Sample use case - Data enrichment
Before you send data extracted from a source to a destination, there are often requirements to enrich the data with additional information from one or many sources. As the volume of the data grows, it becomes challenging to temporarily store and enrich the data and then load it to the destination.
SQL Transformations provides users the ability to pipeline any number of data sources and work with large volumes of data easily. Users can merge/aggregate data across files with SQL join operations and enrich incoming data with additional information, perform manipulations on the fly, and send it to any destination or store it within Workato FileStorage.
Sample recipe: Fetch opportunities from Salesforce, enrich the fetched data and send it to SFTP server
Consider the following scenario:
A company must extract all opportunity information from Salesforce in bulk, enrich it with additional product details, including cost, price, and specific region details, and send the enriched data to a partner file system in an external SFTP server.
With SQL Transformations, you can easily perform these complex processes in just five steps!
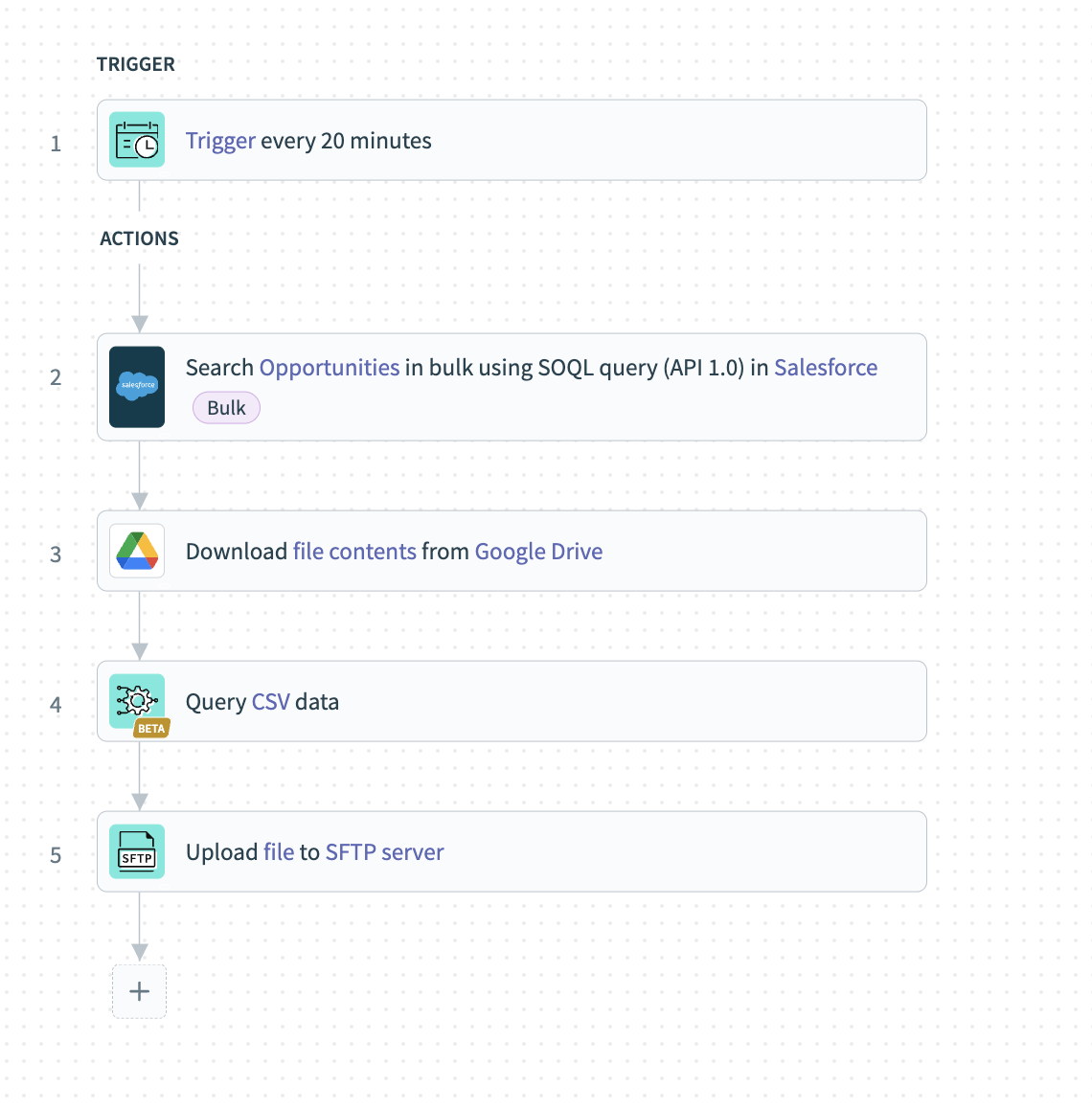
Set up a scheduler trigger that runs at a frequency you specify.
Set up the bulk action in Salesforce that can fetch all required opportunity records in bulk as a CSV content.
If the data you plan to use for enrichment is available at different sources, including Google Drive, you use download actions to fetch those contents as well.
Set up the Query CSV action from the SQL Transformations connector. During this step you can pipeline in the data from all the different sources and write a query that can enrich the opportunities with the additional data.
In the final step, Workato sends the data to the destination, which is the SFTP server.
How to leverage SQL Transformations for data enrichment
This section describes how to set up different sections of the Query CSV action, enabling you to leverage SQL Transformations for data enrichment.
Follow along
See this recipe link to follow along and modify a sample recipe to suit your own workflow.
Data Source setup
Connect the different data sources on which SQL Transformations performs the query. In this example, there are three different data sources.
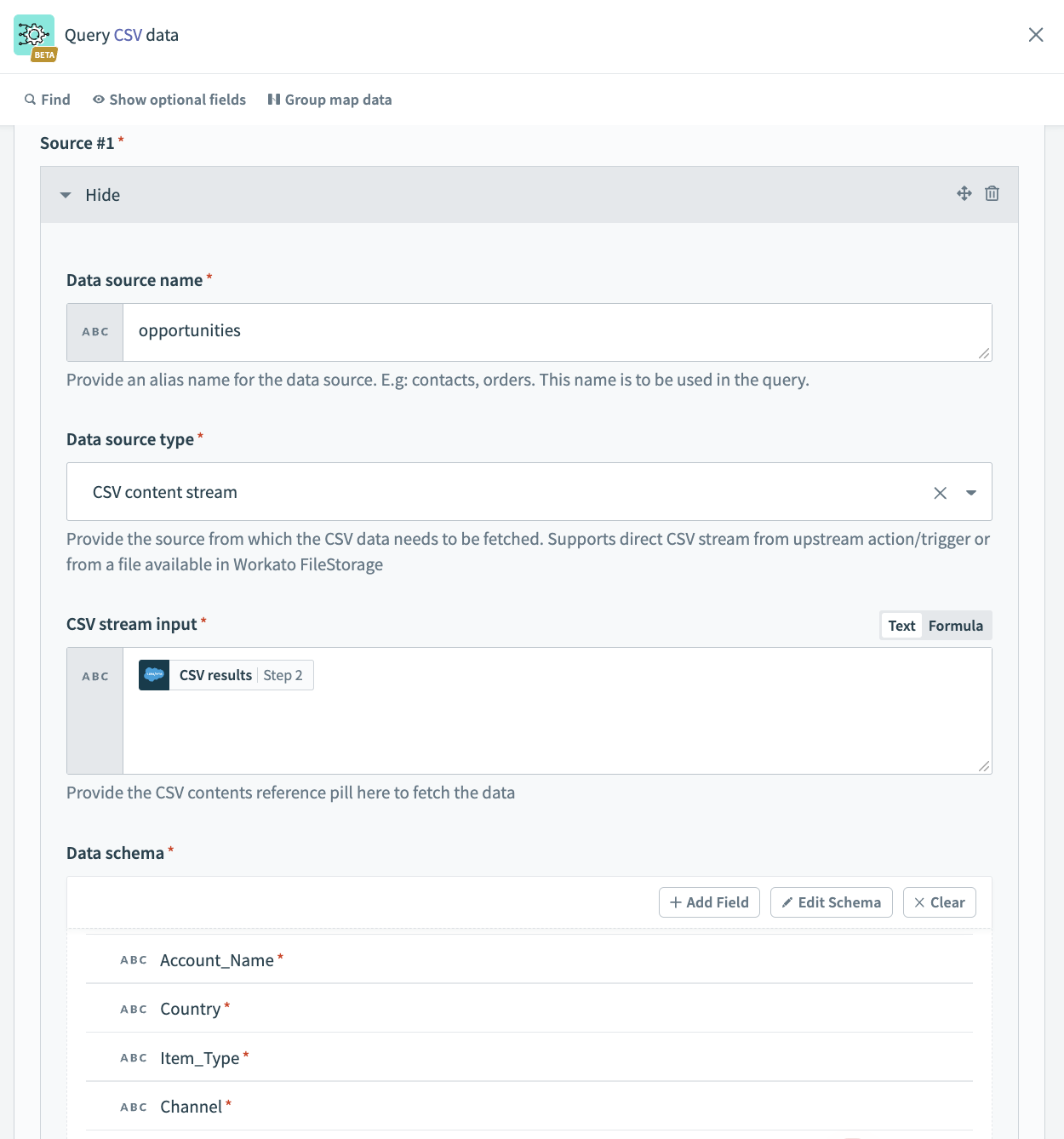
To connect Source #1, fill in the following fields. In our example, Source #1 is the incoming extract from an on-prem system.
Data source name
Give a meaningful name for the Data source name, for example contacts_extract.
Data source type
Select the Data source type. In our example, this is CSV content stream.
CSV stream input
After you set the data source as CSV content stream, you can now set the CSV stream input. This is where you pass the file contents coming from the on-prem files trigger.
Data schema
Set the Data schema. You can do this easily by importing a CSV file containing a few sample contacts data.
Ignore CSV header row
This allow users to specify whether the incoming data has a heading column that must be ignored and not considered as part of the data.
Column delimiter
Select the delimiter used in the CSV file to separate columns.. Available options include a , (comma), ; (semicolon), and more.
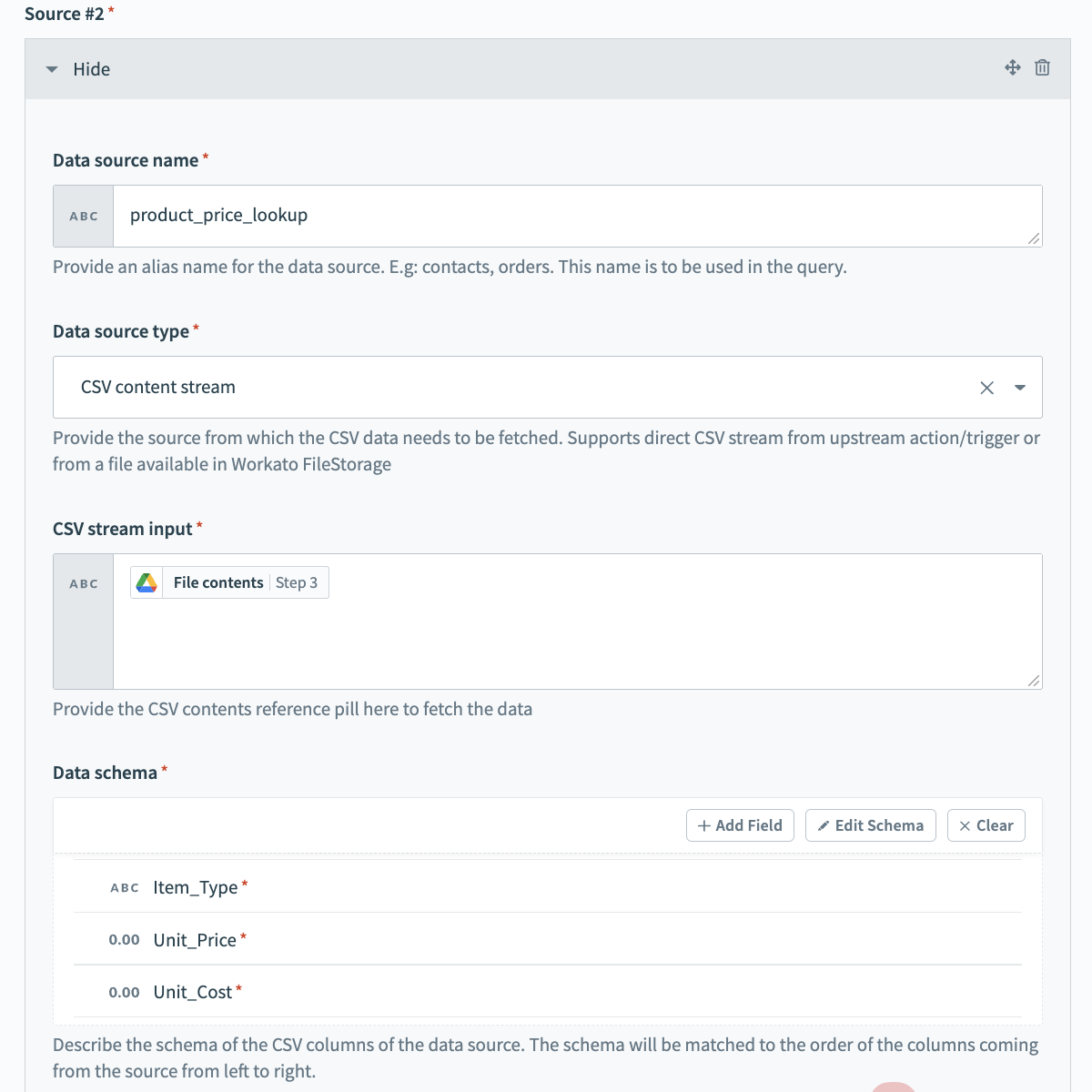
To connect Source #2, fill in the following fields. This is the source that points to the product price list data, which is used to enrich the data extracted from the source.
Data source name
Give a meaningful name for the Data source name, for example product_price_lookup.
Data source type
Select the Data source type. In our example, this is CSV content stream.
CSV stream input
Provide the CSV reference datapill to fetch the data. Our example uses contents from a Google drive download action.
Data schema
Set the Data schema. You can do this easily by importing a CSV file containing a few sample contacts data.
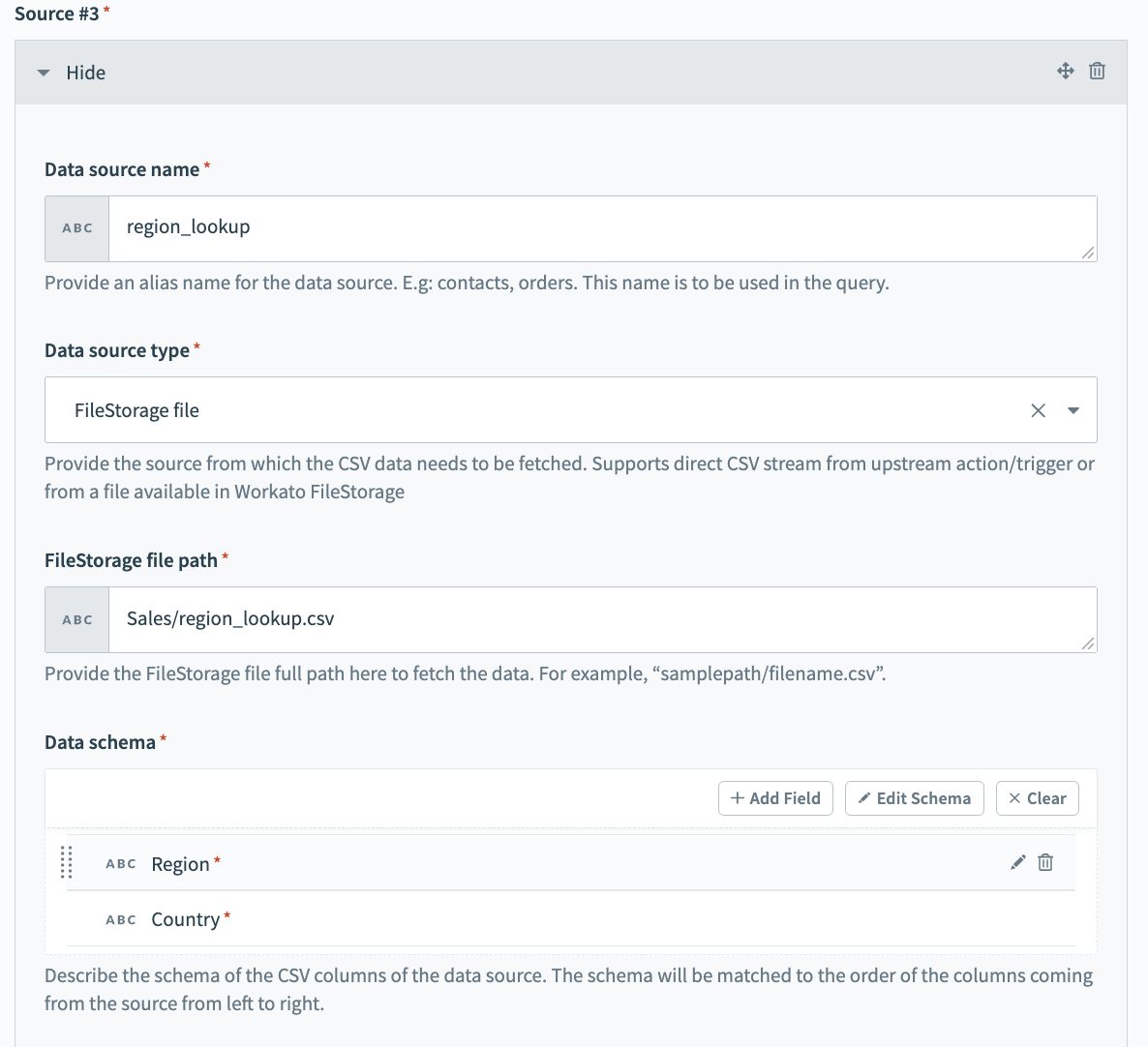
Configure Source #3.
In this step, our example fetches specific region details which we plan to use to enrich the opportunities data. Because we plan to reuse this data quite often and it does not change much, it is easy to store and handle this data using FileStorage, Workato's own internal persistent file storage system.
Configure the following fields:
Data source name
Give a meaningful name for the Data source name, for example region_lookup.
Data source type
Select the Data source type. In our example, this is FileStorage file.
FileStorage file path
Provide the path within FileStorage where the historical data file is available.
Data schema
Set the Data schema. You can do this easily by importing a CSV file containing a few sample contacts data. The schema is matched to the order of the columns coming from the source from left to right.
Query setup
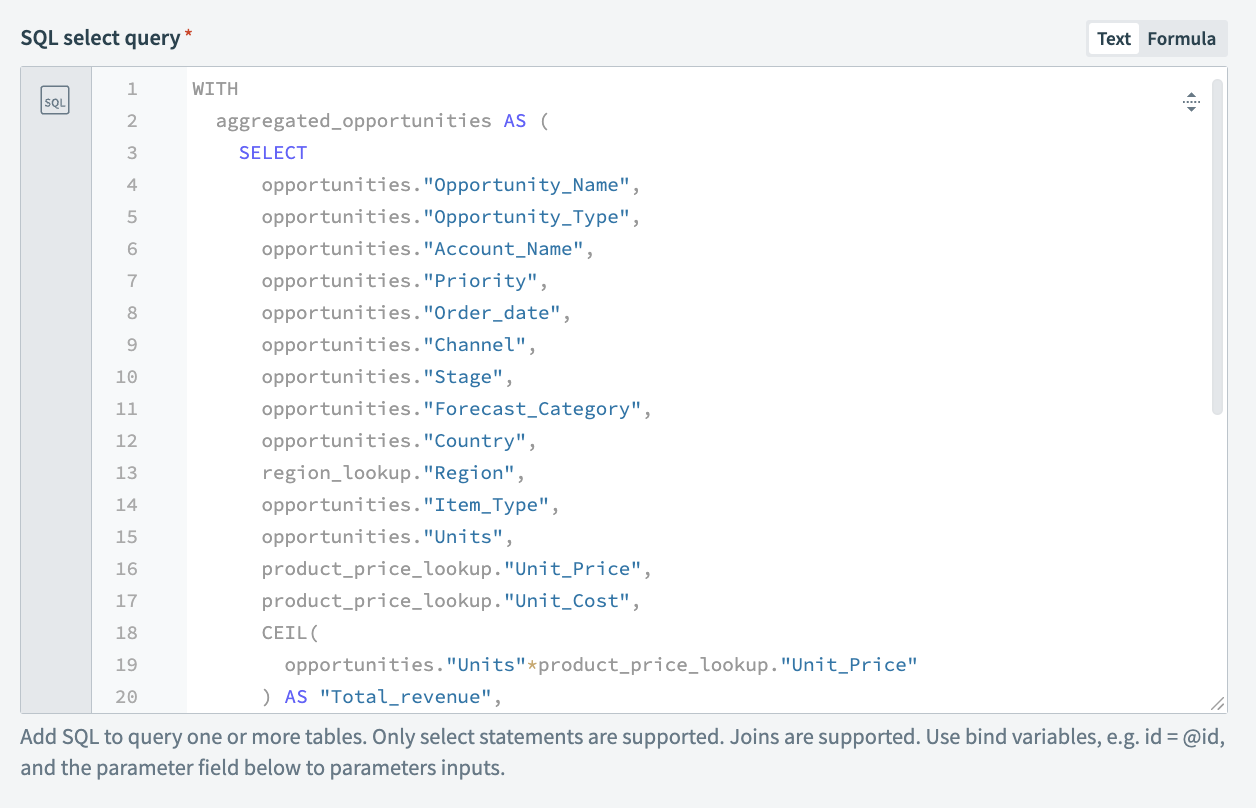
Next, set up the query that works on the data sources and produces the transformed output. In this example, the query joins the data across all three data sources, and then calculates the total revenue, total cost, and total profit with the help of the product pricing data. Additionally, country and region details are also added by joining with the region_lookup data source. The WITH ... AS ... function helps write a subquery and use that data in the main query easily.
Output setup
Define the format of the output.
Our example sends the enriched records file to the SFTP server. Because our example sends the enriched records file to the SFTP server, we chose the output type as CSV contents stream. This means that we can pass the CSV contents output datapill from Query CSV data action into the contents input section of the SFTP upload file action, and the contents stream automatically from Query CSV action to SFTP server. Also, similar to data source setup, here we have the options to choose what delimiter to use in the output CSV content, and whether to include a column header.
Fill in the following fields:
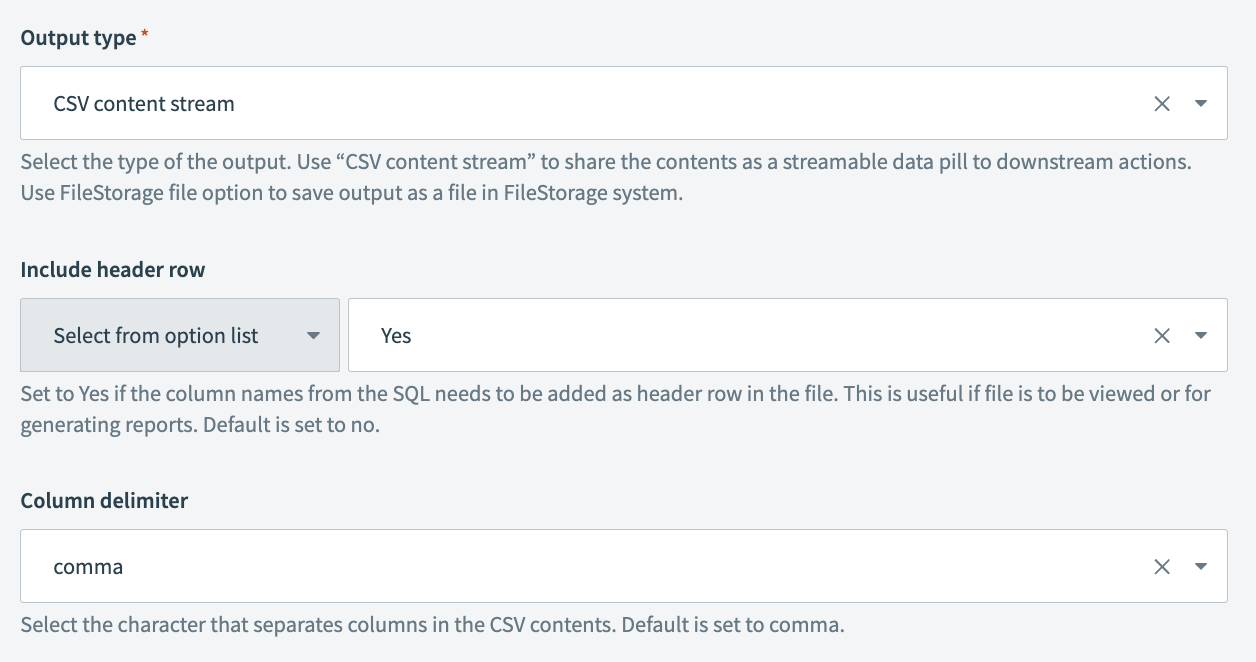
Output type
Select the type of the output. Use CSV content stream to share the contents as a streamable datapill to downstream actions.
Include header row
Set to Yes if the column names from the data must be added as header rows in the file. This is useful if you plan to use the file for generating reports. The default value is No.
Column delimiter
Select the delimiter used in the CSV file to separate columns. Available options include a , (comma), ; (semicolon), and more.
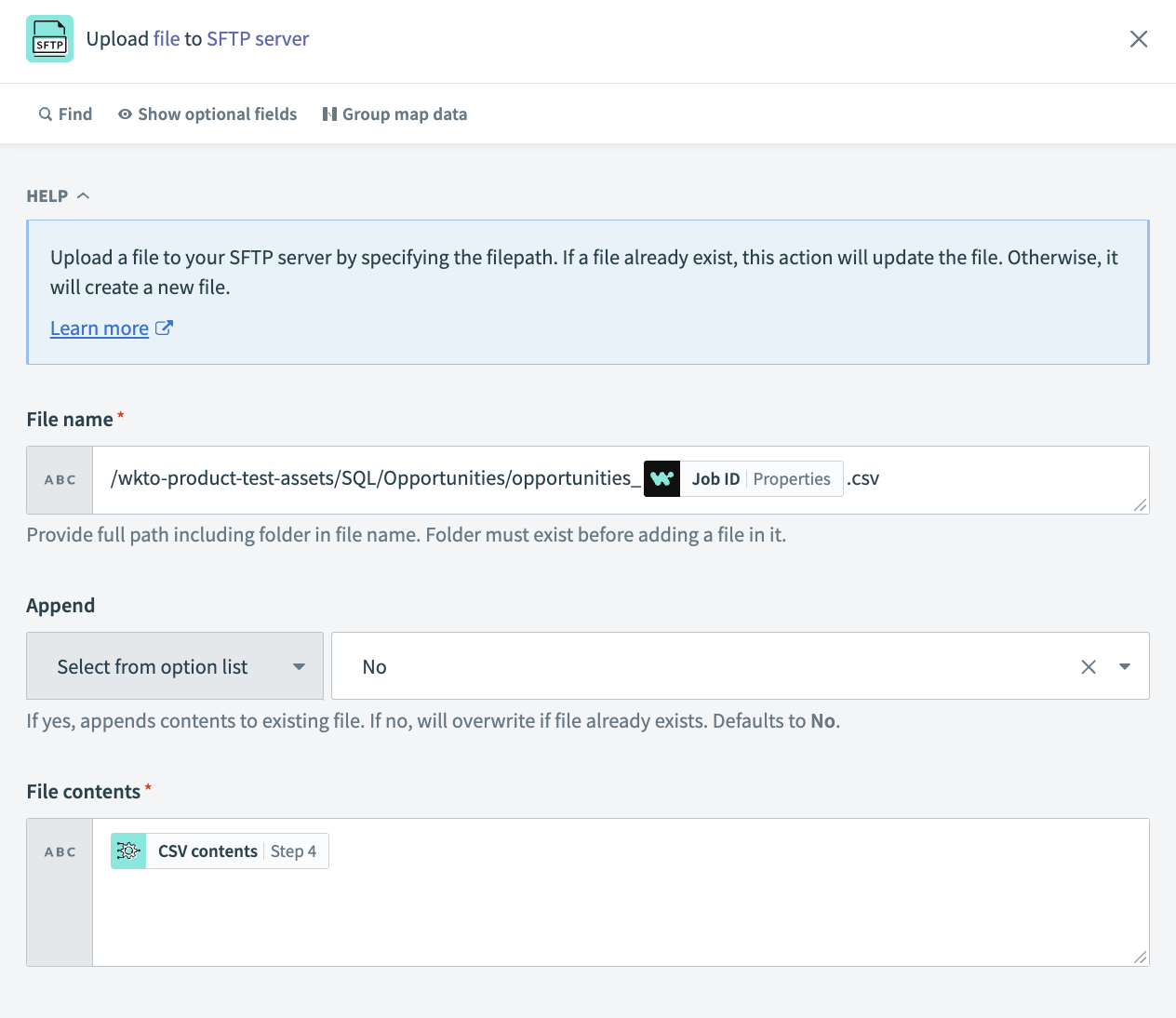
Select the Upload file to SFTP action.
Fill in the following fields:
File name
Provide the full path, including the folder. The folder must exist before you add a file to it.
Append
If Yes, appends contents to existing file. If No, overwrites if the file already exists. Defaults to No.
File contents
The file contents you plan to upload. Pass the CSV contents datapill from Step 4 Query CSV data action.
Read next
Sample use cases
To view more sample use cases, read the following guides:
Last updated: