Snowflakeをデータパイプラインの宛先として設定
Snowflakeをデータパイプラインの宛先として設定します。 このコネクションにより、Workatoはソーススキーマを使用してソースアプリケーションからSnowflakeにデータをレプリケートできます。
サポートされている機能
Snowflakeをパイプラインの宛先として使用する場合、次の機能がサポートされます:
- ソーススキーマに基づく宛先テーブルの自動作成
- フルデータロードおよび増分データロードのサポート
- 明示的なフィールドマッピングを使用しないフィールドレベルのデータレプリケーション
- スキーマドリフトの処理および更新操作
- データ整合性のためのステージングテーブルおよび一時テーブルの使用
前提条件
次の設定とアクセス権が必要です:
- データベース、ウェアハウス、スキーマにアクセスできるSnowflakeアカウント
- テーブルを作成し、データをロードする権限を持つユーザーロール
- サポートされている認証方法: OAuth 2.0、キーペア認証、またはユーザー名/パスワード
Snowflakeへの接続
Snowflakeをデータパイプラインの宛先として接続するには、次の手順を実行します。 このコネクションにより、パイプラインでデータをSnowflakeにレプリケートしてロードできます。
Snowflakeへの接続
作成 > コネクションを選択するか、Cを2回押します。
新規コネクションページでSnowflakeを検索して選択します。
コネクション名フィールドにコネクションの名前を入力します。
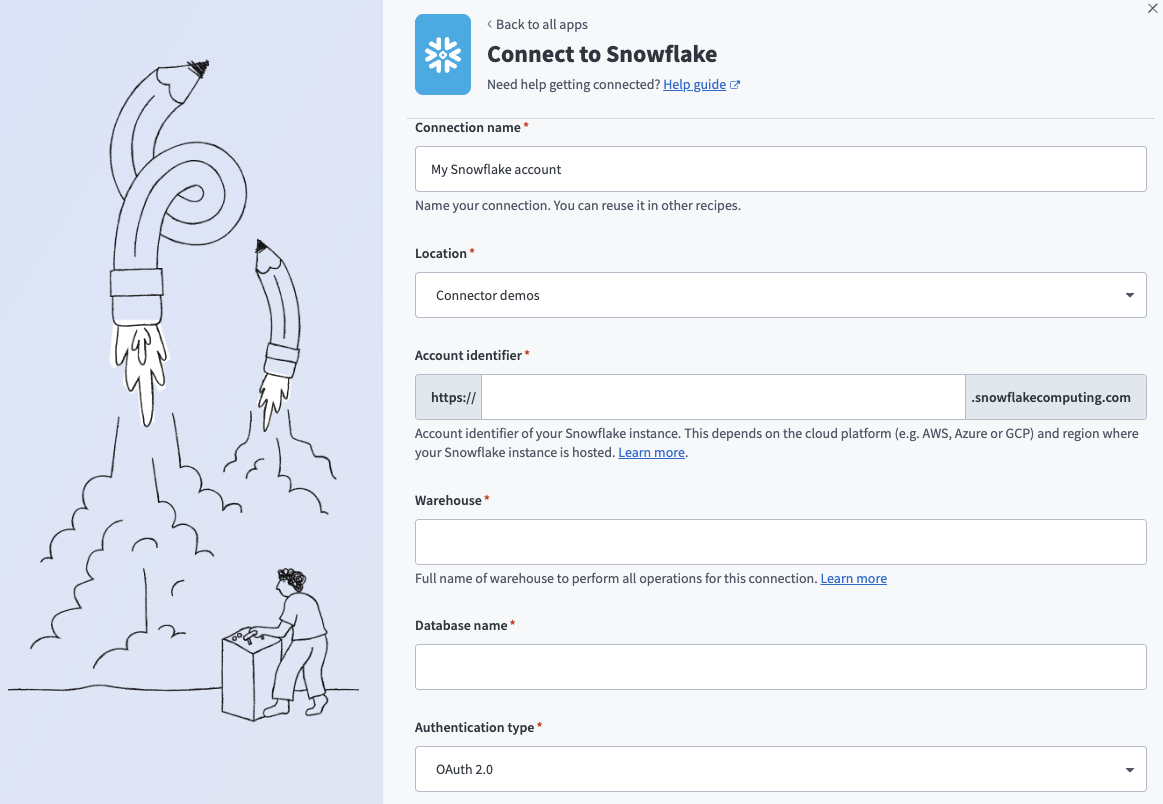 Snowflakeコネクションの設定
Snowflakeコネクションの設定
ロケーションドロップダウンメニューを使用して、コネクションを保存するプロジェクトを選択します。
Snowflakeインスタンスのアカウント識別子を、サポートされている次のいずれかの形式で入力します:
- アカウント名:
https://{orgname}-{account_name} - コネクション名:
https://{orgname}-{connectionname} - アカウントロケーター:
https://{accountlocator}.{region}.{cloud}
詳細については、Snowflakeのアカウントへの接続ガイドを参照してください。
アカウントロケーター形式
特定のロケーションでは、アカウントロケーターURLに{region}および{cloud}を含める必要があります。 例:
- AWS米国西部(オレゴン):
your-account-locator - AWS米国東部(オハイオ):
your-account-locator.us-east-2 - Azure West Europe:
your-account-locator.west-europe.azure
詳細については、識別子としてのアカウントロケーターの使用ガイドを参照してください。
このコネクションのコンピューティングリソースを定義するには、ウェアハウス名を入力します。 詳細については、ウェアハウスに関する考慮事項セクションを参照してください。
ターゲットのSnowflakeデータベースのデータベース名を入力します。
認証タイプを選択します:
- OAuth 2.0: クライアントIDとクライアントシークレットが必要です。
- キーペア認証: Snowflakeのユーザー名、PKCS#8形式の秘密鍵、および鍵が暗号化されている場合は秘密鍵パスフレーズが必要です。
- ユーザー名/パスワード: ユーザー名とパスワードが必要です。
SNOWFLAKEユーザー名/パスワード認証の廃止
Snowflakeは、ユーザー向けの単一要素パスワード認証を2025年11月までに廃止する予定です。
この日付より前に、既存のすべてのユーザー名/パスワードコネクションをOAuth 2.0またはキーペア認証に移行することを強く推奨します。 既存のユーザー名/パスワードコネクションは、廃止日まで引き続き動作します。
設定手順については、Snowflakeコネクターの認証オプションセクションを参照してください。
任意です。 認証に使用するロールを指定します。 このロールは、ユーザーに割り当てられた既存のロールである必要があります。 空白のままにすると、Snowflakeはユーザーに割り当てられたデフォルトロールを使用します。
任意です。 スキーマを入力します。 空白のままにすると、デフォルトスキーマはpublicになります。
任意です。 タイムスタンプのタイムゾーンが正しく処理されるように、改善された日時処理を使用(推奨)をはいに設定します。
任意です。 割り当てられたタイムゾーンがないタイムスタンプに適用するデータベースタイムゾーンを定義します。
接続をクリックして、コネクションを検証および確立します。
宛先アクションの設定
パイプラインを開始する前に、Snowflakeのスキーマが新しく作成され、空であることを確認してください。 これにより、初回同期中のエラーを防ぎ、パイプラインが競合なく宛先テーブルを作成できるようになります。
宛先アプリのターゲットテーブルにデータをロードアクションをクリックします。 このアクションでは、パイプラインが宛先でデータをレプリケートする方法を定義します。
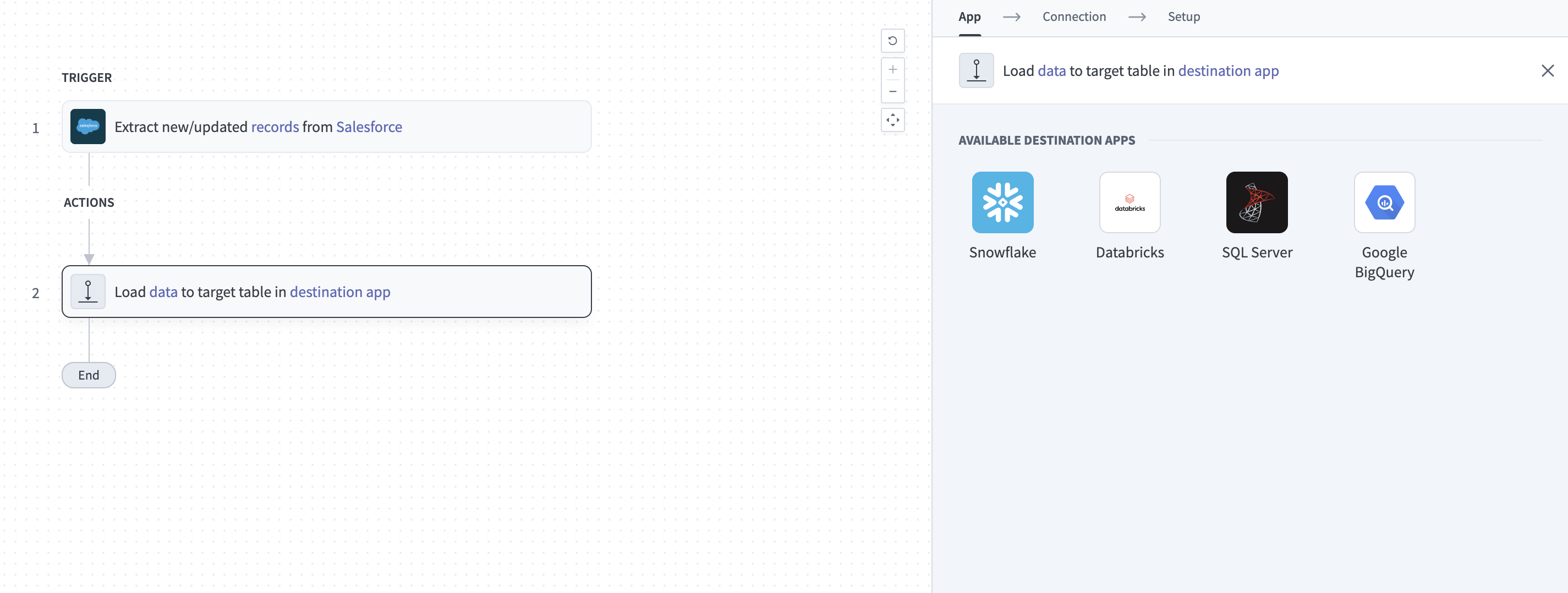 宛先アプリのターゲットテーブルにデータをロードアクションの設定
宛先アプリのターゲットテーブルにデータをロードアクションの設定
利用可能なソースアプリのリストからSnowflakeを選択します。
このパイプラインに使用するSnowflakeコネクションを選択します。 または、+ 新規コネクションをクリックして新しいコネクションを作成します。
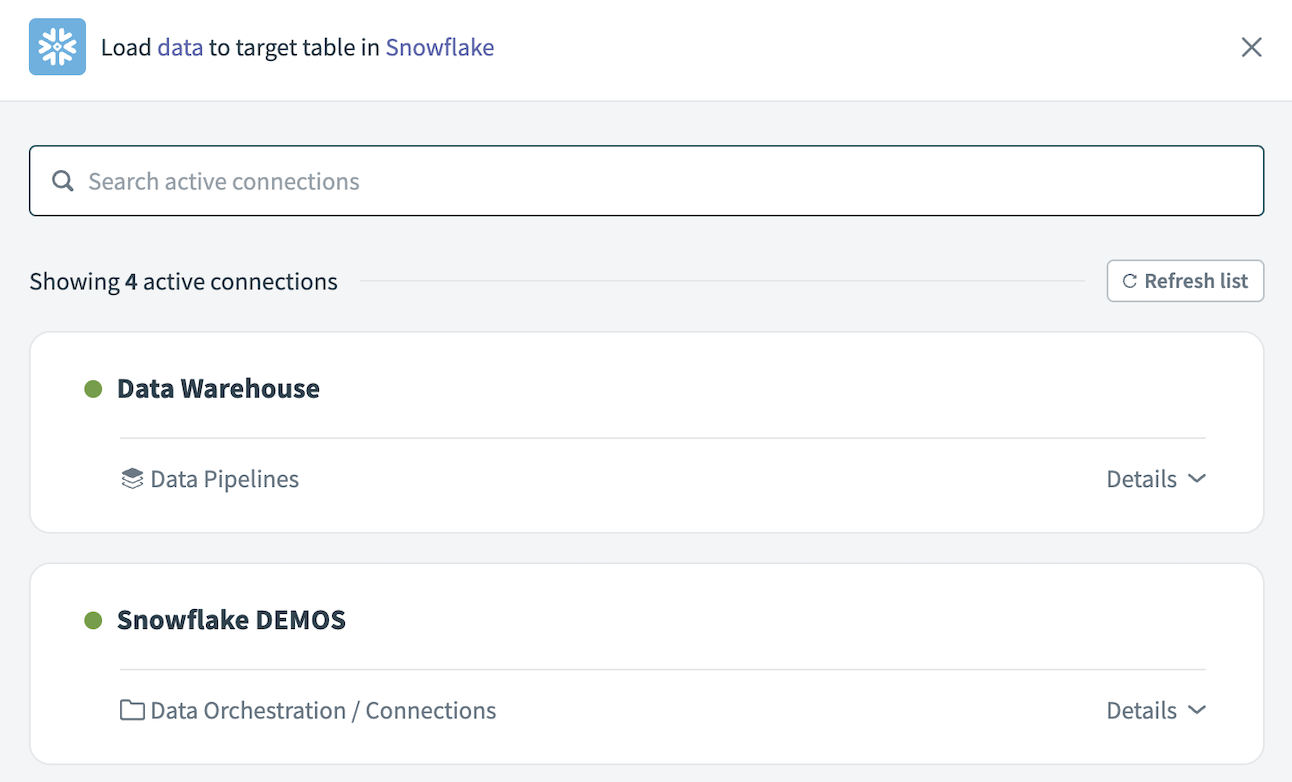 Snowflakeコネクションの選択
Snowflakeコネクションの選択
宛先アプリのターゲットテーブルにデータをロードアクションは、ソースからSnowflakeにオブジェクトスキーマを自動的にレプリケートします。 明示的なフィールドマッピングは不要です。
Workatoパイプラインは、ソーススキーマに基づいて宛先テーブルを作成します。 パイプラインは、データレプリケーションと更新操作をサポートするためにステージと一時テーブルも作成します。
任意です。 宛先アプリのターゲットテーブルにデータをロードアクションをクリックして、Snowflakeでテーブルを作成する方法を設定します。
特定のスキーマ配下にテーブルを整理するには、スキーマを入力します。 空白のままにすると、Workatoはコネクションのデフォルトスキーマを使用します。
すべてのテーブル名の先頭に値を付加するには、テーブルプレフィックスを入力します。 これにより、複数のパイプラインが同じスキーマに書き込む場合の命名競合を防ぐことができます。
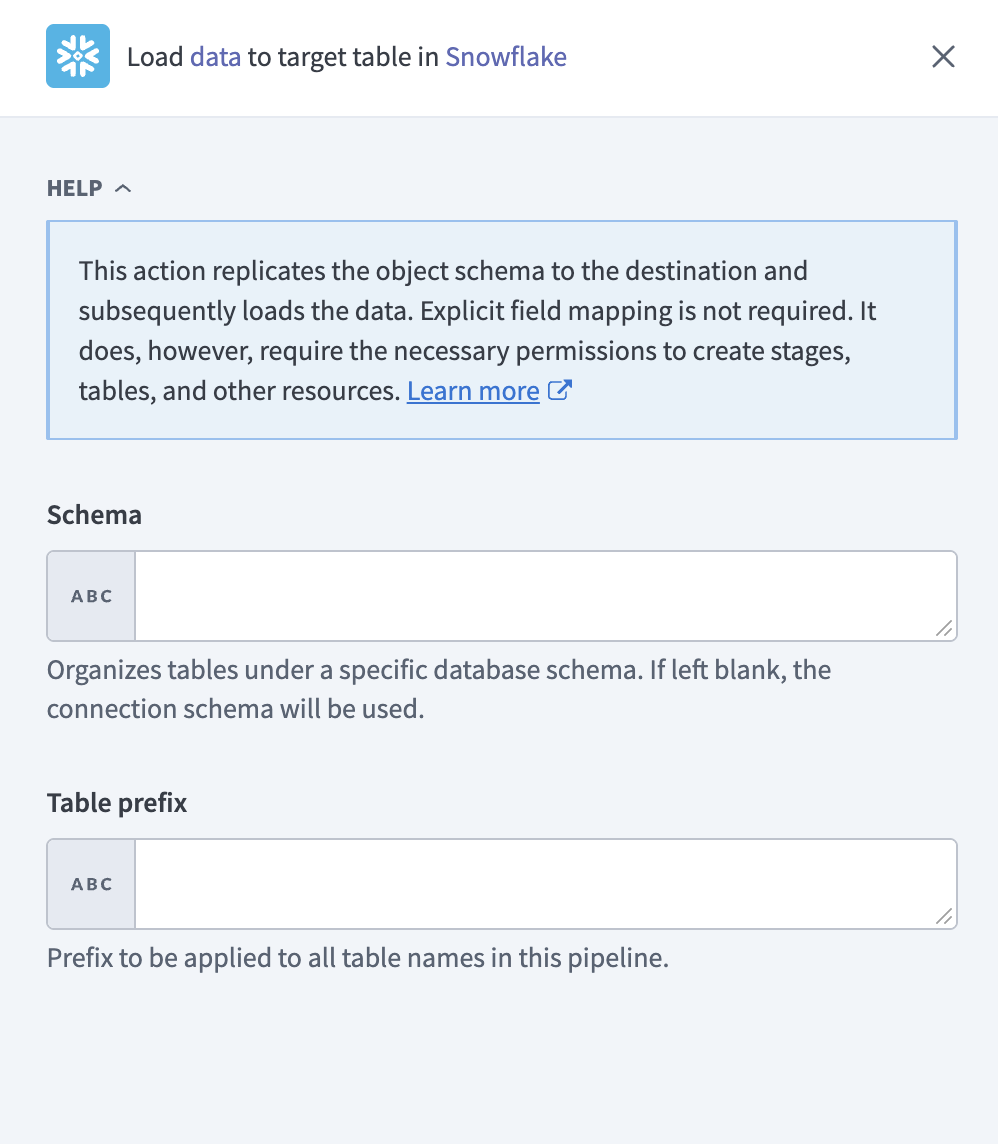 Snowflakeスキーマとテーブルプレフィックスの設定
Snowflakeスキーマとテーブルプレフィックスの設定
パイプラインを初めて実行した後は、スキーマまたはテーブルプレフィックスを変更できません。
保存を選択してパイプラインを保存します。
識別子の処理
Workatoは、データをSnowflakeにレプリケートする際に、オブジェクト名とフィールド名に次の変換を適用します:
- カラム名は大文字に変換されます
$、スペース、ダッシュなどの特殊文字はアンダースコア(_)に置き換えられます- 識別子は、特殊文字および予約語をサポートするために二重引用符で囲まれます
これらの変換により、SnowflakeのSQL構文および予約キーワードとの互換性が確保されます。
例
次のソーステーブル構造:
| ソースオブジェクト | ソースフィールド |
|---|---|
Account | $Name$, CreatedDate, Limit |
Snowflakeに作成される次のテーブルになります:
CREATE TABLE "ACCOUNT" ("_NAME_", "CREATEDDATE", "LIMIT")Snowflakeは引用符で囲まれていない識別子を大文字小文字を区別せずに扱うため、次のようなクエリを実行できます:
SELECT createddate FROM account;
SELECT "LIMIT" FROM ACCOUNT;引用符で囲まれたクエリは、識別子の正確な大文字小文字と一致している必要があります。
最終更新日: