Redshift
Amazon Redshiftは、標準SQLと既存のBusiness Intelligence(BI)ツールを使用して、すべてのデータを簡単かつコスト効率よく分析できる、高速で完全に管理されたデータウェアハウスです。
WorkatoでRedshiftに接続する方法
Redshiftコネクターは、基本認証を使用してRedshiftで認証します。 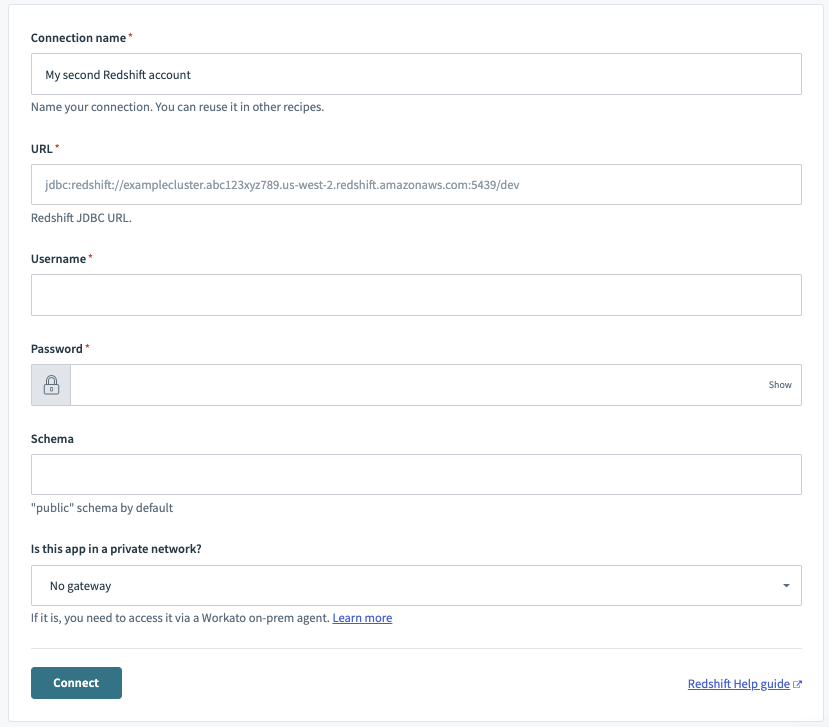
| フィールド | 説明 |
|---|---|
| コネクション名 | このRedshiftコネクションに、接続先のRedshiftインスタンスを識別する一意の名前を付けます。 |
| URL | Redshiftインスタンスの完全なJDBC URL。 例: jdbc:redshift://redshift-main.sample.us-east-2.redshift.amazonaws.com:5439/dev |
| ユーザー名 | Redshiftへの接続に使用するユーザー名。 |
| パスワード | Redshiftへの接続に使用するパスワード。 |
| スキーマ | 接続するRedshiftデータベース内のスキーマの名前。 デフォルトはpublicです。 |
| コネクションタイプ | データベースが直接コネクションを許可しないネットワークで実行されている場合は、オンプレミスグループを選択します。 接続を試みる前に、有効なオンプレミスエージェントがあることを確認してください。 詳細については、オンプレミス接続ガイドを参照してください。 |
接続に必要な権限
少なくとも、データベースユーザーアカウントには、コネクションで指定したデータベースに対するSELECT権限を付与する必要があります。
新しいデータベースユーザーworkatoを使用してRedshiftインスタンスに接続する場合は、次のクエリ例を使用できます。
まず、Workatoでの連携ユースケース専用の新しいユーザーを作成します。
CREATE USER workato PASSWORD 'password';次のステップでは、スキーマ内のcustomerテーブルへのアクセス権を付与します。 この例では、SELECTおよびINSERT権限のみを付与します。
GRANT SELECT,INSERT ON TABLE customer TO workato;最後に、このユーザーに必要な権限があることを確認します。 すべての権限付与を確認するクエリを実行します。
SELECT
u.usename,
t.schemaname||'.'||t.tablename AS "table",
has_table_privilege(u.usename,t.tablename,'select') AS "select",
has_table_privilege(u.usename,t.tablename,'insert') AS "insert",
has_table_privilege(u.usename,t.tablename,'update') AS "update",
has_table_privilege(u.usename,t.tablename,'delete') AS "delete"
FROM
pg_user u
CROSS JOIN
pg_tables t
WHERE
u.usename = 'workato'これにより、WorkatoでRedshiftコネクションを作成するための次の最小権限が返されます。
+---------+----------+--------+--------+--------+--------+
| usename | table | select | insert | update | delete |
+---------+----------+--------+--------+--------+--------+
| workato | customer | true | true | false | false |
+---------+----------+--------+--------+--------+--------+
2 rows in set (0.26 sec)Redshiftコネクターの使用
テーブルとビュー
Redshiftコネクターは、すべてのテーブルとビューで動作します。 これらは各トリガー/アクションのピックリストで使用できます。または、正確な名前を指定できます。
 ピックリストからテーブル/ビューを選択
ピックリストからテーブル/ビューを選択
 テキストフィールドに正確なテーブル/ビュー名を入力
テキストフィールドに正確なテーブル/ビュー名を入力
Redshiftでは、引用符で囲まれていない識別子は大文字と小文字を区別しません。 そのため、
SELECT ID FROM USERSは次と同等です
SELECT ID FROM usersただし、引用符で囲まれた識別子は大文字と小文字が区別されます。 したがって、
SELECT ID FROM "USERS"は次と同等ではありません
SELECT ID FROM "users"単一行と行のバッチ
Redshiftコネクターは、単一行またはバッチのいずれかでデータベースの読み取りまたは書き込みを実行できます。 バッチトリガー/アクションを使用する場合は、操作するバッチサイズを指定する必要があります。 バッチサイズには1~100の任意の数値を指定でき、最大バッチサイズは100です。
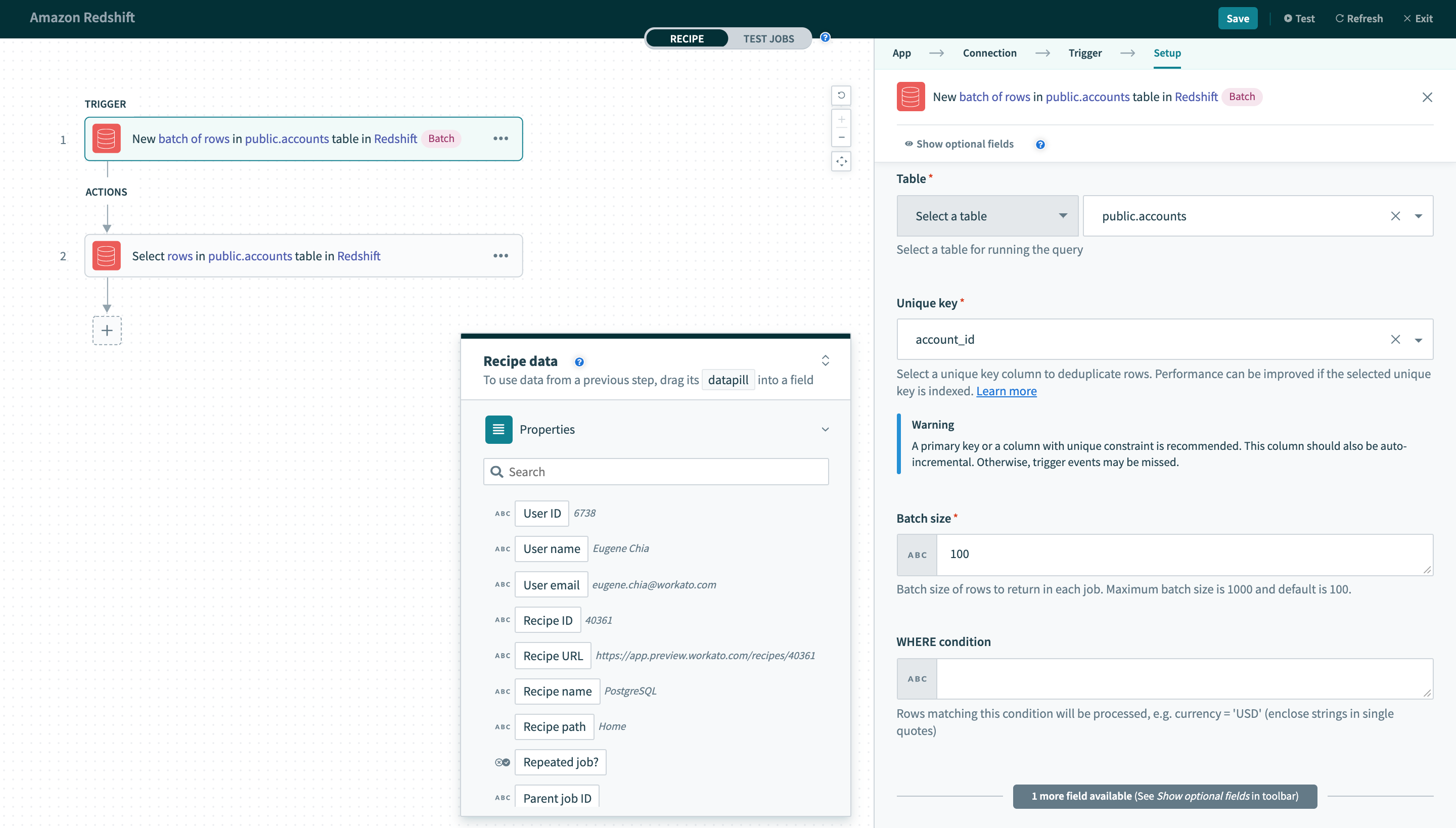 バッチトリガー入力
バッチトリガー入力
入力フィールドの違いに加えて、これら2種類の操作の出力にも違いがあります。 行を1つずつ処理するトリガーには、その単一行のデータをマッピングできる出力データツリーがあります。
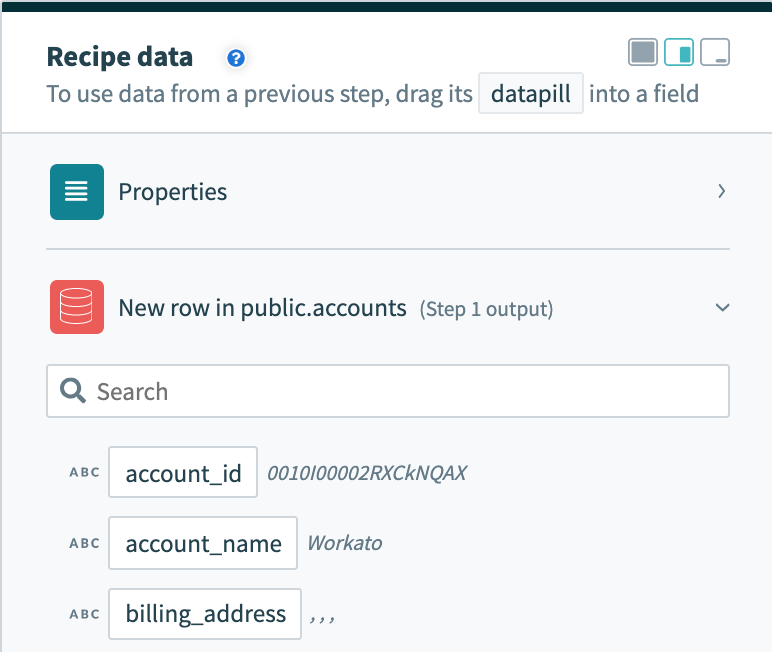 単一行の出力
単一行の出力
ただし、行をバッチで処理するトリガーは、それらを行の配列として出力します。 行データピルは、出力がそのバッチ内の各行のデータを含むリストであることを示します。
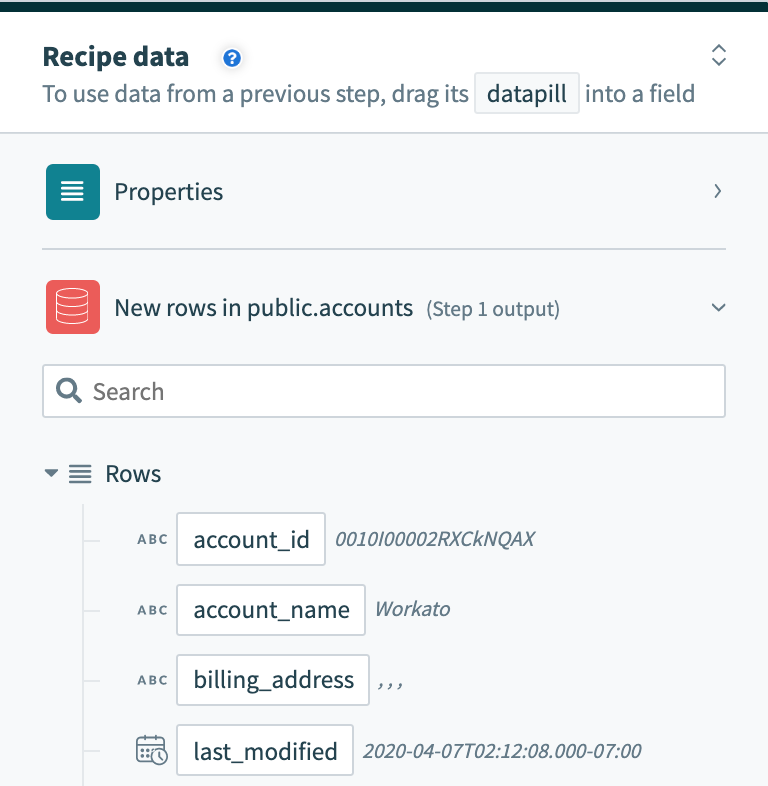 バッチトリガー出力
バッチトリガー出力
そのため、バッチトリガー/アクションの出力は異なる方法で処理する必要があります。 このレシピでは、usersテーブルの新しい行に対してバッチトリガーを使用します。 トリガーの出力は、Rowsデータピルをソースリストにマッピングする必要があるSalesforce一括更新アクションで使用されます。
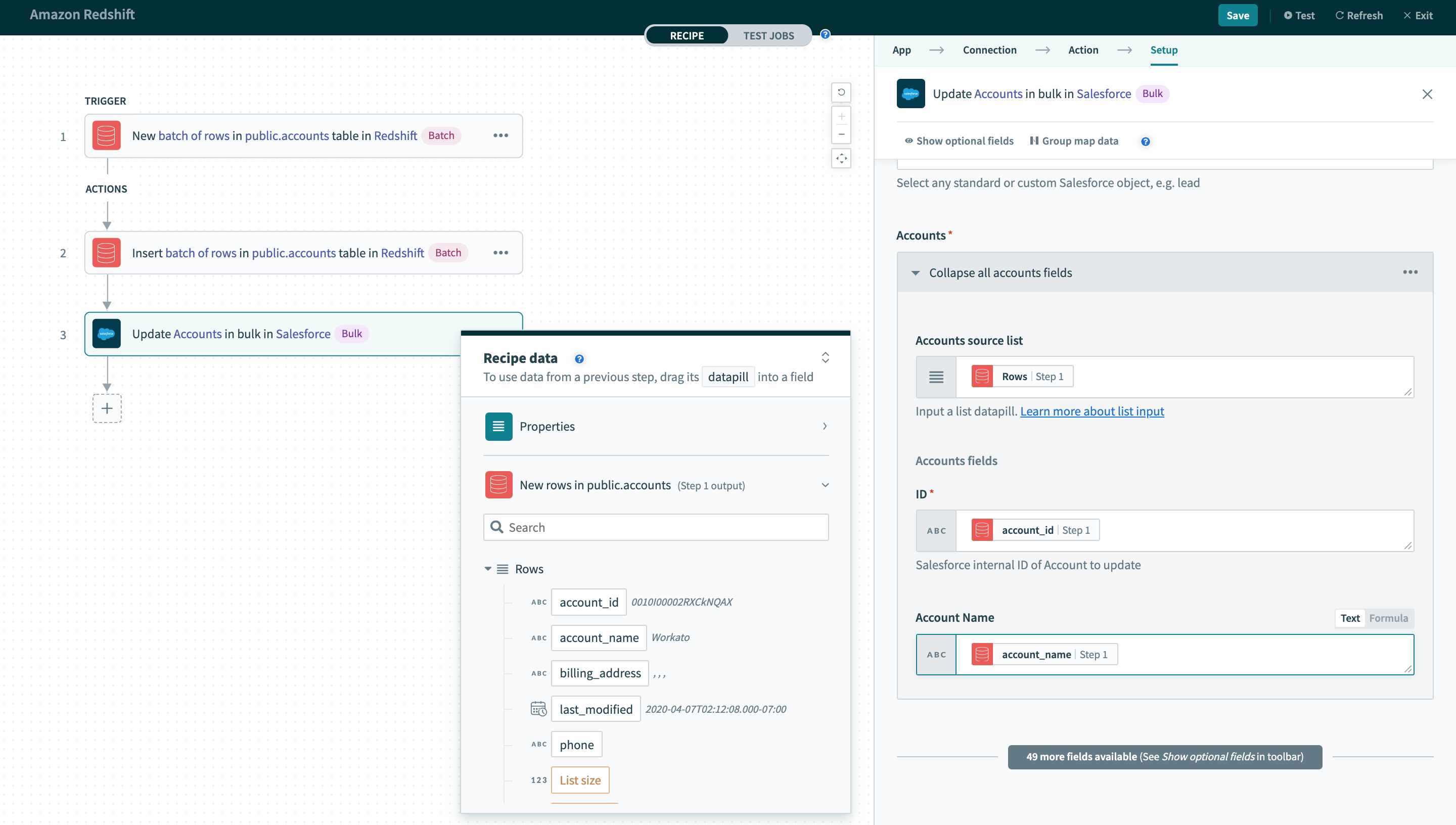 バッチトリガー出力の使用
バッチトリガー出力の使用
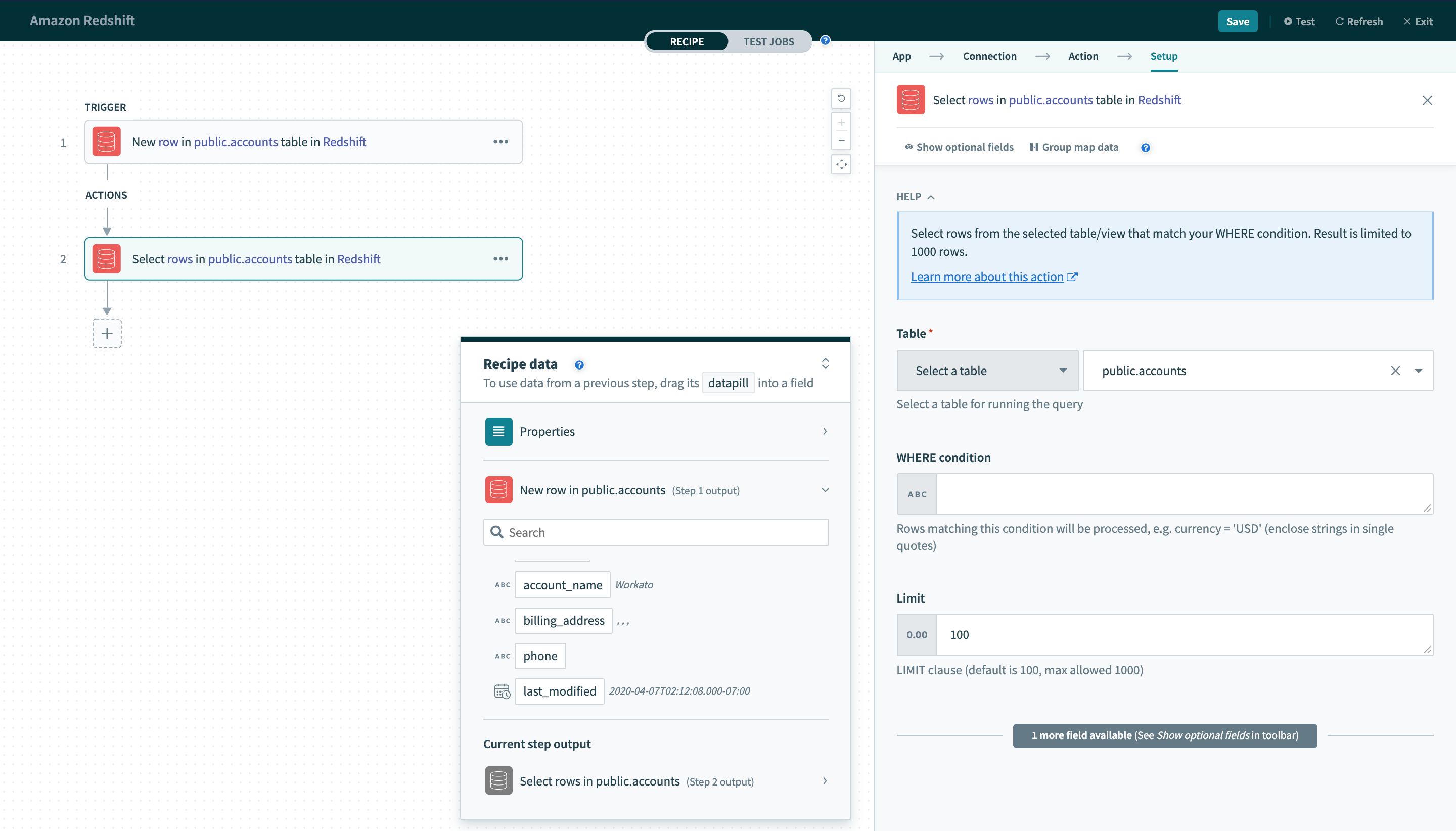
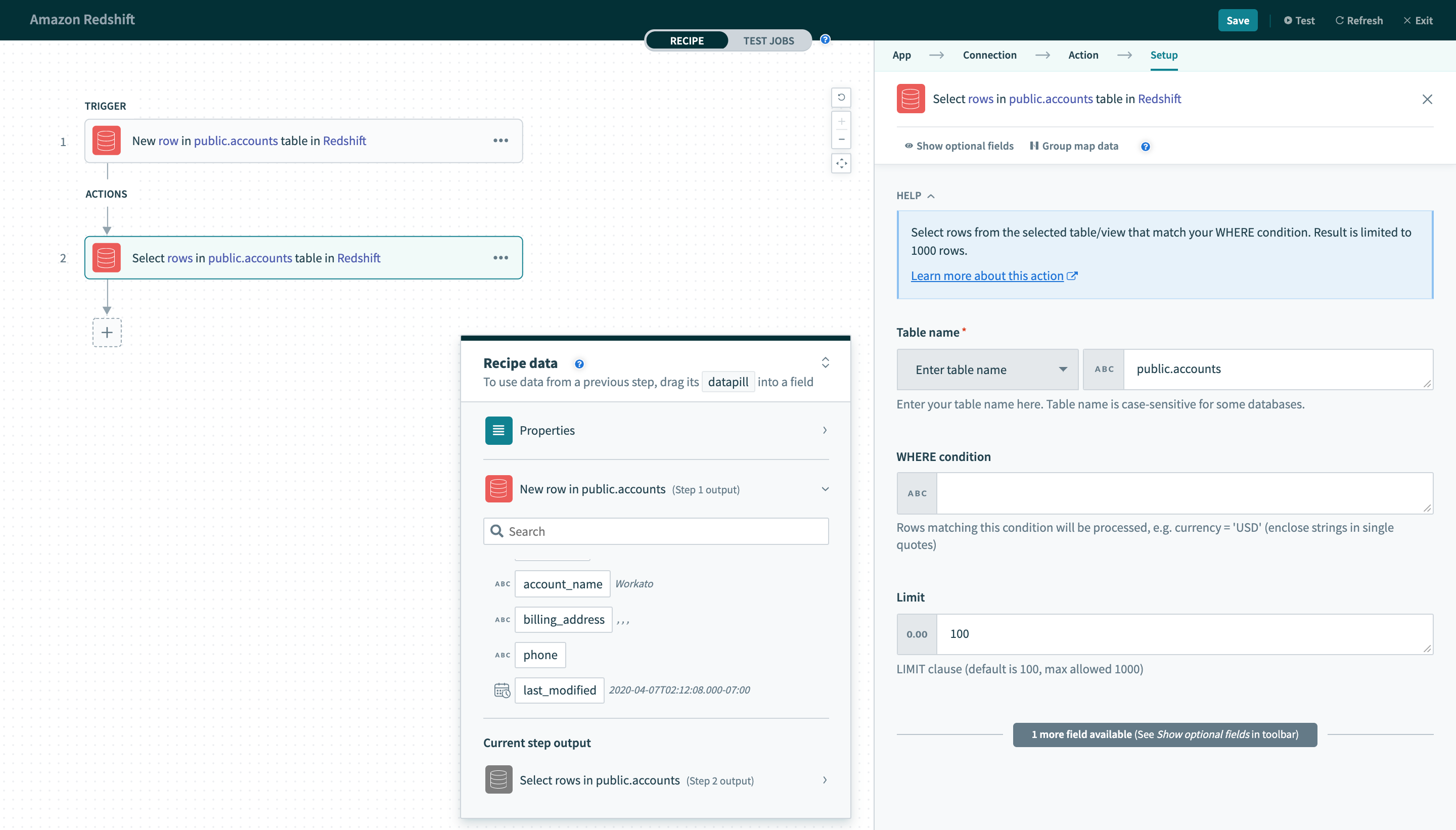
WHERE条件
この入力フィールドは、アクションを実行する行をフィルタリングして識別するために使用されます。 次の方法で複数のトリガーおよびアクションで使用されます:
- トリガーで取得する行をフィルタリング
- Select rowsアクションで行をフィルタリング
- Delete rowsアクションで削除する行をフィルタリング
この句は、各リクエストでWHEREステートメントとして使用されます。 これは基本的なSQL構文に従う必要があります。 Redshift SQLステートメントの記述ルールの完全なリストについては、このRedshiftドキュメントを参照してください。
演算子
| Operator | 説明 | 例 |
|---|---|---|
| = | 等しい | WHERE ID = 445 |
| != <> | 等しくない | WHERE ID <> 445 |
| > >= | より大きい 以上 | WHERE PRICE > 10000 |
| < <= | より小さい 以下 | WHERE PRICE > 10000 |
| IN(...) | 値のリスト | WHERE ID IN(445, 600, 783) |
| LIKE | ワイルドカード文字(%および_)を使用したパターン照合 | WHERE EMAIL LIKE '%@workato.com' |
| BETWEEN | 範囲を指定して値を取得 | WHERE ID BETWEEN 445 AND 783 |
| IS NULL IS NOT NULL | NULL値のチェック NULL以外の値のチェック | WHERE NAME IS NOT NULL |
単純なステートメント
文字列値は一重引用符('')で囲む必要があり、使用する列はテーブルに存在している必要があります。
単一列の値に基づいて行をフィルタリングする単純なWHERE条件は次のようになります。
currency = 'USD'行を選択アクションで使用した場合、このWHERE条件は、currency列に値'USD'を持つすべての行を返します。 入力では、データピルを一重引用符で囲むことを忘れないでください。
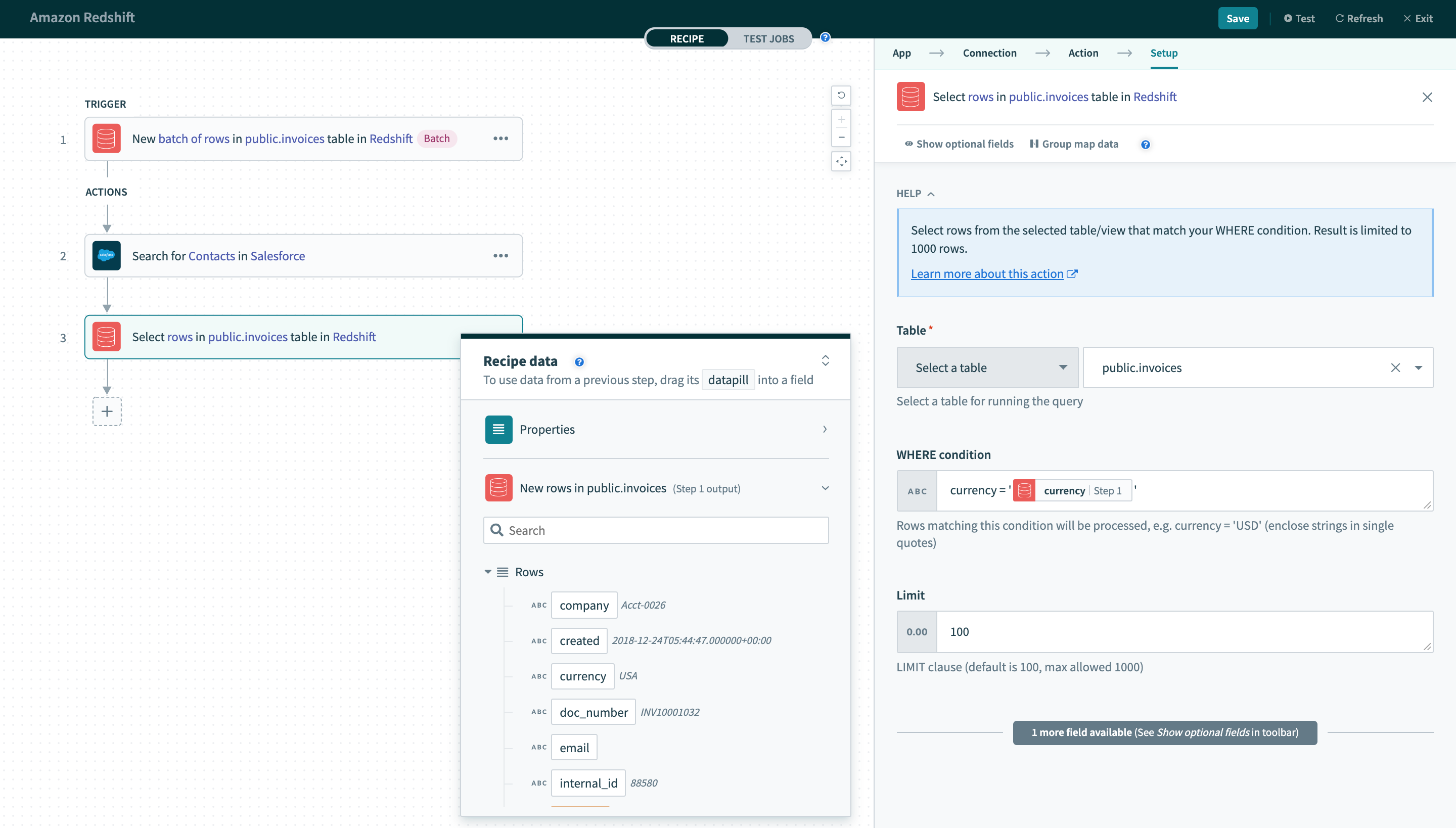
WHERE条件でのデータピルの使用
スペースを含む列名は二重引用符("")で囲む必要があります。 たとえば、currency codeを識別子として使用するには、引用符で囲む必要があります。 引用符で囲まれた識別子はすべて大文字と小文字が区別されることに注意してください。
"currency code" = 'USD'レシピでは、各値/識別子に適切な引用符を使用してください。
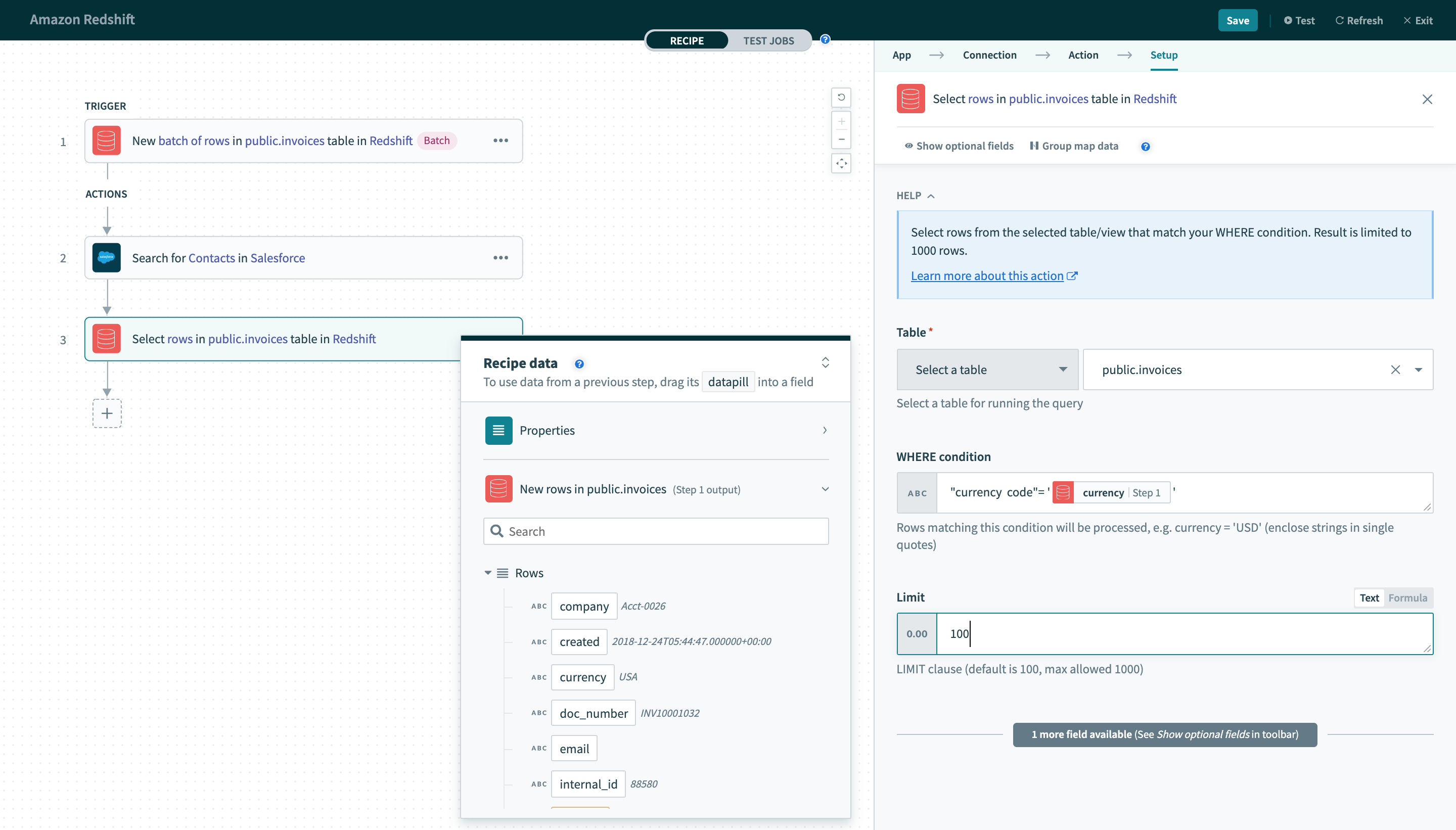 囲まれた識別子を含む
囲まれた識別子を含むWHERE条件
複雑なステートメント
WHERE条件にはサブクエリを含めることもできます。 次のクエリはaccountsテーブルで使用できます。
id in (select user_id from tickets where priority = 2)Delete rowsアクションで使用すると、accountsテーブル内の関連付けられた少なくとも1つの行で、account_name列の値が2である場合に、invoicesテーブル内のすべての行が削除されます。
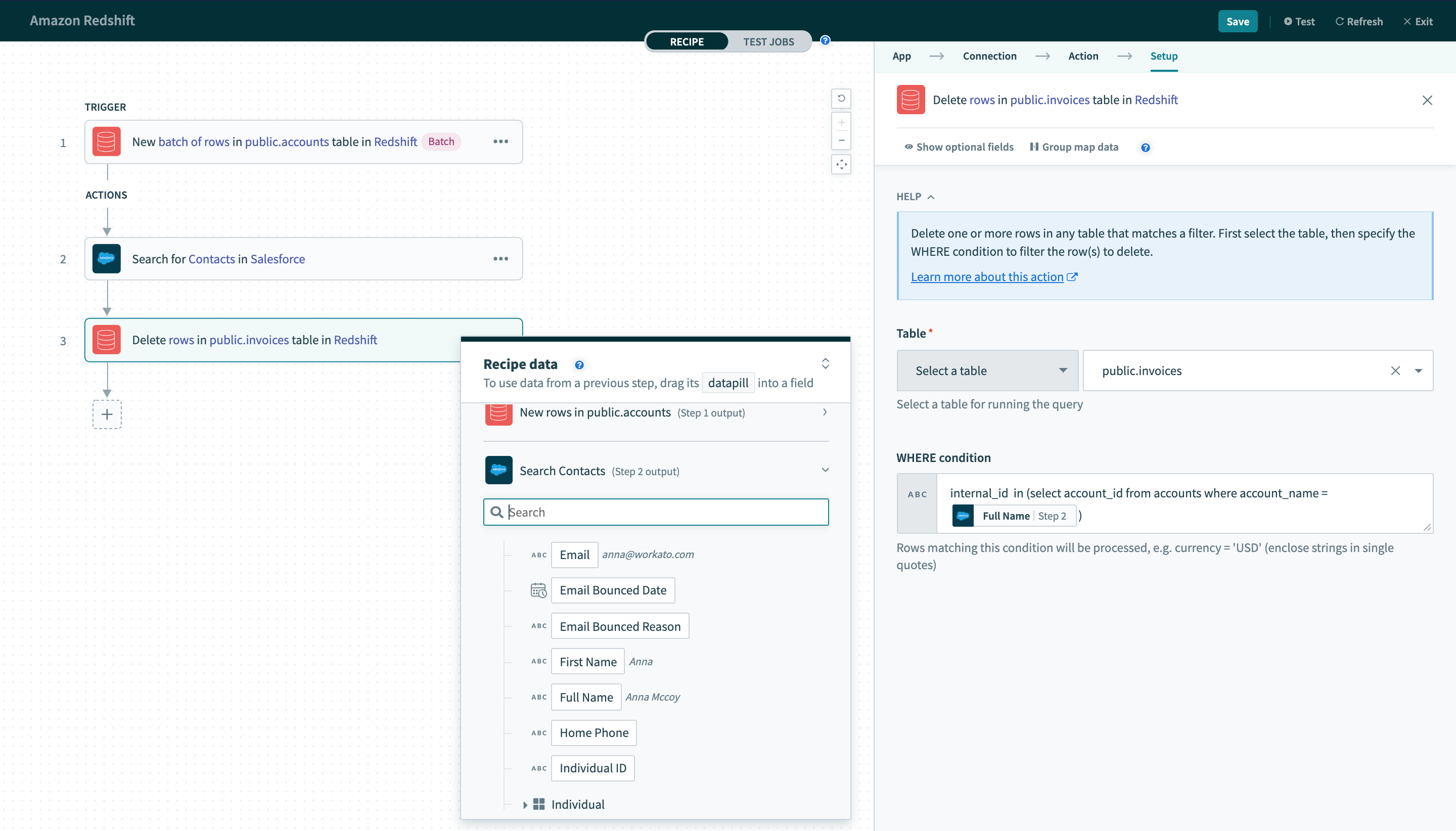 サブクエリを含む
サブクエリを含むWHERE条件でのデータピルの使用
一意キー
すべてのトリガーと一部のアクションでは、これは必須入力です。 この選択された列の値は、選択したテーブル内の行を一意に識別するために使用されます。
そのため、選択した列の値は一意である必要があります。 通常、この列はテーブルの主キーです(例: ID)。
トリガーで使用する場合、この列は増分である必要があります。 この制約が必要なのは、トリガーがこの列の値を使用して新しい行を検索するためです。 各ポーリングで、トリガーは前回の最大値より大きい一意キー値を持つ行をクエリします。
この動作を説明するために、簡単な例を使用しましょう。 テーブルから行を処理するNew rowトリガーがあるとします。 このトリガーに設定されている一意キーはIDです。 最後に処理された行のID値は100です。 次のポーリングでは、トリガーは新しい行を検索する条件としてID >= 101を使用します。
一意キーとして使用するために選択された列にインデックスが設定されている場合、トリガーのパフォーマンスを向上させることができます。
ソート列
これはNew/updated rowトリガーでは必須です。 この選択された列の値は、更新された行を識別するために使用されます。
行が更新されても、Unique key値は同じままです。 ただし、最終更新時刻を反映するようにSort columnが更新されている必要があります。 このロジックに従って、Workatoはこの列の値を、選択されたUnique key列の値とともに追跡します。 Sort column値の変更が検出されると、更新行イベントが記録され、トリガーによって処理されます。
この動作を説明するために、簡単な例を使用しましょう。 テーブルから行を処理するNew/updated rowトリガーがあります。 このトリガーに設定されているUnique keyとSort columnは、それぞれIDとUPDATED_ATです。 トリガーによって最後に処理された行のID値は100、UPDATED_AT値は2018-05-09 16:00:00.000000です。 次のポーリングで、トリガーは次の2つの条件のいずれかを満たす新しい行をクエリします。
UPDATED_AT > '2018-05-09 16:00:00.000000'ID > 100 AND UPDATED_AT = '2018-05-09 16:00:00.000000'
Redshiftでは、timestampおよびtimestamptz列タイプのみ使用できます。
最終更新日: