メモリ最適化のベストプラクティス
すべてのレシピジョブは、有限のメモリ割り当てを持つコンテナー内で実行されます。 レシピ内のアクションにより、コンテナーのメモリが不足する場合があります。 これにより、Temporary job dispatch failureエラーが発生します。 推奨される解決策を含む一般的なレシピ設計上の問題を以下に示します。
大きなバッチでアクションを繰り返す
1つのジョブで大きなバッチを処理すると、合計処理時間を短縮できます。 これは、多数のプロダクションレシピで使用されている非常に一般的な設計パターンです。 しかし、これらのバッチを適切に処理しないと、メモリ使用量がすぐに大きくなる可能性があります。
問題のあるパターン
一般的なミスは、大きなバッチをループし、個別に処理することです。 さらに悪いことに、各反復で複数のステップが必要になることがよくあります。 たとえば、従業員レコードのバッチをループ処理する場合、レシピロジックでは、新しいレコードを更新または作成する前に、既存のレコードを検索する必要がある場合があります。 これにより、メモリ使用率が非常に高くなる可能性があります。
解決策: バッチアクションを組み合わせる
バッチ処理により、大きなレコードバッチを扱うコストを大幅に削減できます。 また、合計スループットを向上させる利点もあります。 推奨される手順を以下に示します:
- ループ内で検索、更新、作成を行う代わりに、batch upsertアクションを使用します。 (例: SQL Server upsert rowsアクション)
- ソースと宛先のバッチサイズが一致しない場合は、個別に繰り返すのではなくrepeat in batchesを使用します。
大きなファイルのメモリへのロード
大きなファイルの転送中にメモリの問題が発生するのを回避するため、Workatoアクションはストリーミング機能を使用します。 これにより、ジョブの実行時にメモリを消費せずに、ジョブで大きなファイルを転送できます。
問題のあるパターン
一般的なユースケースは、bytesize Formulaを使用してファイルサイズを確認することです。 これは、ファイルサイズを計算するためにアクションがファイル全体をメモリにダウンロードすることを強制するため、推奨されません。
解決策: ファイルメタデータ出力を使用する
すべてのfile streamingアクションには、出力datatreeにファイルに関する追加情報が含まれています。 これらのデータピルを使用すると、メモリに過負荷をかけずにファイルサイズなどのメタデータを判定できます。 たとえば、Amazon S3 Download fileアクションのサイズデータピルを使用できます。
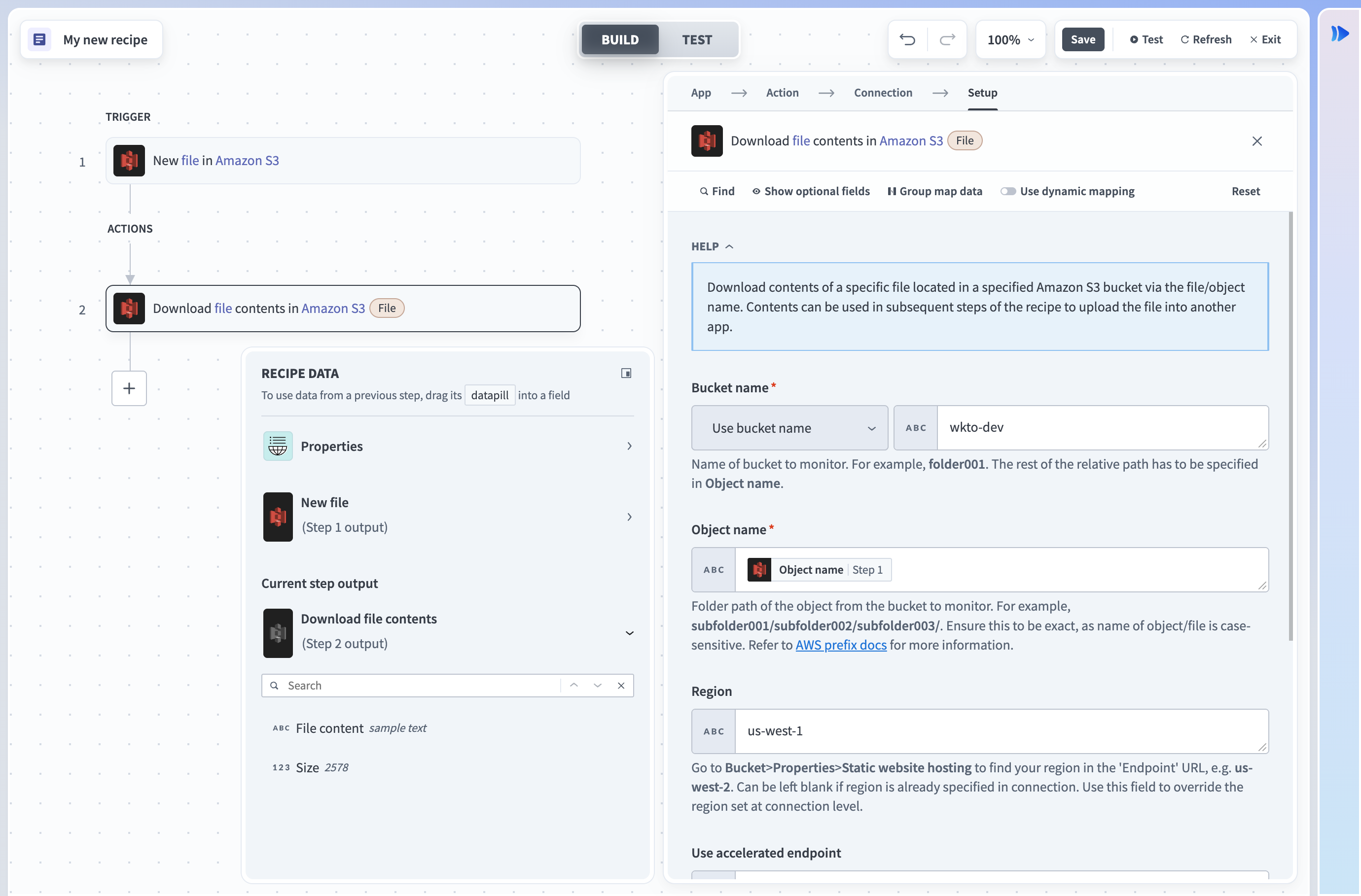 Amazon S3 - Download fileアクション
Amazon S3 - Download fileアクション
その他の推奨事項
- 可能な限りfile streamingを使用します。特にファイルが100 MBを超える場合に使用してください。
- JDBC Exportアクションを使用して、大きなクエリ結果セットを転送します
Collectionsの不要な使用
Collectionsはインメモリデータベースです。 このツールを使用すると、データウェアハウスにロードする前に、さまざまなソースのデータセットを結合できます。 しかし、レシピでCollectionsを過剰に使用すると、メモリの問題が発生する可能性があります。
問題のあるパターン
一般的なミスは、Collectionsを使用してCSVファイルを解析することです。 Collectionsは適切な選択肢のように思えるかもしれませんが、効率的ではありません。 実際、このアプローチではデータをクエリするための追加ステップが必要です。
解決策: CSV Parser
CSV Parserを使用すると、追加コストを発生させずに同じ結果を得ることができます。
最終更新日: