# サンプルユースケース - データエンリッチメント
送信元から抽出されたデータを宛先に送信する前に、しばしば、1つまたは複数のソースから追加情報を用いてデータを拡充する必要があります。データの量が増えるにつれ、データを一時的に保存し、拡充してから宛先にロードすることは困難になります。
SQL変換は、任意の数のデータソースをパイプライン化し、大量のデータを容易に扱う能力をユーザーに提供します。ユーザーは、SQL結合操作を使用してファイル間のデータを結合/集約し、受信データを追加情報で拡充し、その場で操作を行い、任意の宛先に送信するか、WorkatoのFileStorage内に保存することができます。
# サンプルレシピ: Salesforceから商談を取得し、取得したデータを拡充してSFTPサーバーに送信する
次のシナリオを考えてみましょう:
会社は、Salesforceからすべての商談情報を一括で抽出し、コスト、価格、特定の地域の詳細を含む追加の製品詳細でそれを拡充し、拡充されたデータを外部のSFTPサーバーにあるパートナーファイルシステムに送信する必要があります。
SQL変換を使用すれば、これらの複雑なプロセスをわずか5つのステップで簡単に実行できます!
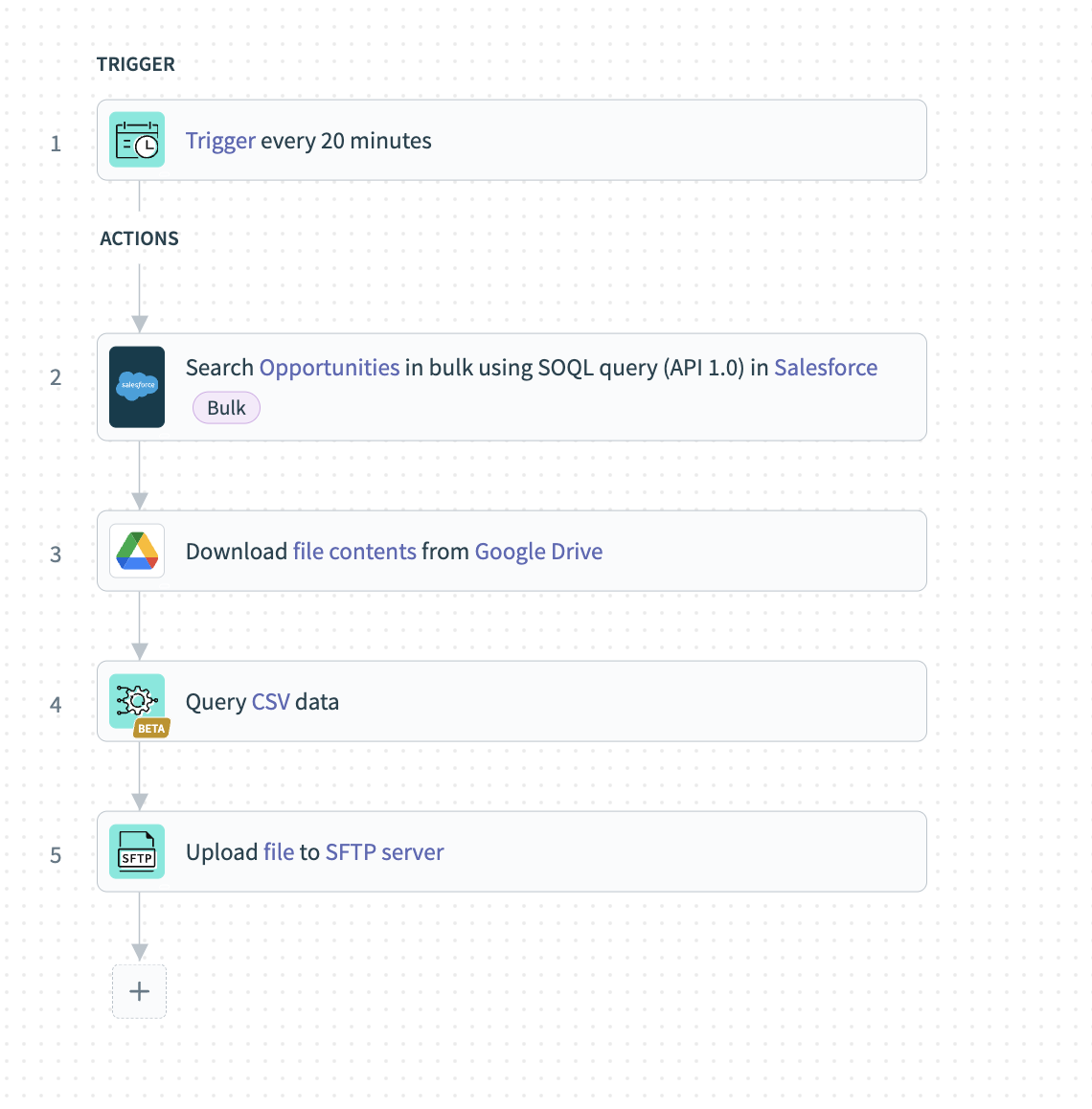
指定した頻度で実行されるスケジューラートリガーを設定します。
Salesforceで一括アクションを設定し、必要なすべての商談レコードをCSVコンテンツとして一括取得できるようにします。
拡充に使用する予定のデータがGoogleドライブを含む異なるソースで利用可能な場合、それらのコンテンツを取得するためにダウンロードアクションを使用します。
SQL変換コネクタからQuery CSVアクションを設定します。このステップでは、すべての異なるソースからのデータをパイプライン化し、追加データで商談を拡充できるクエリを作成できます。
最後のステップでは、Workatoがデータを宛先であるSFTPサーバーに送信します。
# データエンリッチメントのためにSQL変換を活用する方法
このセクションでは、Query CSVアクションの異なるセクションを設定する方法について説明します。これにより、SQL変換をデータエンリッチメントに活用できます。
実践ガイド
このレシピリンクを参照して、サンプルレシピを自分のワークフローに合わせて修正しながら進めてください。
# データソースの設定
SQL変換がクエリを実行する異なるデータソースを接続します。この例では、3つの異なるデータソースがあります。
Source #1を接続するには、次のフィールドに入力します。この例では、Source #1はオンプレミスシステムからの受信抽出です。
- Data source name
- Data source nameに意味のある名前を付けます。例えば、contacts_extractなど。
- Data source type
- Data source typeを選択します。この例では、CSV content streamです。
- CSV stream input
- データソースをCSV content streamに設定した後、CSVストリーム入力を設定できます。ここで、オンプレミスファイルのトリガーからのファイルコンテンツを渡します。
- Data schema
- Data schemaを設定します。サンプルの連絡先データを含むCSVファイルをインポートすることで、これを簡単に行うことができます。
- Ignore CSV header row
- これにより、受信データにヘッダー行が含まれているかどうかを指定し、データの一部として考慮せずに無視できます。
- Column delimiter
- CSVファイルで列を区切るために使用されるデリミタを選択します。利用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
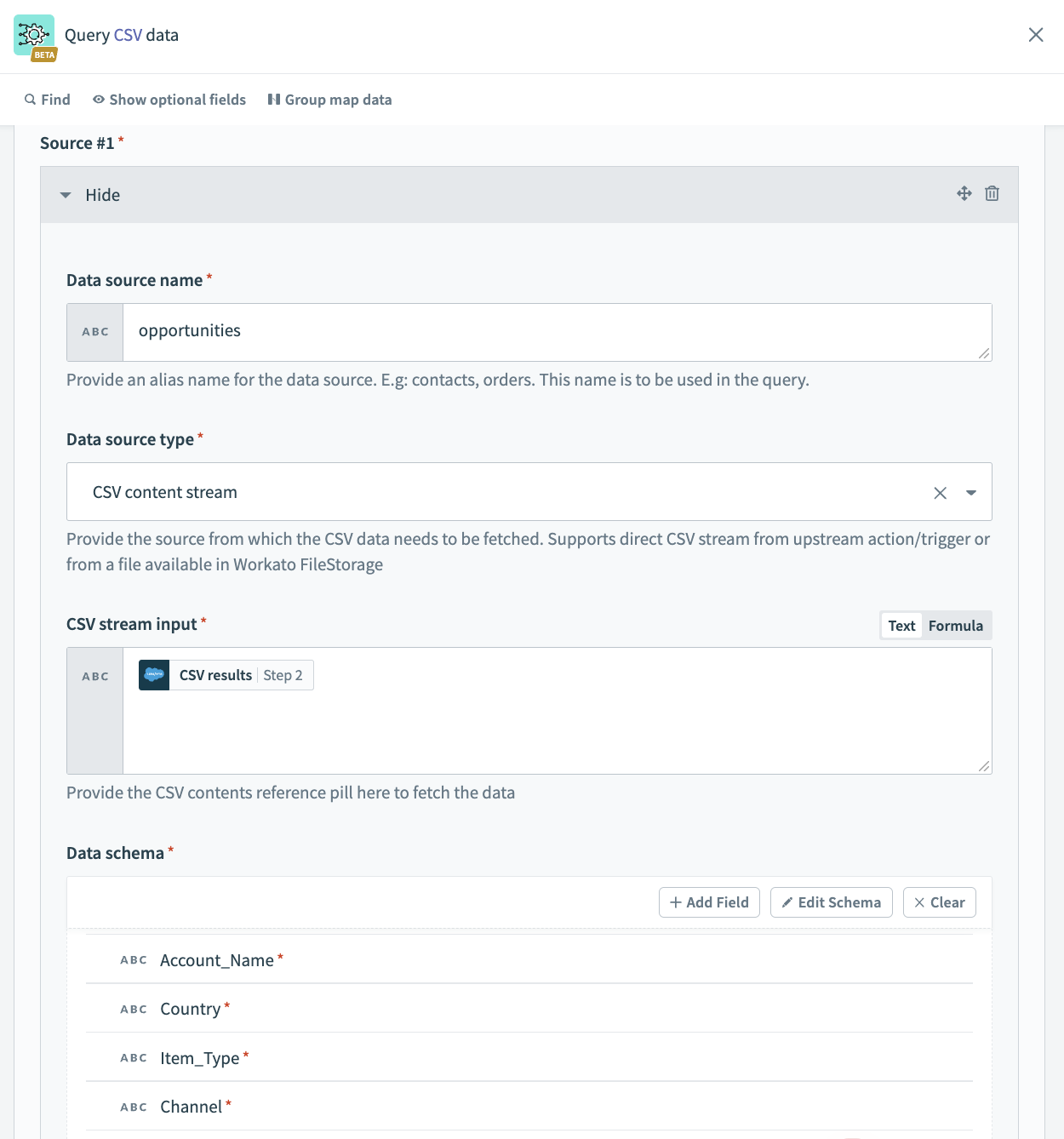
Source #2を接続するには、次のフィールドに入力します。これは、ソースから抽出されたデータを拡充するために使用される製品価格リストデータを指すソースです。
- Data source name
- Data source nameに意味のある名前を付けます。例えば、product_price_lookupなど。
- Data source type
- Data source typeを選択します。この例では、CSV content streamです。
- CSV stream input
- CSV参照データピルを提供してデータを取得します。この例では、Googleドライブのダウンロードアクションからのコンテンツを使用します。
- Data schema
- Data schemaを設定します。サンプルの連絡先データを含むCSVファイルをインポートすることで、これを簡単に行うことができます。
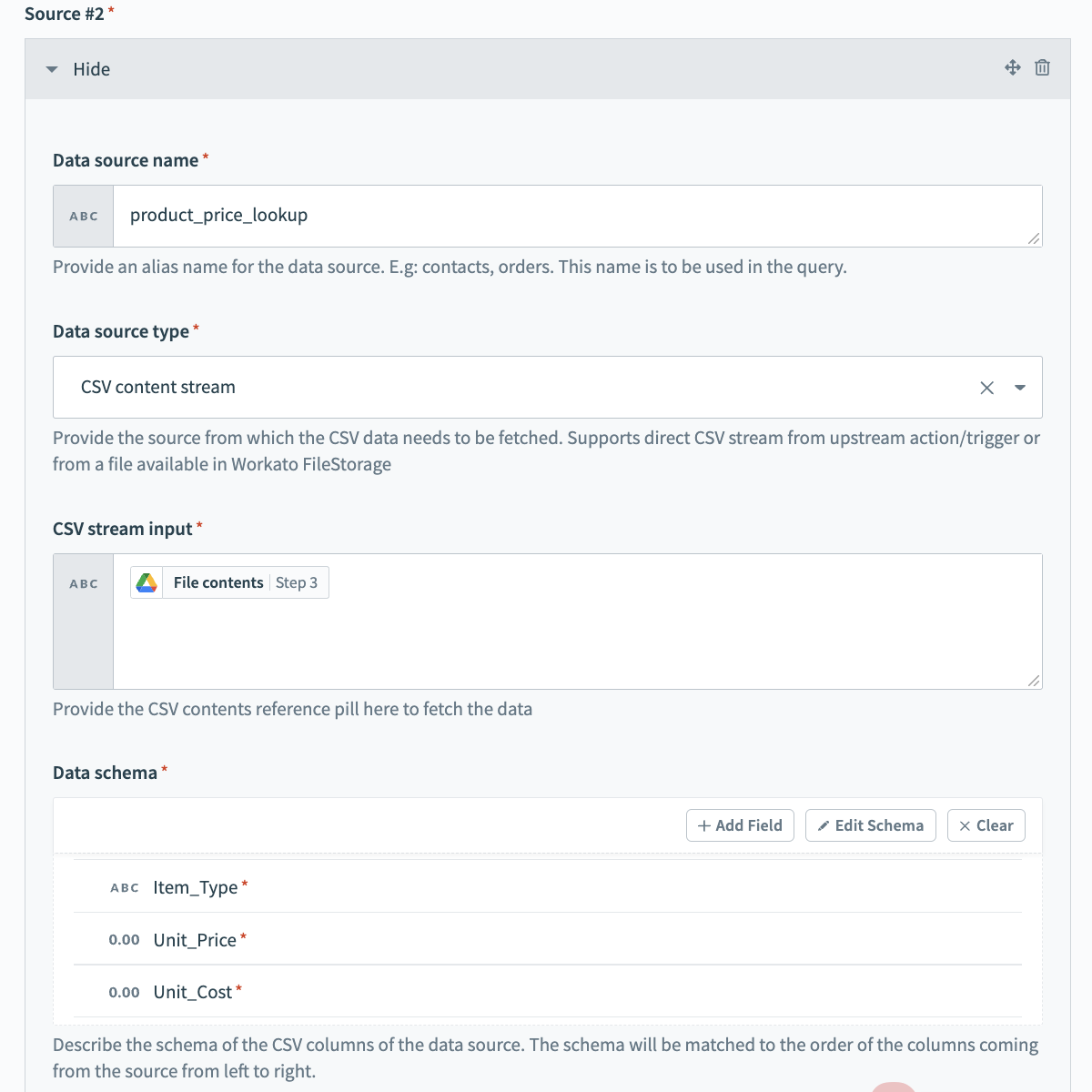
Source #3を設定します。
このステップでは、商談データを拡充するために使用する特定の地域の詳細を取得します。このデータを頻繁に再利用し、あまり変更されないため、Workatoの内部永続ファイルストレージシステムであるFileStorageを使用してこのデータを保存および処理することが容易です。
次のフィールドを設定します:
- Data source name
- Data source nameに意味のある名前を付けます。例えば、region_lookupなど。
- Data source type
- Data source typeを選択します。この例では、FileStorage fileです。
- FileStorage file path
- 履歴データファイルが存在するFileStorage内のパスを指定します。
- Data schema
- Data schemaを設定します。サンプルの連絡先データを含むCSVファイルをインポートすることで、これを簡単に行うことができます。スキーマは、ソースからの列の左から右の順序に一致します。
# クエリの設定
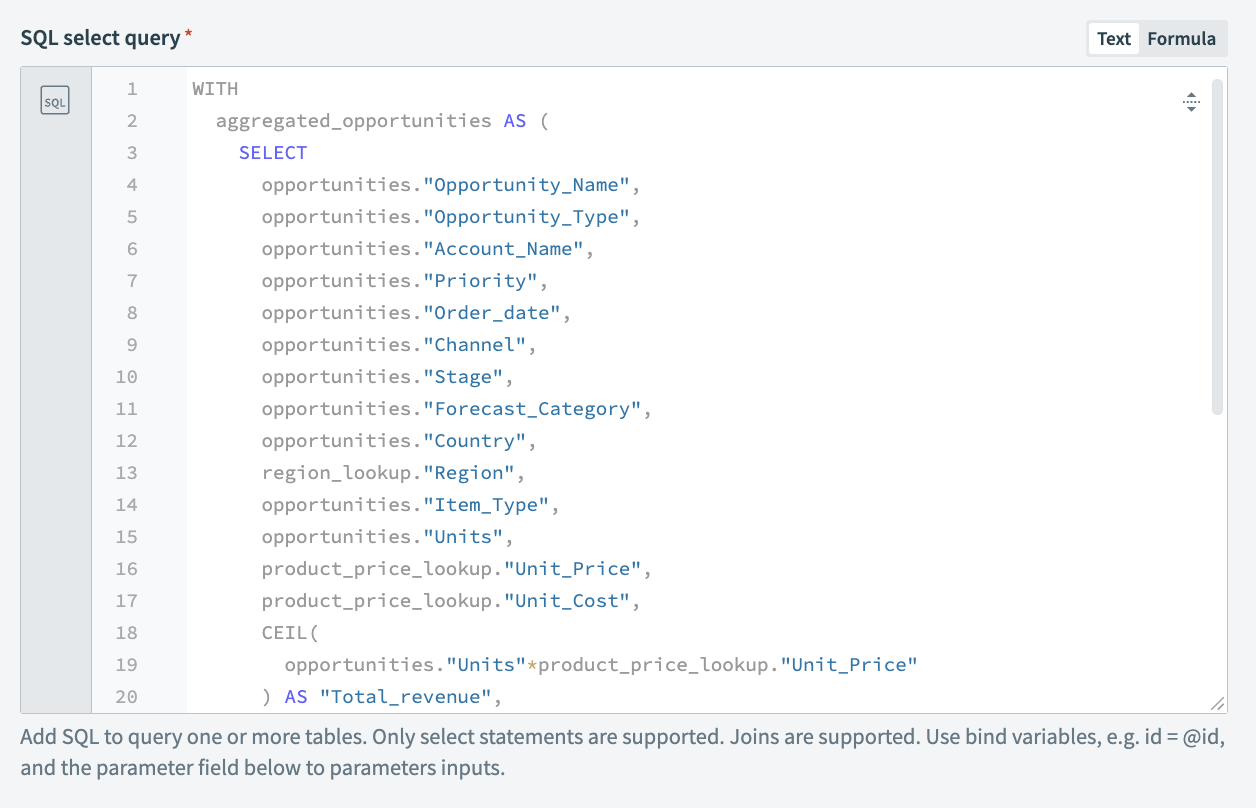
次に、データソース上で動作し、変換された出力を生成するクエリを設定します。この例では、クエリはすべてのデータソース間のデータを結合し、製品価格データの助けを借りて総収入、総コスト、総利益を計算します。さらに、region_lookupデータソースと結合することで、国および地域の詳細も追加されます。WITH ... AS ... 構文は、サブクエリを記述し、そのデータをメインクエリで簡単に使用するのに役立ちます。
# 出力の設定
出力の形式を定義します。
この例では、拡充されたレコードファイルをSFTPサーバーに送信します。そのため、出力タイプとしてCSV contents streamを選択しました。これは、Query CSV dataアクションからの「CSV contents」出力データピルをSFTPファイルアップロードアクションのコンテンツ入力セクションに渡すことができ、Query CSV actionからSFTPサーバーにコンテンツストリームが自動的に送信されることを意味します。また、データソースの設定と同様に、出力CSVコンテンツで使用するデリミタや列ヘッダーを含めるかどうかを選択できます。
次のフィールドに入力します:
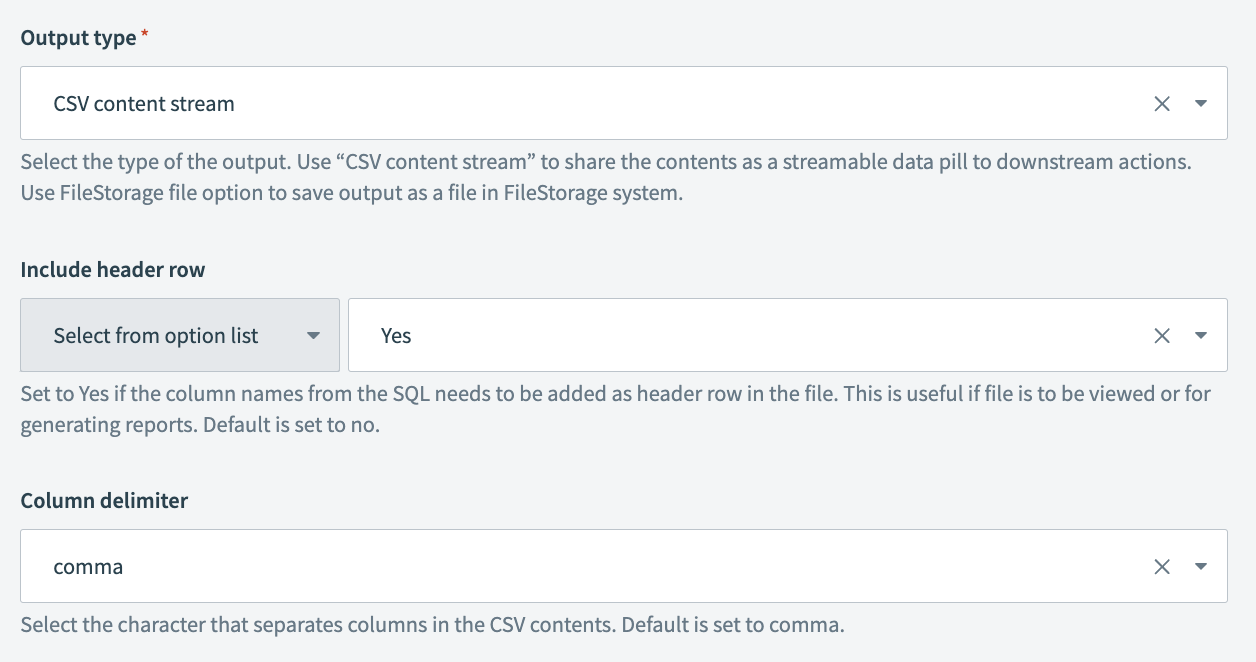
- Output type
- 出力のタイプを選択します。コンテンツをストリーム可能なデータピルとして下流のアクションと共有するには、CSV content streamを使用します。
- Include header row
- ファイルにデータからの列名をヘッダー行として追加する場合はYesに設定します。これは、ファイルを使用してレポートを生成する場合に便利です。デフォルト値はNoです。
- Column delimiter
- CSVファイルで列を分割するために使用されるデリミタを選択します。利用可能なオプションには、,(カンマ)、;(セミコロン)などがあります。
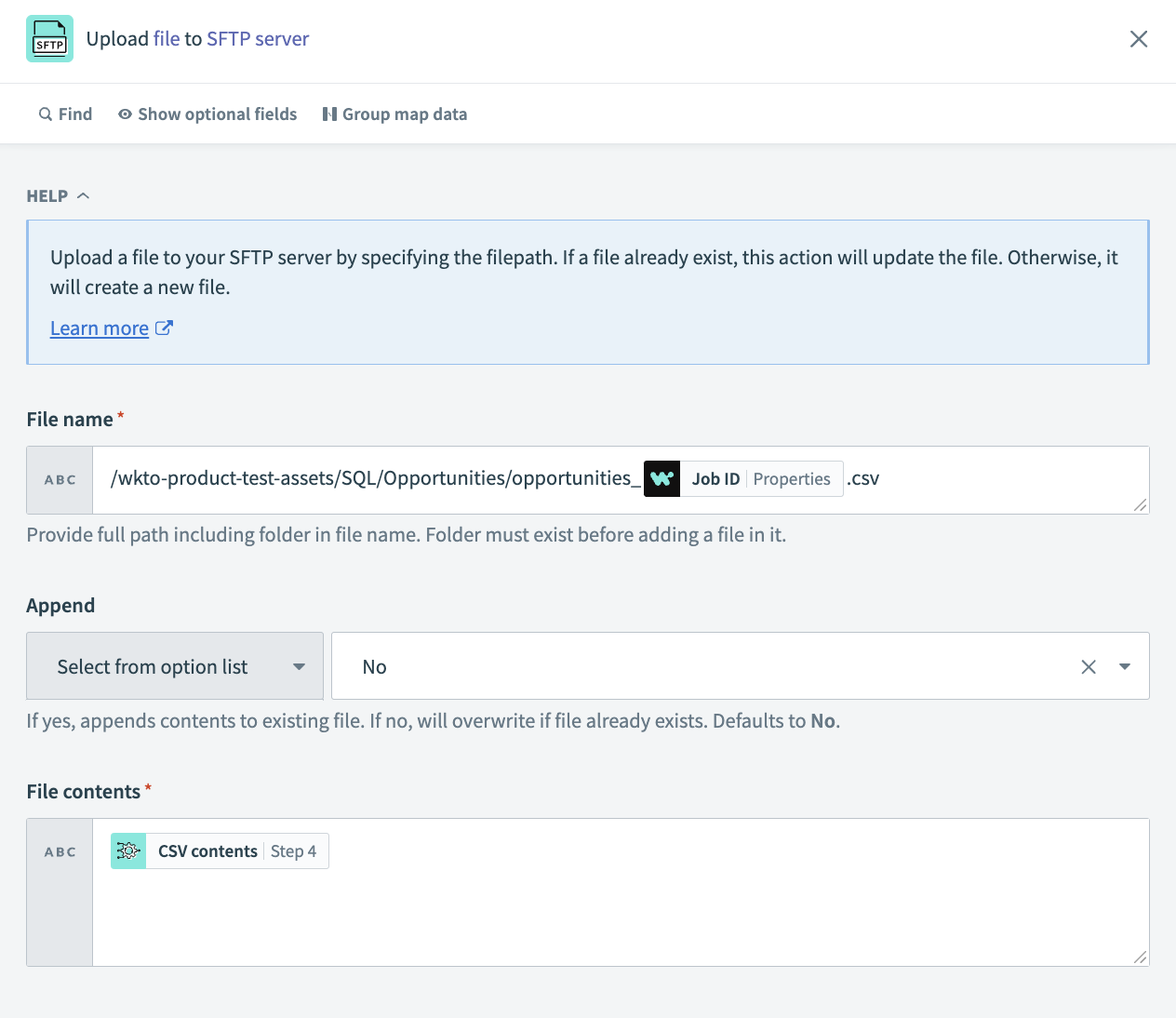
Upload file to SFTPアクションを選択します。
次のフィールドに入力します:
- File name
- フォルダを含むフルパスを指定します。フォルダはファイルを追加する前に存在している必要があります。
- Append
- Yesの場合、既存のファイルにコンテンツを追加します。Noの場合、ファイルが既に存在する場合は上書きします。デフォルトはNoです。
- File contents
- アップロードするファイルのコンテンツです。Step 4 Query CSV dataアクションからのCVS contentsデータピルを渡します。
# 次を読む
Last updated: 2024/12/18 21:44:08