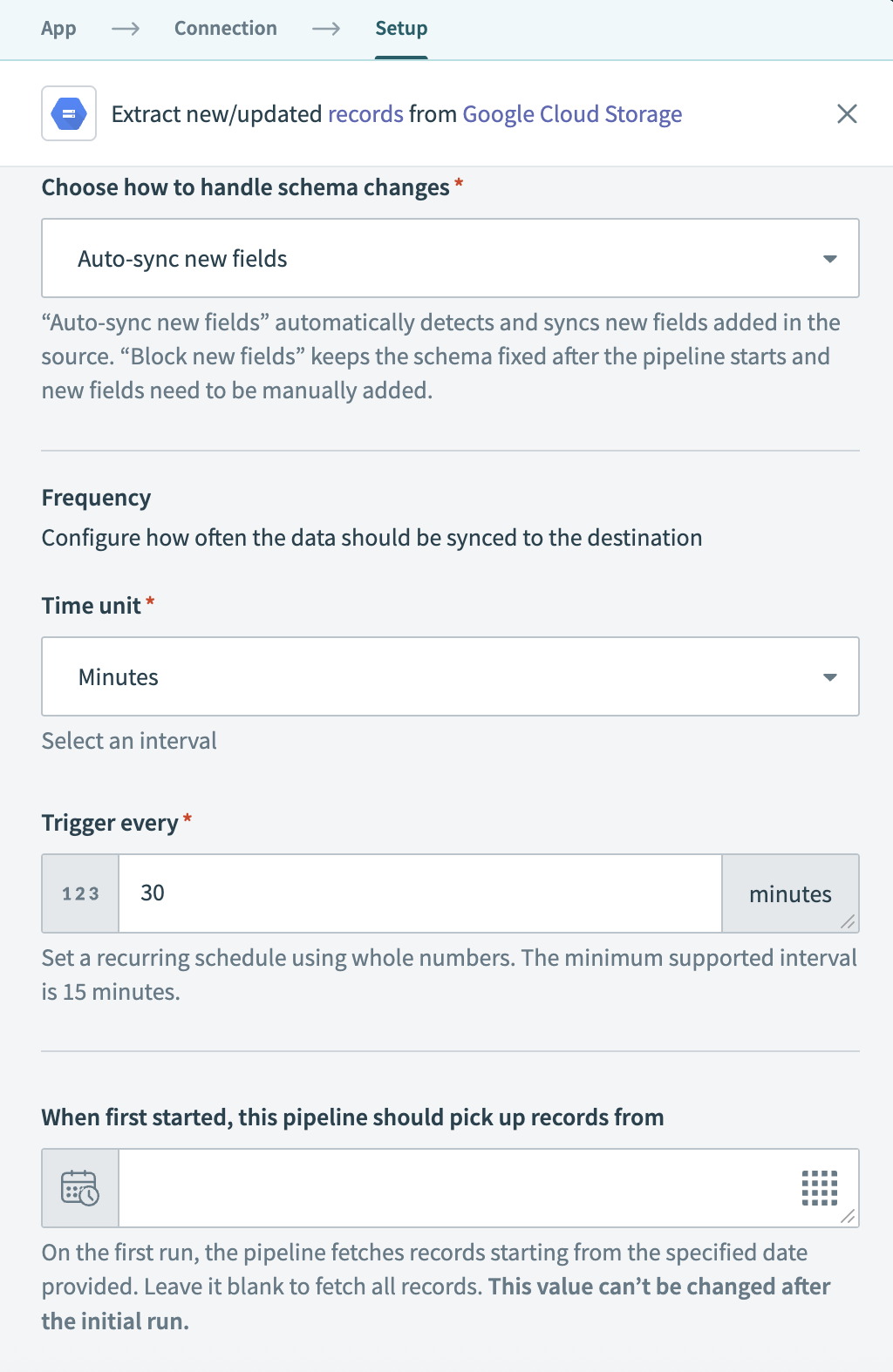 同期頻度を設定
同期頻度を設定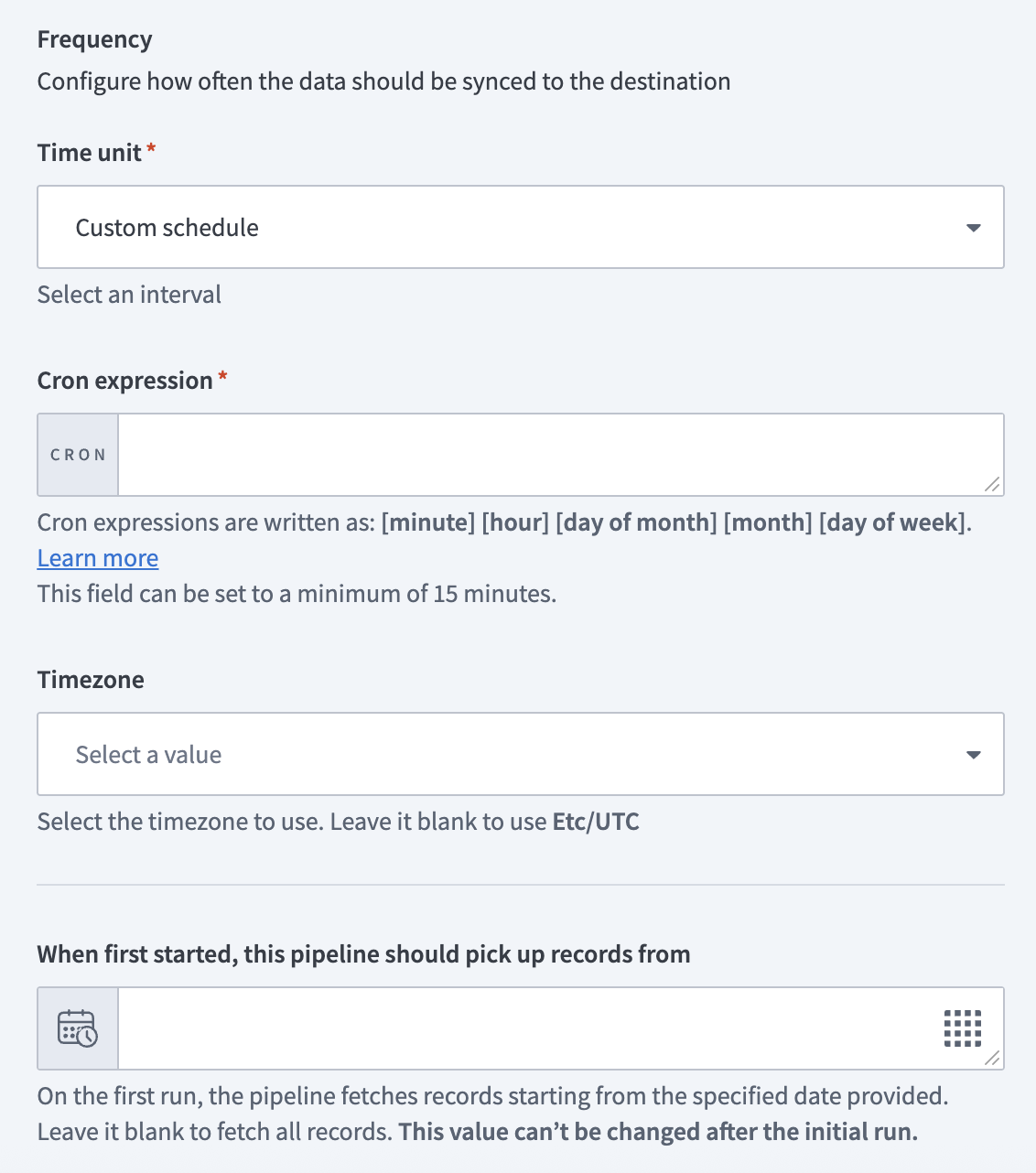 同期頻度を設定
同期頻度を設定ファイルスキーマと処理
Google Cloud Storageコネクターは、指定したバケットに保存されている.csvファイルおよび.parquetファイルを読み取ります。 これらのファイルは、パイプラインが抽出して送信先に同期する構造とデータを定義します。
Workatoは、選択した参照ファイルからスキーマとデータ型を推測します。 Workatoは、.csvファイルの日付値と日時値を文字列として扱います。 ロードが完了した後、宛先でこれらのフィールドを適切なデータ型に変換します。
正確なスキーママッピングを確保するには、ファイルパターンに一致するすべてのファイルで同じカラム構造とデータ形式を維持する必要があります。
最終更新日: