Databricksをデータパイプライン送信先として設定する
Databricksをデータパイプラインの送信先として設定します。 このコネクションにより、Workatoはソーススキーマを使用して、ソースアプリケーションからDatabricksワークスペースにデータをレプリケートできます。
サポートされている機能
Databricksをパイプライン送信先として使用する場合、次の機能がサポートされます:
- ソーススキーマに基づく宛先テーブルの自動作成
- フルデータロードおよび増分データロードのサポート
- 明示的なフィールドマッピングを使用しないフィールドレベルのデータレプリケーション
- スキーマドリフトの処理および更新操作
前提条件
次の設定とアクセス権が必要です:
- SQLウェアハウスにアクセスできるDatabricksワークスペース
- Databricks SQLエンドポイントのサーバーホスト名とHTTPパス
- サポートされている認証方法
Databricksに接続する
データパイプライン送信先としてDatabricksに接続するには、次の手順を実行します。 このコネクションにより、パイプラインはデータをDatabricksにレプリケートしてロードできます。
Databricksに接続
作成 > コネクションを選択するか、Cを2回押します。
新規コネクションページでDatabricksを検索して選択します。
コネクション名フィールドに名前を入力します。
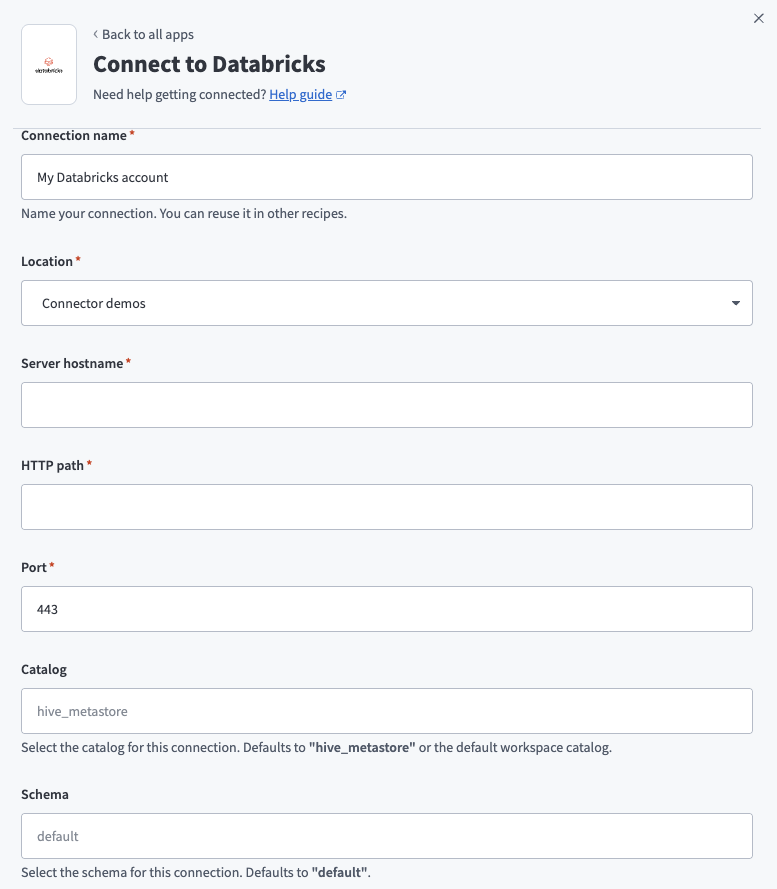 Databricksコネクション設定
Databricksコネクション設定
ロケーションドロップダウンを使用して、コネクションを保存するプロジェクトを選択します。
Databricksインスタンスのサーバーホスト名を入力します。
HTTPパスを入力します。 このパスは、Databricks Environment内の特定のSQLウェアハウスを識別します。
コネクションのポートを入力します。 デフォルトは443です。
任意です。 カタログを指定します。 空白のままにすると、コネクターはデフォルトのhive_metastoreを使用します。
任意です。 スキーマを指定します。 空白のままにすると、コネクターはデフォルトスキーマdefaultを使用します。
任意です。 データベースタイムゾーンを選択します。 このタイムゾーンは、データレプリケーション中のタイムスタンプに適用されます。
認証タイプドロップダウンメニューを使用して、次のいずれかの認証タイプを選択します:
- ユーザー名/パスワード:Databricks認証情報をユーザー名フィールドとパスワードフィールドに入力します。
- パーソナルアクセストークン:対応するフィールドにパーソナルアクセストークンを入力します。
接続をクリックして、コネクションを検証および確立します。
宛先アクションの設定
パイプラインを開始する前に、Databricksのスキーマが新規作成済みで空であることを確認します。 これにより、初回同期中のエラーを防ぎ、パイプラインが競合なしで送信先テーブルを作成できるようになります。
宛先アプリのターゲットテーブルにデータをロードアクションをクリックします。 このアクションでは、パイプラインが宛先でデータをレプリケートする方法を定義します。
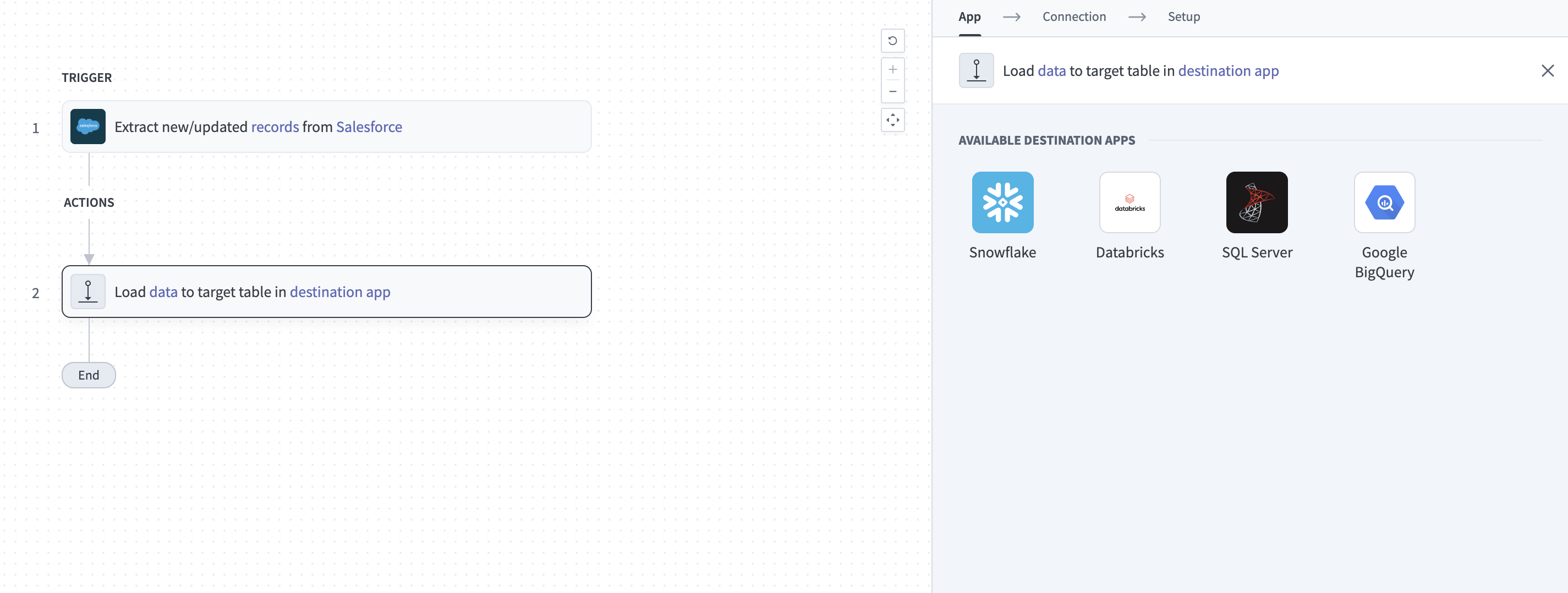 宛先アプリのターゲットテーブルにデータをロードアクションの設定
宛先アプリのターゲットテーブルにデータをロードアクションの設定
利用可能なソースアプリのリストからDatabricksを選択します。
このパイプラインで使用するDatabricksコネクションを選択します。 または、+ 新規コネクションをクリックして新しいコネクションを作成します。
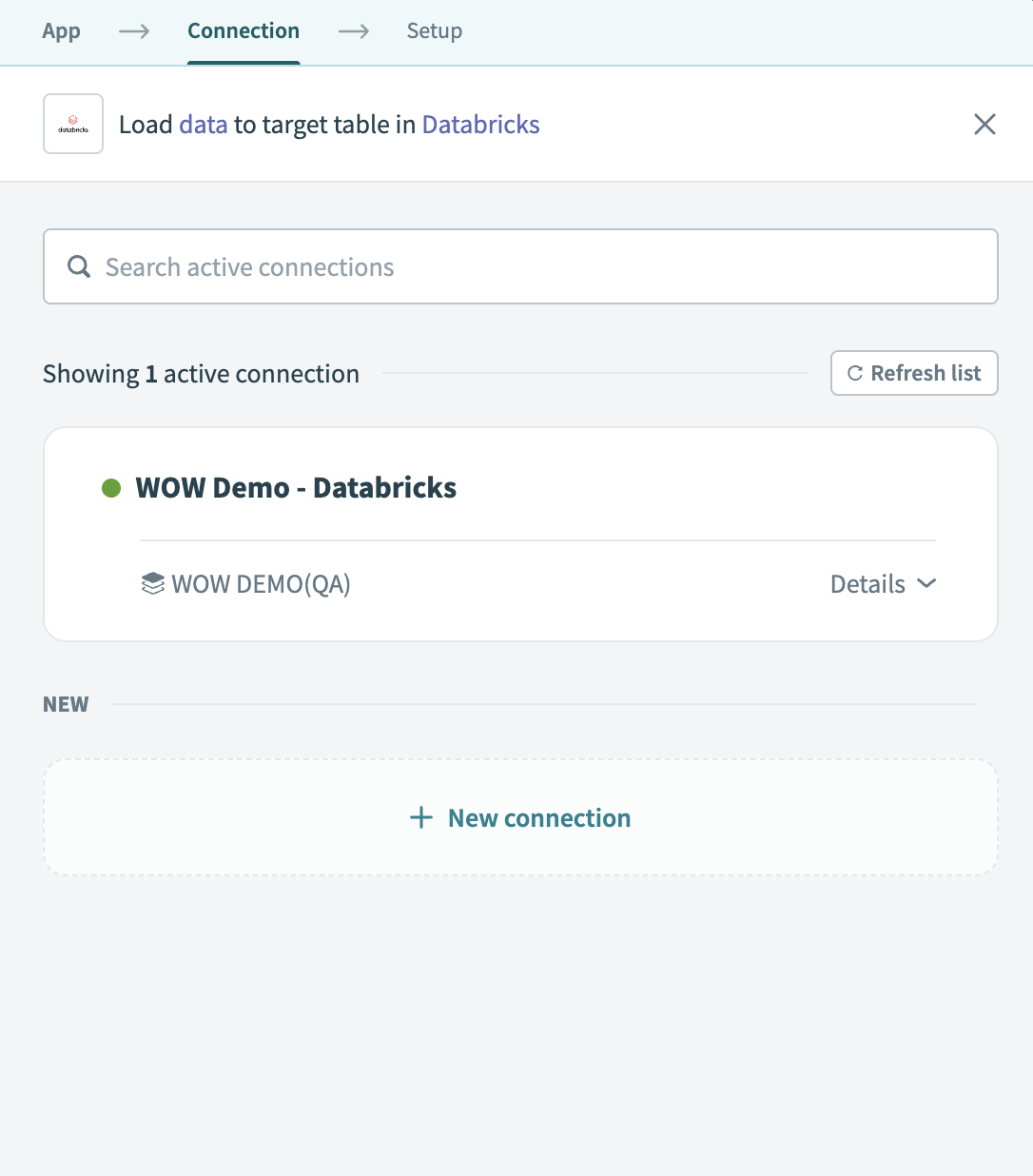 Databricksコネクションを選択
Databricksコネクションを選択
送信先アプリのターゲットテーブルにデータをロードアクションは、ソースからDatabricksにオブジェクトスキーマを自動的にレプリケートします。 明示的なフィールドマッピングは不要です。
Workatoパイプラインは、ソーススキーマに基づいて送信先テーブルを自動的に作成します。 パイプラインは、データレプリケーションと更新操作をサポートするためにステージと一時テーブルも作成します。
保存を選択してパイプラインを保存します。
識別子の処理
Databricksは、識別子が引用符で囲まれていない限り、デフォルトで大文字と小文字を区別しない識別子システムを使用します。 Workatoパイプラインは、次のルールを適用して、ソース列名を有効なDatabricks識別子に変換します:
- カラム名は大文字に変換されます
$、スペース、ダッシュなどの特殊文字はアンダースコア(_)に置き換えられます 識別子は、特殊文字および予約語をサポートするためにバッククォート(`)で囲まれます。
これにより、DatabricksでのDelta Lakeテーブル作成とクエリ動作との互換性が確保されます。
例
次のソーステーブル構造:
| ソースオブジェクト | ソースフィールド |
|---|---|
Account | $Name$, Created Date, Limit |
結果として、Databricksに次のテーブルが作成されます:
CREATE TABLE `account` (`_NAME_`, `CREATED_DATE`, `LIMIT`)引用符で囲まれていないクエリでは、大文字と小文字に関係なく列を参照できます:
SELECT created_date FROM account;引用符で囲まれたクエリは、正確な大文字と小文字および形式と一致している必要があります:
SELECT `_NAME_` FROM `account`;ツール全体で一貫した動作を実現するために、すべてのクエリがDatabricks識別子ルールに従っていることを確認します。
最終更新日: