テキストプロンプトアクション
このアクションは、OpenAIの強力な言語モデルを使用して、指定されたプロンプトに対する補完を生成します。単純にプロンプトと必要なパラメータを提供するだけで、アクションは1つまたは複数の予測された補完を返します。このアクションを使用して、テキストの自動補完、質問への回答、新しいコンテンツの生成を簡単に行うことができます。
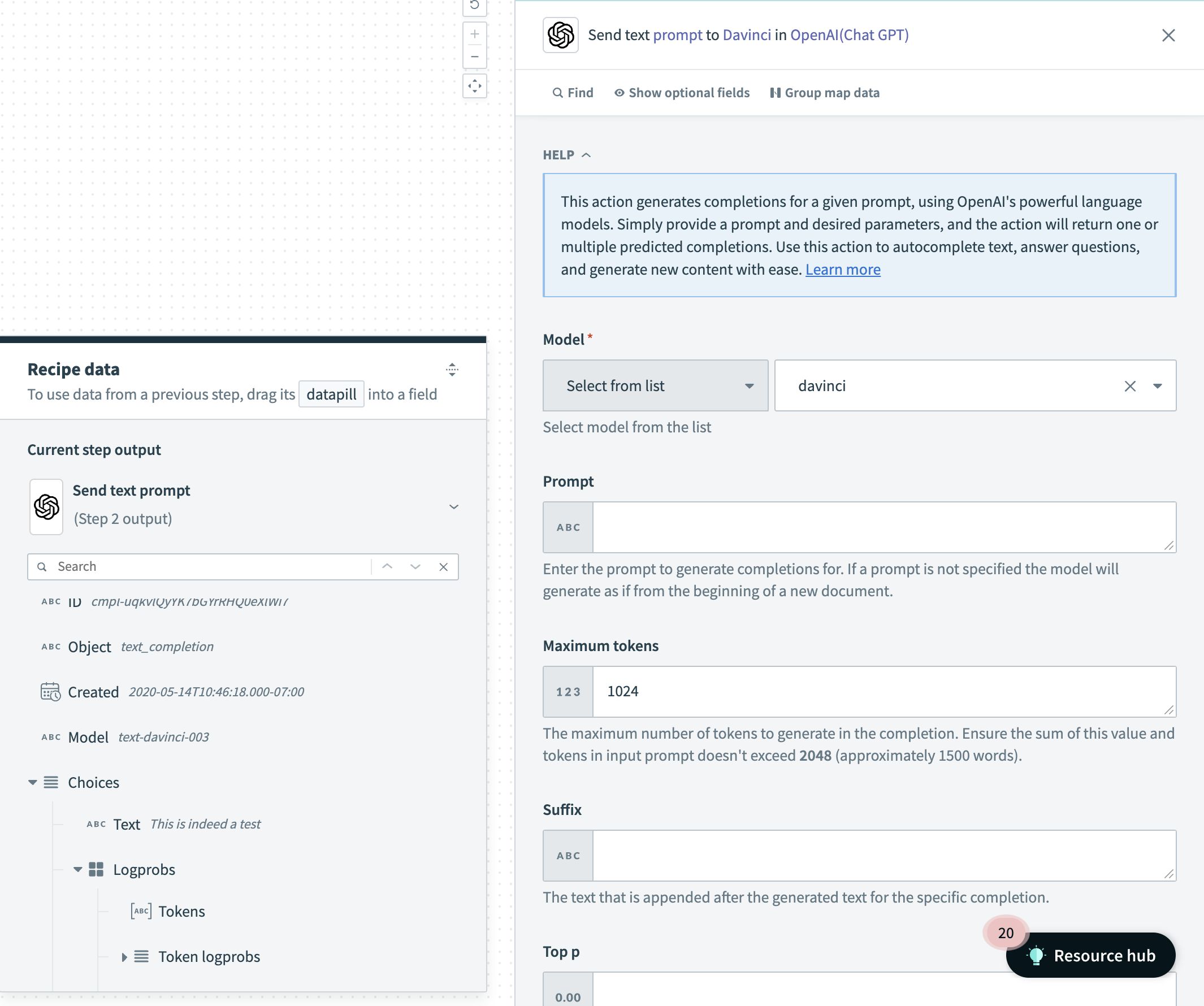 テキストプロンプトアクション
テキストプロンプトアクション
入力
| フィールド | 説明 |
|---|---|
| Model | テキストプロンプトを送信するOpenAIモデルを選択します。 |
| Prompt | 補完を生成するためのプロンプト。プロンプトが指定されていない場合、モデルは新しいドキュメントの開始時として生成します。複数の文字列(またはトークン)に対して応答を作成する場合は、関連する情報をデータピルとして入力してください。フォーマットの詳細については、こちらを参照してください。 |
| Maximum Tokens | 補完で生成するトークンの最大数。プロンプトのトークン数とここでの値の合計は、モデルのコンテキスト長を超えることはできません。ほとんどのモデルのコンテキスト長は2048トークンです(最新のモデルは4096をサポートしています)。 |
| Suffix | 挿入されたテキストの補完の後に続くサフィックス。 |
| Top p | 補完の多様性を制御するために、0から1の値を入力します。値が高いほど、より多様な応答が生成されます。これと温度の両方を使用することはお勧めしません。詳細はこちらをご覧ください。 |
| Temperature | 補完のランダム性を制御するために、0から2の値を入力します。値が高いほど、出力はよりランダムになり、値が低いほど、より焦点を絞った決定論的な出力になります。これとtop pの両方を使用することはお勧めしません。詳細はこちらをご覧ください。 |
| Number of completions | プロンプトに対して生成する補完の数。 |
| Log probabilities | 次のn個(この値によって決まる)の最も可能性の高いトークンと選択されたトークンのログ確率を取得するための数値を入力します。詳細はこちらをご覧ください。 |
| Stop phrase | 生成を終了する特定の停止フレーズ。たとえば、停止フレーズをピリオド(.)に設定すると、モデルはピリオドに到達するまでテキストを生成し、その後停止します。生成されるテキストの量を制御するために使用します。 |
| Presence penalty | -2.0から2.0の数値。正の値は、テキストに現れるかどうかに基づいて新しいトークンにペナルティを与え、モデルが新しいトピックについて話す可能性を高めます。 |
| Frequency penalty | -2.0から2.0の数値。正の値は、テキストにおける既存の頻度に基づいて新しいトークンにペナルティを与え、モデルが同じ行を繰り返す可能性を低下させます。 |
| Best of | 送信前に実際に生成される結果の数を制御します。なお、補完の数はここで入力した値より少なくすることはできません。 |
| ロジットバイアス | トークンとそれぞれの特定のトークンのロジットの変化を含むJSONを入力します。たとえば、{"50256": -100}を渡すことで、<|endoftext|>トークンの生成を防ぐことができます。詳細はこちらをご覧ください。 |
| ユーザー | エンドユーザーを表す一意の識別子。OpenAIがモニタリングおよび不正使用の検出を行うのに役立ちます。 |
出力
| フィールド | 説明 | |
|---|---|---|
| Created | 応答が生成された日時スタンプ。 | |
| ID | 送受信された特定のリクエストと応答を示す一意の識別子。 | |
| Model | テキスト補完の生成に使用されたモデル。 | |
| Choices | Text | 指定された入力に対するモデルの応答。 |
| Finish reason | モデルがテキストの生成を停止した理由。多くの場合、ストップワードまたは長さによるものです。 | |
| Logprobs | トークンとそれに対応する確率を含むオブジェクト。たとえば、ログ確率が5に設定されている場合、最も可能性の高い5つのトークンのリストが返されます。応答には常にサンプルされたトークンのログ確率が含まれるため、応答にはlogprobs+1までの要素が含まれる場合があります。 | |
| Best choice | OpenAIが確率的に最適な選択と見なす応答を含みます。 | |
| Usage | Prompt tokens | プロンプトによって使用されるトークンの数。 |
| Completions tokens | テキストの補完に使用されるトークンの数。 | |
| Total tokens | プロンプトと応答によって使用されるトークンの総数。 | |
Last updated: