SQL Server
SQL Serverは、Microsoftのリレーショナルデータベース管理システムです。 企業向けのトランザクション処理、ビジネスインテリジェンス、および分析アプリケーションをサポートします。 WorkatoのSQL Server連携は、データの移行、データウェアハウスやデータレイクへのデータパイプラインの構築、データの自動バックアップ、複雑なワークフローを構築するためのデータ変換やエクスポートなど、幅広いタスクの実行に役立ちます。 WorkatoからSQL Serverへのコネクションを設定する方法、およびWorkatoがSQL Serverと連携してビジネスニーズを満たす方法について説明します。
サポートされているバージョン
SQL Serverのすべてのバージョンがサポートされています。 ただし、一部のトリガーとアクションは新しいバージョンに制限されています。 詳細については、各トリガーおよびアクションのドキュメントを参照してください。
SQL Serverへの接続方法
SQL Serverコネクターは、次のコネクションタイプをサポートしています:
クラウド
クラウドコネクションを使用してSQL Serverに接続するには、次の手順を実行します:
作成 > コネクションをクリックするか、Cを2回押します。
新規コネクションページで、コネクションとしてSQL Serverを検索して選択します。
Workatoが接続するSQL Serverインスタンスを識別するコネクション名を入力します。
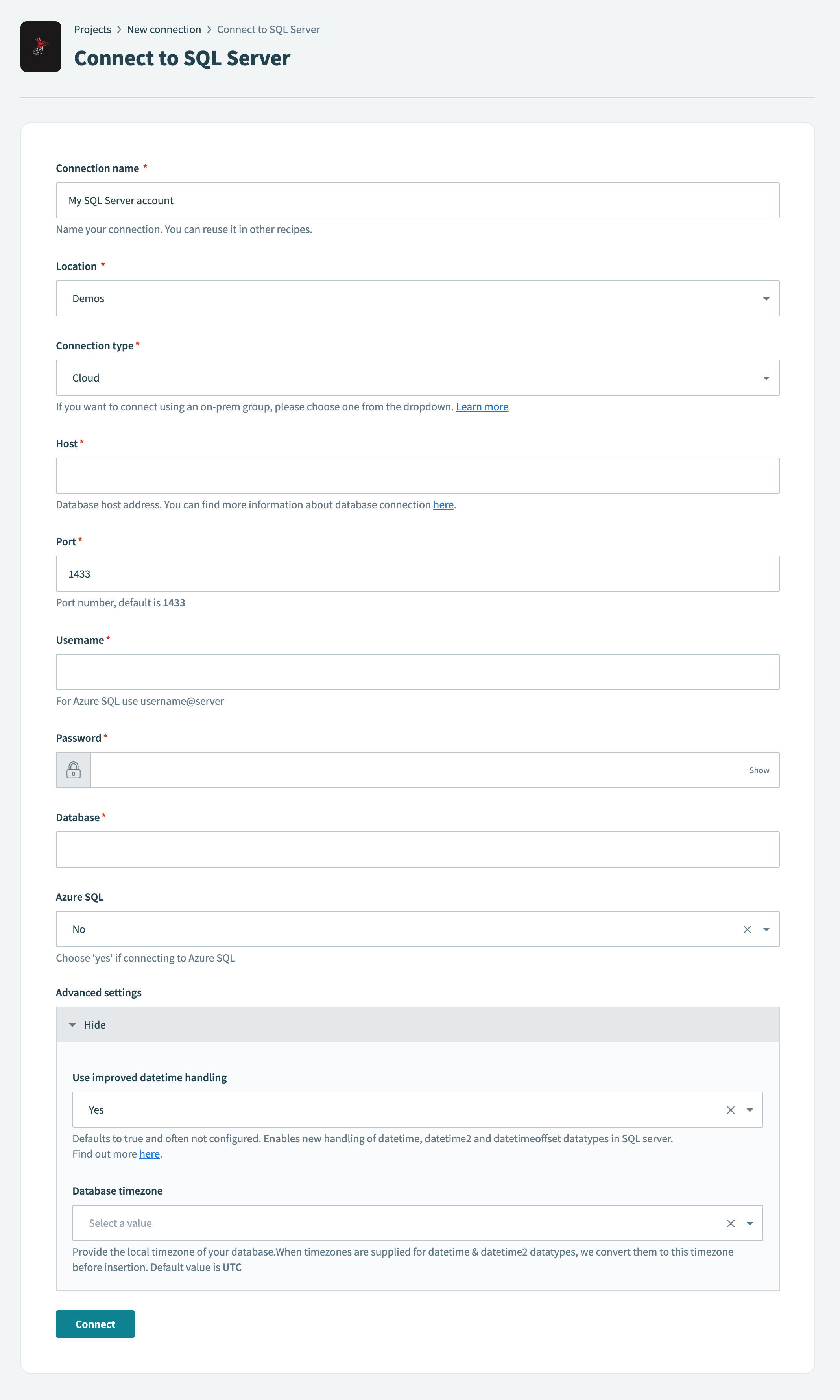 クラウドコネクションを使用してSQL Serverに接続
クラウドコネクションを使用してSQL Serverに接続
ロケーションドロップダウンメニューを使用して、このコネクションを保存するプロジェクトまたはフォルダを選択します。
コネクションタイプドロップダウンメニューを使用して、クラウドを選択します。
ホストされているサーバーのURLをホストフィールドに入力します。
サーバーが実行されているポート番号をポートフィールドに入力します。 SQL Serverのデフォルトポートは1433です。
SQL Serverに接続するユーザー名をユーザー名フィールドに入力します。
SQL Serverに接続するパスワードをパスワードフィールドに入力します。
接続するSQL Serverデータベースの名前をデータベースフィールドに入力します。
任意です。 Azure SQLフィールドで、Azure SQLインスタンスに接続するかどうかを指定します。 デフォルトはいいえです。
任意です。 追加設定を構成するには、詳細設定フィールドを展開します:
| フィールド | 説明 |
|---|---|
| 改善された日時処理を使用 | SQL Serverのdatetime、datetime2、およびdatetimeoffsetデータ型の拡張処理を有効にします。 デフォルトはtrueです。 詳細については、改善された日時処理セクションを参照してください。 |
| データベースのタイムゾーン | データベースのローカルタイムゾーンを設定します。 datetimeおよびdatetime2データ型にタイムゾーンが指定されている場合、値は挿入前にこのタイムゾーンに変換されます。 デフォルトはUTCです。 |
接続をクリックします。
オンプレミス
オンプレミスコネクションを使用してSQL Serverに接続するには、次の手順を実行します:
作成 > コネクションをクリックするか、Cを2回押します。
新規コネクションページで、コネクションとしてSQL Serverを検索して選択します。
Workatoが接続するSQL Serverインスタンスを識別するコネクション名を入力します。
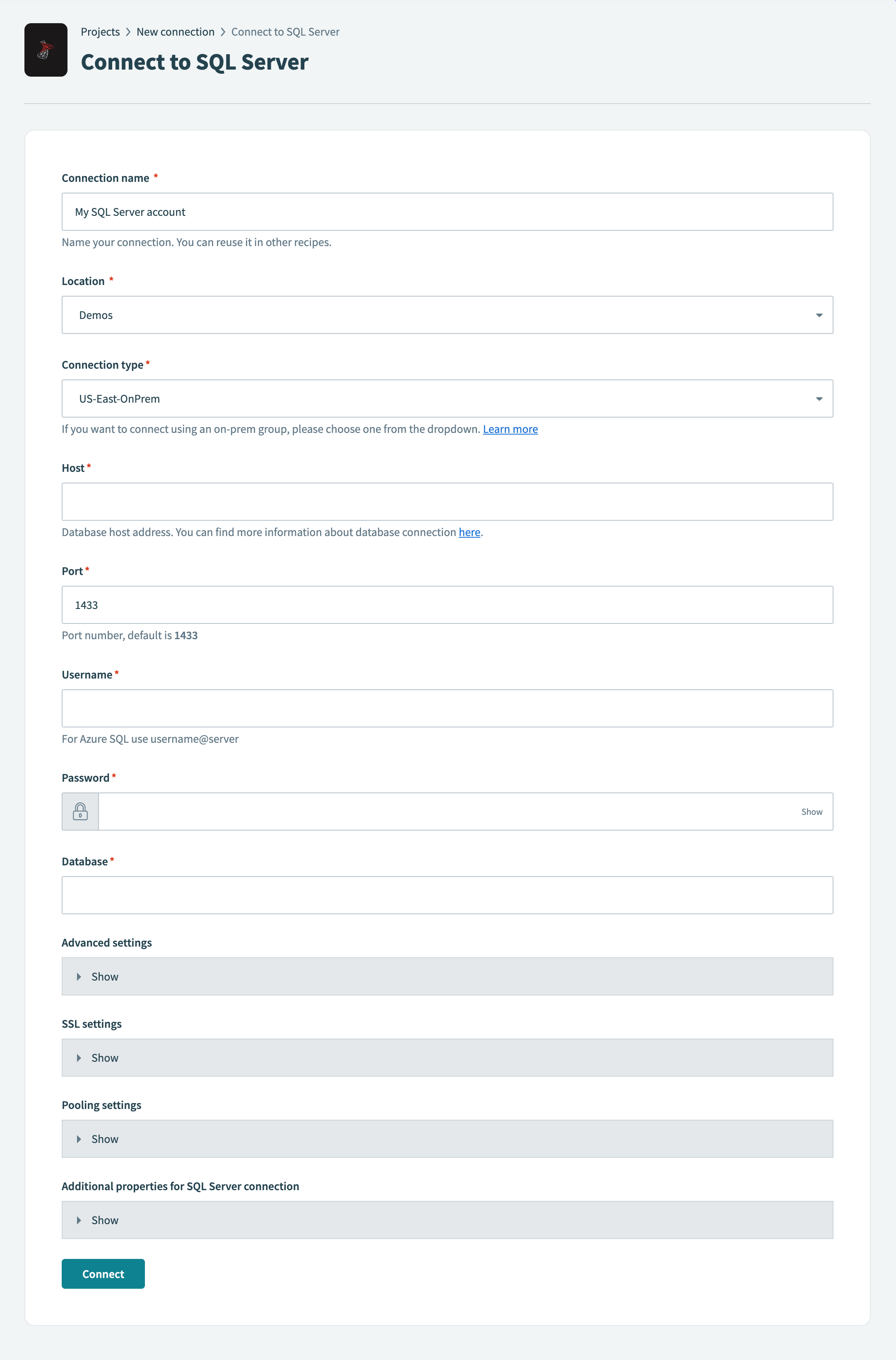 オンプレミスコネクションを使用してSQL Serverに接続
オンプレミスコネクションを使用してSQL Serverに接続
ロケーションドロップダウンメニューを使用して、このコネクションを保存するプロジェクトまたはフォルダを選択します。
コネクションタイプドロップダウンメニューを使用して、オンプレミスグループを選択します。
ホストされているサーバーのURLをホストフィールドに入力します。
サーバーが実行されているポート番号をポートフィールドに入力します。 SQL Serverのデフォルトポートは1433です。
SQL Serverに接続するユーザー名をユーザー名フィールドに入力します。
SQL Serverに接続するパスワードをパスワードフィールドに入力します。
接続するSQL Serverデータベースの名前をデータベースフィールドに入力します。
任意です。 追加設定を構成するには、詳細設定セクションを展開します:
| フィールド | 説明 |
|---|---|
| 改善された日時処理を使用 | SQL Serverのdatetime、datetime2、およびdatetimeoffsetデータ型の拡張処理を有効にします。 デフォルトはtrueです。 詳細については、改善された日時処理セクションを参照してください。 |
| データベースのタイムゾーン | データベースのローカルタイムゾーンを設定します。 datetimeおよびdatetime2データ型にタイムゾーンが指定されている場合、値は挿入前にこのタイムゾーンに変換されます。 デフォルトはUTCです。 |
任意です。 次のフィールドを構成するには、SSL設定セクションを展開します:
| フィールド | 説明 |
|---|---|
| サーバー証明書 | X509サーバー証明書を.pem形式で指定します。 |
| SSL証明書 | X509クライアント証明書を.pem形式で指定します。 |
| SSL証明書キー | RSAクライアントキーを.pem形式で指定します。 |
| すべて信頼 | クライアントが任意の証明書チェーンを信頼するかどうかを指定します。 自己署名サーバー証明書がサポートされています。 |
任意です。 コネクションプールの動作を設定するには、プーリング設定セクションを展開します:
| フィールド | 説明 |
|---|---|
| 最小プールサイズ | アイドル状態とアクティブ状態のコネクションを含め、OPAがプール内で維持する最小コネクション数を設定します。 デフォルトは1です。 |
| 最大プールサイズ | 最大プールサイズを設定します。 プールがいっぱいで使用可能なアイドルコネクションがない場合、新しいコネクション要求はタイムアウトまでブロックされます。 デフォルトは10です。 |
| アイドルタイムアウト | 削除されるまでコネクションがアイドル状態で保持される時間を秒単位で設定します。 アイドルコネクションを削除しない場合は0を使用します。 デフォルトは30分です。 |
| 最大有効期間 | コネクションの最大有効期間を秒単位で設定します。 コネクションは、最近使用された場合でも、この期間に達すると削除されます。 デフォルトは30分です。 |
| タイムアウト | クライアントがプールコネクションを待機する時間を秒単位で設定します。 タイムアウトなしにするには0を使用します。 デフォルトは30秒です。 |
任意です。 Windows AuthenticationまたはManaged Identityに必要なプロパティなど、カスタムコネクションパラメーターを追加するには、SQL Serverコネクションの追加プロパティセクションを展開します。
接続をクリックします。
Windows Authentication
オンプレミスコネクションの設定に従ってから、SQL Serverコネクションの追加プロパティセクションを展開し、integratedSecurity: trueを追加します。 ユーザー名およびパスワードフィールドは空白のままにできます。
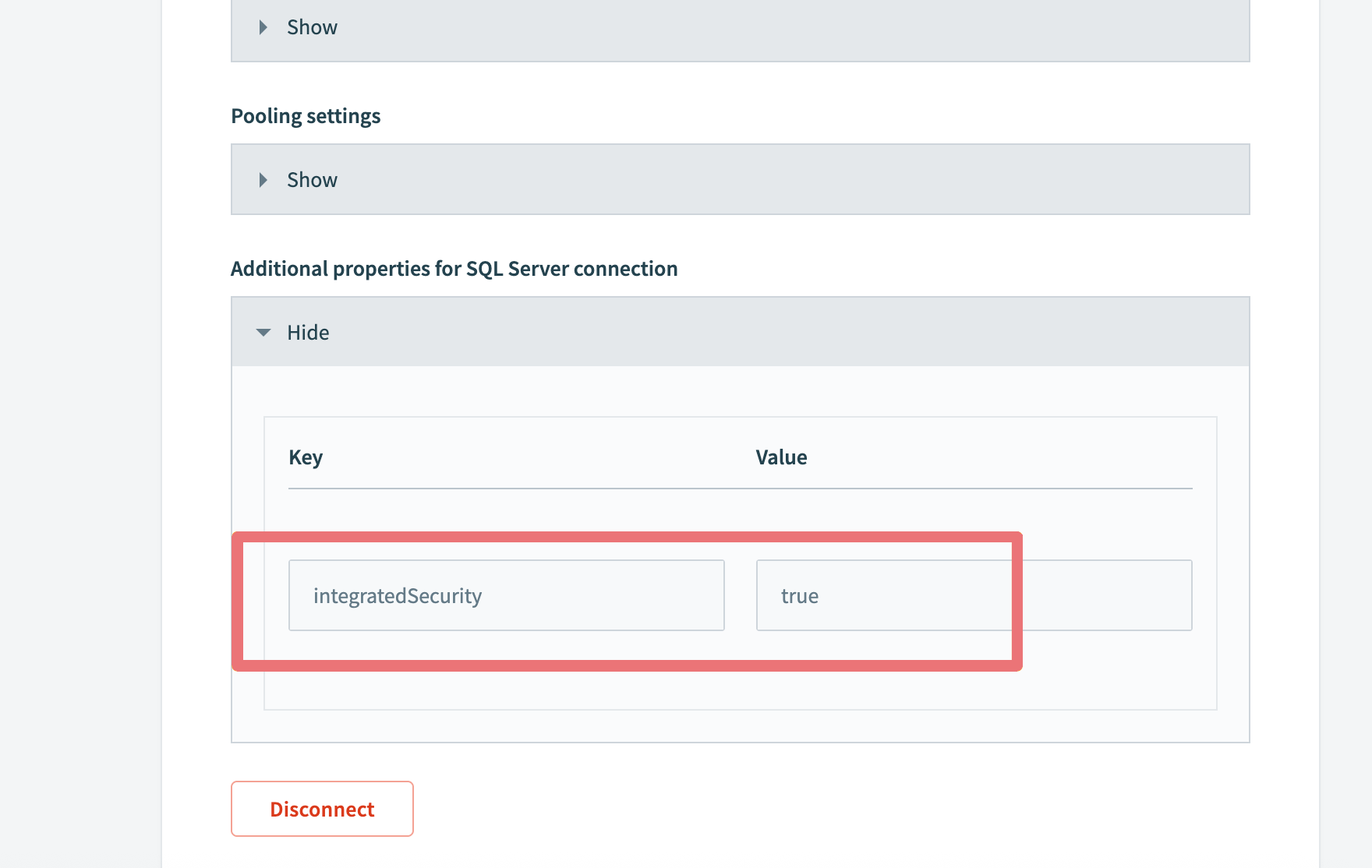 Windows認証コネクションで
Windows認証コネクションでintegratedSecurityをtrueに設定
Managed Identity
オンプレミスコネクションの設定に従ってから、SQL Serverコネクションの追加プロパティセクションを展開し、次を追加します:
| キー | 値 |
|---|---|
authentication | ActiveDirectoryMSI |
msiClientId | SQL Serverへのアクセス権が付与されているAzure内のManaged IdentityのクライアントIDを入力します。 |
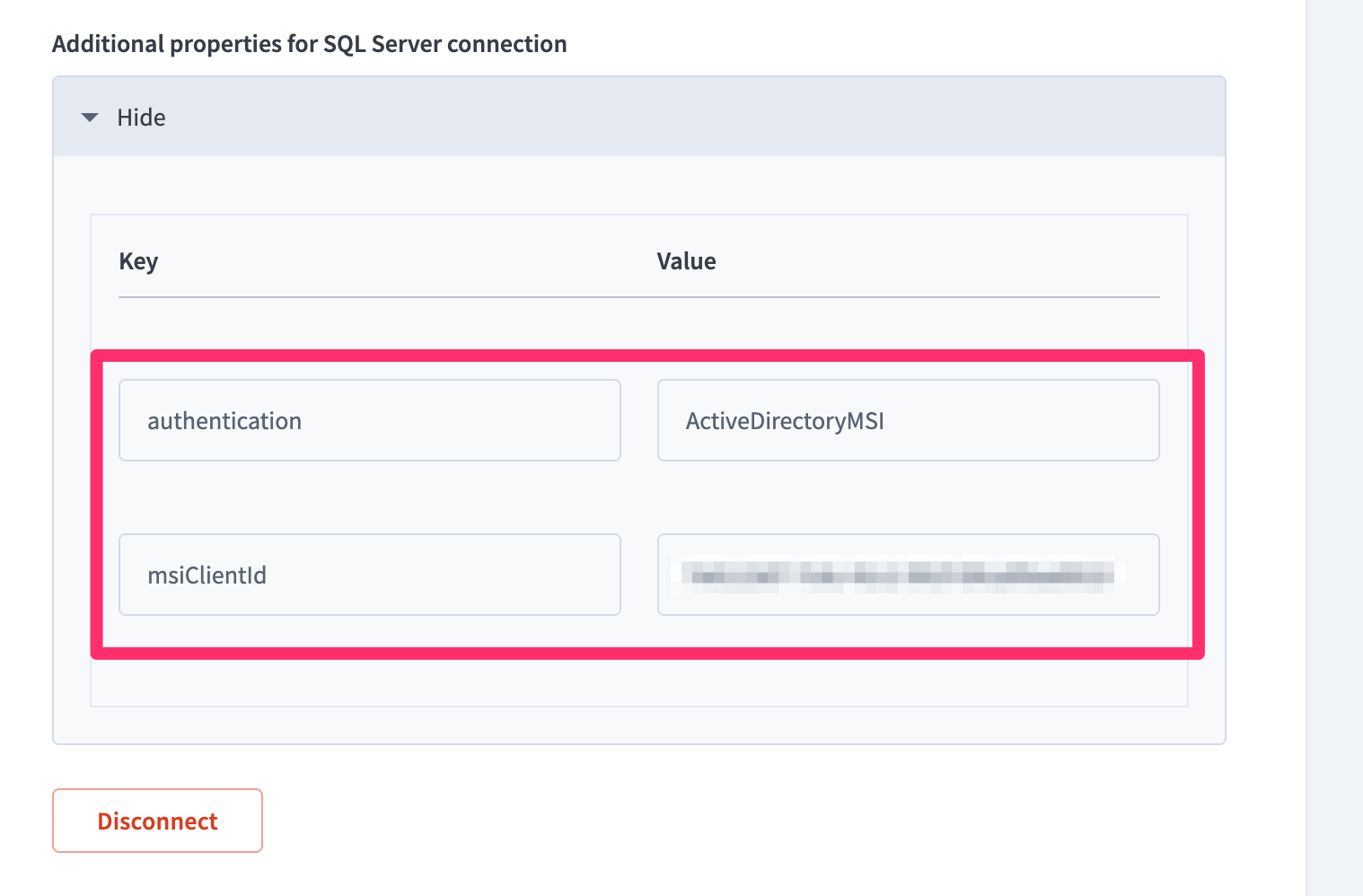 追加プロパティセクションでManaged Identityプロパティを追加
追加プロパティセクションでManaged Identityプロパティを追加
ユーザー名およびパスワードフィールドは空白のままにできます。
改善された日時処理
SQL Serverコネクターでは、datetime、datetime2、およびdatetimeoffsetデータ型の改善された処理を利用するオプションを使用できるようになりました。 これは、各SQL Serverコネクションのコネクション設定で有効にできます。 すべての新規コネクションでは、デフォルトでYesに設定され、タイムゾーンはデフォルトでUTCになります。 必要に応じて、これをデータベースのローカルタイムゾーンに変更します。 これは、SQL Serverに行を挿入するすべてのアクションに影響します。
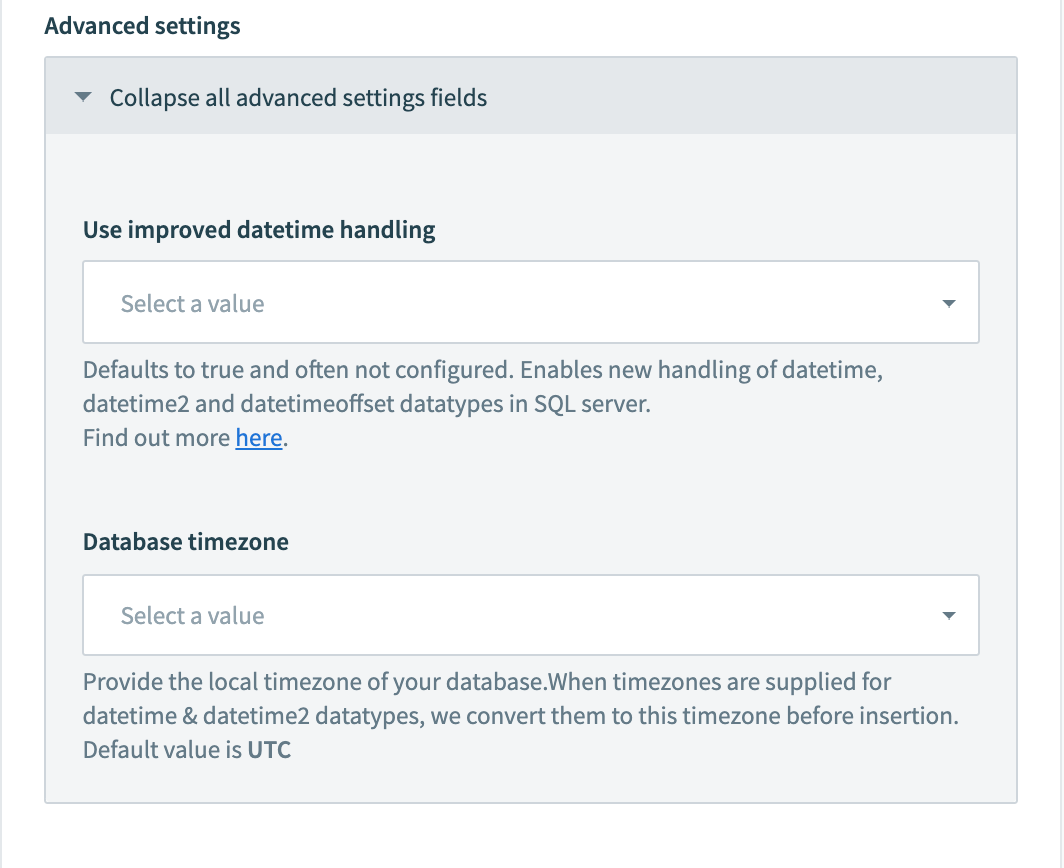 SQL Serverコネクションの設定でこれを構成
SQL Serverコネクションの設定でこれを構成
動作の概要
| データ型 | Workato入力 | 改善された日時処理がfalse/未選択に設定されている場合 | 改善された日時処理がtrueに設定されている場合 |
|---|---|---|---|
| datetime/datetime2 | タイムゾーンなしの時刻 | Workatoワークスペースのタイムゾーンと見なされます。 挿入前にUTCに変換されます。 | TZは想定されません。 そのまま挿入されます。 |
| datetime/datetime2 | タイムゾーン付きの時刻 | 挿入前にUTCに変換されます。 | 挿入前に、コネクション設定のタイムゾーンにあるデータベースタイムゾーンに変換されます。 |
| datetimeoffset | タイムゾーンなしの時刻 | Workatoワークスペースのタイムゾーンと見なされます。 +00:00 tzを付けて挿入前にUTCに変換されます | +00:00タイムゾーンが想定されて挿入されます。 |
| datetimeoffset | タイムゾーン付きの時刻 | +00:00タイムゾーンを付けて挿入前にUTCに変換されます。 | 指定されたタイムゾーンで挿入します。 |
メモ
datetime/datetime2/datetimeoffsetフィールドでカレンダー日付ピッカーを使用する場合、時刻はWorkatoワークスペースのタイムゾーンを使用して定義されます。
接続に必要な権限
少なくとも、データベースユーザーアカウントには、コネクションで指定されたデータベースへのSELECT権限が付与されている必要があります。 ビジネス用のSQL Serverコネクションを設定する担当者である場合は、権限の設定方法について、以下の例を確認してください。
権限の設定方法を確認するには、ここをクリックしてください
SQL Serverインスタンス内の名前付きデータベース(HR_PROD)に、新しいデータベースユーザーworkatoを使用して接続する場合、次のサンプルクエリを使用できます。
まず、Workatoとの連携ユースケース専用の新しいログインとユーザーを作成します。
CREATE LOGIN workato WITH PASSWORD = 'password1234';
USE HR_PROD;
CREATE USER workato FOR LOGIN workato;
password1234をセキュアなパスワードに置き換えます。 自分と組織内の他のユーザーが覚えられるパスワードを設定してください。
これにより、ユーザーはSQL Serverインスタンスにログインアクセスできるようになります。 ただし、このユーザーはどのテーブルにもアクセスできません。
次の手順は、必要なテーブルへの権限を付与することです。 これを行う方法はいくつかあります。 最も簡単な方法の1つは、ROLEに基づいてアクセス権を付与することです。
データベースレベルのロールについて詳しくはこちら
ALTER ROLE db_datareader ADD MEMBER workato;
または、SCHEMA(HR)で定義されているすべてのテーブルへのアクセス権を付与できます。
GRANT SELECT,INSERT ON SCHEMA :: HR TO workato;
特定のテーブルのみに権限を付与するには、テーブル名を個別に指定し、このクエリを実行します。
GRANT SELECT,INSERT ON tablename1 TO workato;
GRANT SELECT,INSERT ON tablename2 TO workato;
選択的な権限付与は、機密情報を含むデータベースに役立ちます。 レシピに必要な情報を含むテーブルにのみ、Workatoへのアクセス権を付与します。
最後に、このユーザーに必要な権限があることを確認します。 すべての権限を表示するクエリを実行します。
SELECT
pr.name,
pr.type_desc,
perm.permission_name,
perm.class_desc,
object_name(perm.major_id) AS "object",
schema_name(perm.major_id) AS "schema"
FROM sys.database_principals pr
LEFT JOIN sys.database_permissions perm ON perm.grantee_principal_id = pr.principal_id
WHERE pr.name = 'workato';
これにより、WorkatoでSQL Serverコネクションを作成するための次の最小権限が返されます。
+---------+-----------+-----------------+------------+--------+-------------+
| name | type_desc | permission_name | class_desc | object | schema |
+---------+-----------+-----------------+------------+--------+-------------+
| workato | SQL_USER | CONNECT | DATABASE | NULL | NULL |
| workato | SQL_USER | INSERT | SCHEMA | NULL | workatodemo |
| workato | SQL_USER | SELECT | SCHEMA | NULL | workatodemo |
+---------+-----------+-----------------+------------+--------+-------------+
3 rows in set (0.20 sec)
SQL Serverコネクターの使用
テーブル、ビュー、およびストアドプロシージャの使用
SQL Serverへの接続に成功し、レシピでアクション/トリガーを選択すると、多くの場合、テーブル、ビュー、またはストアドプロシージャのいずれかを選択するよう求められます。 これにより、データの取得元または送信先にするテーブルがWorkatoに指定されます。
テーブルとビュー
SQL Serverコネクターは、すべてのテーブルとビューで動作します。 これらは各トリガー/アクションのピックリストで使用できます。または、正確な名前を指定できます。 ビューも同様に呼び出すことができ、テーブルと同じ方法で使用できます。
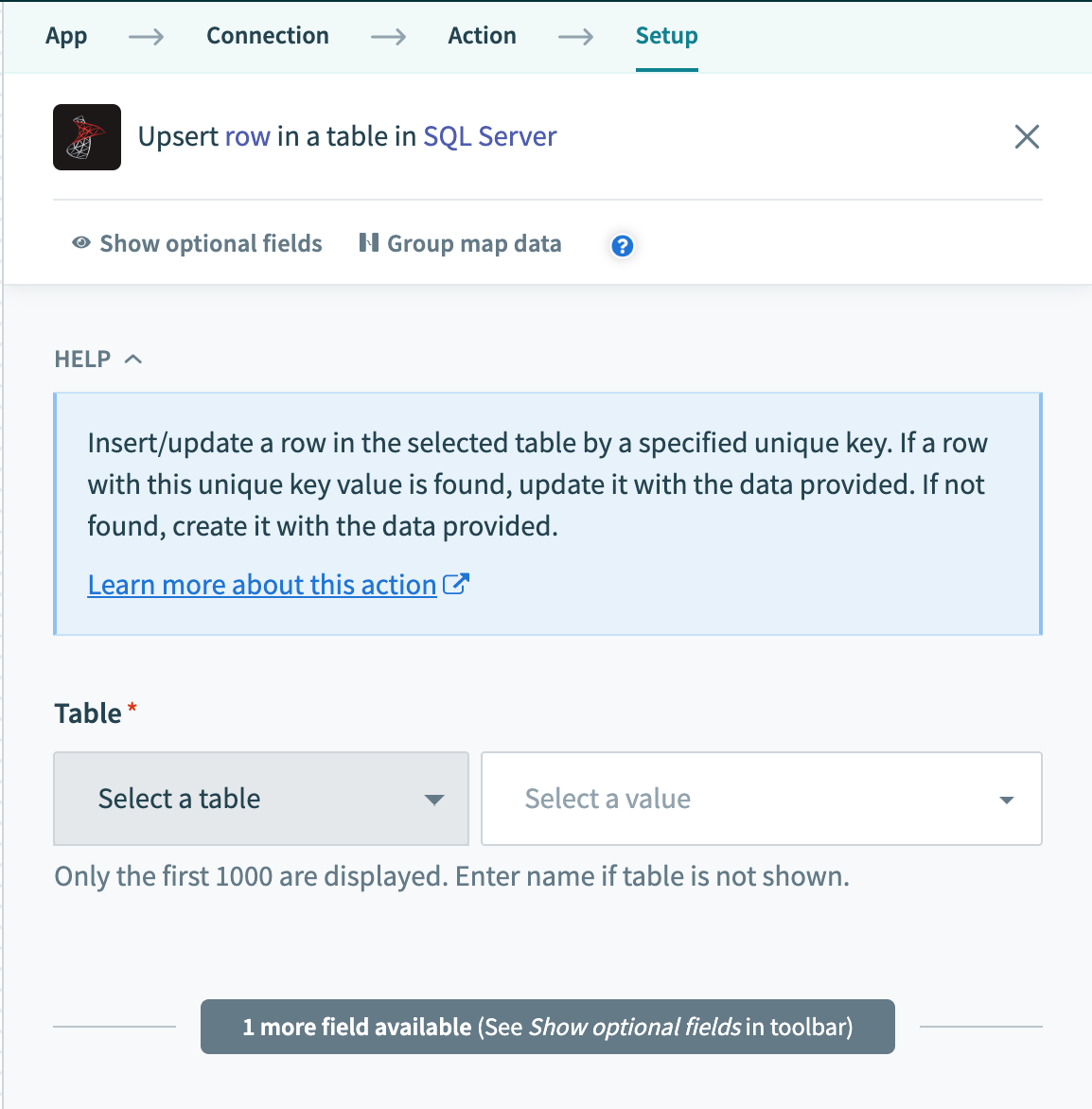 ピックリストからテーブル/ビューを選択
ピックリストからテーブル/ビューを選択
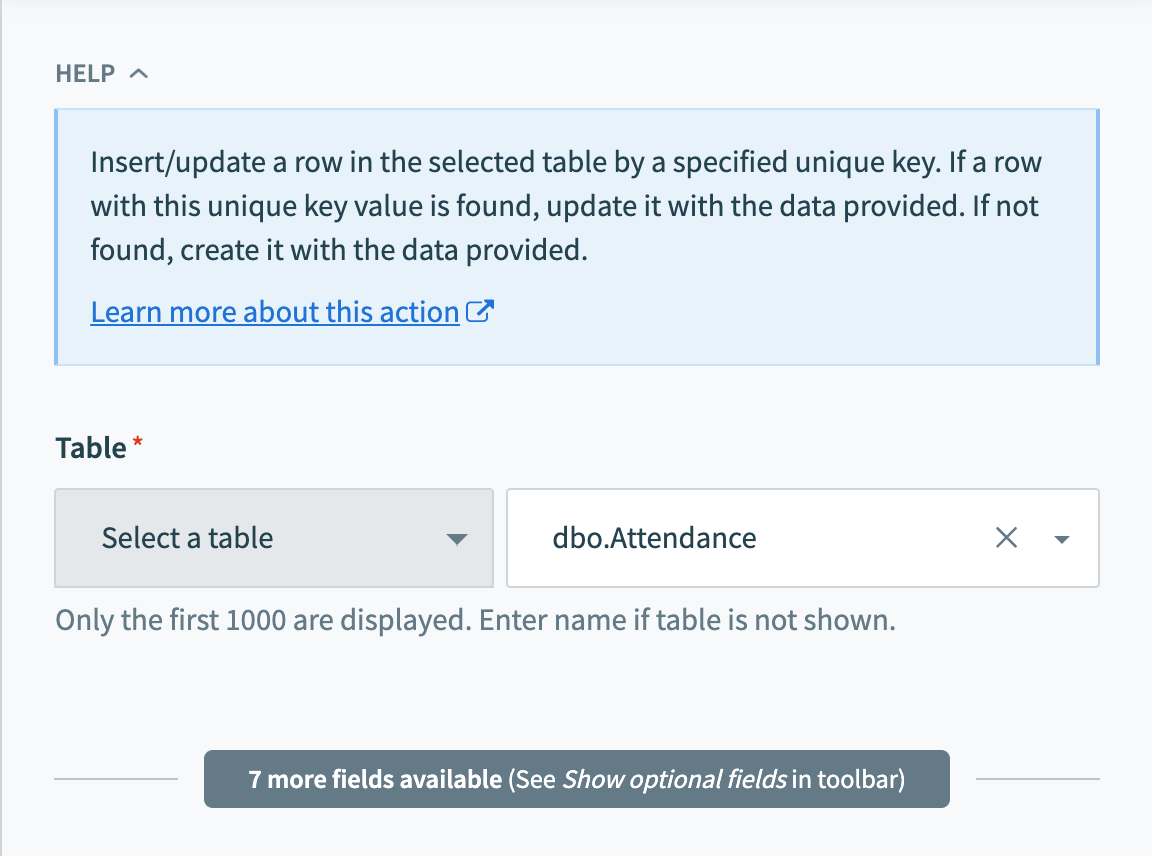 テキストフィールドに正確なテーブル/ビュー名を入力
テキストフィールドに正確なテーブル/ビュー名を入力
テーブル/ビュー名の大文字と小文字の区別は、データベースの実装によって異なります。 デフォルトのSQL Serverでは、大文字と小文字は区別されません。 COLLATIONにCSが含まれるデータベースまたはデータベースオブジェクトは、大文字と小文字が区別されることを示します。
ストアドプロシージャ
ストアドプロシージャは、SQL Server内で記述および保存されるカスタムSQL文です。 行の作成、更新、削除など、さまざまな機能を実行できます。 パラメーターを受け入れることもできます。 Workatoがストアドプロシージャと連携する方法の詳細を確認してください。
WHERE条件の使用
この入力フィールドは、アクションを実行する行をフィルタリングして識別するために使用されます。 次の方法で複数のトリガーおよびアクションで使用されます:
- トリガーで取得する行をフィルタリング
- Select rowsアクションで行をフィルタリング
- Delete rowsアクションで削除する行をフィルタリング
この句は、各リクエストでWHEREステートメントとして使用されます。 これは基本的なSQL構文に従う必要があります。 WHERE文を構築するための包括的なルール一覧については、このSQL Serverドキュメントを参照してください。 以下では、WHERE文を作成するために必要ないくつかの基本事項を説明します。
TIP
以下の例は、ユーザー入力でWHERE条件を直接使用する方法を示しています。 セキュリティを強化するには、SQLインジェクションを防ぐためにパラメーター付きのWHERE条件を使用します。 詳細はこちら
演算子
あらゆるWHERE文の基礎には、Workatoで返す行をフィルタリングおよび識別するのに役立つ演算子があります。 SQLで行うのと同じ方法で演算子を連結することで、Workatoから直接、データに対して堅牢で複雑なフィルターを作成できます。
演算子の一覧を表示するには、ここをクリックしてください
| Operator | 説明 | 例 |
|---|---|---|
| = | 等しい | WHERE ID = 445 |
| != <> | 等しくない | WHERE ID <> 445 |
| > >= | より大きい 以上 | WHERE PRICE > 10000 |
| < <= | より小さい 以下 | WHERE PRICE > 10000 |
| IN(...) | 値のリスト | WHERE ID IN(445, 600, 783) |
| LIKE | ワイルドカード文字(%は0文字以上を表し、_は1文字を表す)によるパターンマッチング | WHERE EMAIL LIKE '%@workato.com' |
| BETWEEN | 範囲を指定して値を取得 | WHERE ID BETWEEN 445 AND 783 |
| IS NULL IS NOT NULL | NULL値のチェック NULL以外の値のチェック | WHERE NAME IS NOT NULL |
| AND | 真になるには、前後の両方の条件が満たされる必要があります | WHERE ID = 445 AND NAME IS NOT NULL |
| OR | 真になるには、前後のいずれかの条件が満たされる必要があります | WHERE ID = 445 OR NAME IS NOT NULL |
データ型
WHERE条件のもう1つの要素は、これらの演算子を適切なデータ型と組み合わせて使用することです。 WHERE文を記述する場合は、テーブル内のdata type = integerの変数を、data type = stringではなくdata type = integerの変数と比較してください。
Workatoでは、選択時に各入力フィールドで想定されるデータ型も表示されます
- Update rowsアクション
- Upsert rowsアクション
これらは出力フィールドのすぐ下に表示され、レシピを構築する際に送信する必要があるデータ型を把握できます。 これらのヒントを使用して、適切なデータ型をSQL Serverに送信してください。そうしないと、予期しない動作やジョブの失敗につながる可能性があります。
 各入力フィールドの下にあるヒントで、想定されるデータ型が通知されます
各入力フィールドの下にあるヒントで、想定されるデータ型が通知されます
以下は、よく表示される一般的なデータ型です。 より包括的な一覧は、SQLデータ型リファレンスで確認できます
一般的なデータ型の一覧を表示するには、ここをクリックしてください
| データ型 | 説明 | 例 |
|---|---|---|
| int | -2,147,483,648から2,147,483,647までの整数を許可します | -100,1,30,000 |
| decimal | 正確な固定精度および固定小数点数です。 これは一般的に使用されます。 最大長を指定できますが、デフォルトは | 1.11,2.0761,1.61803398875 |
| smallint | 0から255までの整数を許可します | 1,245,100 |
| bigint | -9,223,372,036,854,775,808から9,223,372,036,854,775,807までの整数を許可します | 10,000,000,000 |
| bit | 0、1、またはNULLにできる整数 | 1,0,NULL |
| varchar(n) | 長さnの可変幅文字列 | Foo_bar |
| nchar(n) | 長さnの固定幅文字列 | Foo(n = 3の場合) |
| datetime | 1753年1月1日から9999年12月31日まで、精度は3.33ミリ秒 | 2011-09-16 13:23:18.767 |
| datetime2 | 0001年1月1日から9999年12月31日まで、100ナノ秒の精度 | 2011-09-16 13:23:18.7676720 |
| date | 日付のみを保存します。 0001年1月1日から9999年12月31日まで | 2012-10-11 |
| time | 時刻のみを100ナノ秒の精度で保存します。 最小長hh:mm:ss、最大長hh:mm:ss.nnnnnnnn | 08:30:12,09:12:20.12898400 |
WHERE条件の作成
演算子とデータ型について確認したので、WHERE条件を記述する準備ができました。 文字列値は単一引用符('')で囲む必要があり、使用する列はテーブル/ビューに存在している必要があります。
単一列の値に基づいて行をフィルタリングする単純なWHERE条件は次のようになります。
country = 'United States of America'行を選択アクションで使用すると、このWHERE条件は、currency列に値'USD'を持つすべての行を返します。 入力では、データピルを一重引用符で囲むことを忘れないでください。
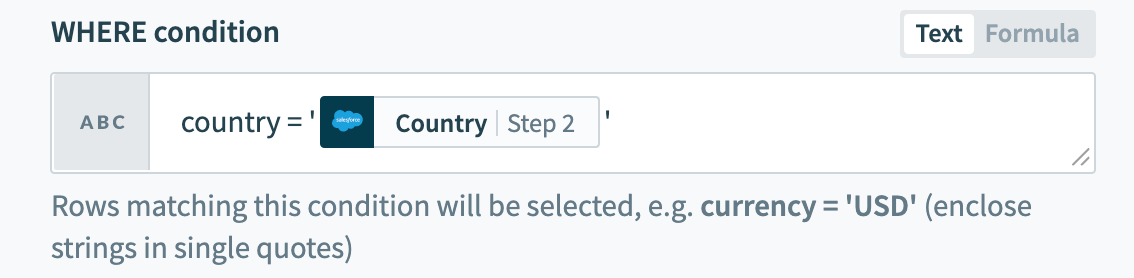
WHERE条件でのデータピルの使用
スペースまたは特殊文字を含む列名は、二重引用符("")または角括弧([])で囲む必要があります。 たとえば、currency codeを識別子として使用するには、引用符で囲む必要があります。
[country code] = 'USA'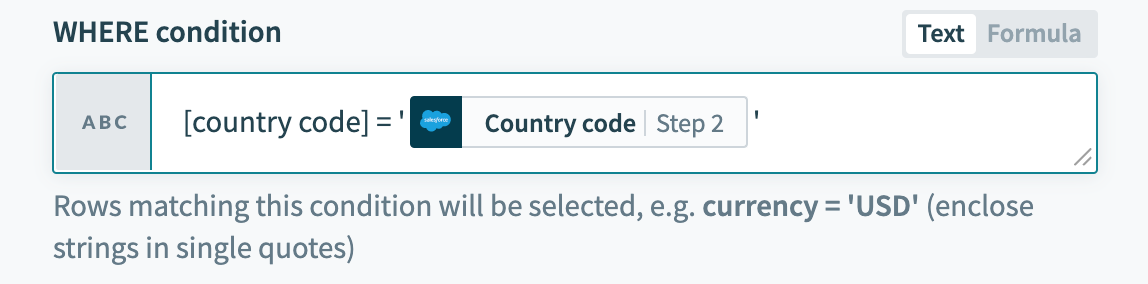 囲まれた識別子を含む
囲まれた識別子を含むWHERE条件
WHERE条件で利用できる機能の詳細については、以下のタブをクリックしてください。
WHERE条件でANDおよびORを使用する
WHERE条件は、ANDやORなどの基本的なSQL論理演算子と組み合わせて使用し、返される行にさらにフィルターを追加することもできます。
([currency code] = 'USD' AND totalAmt >1000) OR totalAmt>2000 組み合わせて使用すると、このWHERE条件は、currency code列に値'USD'があり、かつtotalAmt列が1000を超える行、またはtotalAmt列が2000を超える行をすべて返します
WHERE条件でサブクエリを使用する
WHERE条件にはサブクエリを含めることもできます。 次のクエリは、compensationテーブルで使用できます。
id in (select compensation_id from users where active = 0)行を削除アクションで使用すると、アクティブでなくなったユーザー(active = 0)に関連するcompensationテーブル内のすべての行が削除されます。
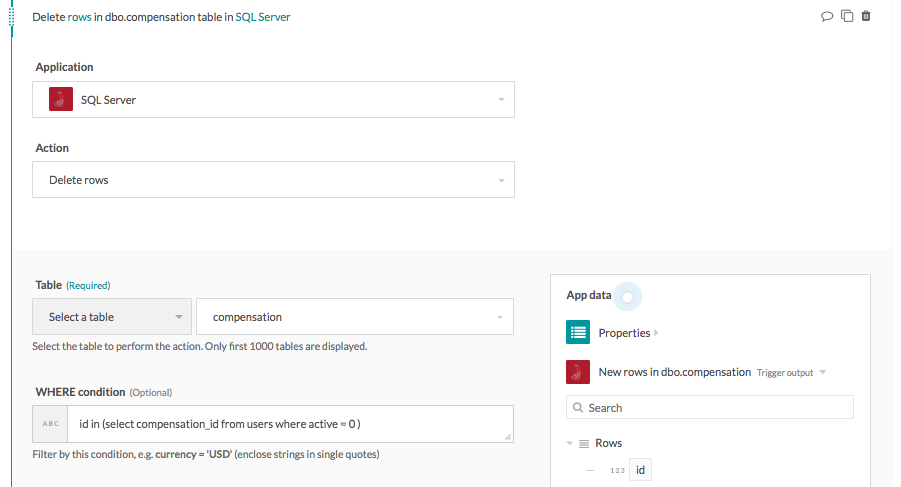 _`WHERE`条件でのサブクエリの使用_
_`WHERE`条件でのサブクエリの使用_ パラメーターの使用
パラメーターは、SQLインジェクションに対する追加のセキュリティレイヤーを加えるために、WHERE条件と組み合わせて使用します。 WHERE条件でパラメーターを使用するには、まず入力でバインド変数を宣言する必要があります。 バインドパラメーターは、変数名の前に:を付けた:bind_variable形式で宣言する必要があります。 これが完了したら、すぐ下のセクションで、指定した正確な名前を使用してパラメーターを宣言します。
TIP
バインド変数は列名ではなく、列値の代わりとしてのみ使用してください。
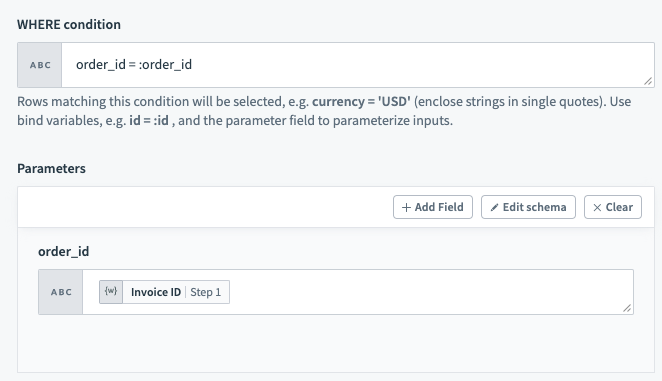 バインド変数を含む
バインド変数を含むWHERE条件
任意の数のバインド変数を指定でき、それぞれに一意の名前を付ける必要があります。 一重引用符(')、二重引用符(")、角括弧([])内の:を無視することで、バインド変数を列名および静的値と区別します。
トリガーの設定
SQL Serverコネクターには、新規行と更新行の両方に対応するトリガーがあります。 トリガーが動作するには、両方の一意キーを構成する必要があります。最近更新された行を検出するトリガーでは、ソート列を構成する必要があります。
トリガーで使用するには、テーブルがいくつかの制約を満たす必要があります。 次のセクションでは、特定の制約について詳しく説明します。 Workatoで使用するためにテーブルを準備する方法については、ベストプラクティスを参照してください。
一意キー
すべてのトリガーと一部のアクションでは、これは必須入力です。 この選択された列の値は、選択したテーブル内の行を一意に識別するために使用されます。 そのため、選択した列の値は一意である必要があります。 通常、この列はテーブルの主キーです(例: ID)。
トリガーで使用する場合、この列は増分である必要があります。 この制約が必要なのは、トリガーがこの列の値を使用して新しい行を検索するためです。 各ポーリングで、トリガーは前回の最大値より大きい一意キー値を持つ行をクエリします。
詳細な例を表示するには、ここをクリックしてください
この動作を説明するために、簡単な例を使用しましょう。 テーブルから行を処理した新規行トリガーがあるとします。 このトリガーに設定されたunique keyはIDです。 最後に処理された行のID値は100です。 次回のポーリングでは、トリガーは新しい行を検索する条件として>= 101を使用します。 一意キーとして使用するために選択した列にインデックスが付けられている場合、トリガーのパフォーマンスを向上できます。
ソート列
これはNew/updated rowトリガーでは必須です。 この選択された列の値は、更新された行を識別するために使用されます。
行が更新されても、Unique key値は同じままです。 ただし、最終更新時刻を反映するようにSort columnが更新されている必要があります。 このロジックに従って、Workatoはこの列の値を、選択されたUnique key列の値とともに追跡します。 Sort column値の変更が検出されると、更新行イベントが記録され、トリガーによって処理されます。
SQL Serverでは、datetime2およびdatetime列タイプのみ使用できます。
詳細な例を表示するには、ここをクリックしてください
この動作を説明するために、簡単な例を使用しましょう。 テーブルから行を処理した新規/更新行トリガーがあるとします。 このトリガーに構成された一意キーとソート列は、それぞれIDとUPDATED_ATです。 トリガーによって最後に処理された行のID値は100、UPDATED_AT値は2018-05-09 16:00:00.000000です。 次回のポーリングで、トリガーは次の2つの条件のいずれかを満たす新しい行をクエリします:
UPDATED_AT'2018-05-09 16:00:00.000000'ID> 100 ANDUPDATED_AT = '2018-05-09 16:00:00.000000'
単一行アクション/トリガーの使用と行のバッチアクション/トリガーの使用
SQL Serverコネクターは、単一行またはバッチのいずれかでデータベースの読み取りまたは書き込みを実行できます。 バッチトリガー/アクションを使用する場合は、操作するバッチサイズを指定する必要があります。 バッチサイズには1~100の任意の数値を指定でき、最大バッチサイズは100です。 多数の行を読み取り、作成、または更新することが想定されるジョブには、バッチトリガーとアクションが適しています。 ジョブ実行を個別のジョブ実行に分割するのではなくバッチ化することを選択すると、オペレーションを節約できるだけでなく、レシピの実行時間を短縮し、サーバーの負荷を軽減できます。
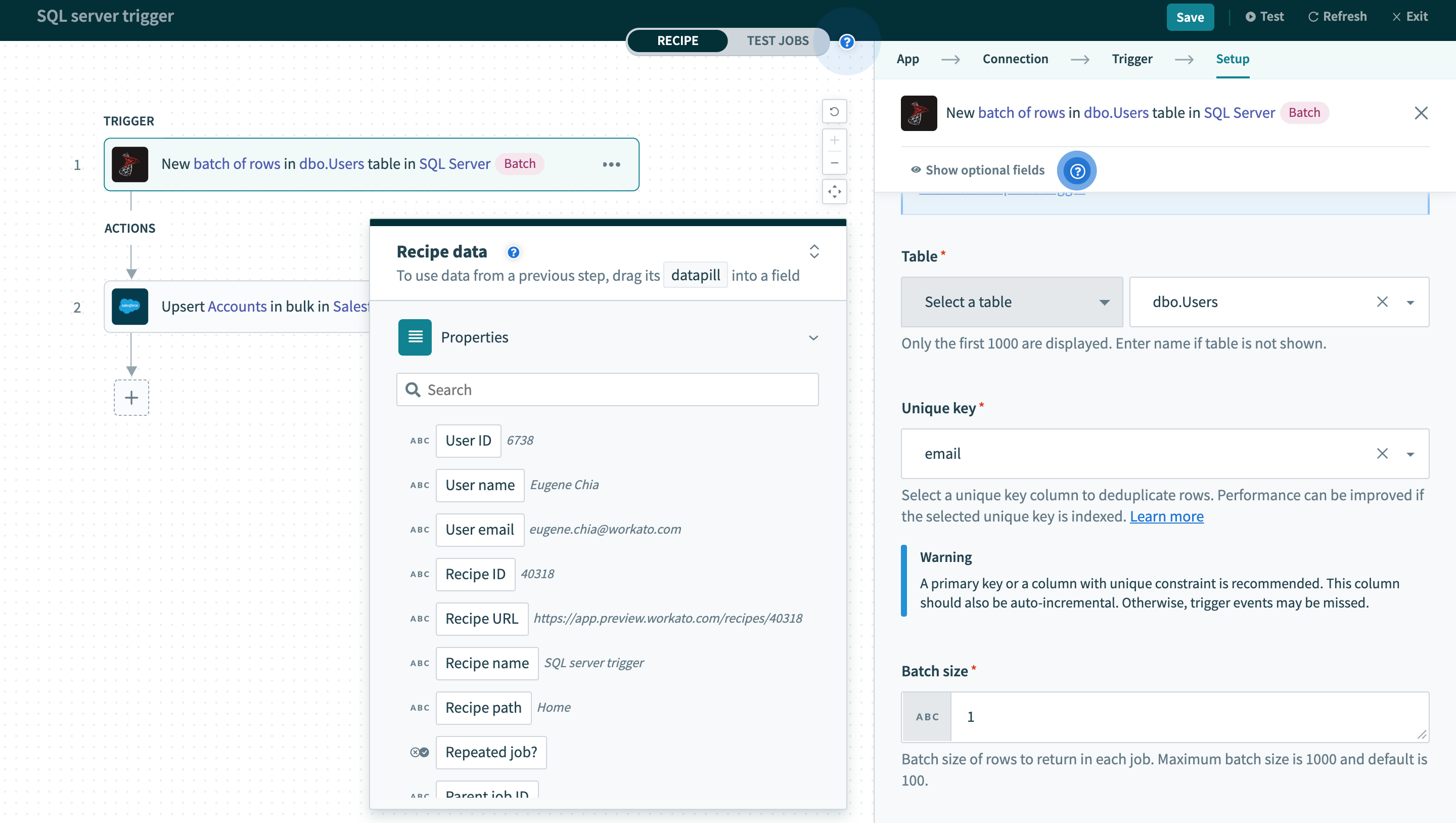 バッチトリガー入力
バッチトリガー入力
入力フィールドの違いに加えて、これら2種類の操作の出力にも違いがあります。 行を1つずつ処理するトリガーには、その単一行のデータをマッピングできる出力データツリーがあります。
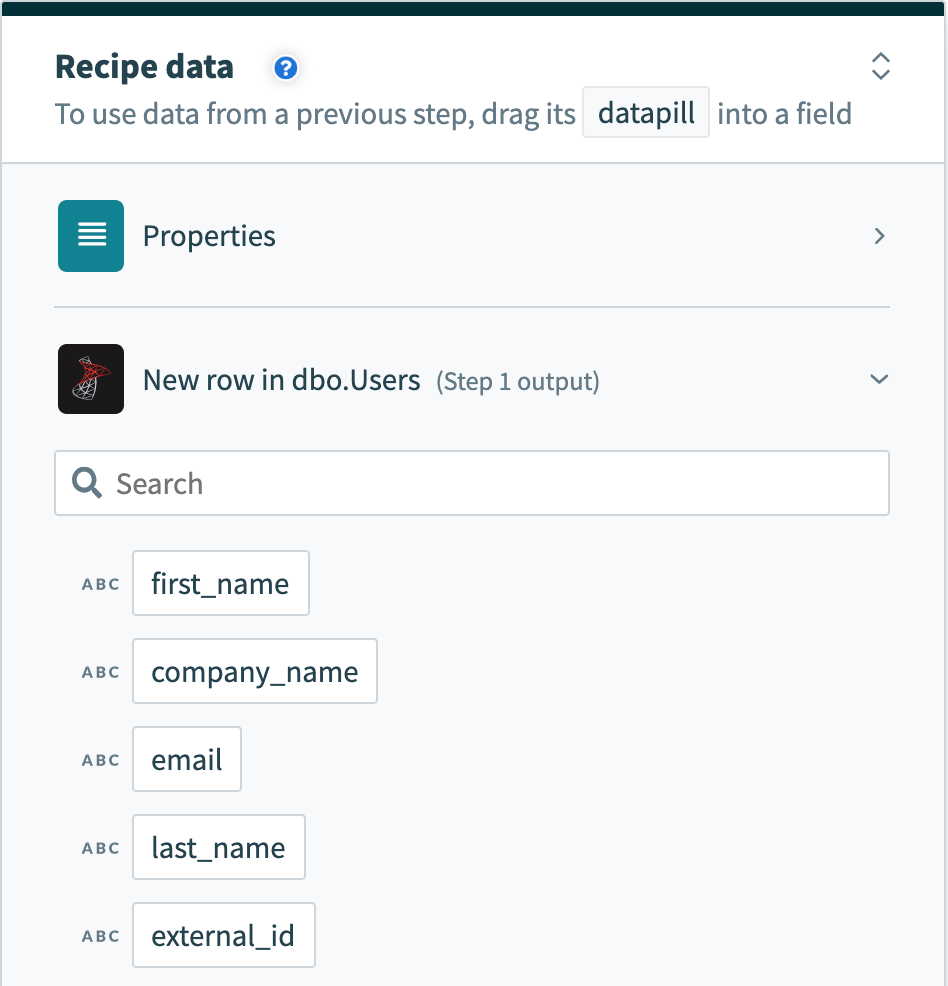 単一行出力
単一行出力
ただし、行をバッチで処理するトリガーは、それらを行の配列として出力します。 行データピルは、出力がそのバッチ内の各行のデータを含むリストであることを示します。
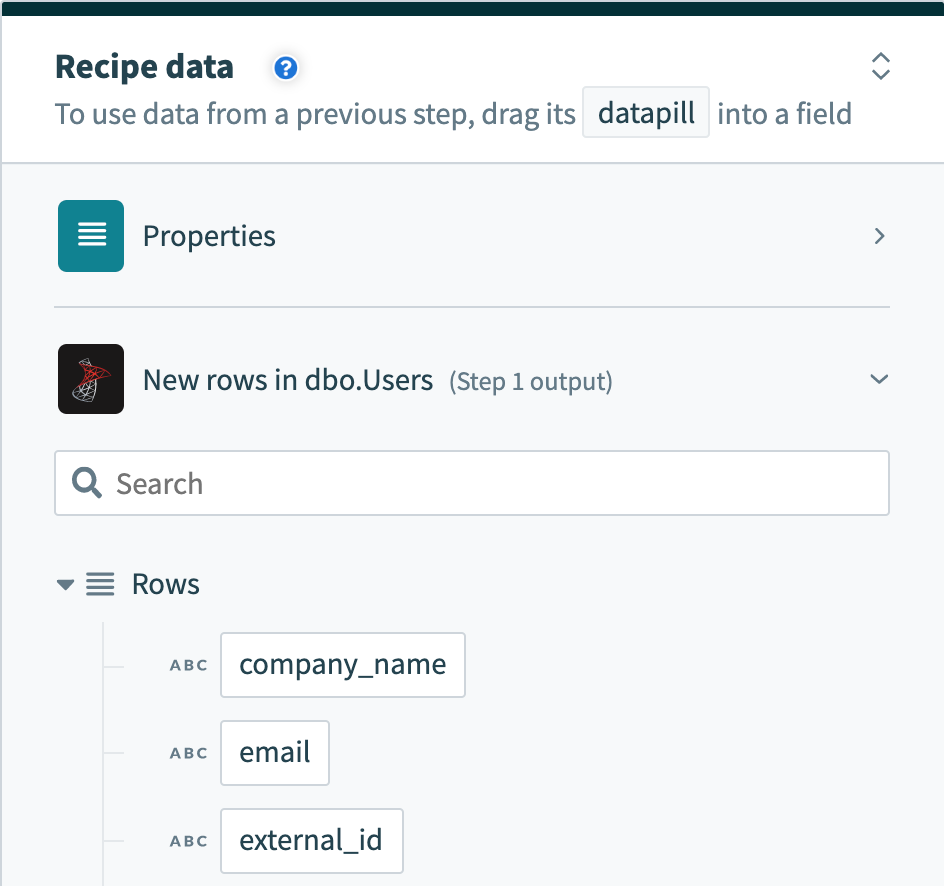 バッチトリガー出力
バッチトリガー出力
そのため、バッチトリガー/アクションの出力は異なる方法で処理する必要があります。 このレシピでは、usersテーブルの新規行にバッチトリガーを使用しています。 トリガーの出力はSalesforce一括作成アクションで使用され、行データピルをソースリストにマッピングする必要があります。
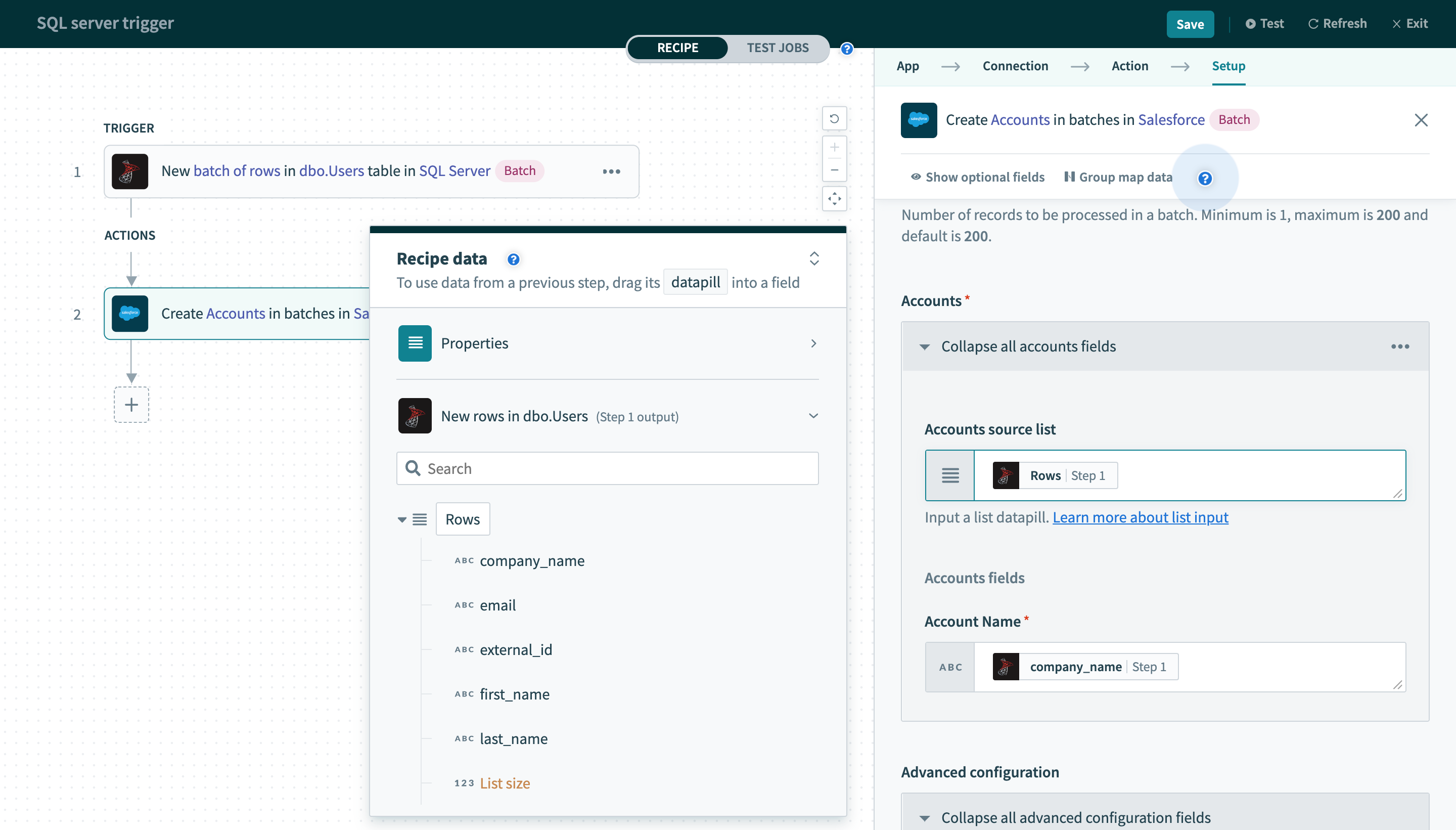 バッチトリガー出力の使用
バッチトリガー出力の使用
バッチトリガー/アクションからの出力は、リスト専用のアクション以外でも使用できます。 Workatoの繰り返しステップを使用すると、バッチ出力を制御し、単一行用に構築された任意のアクションで使用できます。
バッチアクションと単一行アクションのどちらを使用すべきかわからない場合 レシピ設計のヒントについては、ベストプラクティスセクションを確認してください
Workatoのトリガーとアクションの一覧
Workatoは現在、次のトリガーとアクションをサポートしています。 詳細については、以下のリンクをクリックしてください。 サイドバーから移動することもできます。
または、今すぐレシピの構築を開始しましょう。 以下をご覧ください
最終更新日: