Quick Base のアクション - Create and update records in bulk from CSV file (CSV ファイルからのレコードの一括作成および更新)
動作の仕組み
このアクションは、CSV ファイルを取り、Quick Base のレコードを一括で作成または更新します。動作方法は、Quick Base テーブルの設定に応じて以下のように異なります。
Quick Base テーブルでデフォルトのキーフィールド (レコード ID) を使用している場合
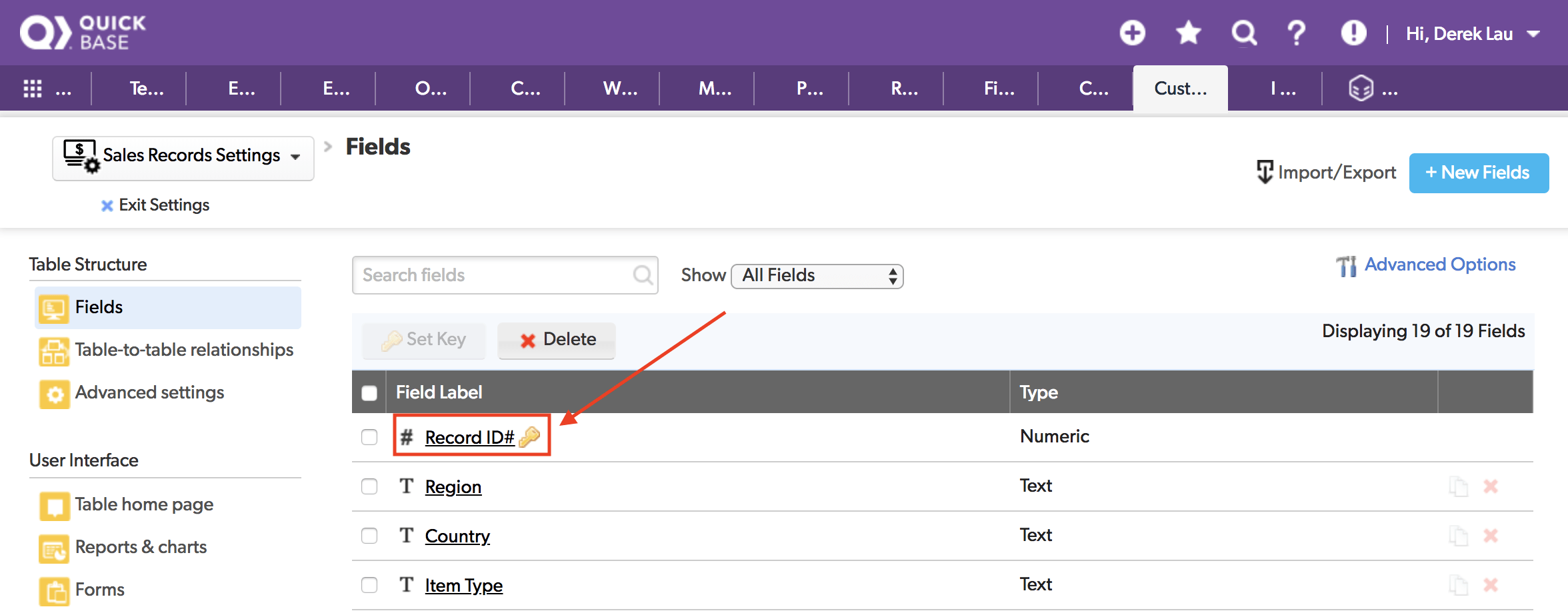
デフォルトのキーフィールド [Record ID#] は、Quick Base により自動的に生成されます。この場合、以下のいずれかを選択できます。
- 新規レコードのみを作成する
- デフォルトのキーフィールドを使用してレコードを作成および更新する
- カスタムのマージフィールドを使用してレコードを作成および更新する
新規レコードのみを作成する
まず、Workato の Quick Base table settings で、[Key field] がデフォルトの Record ID になるよう選択します。
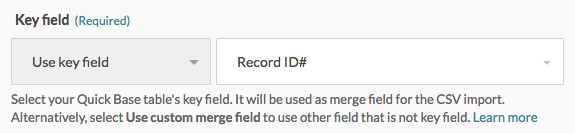
デフォルトの Record ID# は自動生成されるため、新規レコードの作成時にそれを入力する必要はありません。Column mappings セクションの最初の項目の [Record ID#] は 空白 のままにしておいてください。
デフォルトのキーフィールドを使用してレコードを作成および更新する
デフォルトのキーフィールドの Record ID# を使用して、Quick Base のレコードを同時に作成および更新することもできます。
まず、Quick Base のレコード ID を含む列を CSV ファイルに含める必要があります。
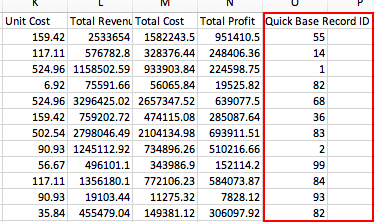
次に Workato の Quick Base table settings で、[Key field] がデフォルトの Record ID になるように選択します。
次に、Column settings セクションで、テーブルの [Record ID#] 列に CSV ファイルのレコード ID 列をマッピングします。
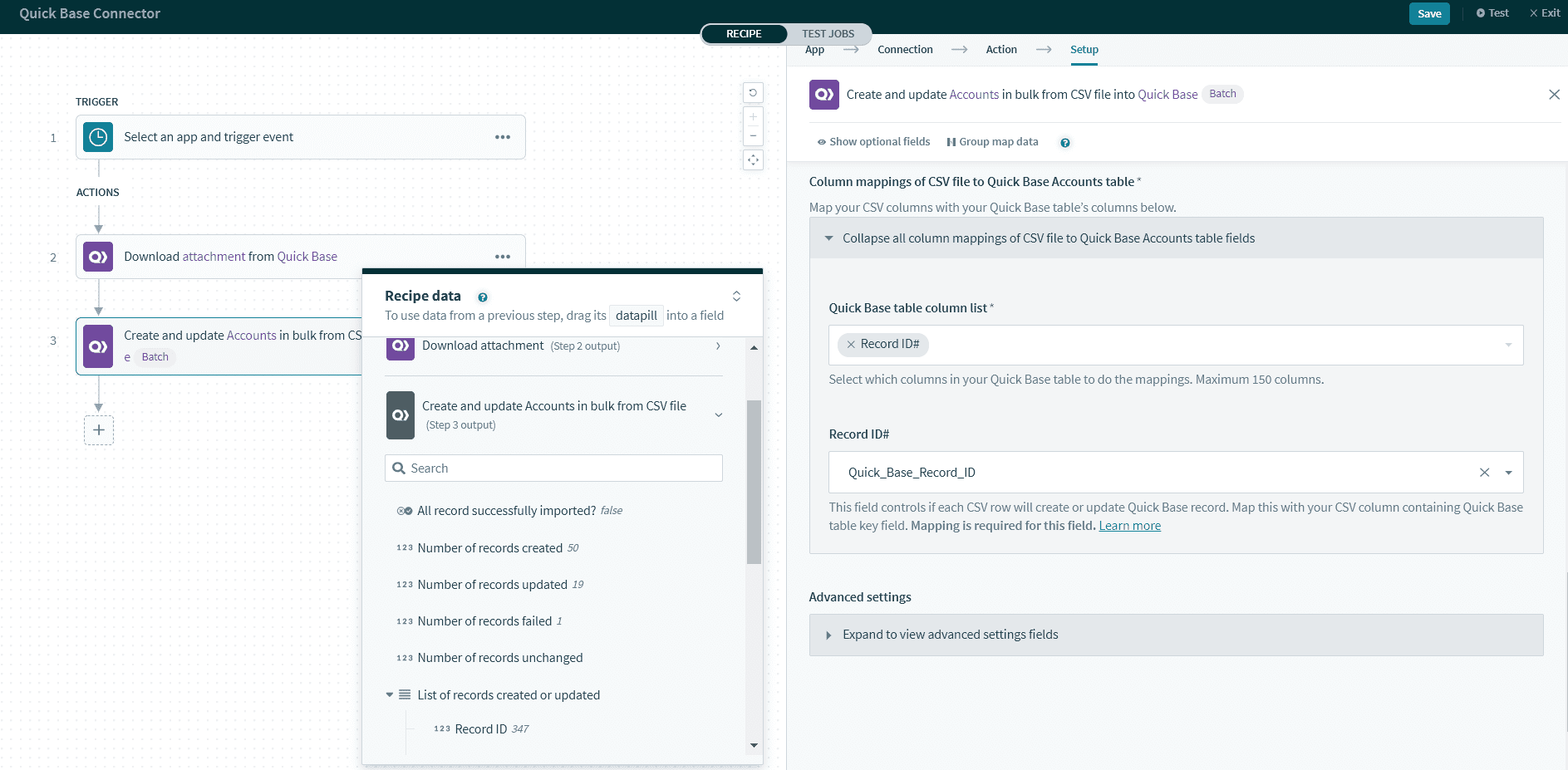
CSV ファイルから指定したレコード ID に基づいて、Quick Base はレコードを作成するか更新するかを決定します。各 CSV 行のルールは以下のようになります。
- レコード ID が空の場合、新しい Quick Base レコードを作成 (
create) します。 - レコード ID が存在する場合、Quick Base 内の一致するレコード ID を検索し、その後レコードを更新 (
update) します。Quick Base 内に一致するレコード ID が見つからない場合、その CSV 行は失敗 (fail) します。
カスタムマージフィールドを使用してレコードを作成および更新する
デフォルトのキーフィールド Record ID# を使用する代わりに、Order ID のような一意のカスタムマージフィールドを使用して、レコードの作成および更新を行うこともできます。この場合、Order ID を使用して CSV レコードがすでに Quick Base 内に存在するかどうかを特定します。
まず、CSV ファイルに Order ID 列が必要です。
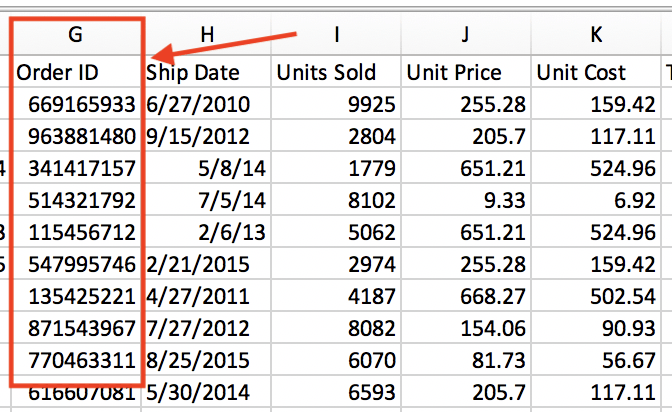
次に、Workato の Quick Base table settings で [Use custom merge field] を選択し、その後 Quick Base テーブルで [Order ID] 列を選択します。
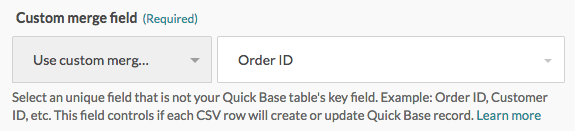
その後 Column mappings セクションで、テーブルの [Order ID] 列に CSV ファイルの [Order ID] 列をマッピングします。
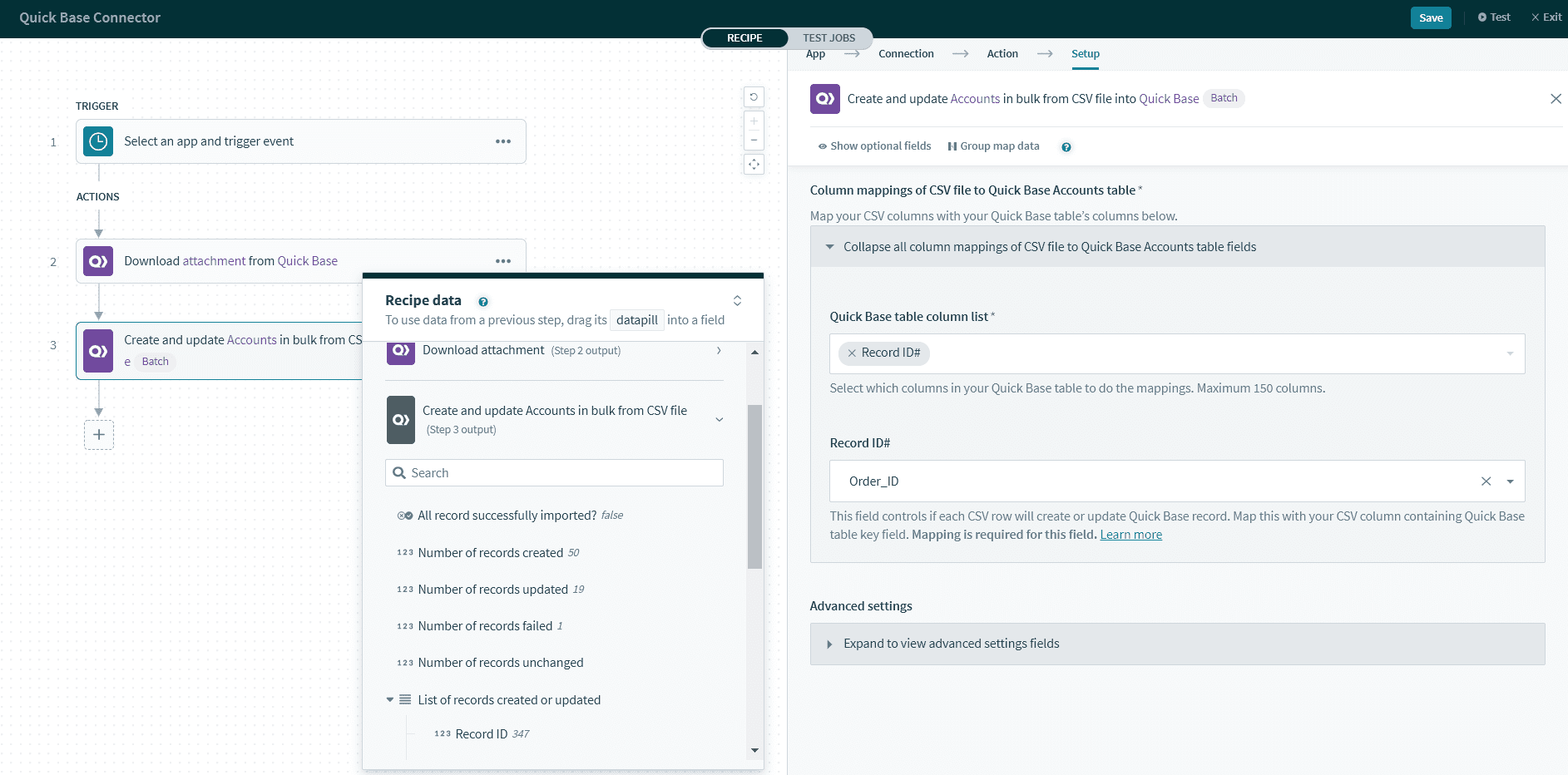
CSV ファイルの指定された ID に基づいて、Quick Base はレコードを作成するか更新するかを決定します。各 CSV 行のルールは以下のようになります。
- ID が空であるか Quick Base 内に存在しない場合、新しい Quick Base レコードを作成 (
create) します。 - ID が存在し Quick Base 内に存在する場合、そのレコードを更新 (
update) します。
Quick Base テーブルでカスタムキーフィールドを使用している場合
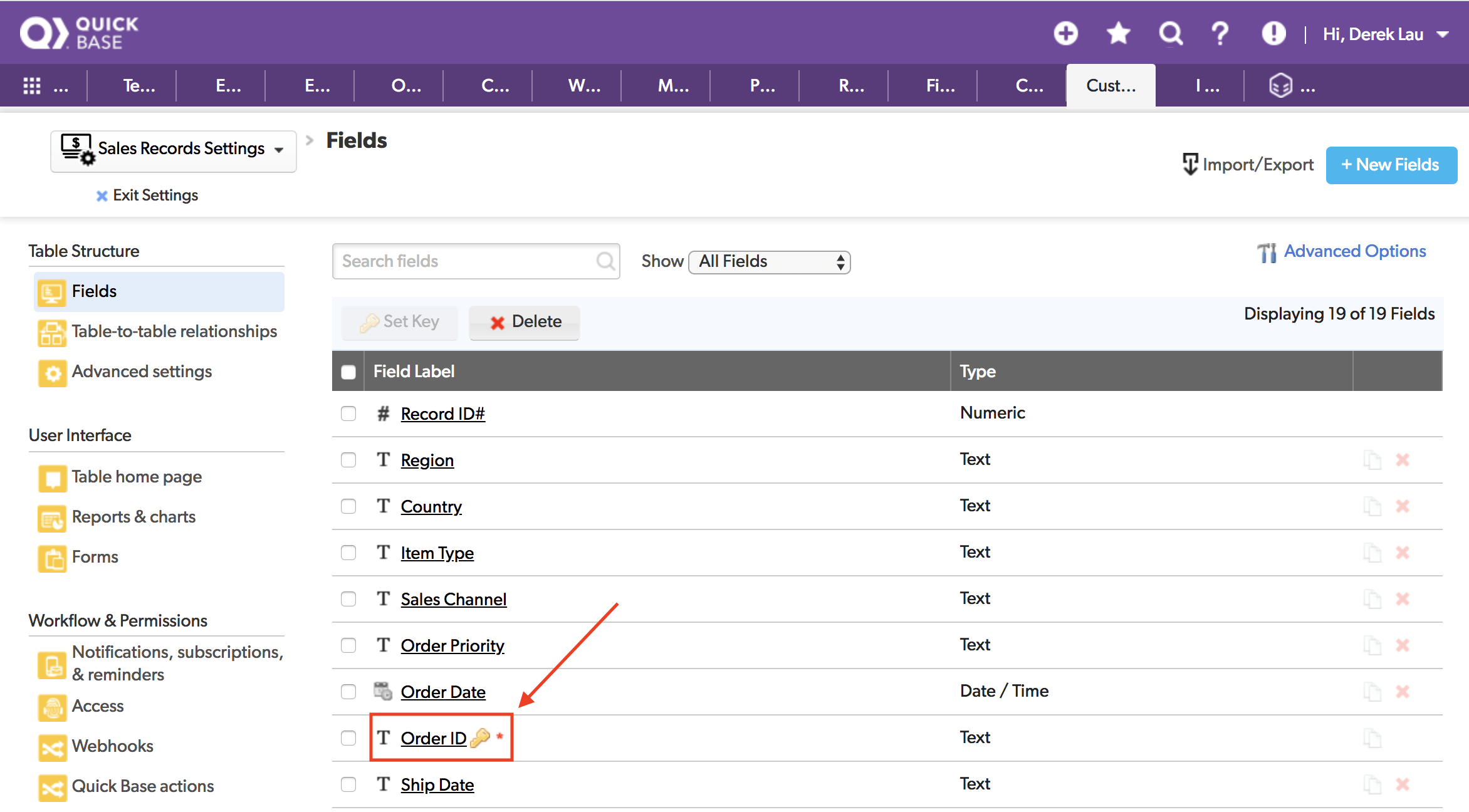
上の例では、この Quick Base テーブルはデフォルトの [Record ID#] の代わりに、カスタムキーフィールドとして [Order ID] を使用しています。この場合、以下のいずれかを選択できます。
- カスタムキーフィールドを使用してレコードを作成および更新する
- カスタムマージフィールドを使用してレコードを更新する
カスタムキーフィールドを使用してレコードを作成および更新する
カスタムキーフィールドは Quick Base により自動的に生成されることはないため、常に CSV ファイルの列として指定する必要があります。この場合は、Order ID です。
Workato の Quick Base table settings で、[Key field] が [Order ID] になるよう選択します。
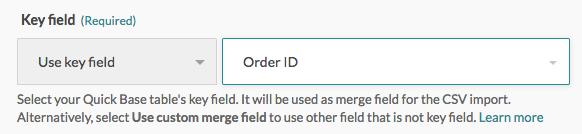
次に、Column mappings セクションの最初の項目に、CSV ファイルの適切なキーフィールドをマッピングします。
CSV ファイルの指定された ID に基づいて、Quick Base はレコードを作成するか更新するかを決定します。各 CSV 行のルールは以下のようになります。
- ID が存在する場合、Quick Base 内の一致するレコード ID を検索し、その後レコードを更新 (
update) します。Quick Base 内に一致する ID が見つからない場合、その ID で新しい Quick Base レコードを作成 (create) します。 - ID が空の場合、その CSV 行は失敗 (
fail) します。
カスタムマージフィールドを使用してレコードを更新する
キーフィールド [Order ID] を使用する代わりに、[Item Type] のような一意のカスタムマージフィールドを使用して、レコードを更新することもできます。この場合、[Item Type] を使用して CSV レコードがすでに Quick Base 内に存在するかどうかを特定します。
Workato の Quick Base table settings で、[Use custom merge field] を選択してから、[Item Type] を選択します。
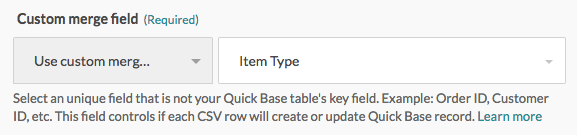
次に、Column mappings セクションの最初の項目に、CSV ファイルの適切なフィールドをマッピングします。
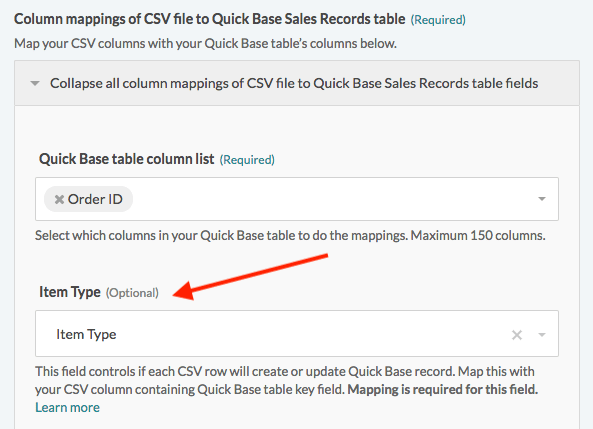
CSV ファイルの指定された ID に基づいて、Quick Base はレコードを更新します。各 CSV 行のルールは以下のようになります。
- ID が存在する場合、Quick Base 内の一致するレコード ID を検索し、その後レコードを更新 (
update) します。Quick Base 内に一致する ID が見つからない場合、その CSV 行は失敗 (fail) します - ID が空の場合、その CSV 行は失敗 (
fail) します。
失敗した CSV 行の処理
このアクションではバッチ処理を使用するため、CSV ファイルを比較的小さな行のチャンク (またはバッチ) に分割してから、Quick Base に送信します。チャンクの中の1行が Quick Base レコード内での作成/失敗に失敗した場合、Quick Base はそのチャンク全体を拒否しますが、その他のチャンクは影響を受けません。
一部の行が失敗した場合でも、アクションは "完了" したと見なされます。これは、Quick Base が CSV ファイルの受け入れに成功しているためです。その後 Quick Base API は、成功したレコードと失敗したレコードのリストとともに、"success" レスポンスを送信します。
この例では、ジョブレポートは "Complete" ステータスを示しています。ただし、アクションの出力を確認すると、実際には失敗したチャンクが1つあります。 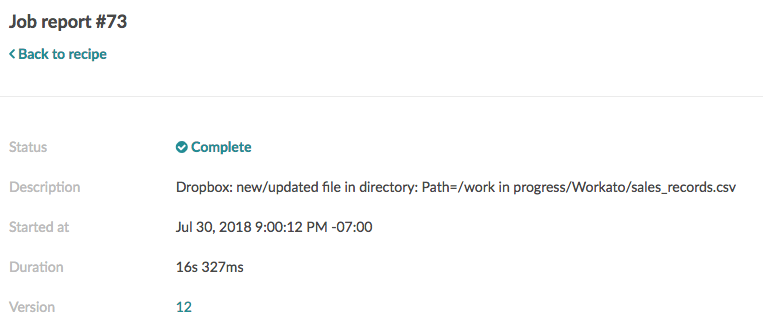
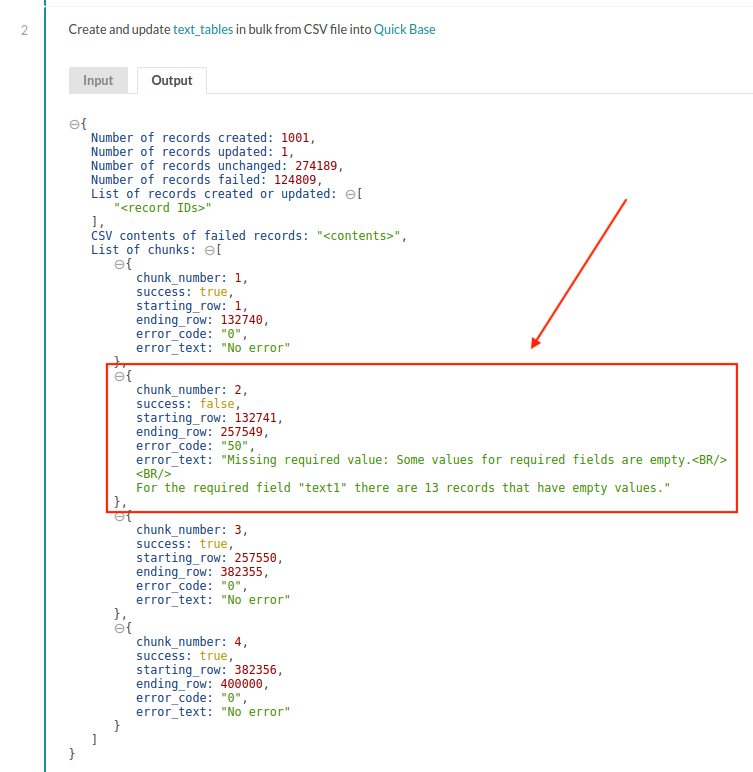
そのため、レシピで失敗した CSV 行を常に処理することが重要です。出力ピル CSV contents of failed records には、すべての失敗した CSV 行が含まれます。これを使用して、CSV ファイルに失敗した行を保存できます。その後、ジョブレポートでエラーの理由を確認し、失敗した行を修正してから、このアクションを使用してそれらの行を再インポートしてください。
以下のサンプルレシピでは、失敗した行を Box の CSV ファイルに保存しています。Amazon S3、SFTP、オンプレミスファイルなどのコネクターを使用して、その他のファイルストレージシステムに CSV ファイルを保存できます。
入力項目
このアクションが機能するには、以下の4つのセクションを設定する必要があります。
- Quick Base テーブル
- CSV ファイルの入力
- 列のマッピング
- 高度な設定
Quick Base テーブル
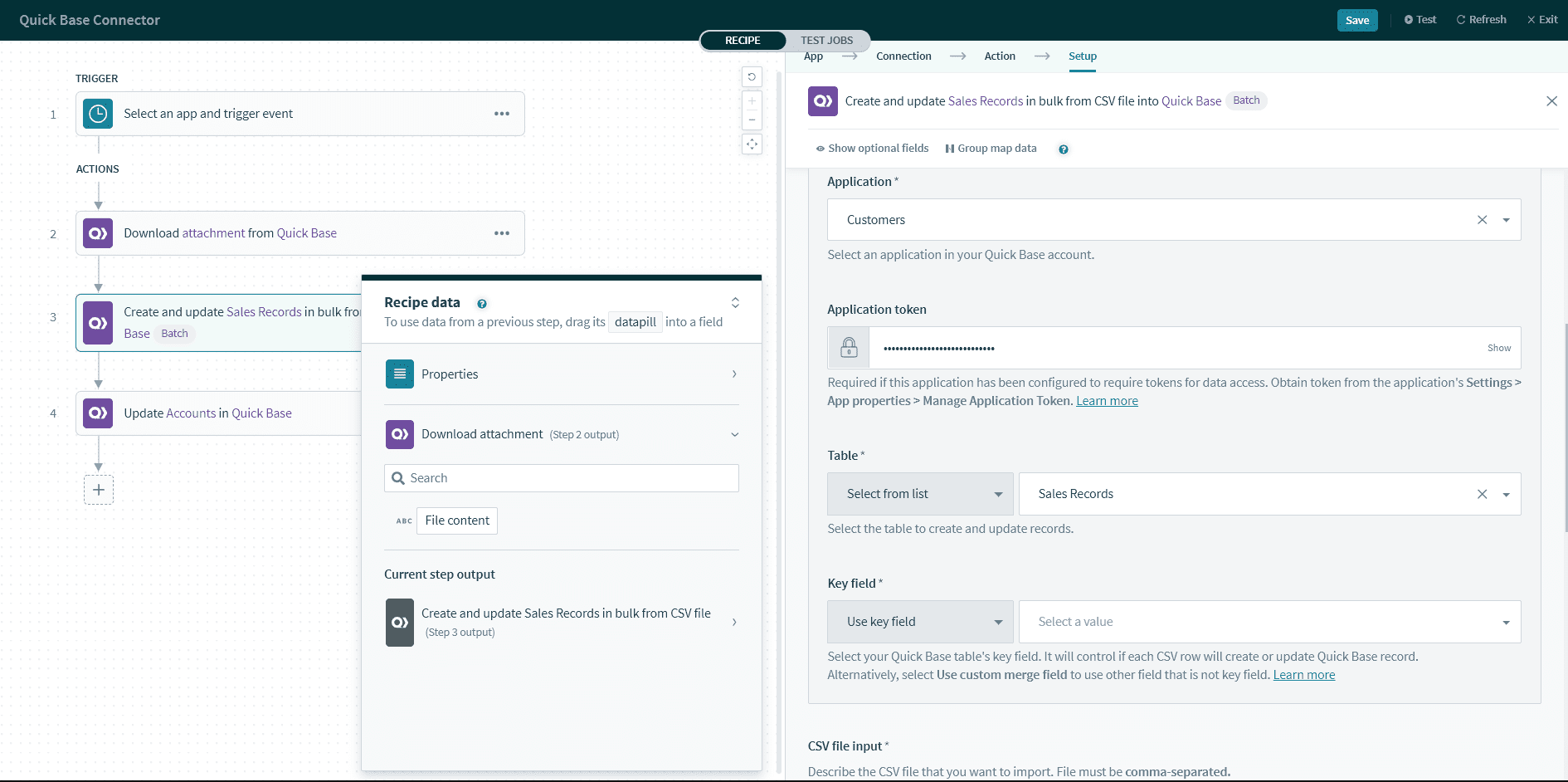
データのインポート先の Quick Base テーブルを設定します。
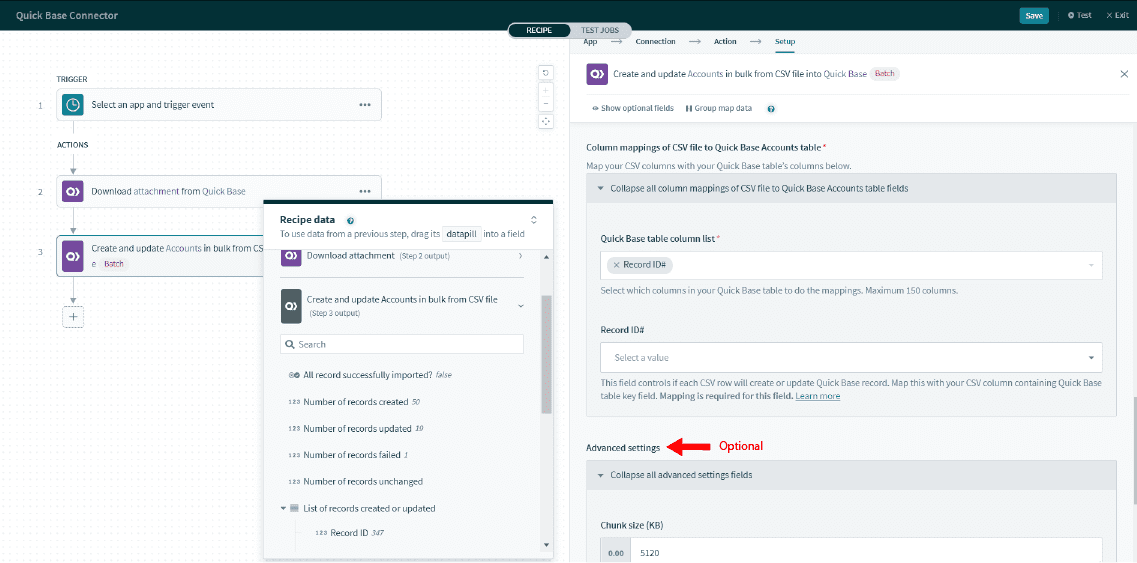
[Key field] フィールドに注意してください。テーブル内の Quick Base キーフィールドを表す適切な列を選択することが重要です。この ID は各レコードに対して一意である必要があります。Workato ではこのフィールドを使用して正確なレコードを検索および更新します。[Use custom merge field] に切り替えることもできます。
デフォルトでは、Quick Base は [Record ID] という名前のフィールドを使用します。しかし場合によっては、[Sales Order ID]、[Customer ID] などのカスタム列をレコード ID として使用できます。
CSV ファイルの入力
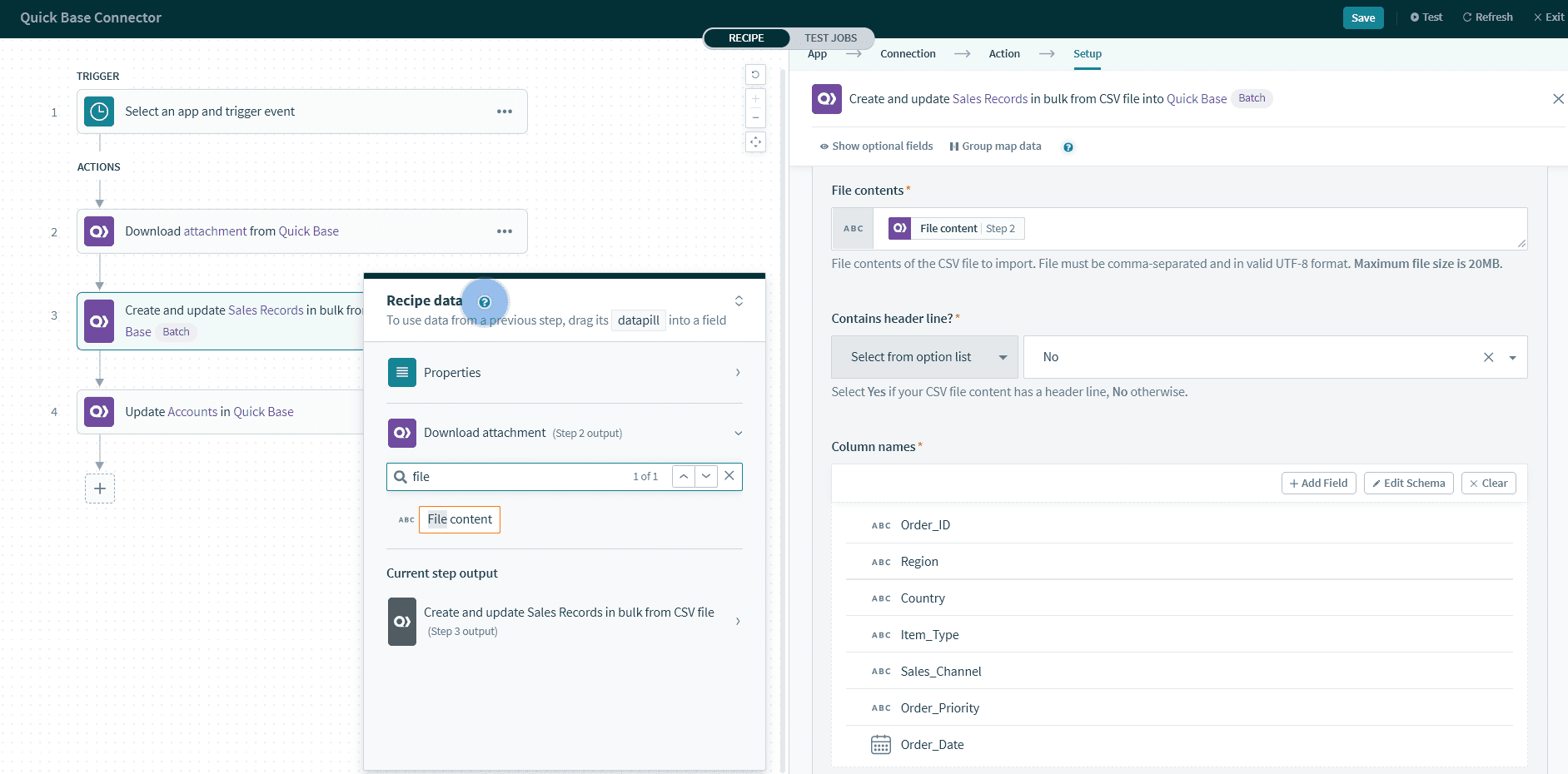
CSV ファイルのコンテンツを指定し、列の構造を説明します。
その他のコネクターのアクションまたはトリガーから、File contents データピルを取得できます。例としては、次のようなものがあります。ファイルコネクター (Box、Amazon S3、オンプレミスファイルなど) の New CSV file in folder トリガー、または Workato ツールの Compose CSV アクション。
ファイルのコンテンツは、 カンマ区切りで UTF-8 形式 である必要があります。
列のマッピング
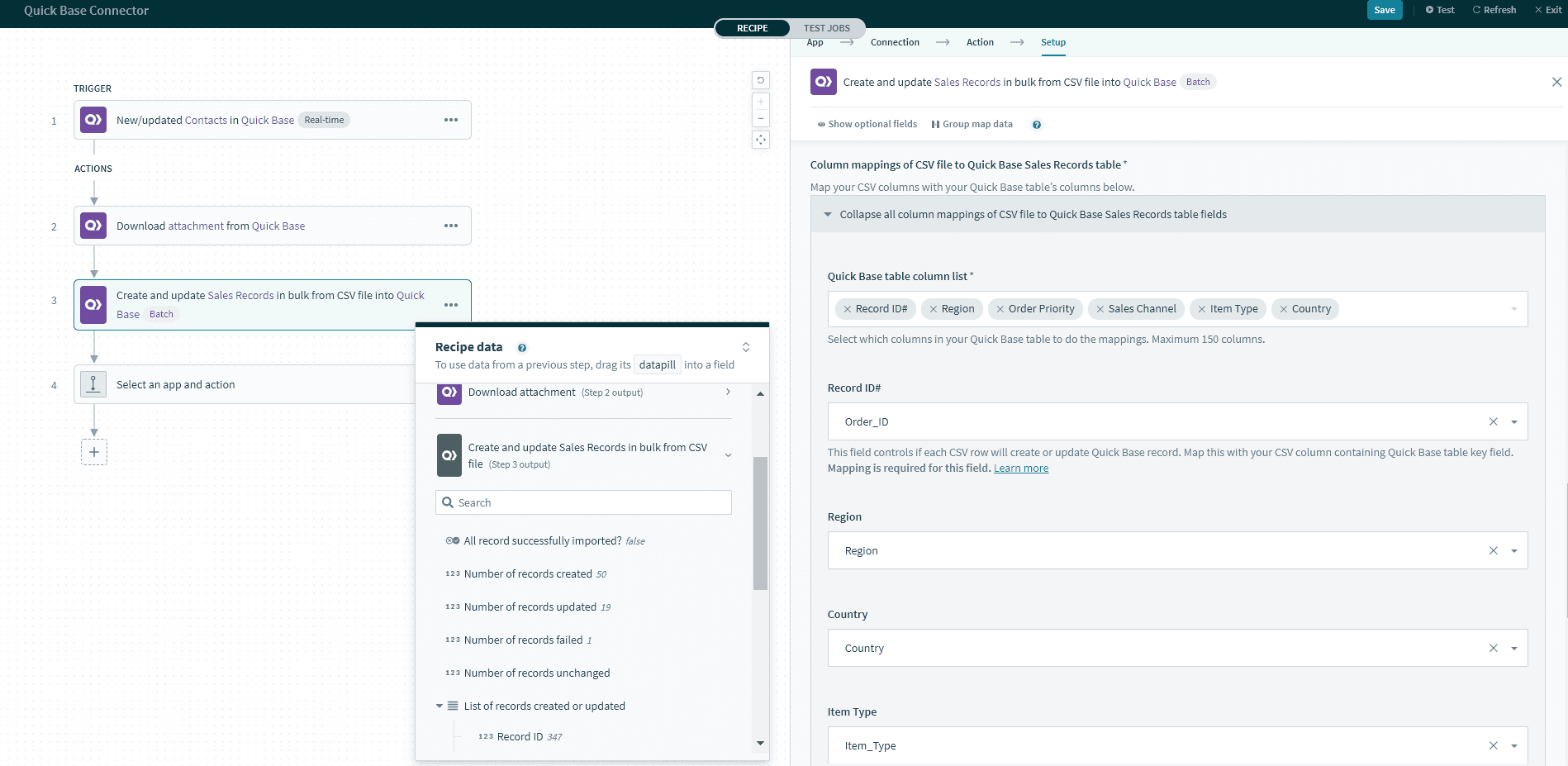
このセクションには、Quick Base テーブルのすべての列がリストされています。それらに CSV ファイルの対応する列をマッピングする必要があります。
最初の入力項目 [Record ID] に注意してください。この列に CSV ファイルの正しいレコード ID 列をマッピングするようにしてください。そうすることで、Workato はその ID を使用して Quick Base 内のレコードを検索および更新できるようになります。このサンプルの CSV ファイルでは、列 [Quick Base Record ID] を使用します。
高度な設定
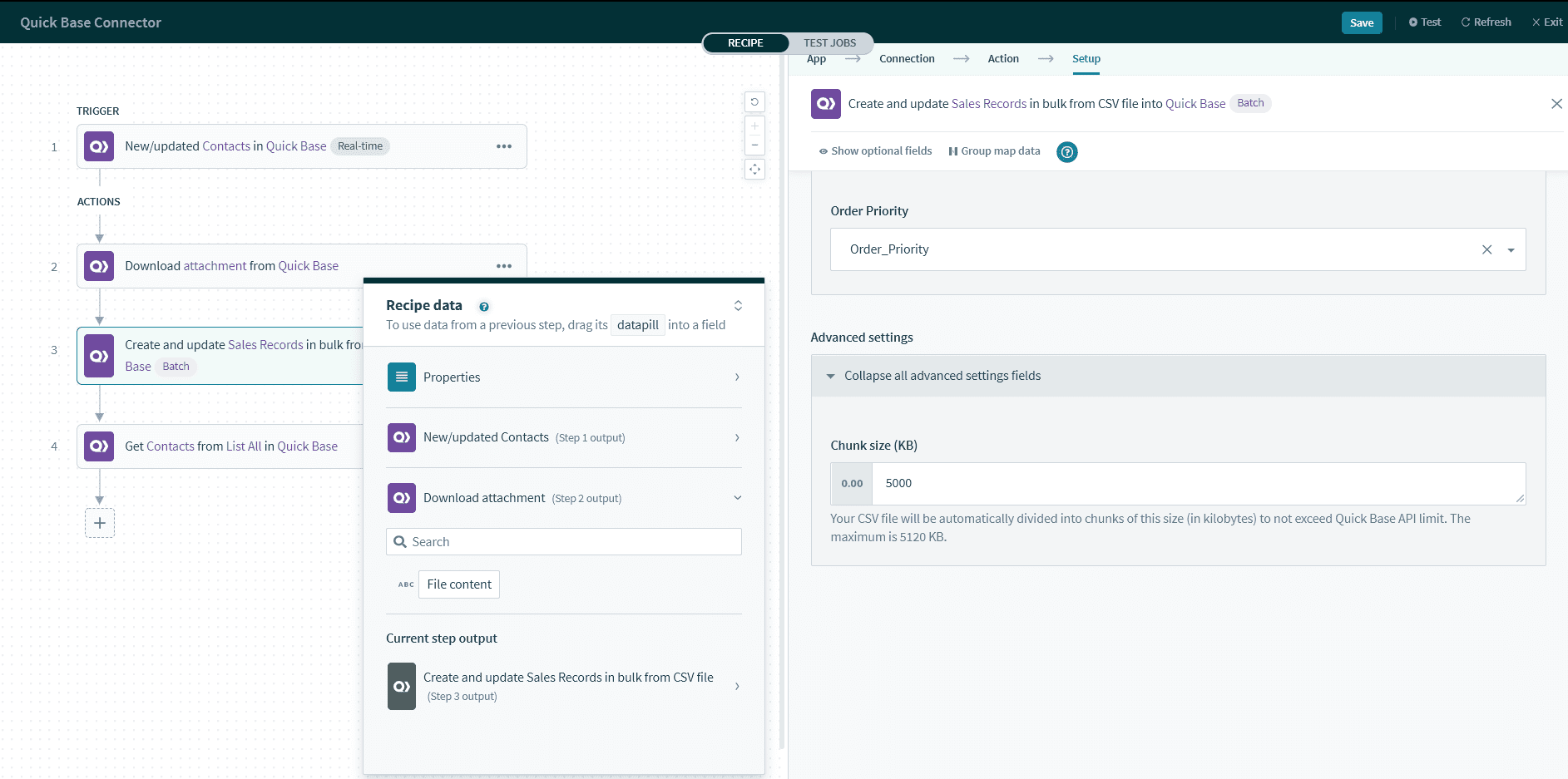
このアクションではバッチ処理を使用するため、CSV ファイルを比較的小さな行のチャンクに分割してから、Quick Base に送信します。これにより、Quick Base の API 制限を超過することなく、サイズの大きな CSV ファイルを送信できるようになります。
この [Chunk size (KB)] を使用して、必要に応じてチャンクサイズ (キロバイト単位) をカスタマイズできます。通常、より大きなチャンクサイズを使用すると、大きなファイルを転送する時間を短縮できます。
出力
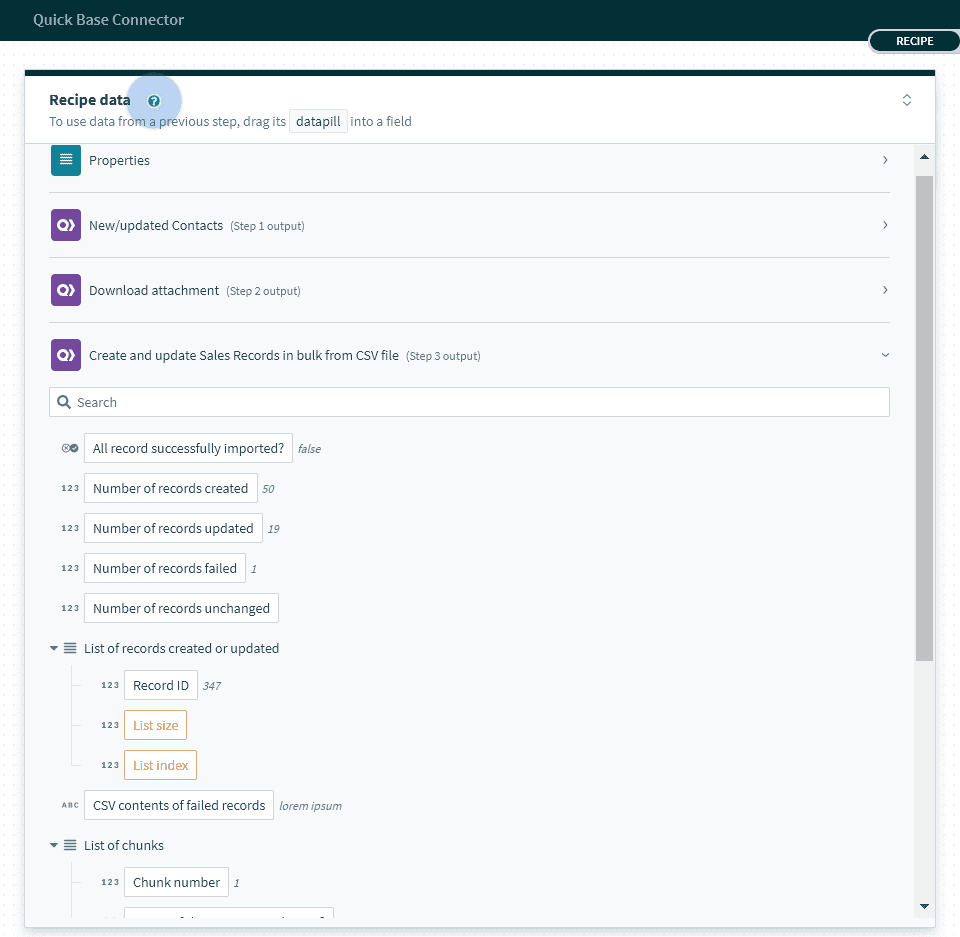
| 出力ピル | 説明 |
|---|---|
| Number of records created | Quick Base で作成に成功したレコードの数。 |
| Number of records updated | Quick Base で更新に成功したレコードの数。 |
| Number of records failed | Quick Base レコード内で作成または更新に失敗した CSV 行の数。 |
| Number of records unchanged | このアクションを実行しても変更されなかったレコードの数。 |
| List of records created or updated | これはリストピルです。このリストには、すべての正常に作成/更新されたレコードの Quick Base レコード ID が含まれます。 |
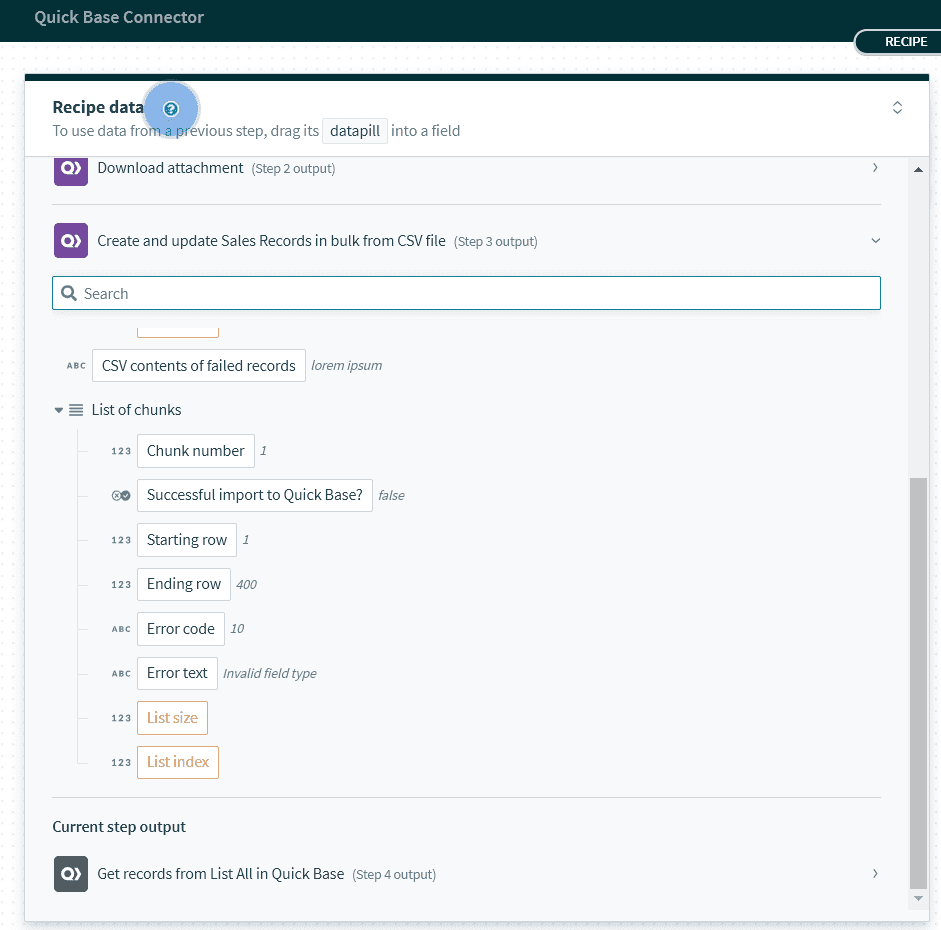
| CSV contents of failed records | このピルには、Quick Base での作成/更新に失敗したすべての CSV 行のコンテンツが含まれます。このピルを使用して、すべての失敗した行を含む CSV ファイルを作成し、後で修正して再提出することができます。 |
| List of chunks | これはリストピルです。このアクションは CSV を比較的小さな行のチャンクに分割するため、このリストにはこれらすべてのチャンクが含まれ、その属性が下に記載されています。 |
| Chunk number | このチャンクの ID。 |
| Successful import to Quick Base? | True または False の値です。 |
| Starting row | このチャンクの最初の CSV 行。 |
| Ending row | このチャンクの最後の CSV 行。 |
| Error code | このチャンクのインポート時に問題がある場合に Quick Base が返すエラーコード。 |
| Error text | このチャンクのインポート時に問題がある場合に Quick Base が返すエラーメッセージ。これは、CSV ファイルで何が問題なのかを調べることが必要な場合に役立ちます。 |
最終更新日: