データパイプラインの設定
このガイドでは、ソースからレコードを抽出し、サポートされている宛先にレプリケートするデータパイプラインを作成する方法について説明します。 コネクションの設定、オブジェクトの選択、スキーマの同期、パイプラインの開始の手順が含まれます。
前提条件
データパイプラインを作成する前に、次のものがあることを確認してください。
- Salesforce、NetSuite2、Jira、Coupa、Marketoなど、サポートされているソースアプリケーション
- Snowflake、Databricks、SQL Serverなど、サポートされている宛先データウェアハウス
- 両方のシステムに必要なアクセス権と認証情報
- ソースシステムのスキーマとオブジェクトに関する知識。 この情報は通常、各アプリケーションの製品ドキュメントで確認できます。 たとえば、Salesforce標準オブジェクトリファレンスを参照してください。
ソースアプリケーションの設定
ソースアプリケーションを選択し、設定ガイドに従って認証、オブジェクトの選択、スキーマの定義を行います。
- Amazon S3の設定
- Azure Blob Storageの設定
- Confluenceを設定する
- Coupaの設定
- Databricksの設定
- Ellucian Bannerの設定
- Google BigQueryを設定
- Google Cloud Storageの設定
- Google Driveの設定
- HiBobを設定
- HubSpotの設定
- Intercomの設定
- Jiraを設定
- Marketoの設定
- NetSuite2の設定
- Oracleを設定
- Oracle Fusion Cloudを設定
- Salesforceの設定
- SAP Table Readerの設定
- ServiceNowを設定
- Shopifyを設定する
- Snowflakeの設定
- SQL Serverの設定
- Stripeの設定
- Workdayの設定
- Workday RaaSの設定
- Zendeskを設定
宛先の設定
宛先を選択し、設定ガイドに従って接続し、データのロード方法を設定します。
データパイプラインの開始
パイプラインを開始を選択して、データパイプラインを開始します。 パイプラインを開始すると、選択したオブジェクトが同期され、履歴データがロードされます。
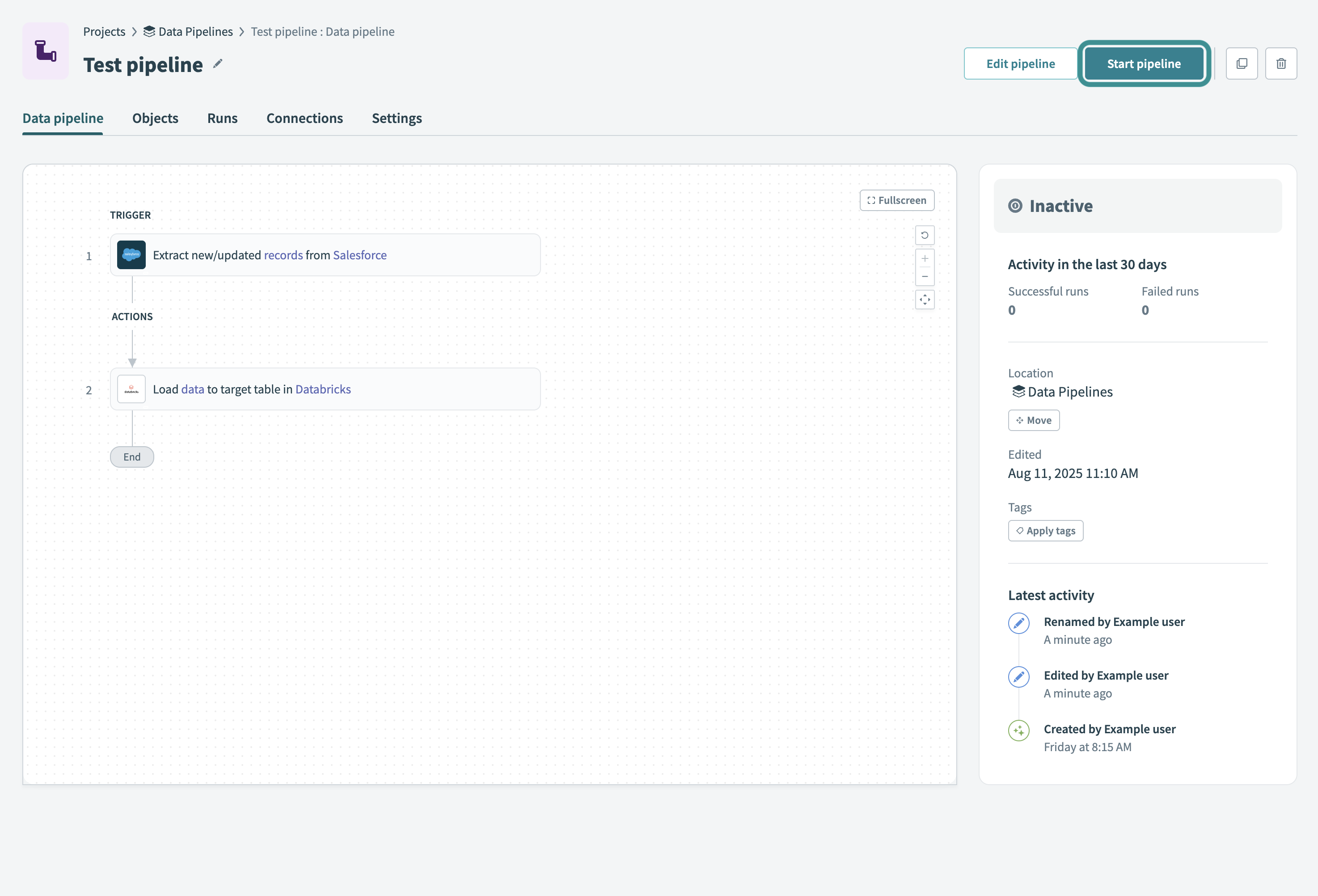 データパイプラインの開始
データパイプラインの開始
パイプラインに対して移動、編集、またはタグを適用を選択することもできます。
パイプラインアクティビティの監視方法と問題のトラブルシューティング方法については、データパイプラインレシピの監視ガイドを参照してください。
最終更新日: