データソースの設定
Data Sources 設定では、SQL クエリを実行するための 1 つ以上のソースを指定できます。レシピのセットアップ中に複数のデータソースを追加できます。レシピがアクティブになった後で既存のデータソースを変更したり新しいものを追加するには、最初にレシピを停止してから変更を行ってください。
データソースの設定方法
データソースを設定するには、次の手順を完了します。
1つ以上のデータソースを含めるには、Add data source を選択します。
各データソースについて、次のフィールドを設定します:
データソース名
クエリで参照するために、
accountsやemployeesなどのデータソースの名前を指定します。データソースの種類
SQL Transformations がデータを取得するデータソースの種類を選択します:
データソースの種類に Data table を選択した場合、利用可能なリストから特定のデータテーブルを選択します。テーブルを選択した後、追加の設定は必要ありません。
RESERVED CHARACTER USAGE
データテーブルのテーブル名やカラム名の先頭に @ 文字を使用しないでください。これは SQL で予約されており、クエリ実行中にエラーを引き起こす可能性があります。
データソースの種類に Content stream または FileStorage file を選択した場合、データの File format(ファイル形式)を選択します。CSV または Excel を選択します。選択に基づいて、追加のフィールドが表示されます:
Worksheet(Excelファイルのみ)
取得するデータを含むExcelワークシートの名前を入力します。
Range(Excelファイルのみ)
データを取得するExcelワークシート内のセル範囲を指定します(例:
B5:C20)。範囲を指定する際はヘッダ行を無視してください。データ範囲が動的な場合は、任意の範囲を含め、クエリを設定して空またはヌル行を無視します。
ファイル形式を選択した後、Schema setup type(スキーマ設定タイプ)を設定します。この設定は、受信データのスキーマをどのように定義するかを決定します:
Add data source を選択して追加のデータソースを提供します。これにより、変換に必要なデータをまとめることができます。
例:AWS S3 コネクタからの CSV ファイルコンテンツを使用したデータソース
この例では、データソースは employee と名付けられ、S3 のダウンロードファイルアクションから取得したファイルコンテンツからデータが取得されます。スキーマには従業員に関する情報が含まれており、CSV データは ,(カンマ)を区切り文字として使用しています。
さらに、ユーザーは CSV のヘッダ行を無視することを選択しています。
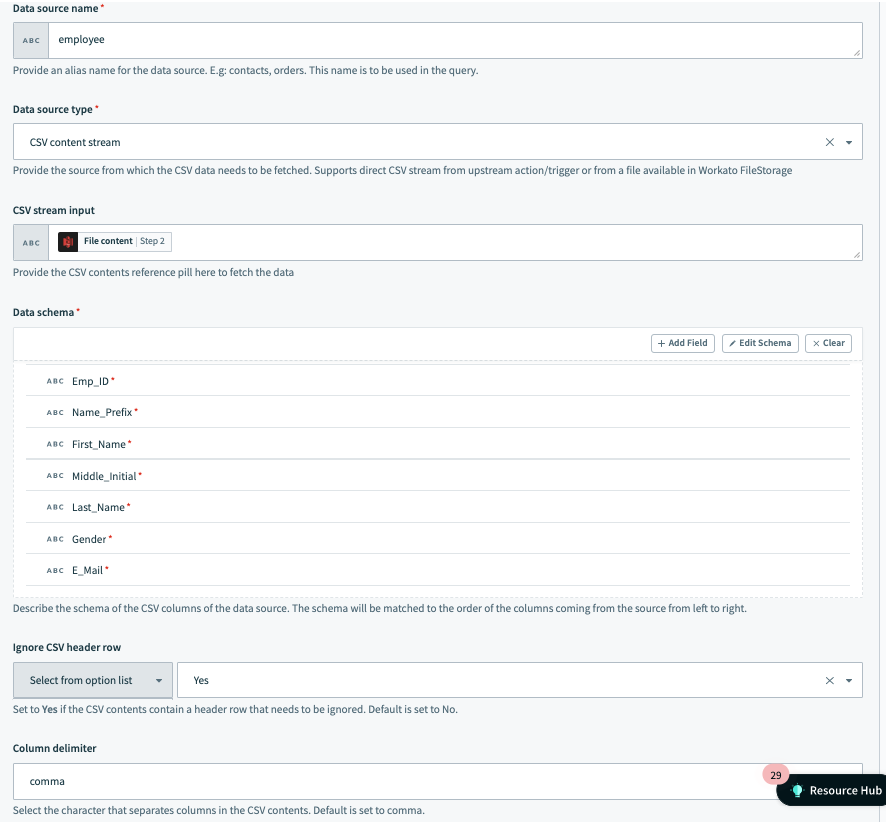 データソースの例の設定 1
データソースの例の設定 1
例:Workato FileStorage に保存された CSV ファイルを使用したデータソース
この例では、データソースは zipcode と名付けられ、パスが SQL/zipcode_data.csv の Workato FileStorage に保存されたファイルから取得されます。
前の例と同様に、カラム区切り文字は ,(カンマ)であり、ユーザーはクエリの実行中にファイルからのデータの CSV ヘッダ行を無視することを選択しています。
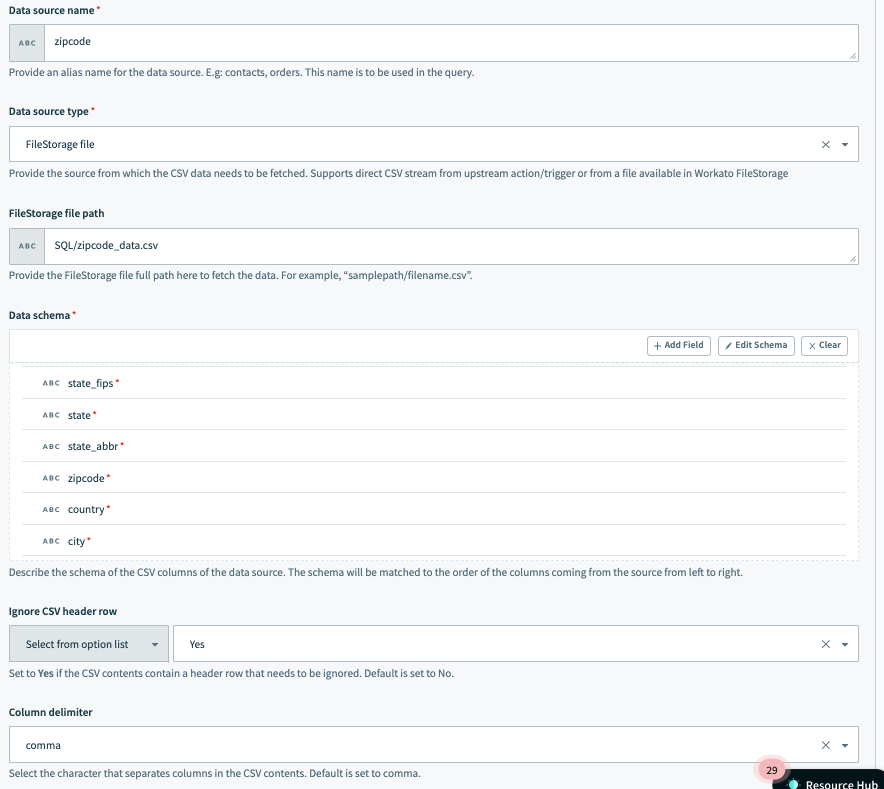 データソースの例の設定 2
データソースの例の設定 2
例:Google Drive コネクタからの Excel ファイルコンテンツを使用したデータソース
この例では、データソースは sales_data と名付けられています。Google Drive のダウンロードファイルアクションから取得した Excel ファイルからデータを取得します。スキーマは売上関連のカラムで構成され、Excel のデータは Q1_Sales という名前のワークシートと範囲 A3:E100 から取得されます。
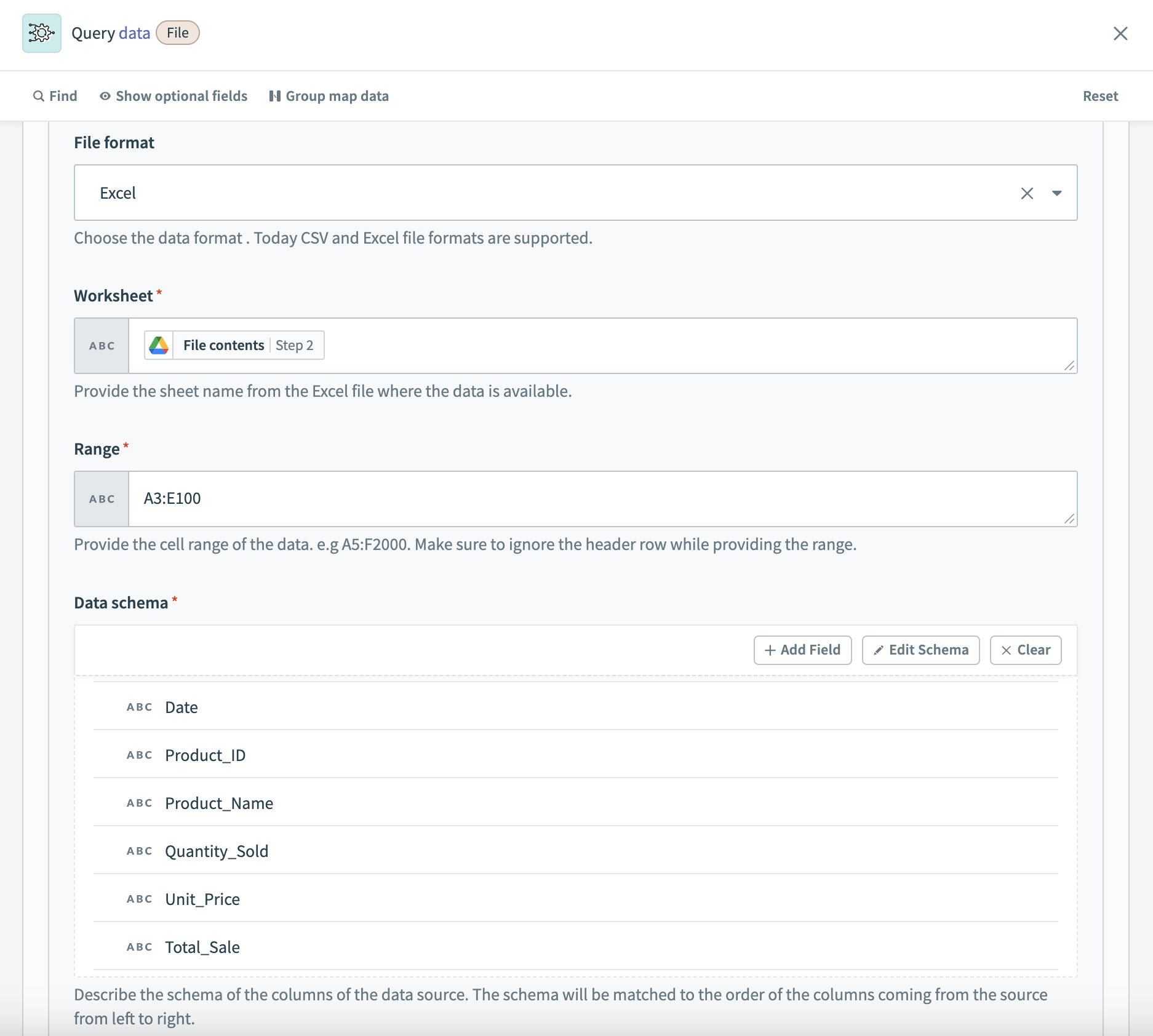 データソースの例の設定 3
データソースの例の設定 3
例:Salesforce トリガー出力を使用した動的スキーマのデータソース
この例では、Salesforce トリガーを使用し、Salesforce 出力の Object schema データピルを通じてスキーマを動的に更新します。Field name、Field label、Mapped type などの Salesforce データは、トリガーによって返されるレコードに応じて変化する可能性があるため、このレシピでは Schema setup type を Dynamic に設定します。
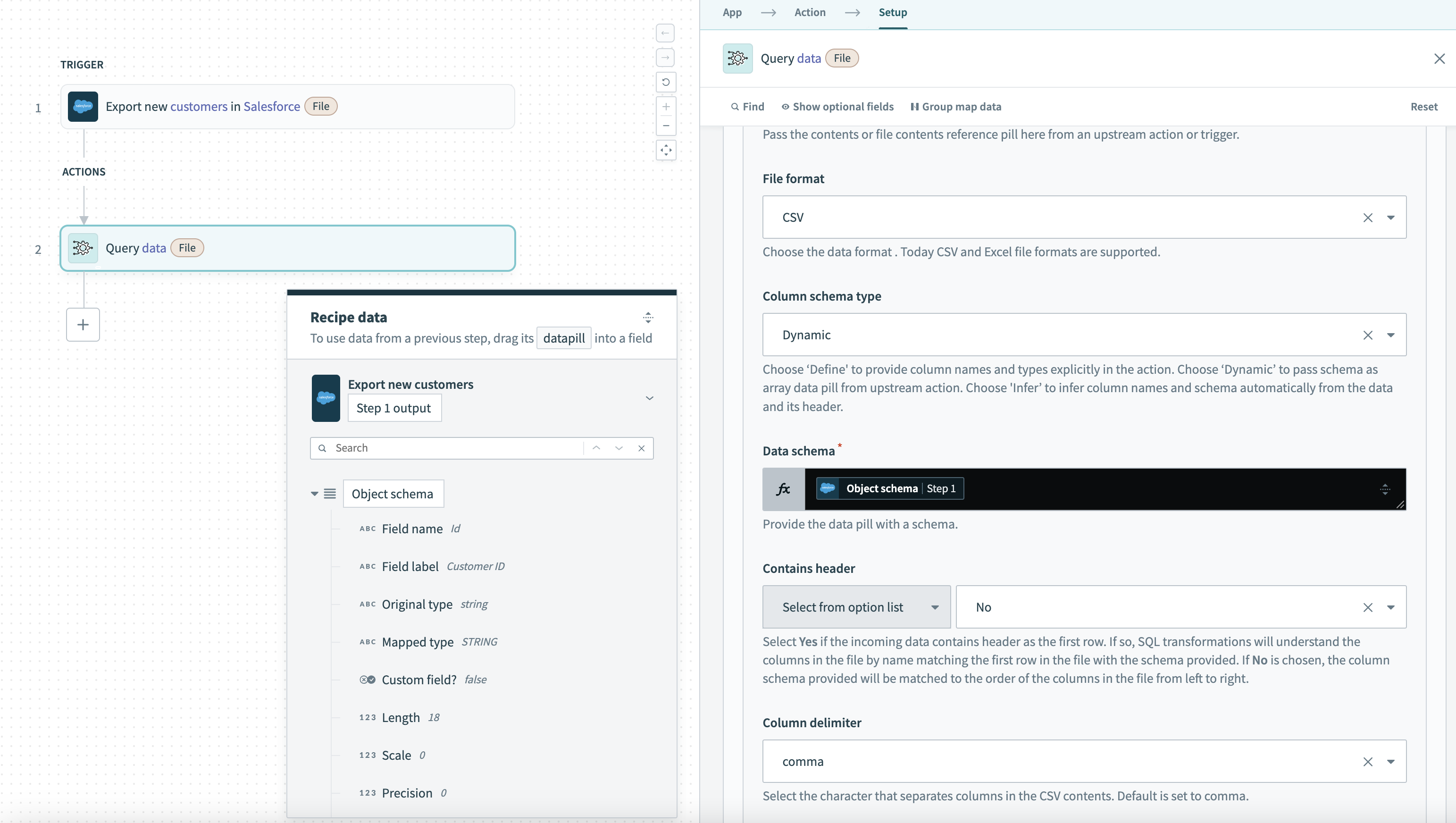 Salesforce 動的スキーマのデータソース設定例
Salesforce 動的スキーマのデータソース設定例
スキーマは Salesforce 出力のフィールドに自動的に適応し、手動の介入を必要とせずにオブジェクトフィールドの変更や更新を処理します。
例:前のクエリからのスキーマを使用した動的スキーマのデータソース
次の例では、あるクエリステップから次のクエリステップに動的なスキーマを渡します。最初のクエリからの Output schema データピルが、2つ目のクエリの動的スキーマセクションでデータソースとしてマッピングされます:
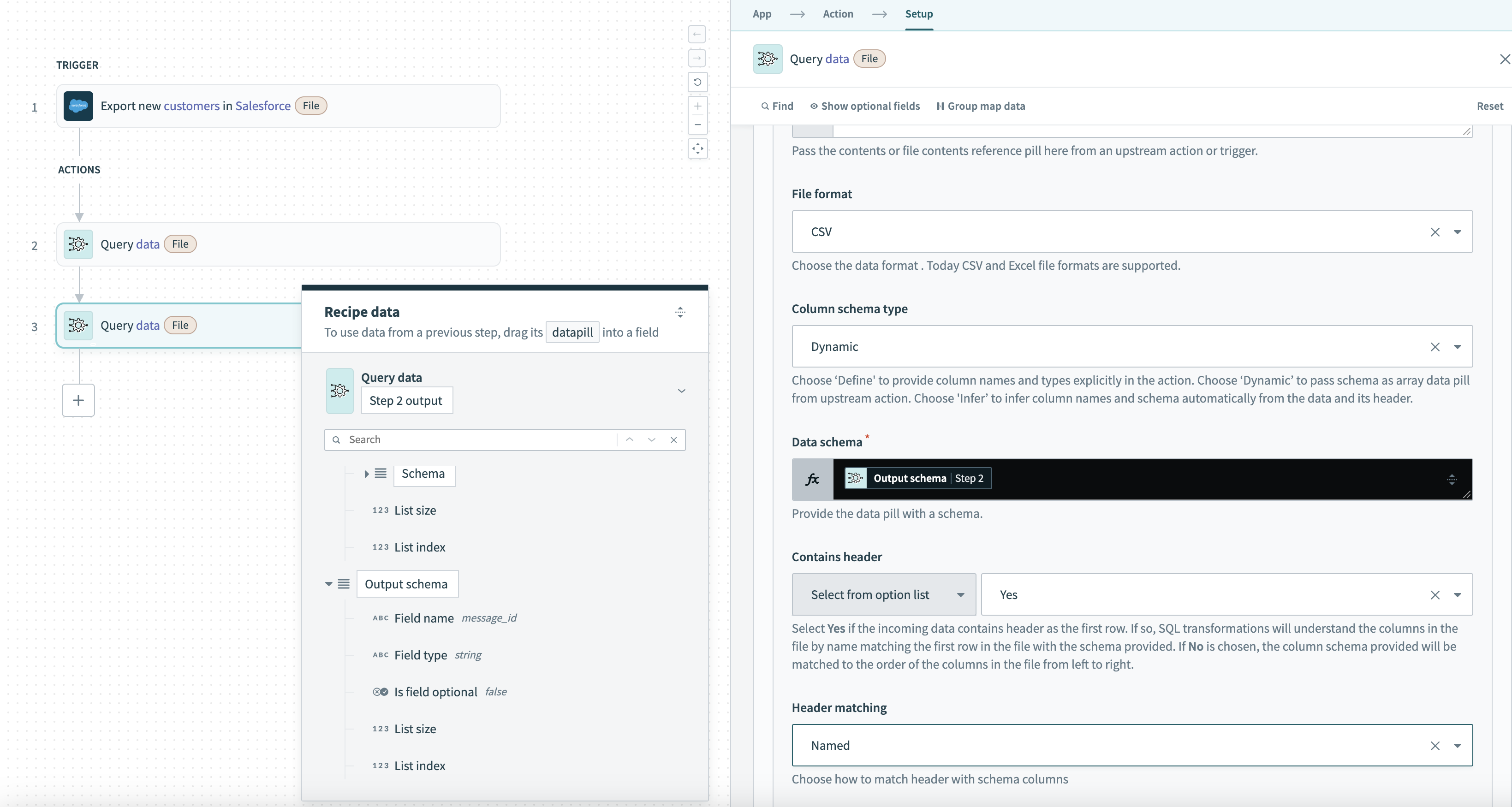 前のクエリデータからのスキーマを渡すデータソース設定例
前のクエリデータからのスキーマを渡すデータソース設定例
データ構造(Field name や Field type など)が前に処理されたレコードによって変化する可能性があるため、動的スキーマオプションが選択されています。スキーマは手動の設定を必要とせず、前のクエリの出力の構造に合わせて自動的に調整されます。
次を読む
Sample use cases
次のユースケースで SQL Transformations を活用するためのステップバイステップの手順については、ガイドをご覧ください:
Last updated: