Oracleコネクターの使用
このガイドでは、Oracleコネクターを使用するためのベストプラクティスについて説明します。 詳細はOracleコネクターを参照してください。
テーブル、ビュー、ストアドプロシージャ
Oracleデータベースに正常に接続し、レシピでアクション/トリガーを選択した後、テーブル、ビュー、またはストアドプロシージャを選択できます。 これにより、Workatoがデータを取得または送信する場所を指定します。
テーブルとビュー
Oracleコネクターはすべてのテーブルとビューで動作します。 各トリガーまたはアクションのドロップダウンメニューで使用するテーブルまたはビューを選択するか、正確な名前を指定できます。
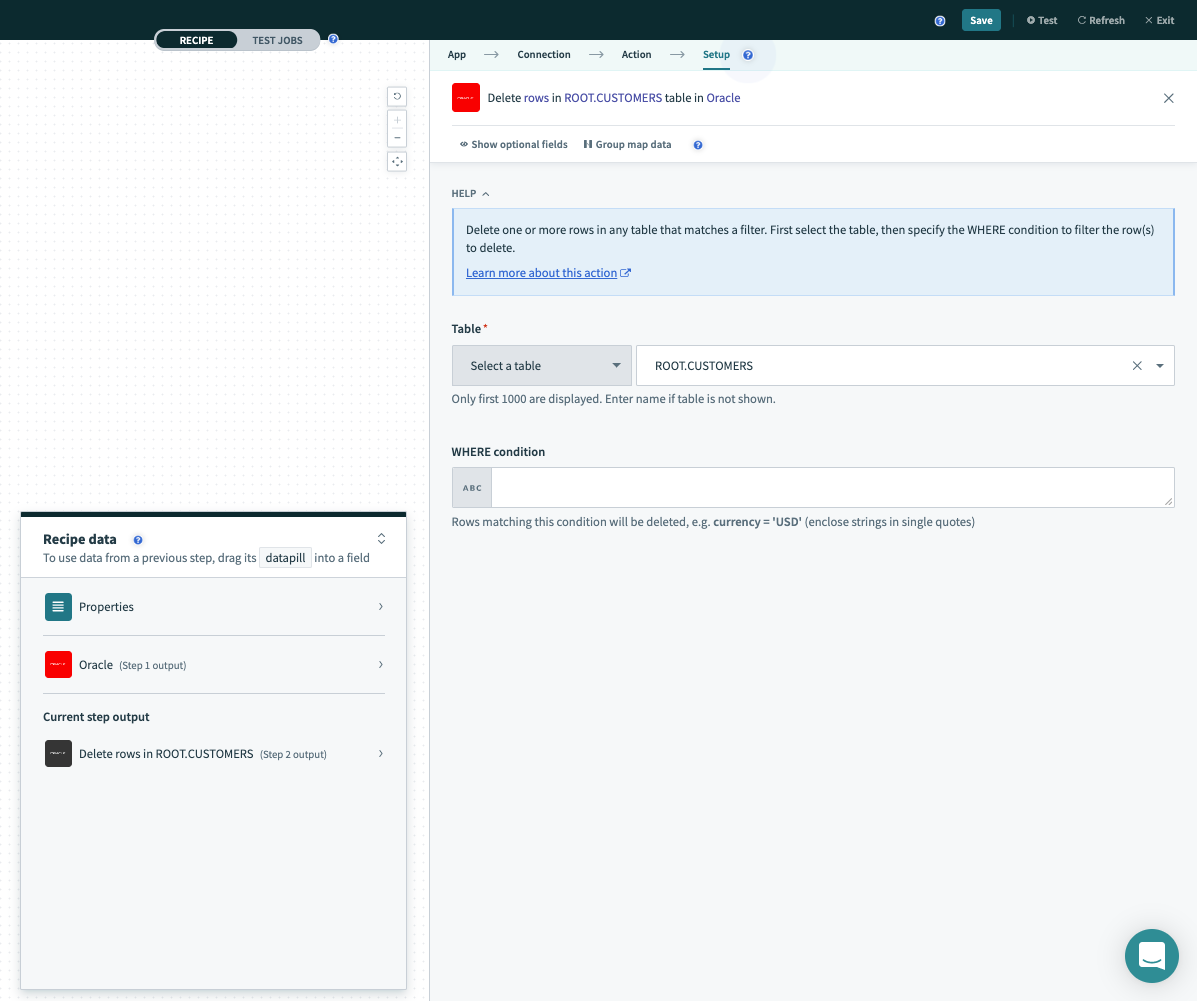 選択リストからテーブル/ビューを選択
選択リストからテーブル/ビューを選択
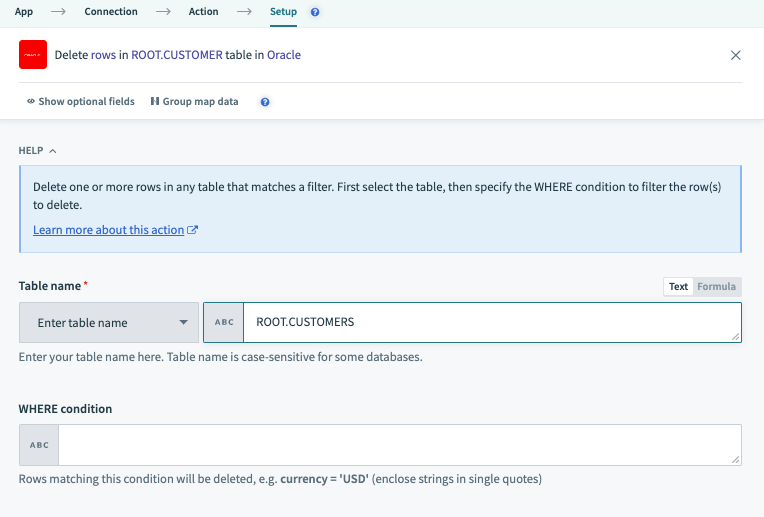 テキスト項目に正確なテーブル/ビュー名を指定
テキスト項目に正確なテーブル/ビュー名を指定
ストアドプロシージャ
ストアドプロシージャは、Oracleデータベース内で作成して保存する必要があるカスタムワークフローです。 ストアドプロシージャを使用すると、行の作成、更新、削除を行えます。 ストアドプロシージャにパラメーターを指定することもできます。 ストアドプロシージャの使用方法の詳細については、Oracle - Execute stored procedureアクションを参照してください。
WHERE条件の使用
この入力項目を使用して、複数のトリガーとアクションで行をフィルタリングして識別します。 次のフィルターを使用できます:
- トリガーで取得する行をフィルタリング
- Select rowsアクションで行をフィルタリング
- Delete rowsアクションで削除する行をフィルタリング
WHERE条件の使用例
ユーザー入力でWHERE条件を直接使用する方法については、次の例を参照してください。 セキュリティを強化するため、SQLインジェクションを防ぐにはパラメーター付きのWHERE条件を使用します。 詳細はパラメーターの使用を参照してください。
この句は、各リクエストでWHEREステートメントとして使用されます。 これは基本的なSQL構文に従う必要があります。 Oracleステートメントの作成ルールの完全な一覧については、このOracleドキュメントを参照してください。
演算子
WHEREステートメントを使用すると、Workatoで返す予定の行をフィルタリングして識別するための演算子を選択できます。 SQLと同じように演算子を連結でき、Workatoからデータに対して堅牢で複雑なフィルターを直接作成するために使用できます。
演算子のリストを表示するには、こちらをクリックしてください
Operator 説明 例 = 等しい WHERE ID = 445!=
<>等しくない WHERE ID <> 445>
>=より大きい
以上WHERE PRICE > 10000<
<=より小さい
以下WHERE PRICE > 10000IN(...) 値のリスト WHERE ID IN(445, 600, 783)LIKE ワイルドカード文字( %および_)を使用したパターン照合WHERE EMAIL LIKE '%@workato.com'BETWEEN 範囲を指定して値を取得 WHERE ID BETWEEN 445 AND 783IS NULL
IS NOT NULLNULL値のチェック
非NULL値のチェックWHERE NAME IS NOT NULL
データ型
WHERE条件のもう1つの要素は、これらの演算子を適切なデータ型と組み合わせて使用することです。 WHEREステートメントを記述する際は、テーブル内のdata type = integerの変数を、同じdata type = integerの変数(data type = stringではなく)と比較するようにしてください。
Workatoでは、次のいずれかのアクションを選択すると、各入力項目の想定されるデータ型が表示されます。
- Update rowsアクション
- Upsert rowsアクション
データ型は出力項目のすぐ下に表示されるため、レシピの作成中に送信すべき想定データ型を確認できます。 この情報を使用して適切なデータ型をOracleデータベースに送信することで、予期しない動作やジョブの失敗を回避できます。
 各入力項目の下の情報には、想定されるデータ型が表示されます
各入力項目の下の情報には、想定されるデータ型が表示されます
一般的なデータ型のリストを表示するには、こちらをクリックしてください
データ型 説明 例 number NUMBERデータ型は、ゼロ、正の固定数、負の固定数を格納します。 -100,1,30,000FLOAT FLOATデータ型はNUMBERのサブタイプです。 精度を指定することも、省略することもできます。 スケールは指定できませんが、データから解釈されます。 各FLOAT値には1~22バイトが必要です。 1.11,2.0761,1.61803398875YEAR 有効な値は-4712~9999で、年0を除きます 1,245,100MONTH 01-12 1DAY 01-31 1,0,15VARCHAR2(n) 長さ nの可変幅文字列Foo_barnchar(n) 長さ nの固定幅文字列Foo(n = 3の場合)TIMESTAMP 1753年1月1日から9999年12月31日まで、精度は3.33ミリ秒 2011-09-16 13:23:18.767
より包括的な一覧については、SQL Data Typesを参照してください。
WHERE条件の作成
文字列値は一重引用符('')で囲む必要があり、使用する列はテーブルまたはビューに存在する必要があります。
次の例は、単一列の値に基づいて行をフィルタリングする単純なWHERE条件を示しています。
currency = 'USD'Select rowsアクションで使用した場合、このWHERE条件はcurrency列に値'USD'を持つすべての行を返します。 入力ではデータピルを一重引用符で囲みます。

WHERE条件でのデータピルの使用
スペース、小文字、特殊文字など、標準ルールに準拠しない列名は、二重引用符("")で囲む必要があります。 たとえば、PUBLISHER NAMEを有効な識別子として使用するには、バッククォートで囲む必要があります。
"PUBLISHER NAME" = 'USD' 囲まれた識別子を含む
囲まれた識別子を含むWHERE条件
WHERE条件の使用方法の詳細については、下のタブをクリックしてください。
WHERE条件でのANDおよびORの使用
WHERE条件は、ANDやORなどの基本的なSQL論理演算子と組み合わせて使用し、返す行にさらにフィルターを追加することもできます。
("currency code" = 'USD' AND totalAmt >1000) OR totalAmt>2000このWHERE条件を使用すると、currency code列に値'USD'を持ち、ANDでtotalAmt列が1000を超える行、またはORでtotalAmt列が2000を超える行をすべて返します。
WHERE条件でのサブクエリの使用
WHERE条件にはサブクエリを含めることもできます。 次のクエリはusersテーブルで使用できます。
ID IN (SELECT "USER ID" FROM TICKETS WHERE PRIORITY >= 2)Delete rowsアクションで使用した場合、ticketsテーブル内の少なくとも1つの関連行のpriority列に値2があるusersテーブルのすべての行が削除されます。
 サブクエリを含む
サブクエリを含むWHERE条件でのデータピルの使用
パラメーターの使用
パラメーターは、SQLインジェクションに対する追加のセキュリティレイヤーを加えるために、WHERE条件と組み合わせて使用します。 WHERE条件でパラメーターを使用するには、入力でバインド変数を宣言する必要があります。 バインドパラメーターは、変数名の前に:を付けた:bind_variable形式で宣言する必要があります。 次に、以前に入力した正確な名前を使用して、次のセクションでパラメーターを宣言します。
バインド変数
バインド変数は列名ではなく、列値の代わりとしてのみ使用してください。
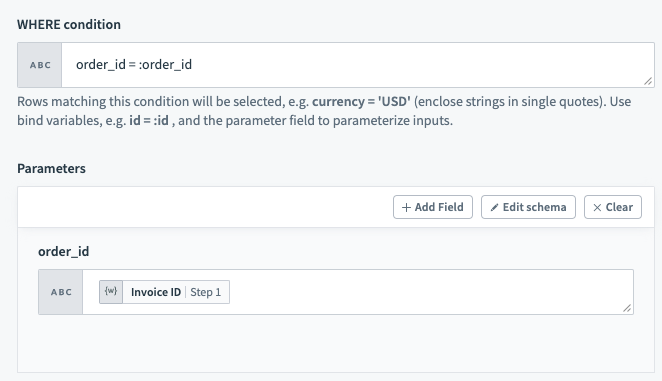 バインド変数を含む
バインド変数を含むWHERE条件
バインド変数は無制限に指定できます。 各バインド変数には一意の名前を付ける必要があります。 Workatoは、一重引用符(')、二重引用符(")、角括弧([])内の:を無視することで、バインド変数を列名や静的値と区別します。
トリガーの設定
Oracleコネクターには、新しい行と更新された行の両方に対応するトリガーがあります。 トリガーを動作させるには、両方のUnique keysを設定する必要があります。 最近更新された行を検索するトリガーには、Sort columnsを設定する必要があります。
トリガーで使用するには、テーブルがいくつかの制約を満たす必要があります。 次のセクションでは、特定の制約について詳しく説明します。 Workatoで使用するテーブルを準備する方法の詳細については、Workato用のテーブル設計を参照してください。
一意キー
一意キーは、すべてのトリガーと一部のアクションで必須の入力です。 この選択された列の値は、選択したテーブル内の行を一意に識別するために使用されます。 選択した列の値も一意である必要があります。 この列は通常、テーブルのprimary keyです。たとえば、IDです。
トリガーで使用する場合、この列は増分である必要があります。 この制約が必要なのは、トリガーがこの列の値を使用して新しい行を検索するためです。 各ポーリングで、トリガーは前回の最大値より大きい一意キー値を持つ行をクエリします。
詳細な例を表示するには、こちらをクリックしてください
New row triggerはテーブルから行を処理しました。 このトリガーに設定されたunique keyはIDです。 最後に処理された行のID値は100です。 トリガーは、次回のポーリングで新しい行を検索する条件として>= 101を使用します。
unique keyとして使用するために選択した列にインデックスが付いている場合、トリガーのパフォーマンスを向上できます。
ソート列
New/updated row triggersにはソート列が必要です。 この選択された列の値は、更新された行を識別するために使用されます。
行が更新されても、Unique key値は同じままです。 ただし、最終更新時刻を反映するようにSort columnが更新されている必要があります。 このロジックに従って、Workatoはこの列の値を、選択されたUnique key列の値とともに追跡します。 Sort column値の変更が検出されると、更新済み行イベントが記録され、トリガーによって処理されます。
Oracleデータベースでは、date、timestamp、timestamp with time zone、およびtimestamp with local time zoneの列型のみ使用できます。
詳細な例を表示するには、こちらをクリックしてください
new/updated row triggerはテーブルから行を処理しました。 このトリガーに設定されたUnique keyとSort columnは、それぞれIDとUPDATED_ATです。 トリガーによって最後に処理された行のID値は100、UPDATED_AT値は2018-05-09 16:00:00.000000です。 次回のポーリングで、トリガーは次の2つの条件のいずれかを満たす新しい行をクエリします:
UPDATED_AT'2018-05-09 16:00:00.000000'ID> 100 ANDUPDATED_AT = '2018-05-09 16:00:00.000000'
単一行アクションとトリガーの使用、または行のバッチアクションとトリガーの使用
Oracleコネクターは、単一行またはバッチでデータベースの読み取りまたは書き込みを行えます。 バッチトリガーとバッチアクションを使用する場合は、希望するバッチサイズを指定する必要があります。 バッチサイズには1~100の任意の数値を指定できます。 多数の行の読み取り、作成、または更新が想定されるジョブでは、バッチトリガーとバッチアクションを使用します。 バッチジョブは、ジョブを個別のジョブ実行に分割することで、処理帯域を節約し、レシピの実行時間を短縮し、サーバーへの負荷を軽減します。 詳細はバッチ処理を参照してください。
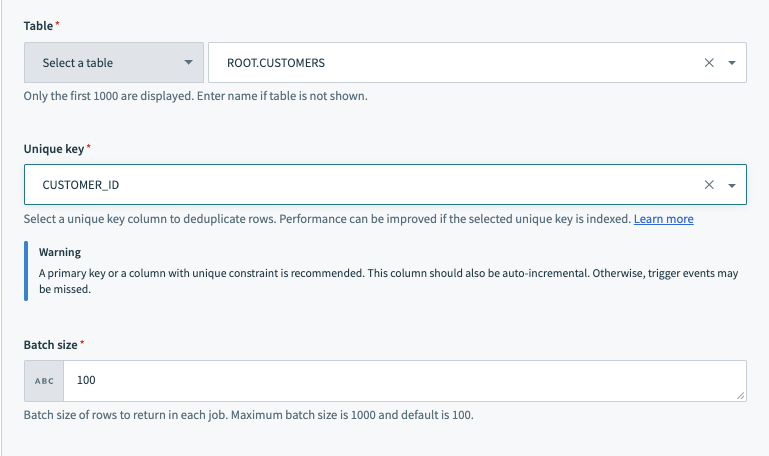 バッチトリガー入力
バッチトリガー入力
これら2種類の操作の出力にも違いがあります。 行を1つずつ処理するトリガーには、その単一行からデータをマッピングできる出力データツリーがあります。
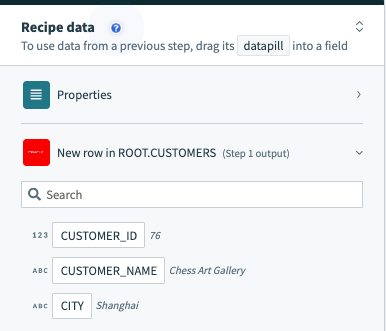 単一行出力
単一行出力
ただし、行をバッチで処理するトリガーは、行の配列として出力します。 行データピルは、出力がそのバッチ内の各行のデータを含むリストであることを示します。
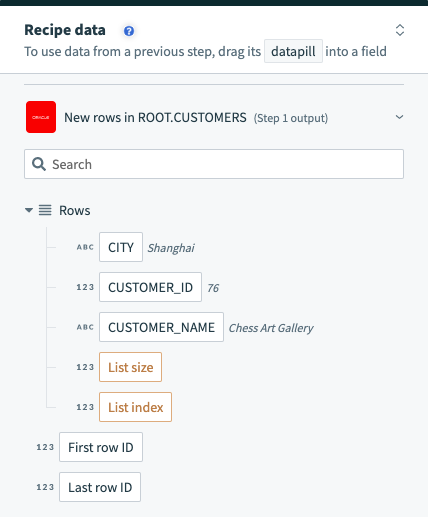 バッチトリガー出力
バッチトリガー出力
そのため、バッチトリガーとバッチアクションの出力は異なる方法で処理する必要があります。 Sync customers from Oracle to Salesforce in batchesレシピは、usersテーブルの新しい行に対してバッチトリガーを使用します。 トリガーの出力は、行データピルをソースリストにマッピングする必要があるSalesforce一括upsertアクションで使用されます。 詳細はお使いのWorkatoインスタンスを参照してください。
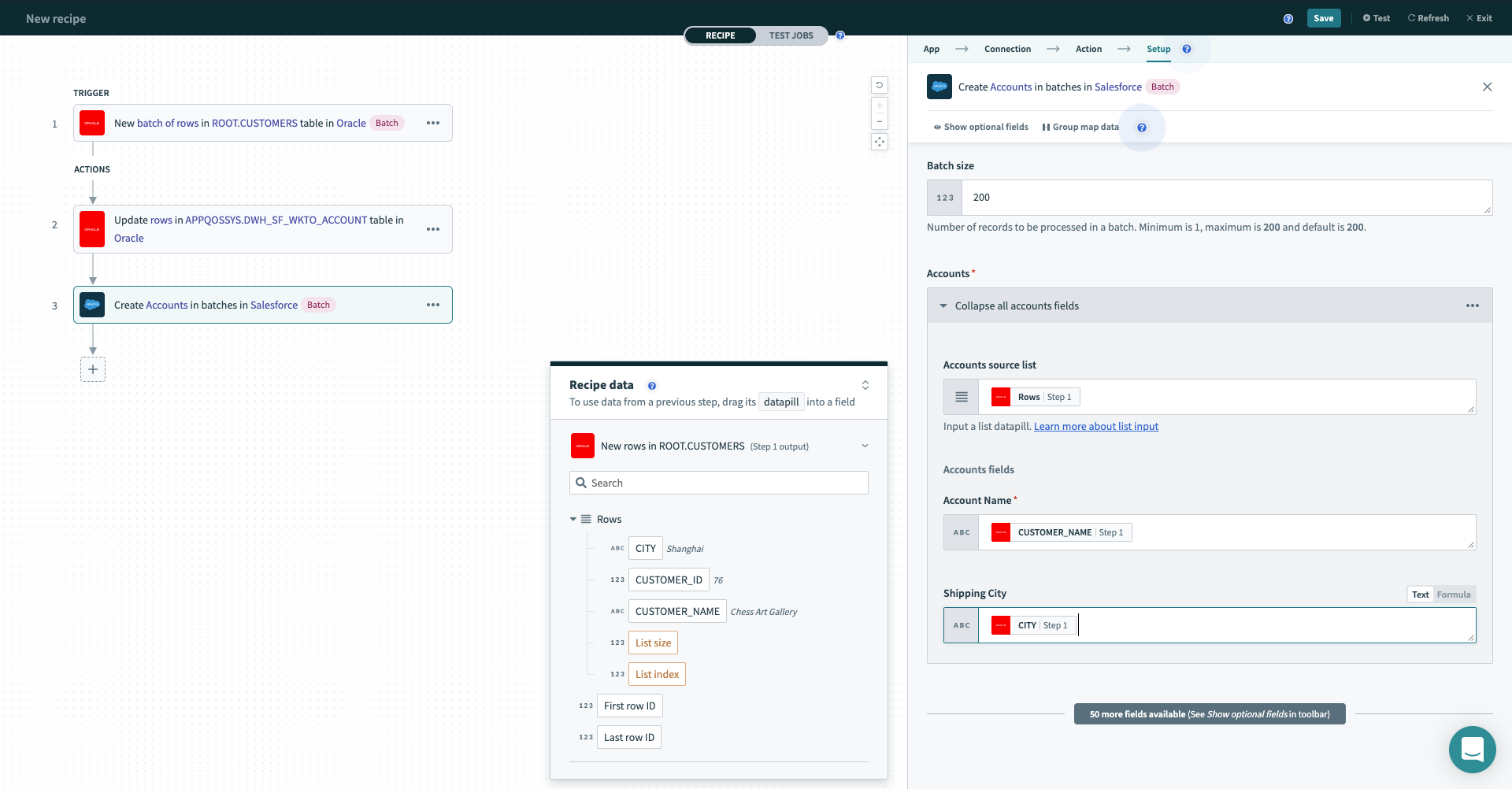 バッチトリガー出力の使用
バッチトリガー出力の使用
バッチトリガーとバッチアクションからの出力は、リスト専用に動作するアクション以外でも使用できます。 Workatoの繰り返しステップを使用してバッチ出力を制御し、単一行向けに構築された任意のアクションで使用できます。 詳細はリストを参照してください。
レシピ設計のベストプラクティス
バッチアクションと単一行アクションのどちらを使用すべきかわからない場合 詳細はバッチと単一行のトリガーおよびアクションの比較を参照してください。
スマートブール変換
Oracleには組み込みのブール列型がありません。 一般的な回避策は、CHECK (COLUMN_NAME IN(1,0))制約を持つNUMBER(1,0)列を使用することです。 その結果、他のアプリケーションの標準値はこの列に適切にマッピングされず、予期しない値やエラーが発生する可能性があります。
このチェックボックスを使用すると、自動スマート変換を有効にできます。 Yesに設定すると、変換はNUMBER型で精度が1のすべての列に適用されます。 これにより、レシピでデータピルを変換するために必要な設定量が減ります。 次の表は、ブール変換のロジックを説明しています。
| 入力値 | 変換後の値 |
|---|---|
true | 1 |
false | 0 |
"true" | 1 |
"false" | 0 |
最終更新日: