データパイプラインの宛先としてSQL Serverを設定する
データパイプラインの宛先としてSQL Serverを設定します。 このコネクションにより、Workatoはソーススキーマを使用して、ソースアプリケーションからSQL Serverインスタンスにデータをレプリケートできます。
サポートされている機能
パイプラインの宛先としてSQL Serverを使用する場合、次の機能がサポートされます:
- ソーススキーマに基づく宛先テーブルの自動作成
- フルデータロードおよび増分データロードのサポート
- 明示的なフィールドマッピングを使用しないフィールドレベルのデータレプリケーション
- スキーマドリフトの処理および更新操作
前提条件
次の設定とアクセス権が必要です:
- Workatoから到達可能なSQL Serverインスタンス(Cloudまたはオンプレミスグループ)
- テーブルを作成し、データを書き込む権限を持つユーザー
- ホスト、ポート、データベース、および認証資格情報
SQL Server OPAの要件
Workatoでデータパイプラインをサポートするには、SQL Server OPAバージョン29.1以上が必要です。
SQL Serverに接続する
データパイプラインの宛先としてSQL Serverに接続するには、次の手順を実行します。 このコネクションにより、パイプラインはSQL Serverインスタンス内のターゲットテーブルにレコードを書き込むことができます。
SQL Serverに接続する
作成 > コネクションを選択するか、Cを2回押します。
新規コネクションページでSQL Serverを検索して選択します。
コネクション名フィールドに名前を入力します。
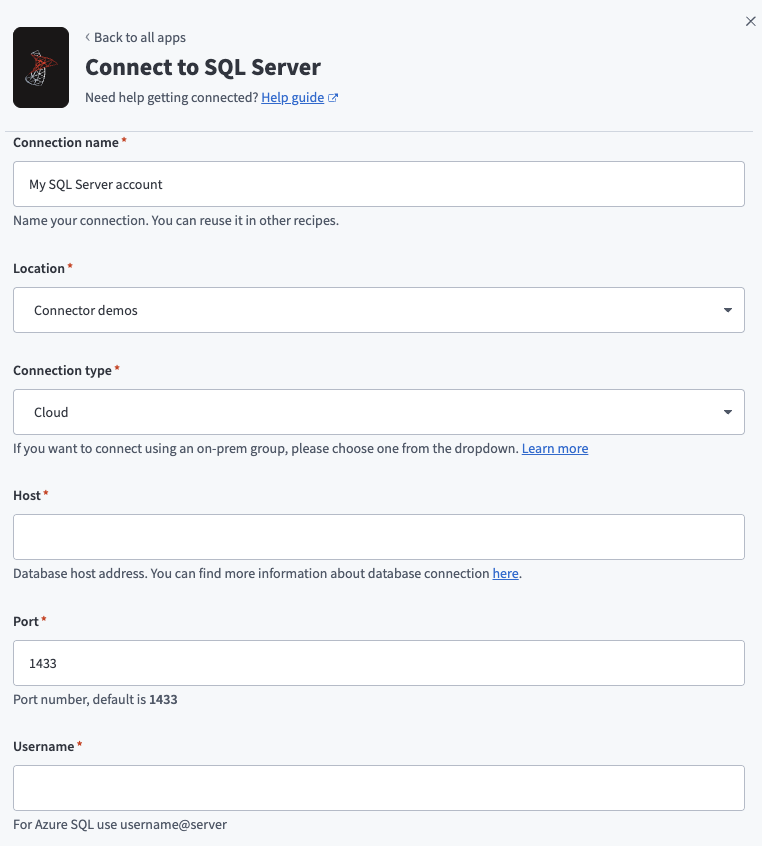 SQL Serverコネクションの設定
SQL Serverコネクションの設定
ロケーションドロップダウンを使用して、コネクションを保存するプロジェクトを選択します。
オンプレミスグループ経由で接続する必要がない限り、コネクションタイプフィールドでCloudを選択します。
ホストされているサーバーのURLをホストフィールドに入力します。
サーバーが実行されているポート番号をポートフィールドに入力します。 SQL Serverのデフォルトポートは1433です。
SQL Serverに接続するユーザー名をユーザー名フィールドに入力します。
SQL Serverに接続するパスワードをパスワードフィールドに入力します。
接続するSQL Serverデータベースの名前をデータベースフィールドに入力します。
任意です。 Azure SQLフィールドで、Azure SQLインスタンスに接続するかどうかを指定します。 デフォルトはいいえです。
任意です。 追加設定を構成するには、詳細設定フィールドを展開します:
| フィールド | 説明 |
|---|---|
| 改善された日時処理を使用 | SQL Serverのdatetime、datetime2、およびdatetimeoffsetデータ型の拡張処理を有効にします。 デフォルトはtrueです。 詳細については、datetime処理の改善セクションを参照してください。 |
| データベースのタイムゾーン | データベースのローカルタイムゾーンを設定します。 datetimeおよびdatetime2データ型にタイムゾーンが指定されている場合、値は挿入前にこのタイムゾーンに変換されます。 デフォルトはUTCです。 |
接続を選択して、コネクションを確認および保存します。
宛先アクションの設定
パイプラインを開始する前に、SQL Server内のスキーマが新規作成された空の状態であることを確認してください。 これにより、初回同期中のエラーを防ぎ、パイプラインが競合なしで送信先テーブルを作成できるようになります。
宛先アプリのターゲットテーブルにデータをロードアクションをクリックします。 このアクションでは、パイプラインが宛先でデータをレプリケートする方法を定義します。
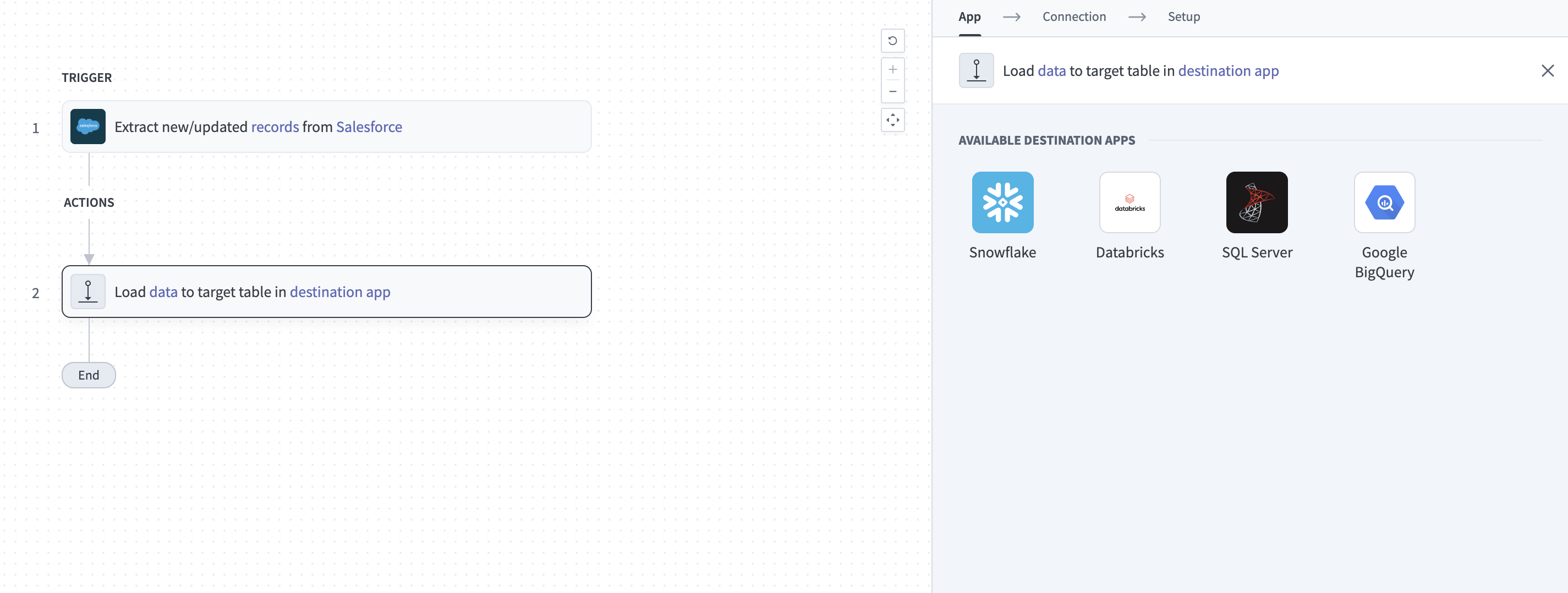 宛先アプリのターゲットテーブルにデータをロードアクションの設定
宛先アプリのターゲットテーブルにデータをロードアクションの設定
使用可能なソースアプリのリストからSQL Serverを選択します。
このパイプラインで使用するSQL Serverコネクションを選択します。 または、+ 新規コネクションをクリックして新しいコネクションを作成します。
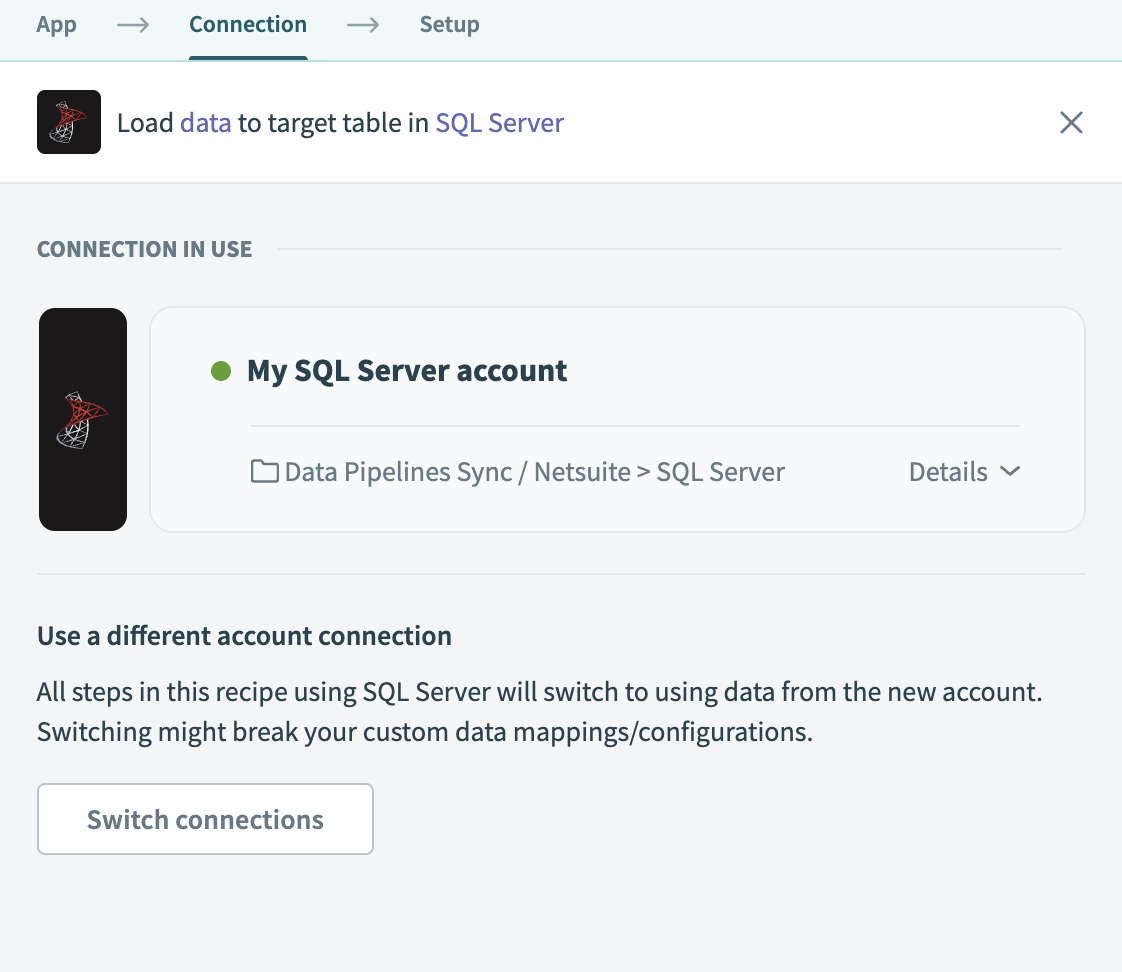 SQL Serverコネクションを選択
SQL Serverコネクションを選択
宛先アプリのターゲットテーブルにデータをロードアクションは、ソースからSQL Serverにオブジェクトスキーマを自動的にレプリケートします。 明示的なフィールドマッピングは不要です。
Workatoパイプラインは、ソーススキーマに基づいて送信先テーブルを自動的に作成します。 パイプラインは、データレプリケーションと更新操作をサポートするためにステージと一時テーブルも作成します。
保存を選択してパイプラインを保存します。
識別子の処理
SQL Serverは、引用符で囲まれていない識別子を大文字と小文字を区別しないものとして扱い、デフォルトで大文字として保存します。 Workatoパイプラインは、次のルールを適用してソース列名を有効なSQL Server識別子に変換します:
- カラム名は大文字に変換されます
$、スペース、ダッシュなどの特殊文字はアンダースコア(_)に置き換えられます- 特殊文字と予約語をサポートするため、識別子は角かっこで囲まれます
これにより、SQL Serverのテーブル作成およびクエリ動作との互換性が確保されます。
例
次のソーステーブル構造:
| ソースオブジェクト | ソースフィールド |
|---|---|
Account | $Name$, Created Date, Limit |
SQL Serverに作成される次のテーブルになります:
CREATE TABLE [ACCOUNT] ([_NAME_], [CREATED_DATE], [LIMIT])引用符で囲まれていないクエリでは、大文字と小文字を区別せずに列を参照できます:
SELECT created_date FROM account;角かっこで囲まれたクエリは、正確な識別子形式と一致する必要があります:
SELECT [_NAME_] FROM [ACCOUNT];最終更新日: