サンプルユースケース - 変更データキャプチャ
毎日、ソースシステムで新しいデータが利用可能になり、これを取得してデスティネーションシステムにロードする必要があります。多くの場合、ソースアプリケーションは新規または更新されたデータだけではなく、データの完全な抽出しか提供できません。これにより、新規/更新されたデータの取得と取り込みが難しくなります。なぜなら、受信データと過去のデータを照合し、両者の差分のみを比較・抽出する必要があるからです。
SQL変換を使用すると、ユーザーは過去のデータと受信した抽出データを簡単に比較し、差分のみを1つのアクションで取得できます。過去のデータはWorkatoのファイルストレージ内に永続的に保存でき、外部データベースへの依存を軽減し、各抽出ごとに更新できます。受信データは、任意の業務アプリケーション、データベース、またはファイルシステムからのものが可能です。
SQL変換は抽出データを取得し、永続化された過去のデータと比較し、変更されたデータを出力として生成します。このユーティリティは、数百万行のデータ量を簡単に処理できるほど強力です。
サンプルレシピ:オンプレミスシステムから抽出を取得し、変更されたデータを見つけてS3にロードする
次のシナリオを考えてみましょう。ある企業が次のようなビジネスプロセスを持っています。
毎日、企業はすべての連絡先を抽出し、その記録をオンプレミスシステム上のCSVデータファイルとして利用可能にします。企業はこの抽出から新たに追加された連絡先のみを取得し、S3のようなクラウドストレージ先に送信したいと考えています。その後、別のWorkatoレシピがここからこの情報を取得して、ターゲットを絞ったマーケティングを行います。
連絡先の件数が非常に多いため(約150万件)、企業の一般的なワークフローは多くの手順で構成されています。Workatoレシピがソースからデータを抽出し、企業はすべての連絡先を外部データベースに過去のデータとして保存し、企業は新しい抽出を別のテーブルにロードし、2つのテーブルの差分を見つけて変更されたデータを取得しなければなりません。その後、さらなる処理のためにデータをWorkatoにロードし直す必要があります。
このプロセスは非常に面倒で、外部データベースシステムへの依存を生み出します。
SQL変換を使用すると、3つの簡単な手順で同じワークフローを実現できます!
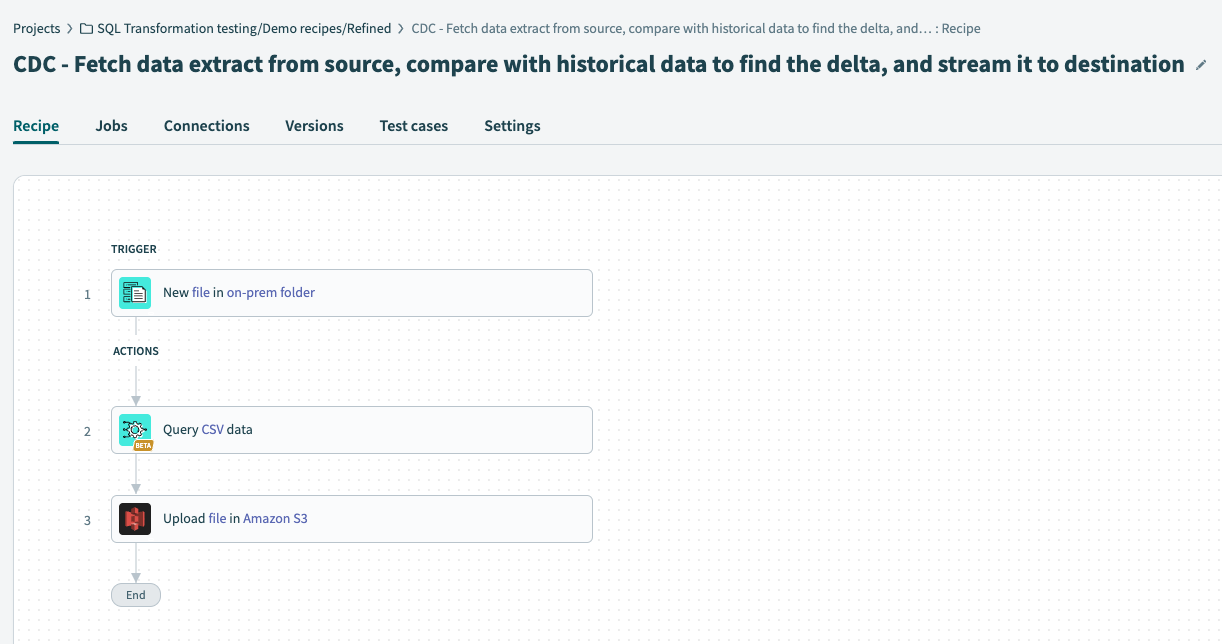 レシピのワークフロー
レシピのワークフロー
レシピのトリガーで、データを抽出する予定のソース(オンプレミスシステム)を設定し、新しい受信抽出を探すように設定します。
SQL変換コネクタの Query CSV アクションを設定します。これにより、抽出データと過去のデータを比較し、変更されたデータを出力として生成できます。
データをS3などのクラウドストレージ先に送信します。
変更データキャプチャのためにSQL変換を活用する方法
このセクションでは、SQL変換を変更データキャプチャに活用できるように、 Query CSV アクションのさまざまなセクションを設定する方法を説明します。
Follow along
See this recipe link to follow along and modify a sample recipe to suit your own workflow.
データソースの設定
SQL変換がクエリを実行するさまざまなデータソースを接続します。
Source #1 を接続するには、次のフィールドに入力します。私たちの例では、 Source #1 はオンプレミスシステムからの受信抽出データです。
データソース名
Data source name に意味のある名前を付けます。例えば contacts_extract のように。
データソースタイプ
Data source type を選択します。私たちの例では、アップストリームのオンプレミスシステムからCSVデータが入ってくるため、これは CSV content stream です。
CSVストリーム入力
データソースを CSV content stream に設定した後、CSVストリーム入力を設定できます。これは、オンプレミスファイルのトリガーから来るファイル内容を渡す場所です。
データスキーマ
Data schema を設定します。いくつかのサンプル連絡先データを含むCSVファイルをインポートすることで、これを簡単に行うことができます。
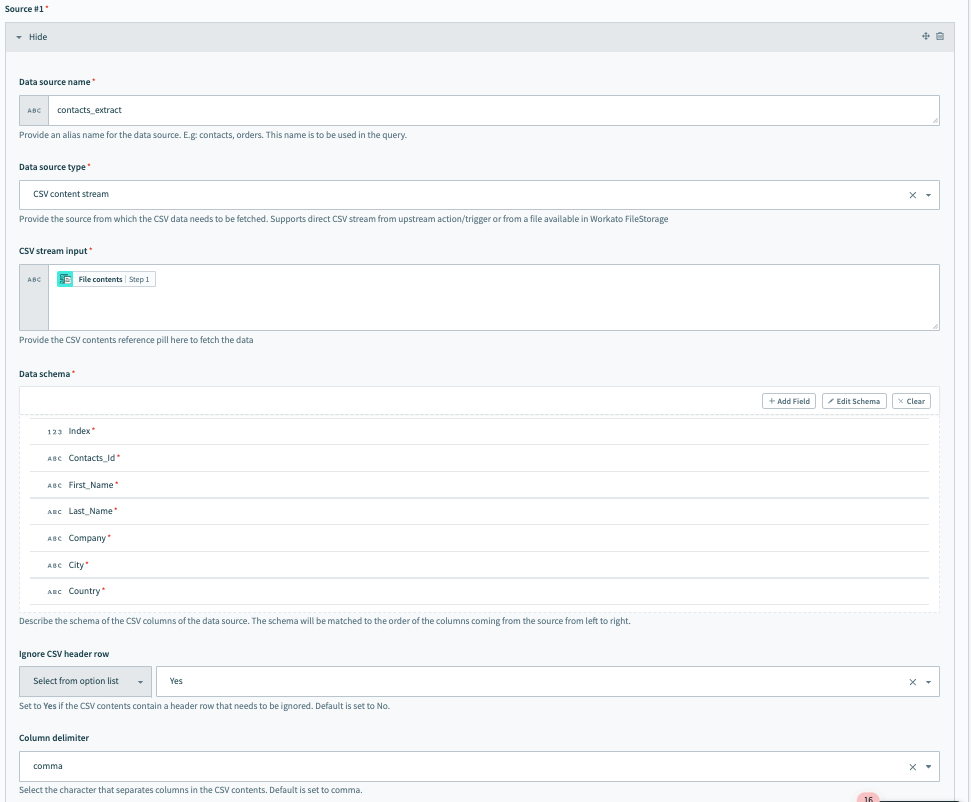 ソース #1 の設定、受信データ抽出
ソース #1 の設定、受信データ抽出
CSV固有のオプションを設定します。これらには次のフィールドが含まれます。
CSVヘッダ行を無視
これにより、受信データに無視すべき見出し列が含まれており、データの一部として考慮しないように指定できます。
カラム区切り文字
CSVファイルで列を区切るために使用される区切り文字を選択します。利用可能なオプションには、 , (カンマ)、 ; (セミコロン)などがあります。
Source 2 を接続するには、次のフィールドに入力します。私たちの例では、このソースは過去のデータを指します。このデータは、Workatoの内部永続ファイルストレージシステムであるFileStorageを使用して簡単に保存および処理できます。
データソース名
Data source name に意味のある名前を付けます。例えば contacts_historical のように。
データソースタイプ
Data source type を選択します。私たちの例では、これは FileStorage file です。
FileStorageファイルパス
過去のデータファイルが利用可能なFileStorage内のパスを指定します。
データスキーマ
Data schema を設定します。いくつかのサンプル連絡先データを含むCSVファイルをインポートすることで、これを簡単に行うことができます。スキーマは、ソースから来る列の左から右への順序に一致します。
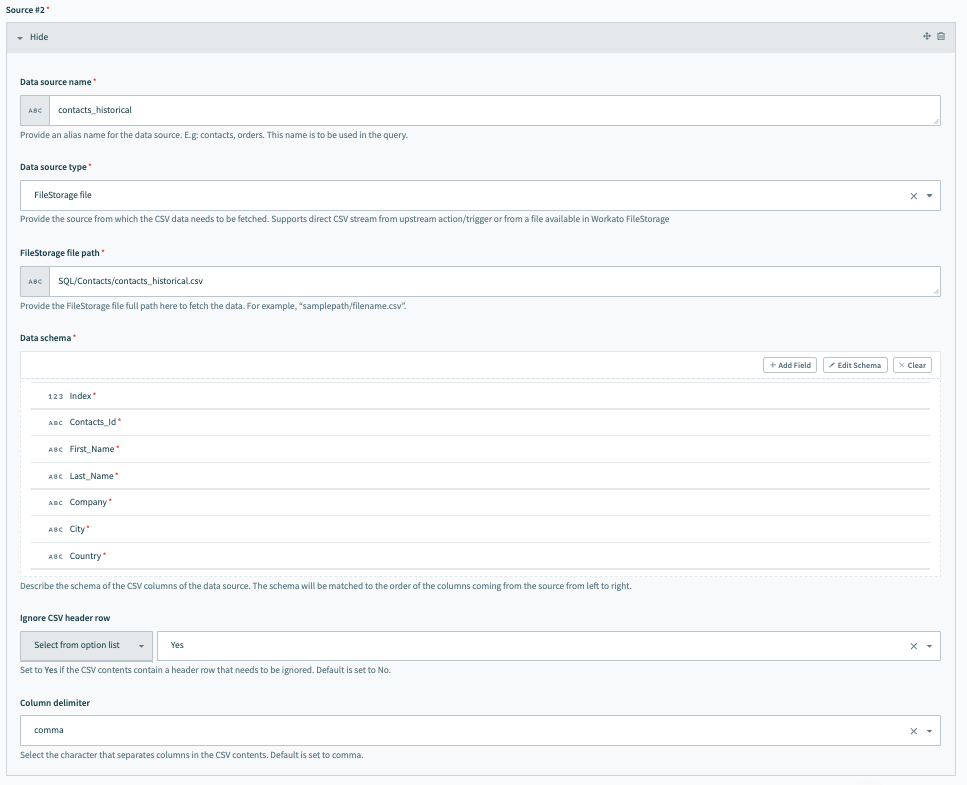 ソース #2 の設定、過去のデータ
ソース #2 の設定、過去のデータ
CSV固有のオプションを設定します。これらには次のフィールドが含まれます。
CSVヘッダ行を無視
これにより、受信データに無視すべき見出し列が含まれており、データの一部として考慮しないように指定できます。
カラム区切り文字
CSVファイルで列を区切るために使用される区切り文字を選択します。利用可能なオプションには、 , (カンマ)、 ; (セミコロン)などがあります。
クエリ設定
次に、データソース上で動作し、変換された出力を生成するクエリを設定します。
この例では、目的は連絡先の抽出から新しいレコードのみを取得することです。したがって、クエリは2つのデータソース( contacts_extract と contacts_historical)間で Contacts_Id を比較し、Contacts_Id が contacts_extract に存在し contacts_historical には存在しないレコードを返します。これは、Workatoが過去のデータにない新しく作成された連絡先を返すことを意味します。
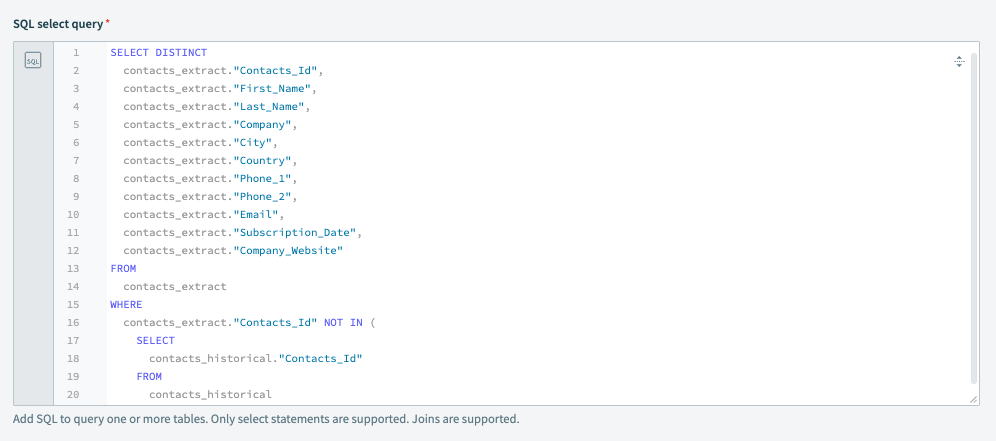
出力設定
最後に、次のフィールドを設定して出力の形式を定義します。
私たちの例では、新しいレコードデータをS3に送信してさらに処理します。
次のフィールドに入力します。
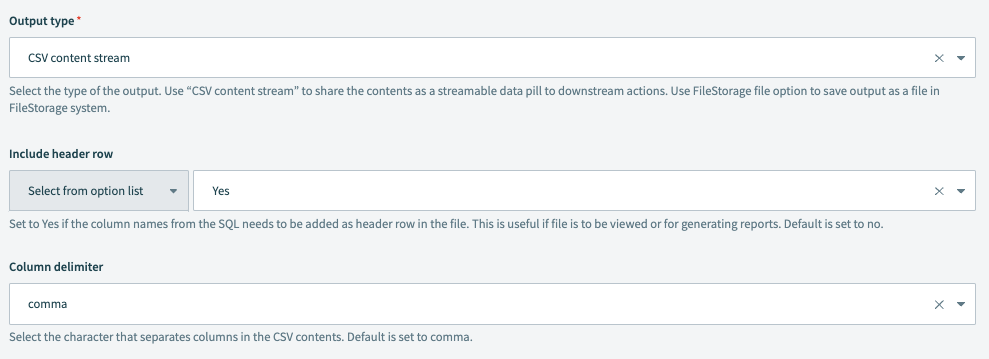
出力タイプ
出力のタイプを選択します。CSV content stream を使用して、コンテンツをストリーム可能なデータピルとしてダウンストリームのアクションと共有します。
ヘッダ行を含める
データの列名をファイルのヘッダ行として追加する必要がある場合は Yes に設定します。これは、レポートを生成するためにファイルを使用する予定の場合に便利です。デフォルト値は No です。
カラム区切り文字
CSVファイルで列を区切るために使用される区切り文字を選択します。利用可能なオプションには、 , (カンマ)、 ; (セミコロン)などがあります。
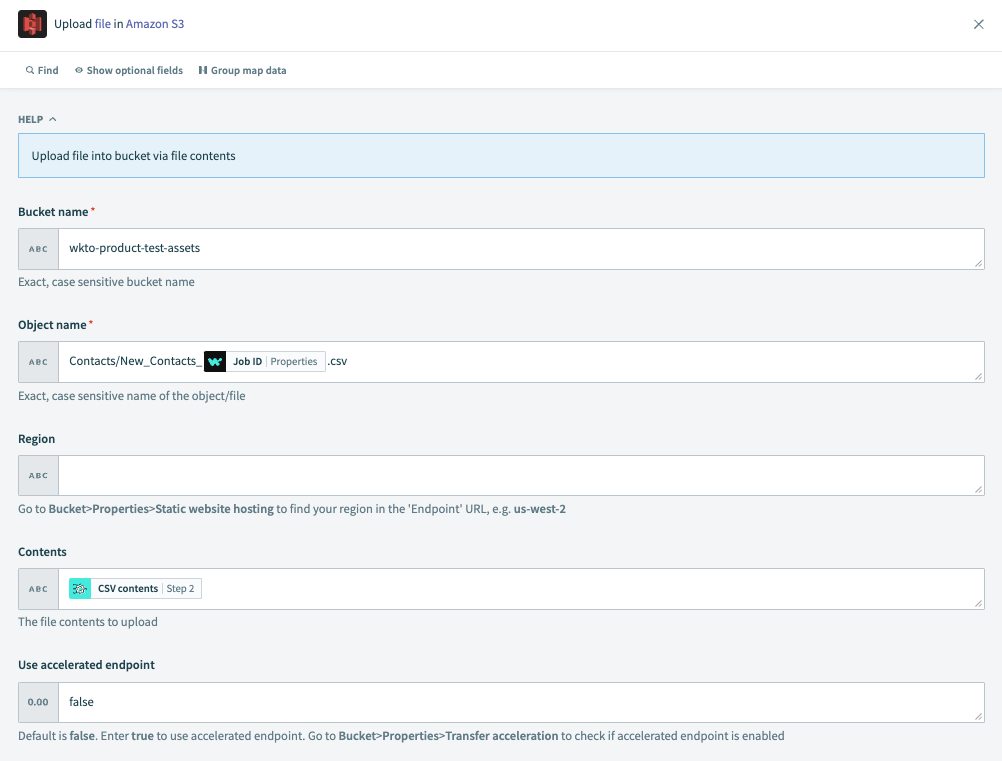
Upload file in Amazon S3 アクションを選択します。
次のフィールドを設定します。
バケット名
バケットの正確な大文字小文字区別のある名前。
オブジェクト名
オブジェクト/ファイルの正確な大文字小文字区別のある名前。
リージョン
お使いのリージョンを見つけるには、S3で Bucket > Properties > Static website hosting をナビゲートして、
Endpoint URL内のリージョンを見つけます。例:us-west-2。コンテンツ
アップロードする予定のファイル内容。Step 2 Query CSV data アクションから CVS contents データピルを渡します。
高速化エンドポイントを使用
デフォルトは false です。高速化エンドポイントを使用するには true に設定します。S3で Bucket > Properties > Transfer acceleration に移動して、高速化エンドポイントが有効になっているか確認します。
次を読む
Last updated: